스프링 트랜잭션과 @Transactional의 동작방식
배경
Spring을 이용하여 코드를 작성하면서 @Transactional을 이용해본적 없는 개발자는 없을 것입니다.
@Transactional을 선언하면 어플리케이션에서 어노테이션 하나로 DB에 트랜잭션을 적용할 수 있으며
해당 어노테이션을 통해 트랜잭션 전파유형, 롤백규칙, 격리 수준 등을 커스텀하게 설정할 수 있는 아주 흔히 쓰이며 유용성 높은 어노테이션입니다.
그런데 코드를 작성하다 문득, @Transactional을 사용을 자주하지만 내부적으로 동작원리를 잘 모르고 있는 것 같았습니다. 그 계기는 하나의 클래스에서 @Transactional이 선언되어있는 메서드가 동일한 클래스의 @Transacitional이 있는 내부 메서드를 호출하여 코드를 작성한 과거의 저를 발견했기 때문입니다.
이 상황은 무엇이 잘못되었을까요?
이번 기회에 Spring에서의 Transactiona의 동작원리 및 @Transactional의 동작방식에 대해서 정리해보고자 합니다.
Spring과 Transaction
@Transactional 이해에 앞서 Spring 자체에서 트랜잭션을 어떠한 관점에서 보고 어떻게 다루는지를 이해할 필요가 있습니다.
스프링은 다음의 3가지 방식으로 트랜잭션을 다룹니다.
트랜잭션 동기화
-
TransactionSynchronizationManager를 통해 트랜잭션 동기화를 실행합니다.
-
TransactionSynchronizationManager는 내부에 트랜잭션 관련된 정보를 ThreadLocal을 이용하여 저장하여 동일한 스레드 내에서 같은 정보를 공유할 수 있게끔 구성합니다.
- ThreadLocal에는 트랜잭션과 관련된 리소스(Connection, Session 등)를 저장합니다.
- JDBC -> Connection 객체
- JPA, Hibernate -> EntityManager, Session 객체
- 즉 ThreadLocal 내에 트랜잭션 관련 정보를 저장함으로써 동일한 트랜잭션 보장이 가능합니다.
- ThreadLocal에는 트랜잭션과 관련된 리소스(Connection, Session 등)를 저장합니다.
-
작업 쓰레드마다 각 ThreadLocal에 트랜잭션 관련 정보를 저장하기 때문에 멀티 쓰레드 환경에서 충돌이 발생할 여지가 없습니다.
하단 그림은 TransactionSynchronizationManager의 코드
-
또한 PlatformTransactionManager의 각 구현체에서 TransactionSynchronizationManager를 아래와 같은 방식으로 이용하여 하나의 쓰레드 내에서 유지할 수 있습니다.
- DataSourceTransactionManager의 JDBC 트랜잭션 생성 코드
@Override protected void doBegin(Object transaction, TransactionDefinition definition) { DataSourceTransactionObjecttxObject = (DataSourceTransactionObject) transaction; Connection con =DataSourceUtils.getConnection(this.dataSource); txObject.setConnectionHolder(new ConnectionHolder(con)); // ThreadLocal에 트랜잭션 동기화 TransactionSynchronizationManager.bindResource(this.dataSource,txObject.getConnectionHolder()); }
트랜잭션 추상화
- Spring은 PlatformTransactionManager라는 인터페이스를 통해 트랜잭션 추상화 기술을 제공합니다.
- JDBC, JPA 등 DB 접근하는 기술이 무엇이느냐에 따라서 각 구현체가 다릅니다. (하단 그림참조)
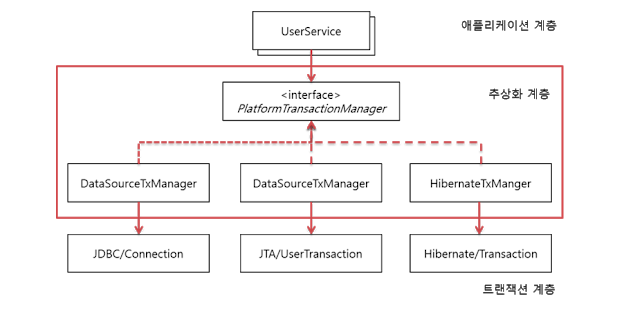
AOP를 이용한 트랜잭션 분리
public void addUser(User user) {
TransactionStatus status = this.transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
userRepository.save(user) // 비즈니스 로직
this.transactionManager.commit(status);
} catch (Exception e) {
this.transactionManager.rollback(status);
throw e
}
}
위와 같은 코드에서 비즈니스로직과 Transaction 관련 코드가 뒤섞여있는데, 이를 @Transactional이라는 선언형 어노테이션을 통해 비즈니스 로직에 집중할 수 있습니다.
