SNU : Causal Inference
1.SNU Causal Inference : Introduction
해당 게시글은 서울대학교 데이터 사이언스 대학원 이상학 교수님의 강의를 기반으로 작성되었습니다.Explore CSR 워크샵을 통해 2달 간 서울대학교 인과 추론 연구실 인턴으로 활동하며 진행한 스터디의 일환으로 이 글을 작성하게 되었으며, 다시 한 번 좋은 기회를 주신
2.SNU Causal Inference : Causal Model & Causal Graph
인과관계를 명시하기 위한 모델로, PCH (Pearl's Causal Hierarchy) 세 계층을 모두 만들어 낼 수 있다.$Z$ : Random Variable$z$ : Value of the variable, where $z\\in\\mathfrak{X}\_Z$$
3.SNU Causal Inference : Connecting Unobserved and Observed Worlds
$U_1,...,U_n\\subset U$ are jointly independent $\\equiv$ No bidirected Edge in the $\\mathcal{G}$이러한 형태가 된다면 앞서 다룬 것보다 더 쉽게 다음과 같이 P(v)를 나타낼 수 있다.$P(
4.SNU Causal Inference : Identification of Causal Effects
어떠한 변수 X 를 우리가 조작한다고 할 때, 기존에 우리가 수집한 데이터의 분포는 조작 후의 데이터 분포와는 달라질 것이다.우리가 개입한 후에 발생하는 목표 변수 Y의 변화량을 인과 효과 (Causal Effect)라 부름. 앞서 말했 듯, 주어진 데이터셋의 분포는
5.SNU Causal Inference : Confounding and Backdoor
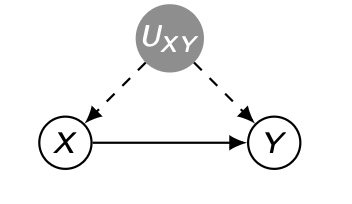
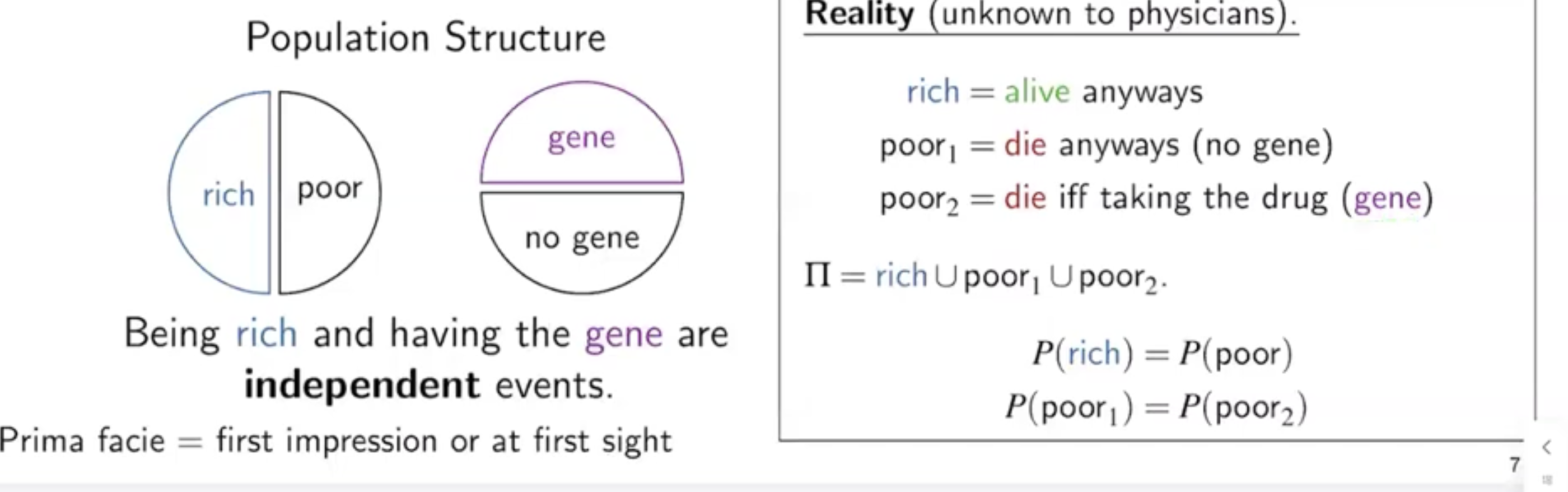
Markovian Model 에서는 우리가 identifiable 함을 알고 있으나, unobserved confounder 가 존재한다고 하더라도 non-causal path를 차단할 수 있다면 causal effect 를 계산할 수 잇음을 알아보았다.하지만 우리가
6.SNU Causal Inference : Adjustment Criterion

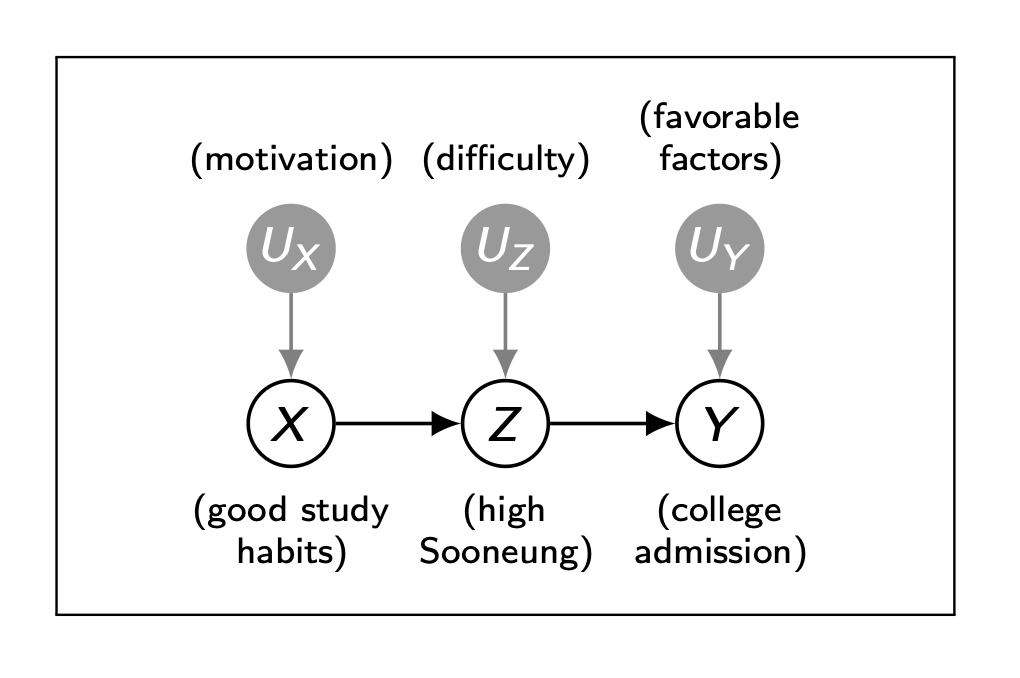
위의 정리에 따르면, 앞서 배운 back-door criterion을 만족하는 변수들에 대해, w를 만족하는 특정 집단에 대한 treatment의 인과효과를 측정할 수 있으며 이를 w-specific effect 라고 부른다.위의 그래프의 경우, $Z_1,\\,Z_2$
7.SNU Causal Inference : Do-Calculus

1. Truncated Factorization in Semi-Markovian Models 앞서 다룬 Markovian Model들은 모두 identifiable 하며, 이 경우 $P(vi|pai,ui)=P(vi|pa_i)$ 로 줄여서 표현할 수 있었다. 하지만 Semi-Markovian, 즉 unobserved confounder가 존재하는 상황에선 ...
8.SNU Causal Inference : Algorithmic ID
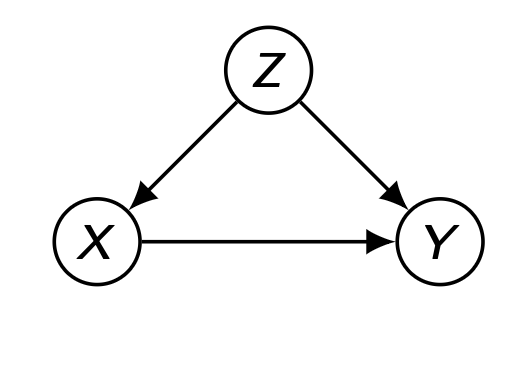
다음과 같은 Markovian Model 상황을 가정하자. 이 경우, Truncated Factorization 에서 unobserved variable을 생략해도 괜찮으며 $P(v_i|pa_i)$ 를 canonical factor 로 사용하여 분리할 수 있다.Trun
9.Paper Review : Counterfactual Graphical Models - Constraints and Inference (Bareinboim et al., ICML 2025)
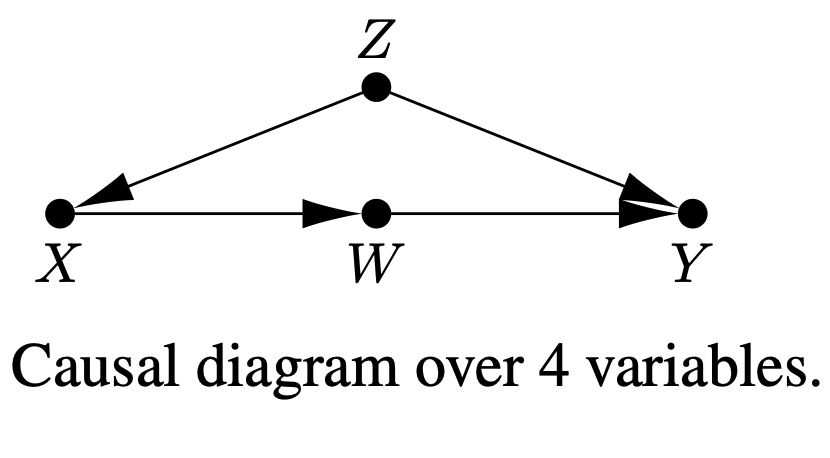
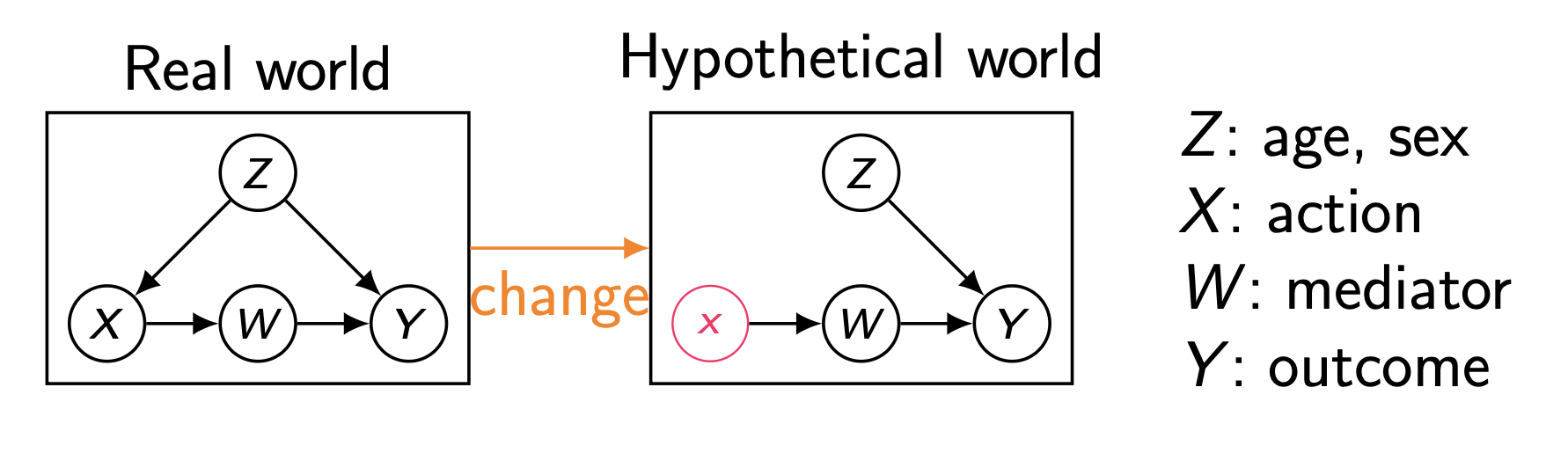
Pearl's Causal Hierarchy 에서는 보통 "관찰", "개입", "반사실"로 세 층위로 나눈다. 그중에 반사실은 $P(Y_x|X=x')$ 같이, 어떠한 Treatment X를 실행하지 않은 집단에 대해, Treatment를 실행할 경우에 실제론 어떻게 변