@Transactional은 Spring의 AOP를 사용해서 프록시 객체를 생성하는데, 해당 프록시 객체가 트랜잭션과 관련된 로직을 담당하게 함으로써 역할과 책임을 명확히 분리할 수 있습니다.
@Transactional에의 이해
@Transacional 어노테이션은 그렇다면 어떻게 동작할까요?
스프링 AOP 개념의 이해가 본 글의 목적이 아닌 관계로 간단히만 설명하고 넘어가겠습니다.
전술하였듯, 해당 어노테이션은 스프링의 AOP 기술을 이용한 프록시 객체를 사용하는데요, 간략하게 알아보자면 과정은 다음과 같습니다.
- @Transactional 어노테이션이 붙어있는 메서드 혹은 클래스는 AOP의 ‘Pointcut’으로 등록됩니다.
- 스프링의 AOP 기술을 활용하여 해당 어노테이션이 붙은 클래스 또는 메서드 등은 CGLIB(클래스 기반) 또는 JDK 동적프록시(인터페이스 기반의 클래스)를 통해 프록시 객체가 생성됩니다.
- @Transactional이 붙은 메서드 또는 클래스가 호출되면 프록시 객체가 호출을 가로채서 Transactionalnterceptor로 전달합니다. 해당 객체가 Advice 역할을 수행합니다.
- Transactionalnterceptor가 내부적으로 TransactionManager를 호출하고 TransactionStatus 객체를 반환하여 트랜잭션 상태를 관리하며 ProceedingJoinpoint.proceed()를 통해 비즈니스 로직을 위임한 후 커밋 또는 롤백을 수행합니다.
@Transactional
public void addUser(User user) {
userRepository.save(user) // 비즈니스 로직
}
동일한 기능을 하는 로직이지만, @Transactional 어노테이션 추가로 인해 비즈니스로직에만 집중할 수 있습니다.
Spring에서 @Transactional 이용 시 기본 예외 전략
Spring에서 @Transactional은 UnCheckedException에 대해서 예외가 발생하면 자동적으로 RollBack이 되게끔 구성되어있습니다.
한 예로 Spring의 data접근과 관련되어 발생하게 되는 예외(예를 들어 SqlException)는 내부적으로 UnCheckedException 계열(DataAccessException)으로 전환해서 다시 예외를 내던지는 방식으로 작성이 되어있고 이는 Spring의 기본적 예외처리 관련된 철학의 일환이라고 볼 수 있습니다.
이는 UnCheckedException의 경우에 프로그래밍적 오류나 논리적으로 복구 불가능한 오류 혹은 개발자가 처리할 수 없는 것 등에 해당되는 경우가 많기에 롤백되게끔 스프링에서 설계를 해뒀기 때문입니다.
물론 해당 옵션은 기본값이지만, @Transactional의 속성 값으로 ‘rollBackFor’라는 값이나 ‘noRollbackFor’에 특정 예외를 설정해줌으로써 해당 예외에만 롤백을 적용하거나 적용하지 않는 방식으로 커스텀하게 작성할 수도 있습니다.
트랜잭션 전파
트랜잭션 전파는 트랜잭션의 경계에서 이미 진행중인 트랜잭션이 있거나 없을때 어떻게 동작할 것인지를 결정하는 것을 의미한다. 이미 기 실행중이던 트랜잭션 A가 존재하고 B라는 새로운 작업의 시작으로 B작업에 대한 트랜잭션을 어떻게 다룰까와 같은 것이 트랜잭션 전파에서 다루는 내용입니다.
해당 개념을 다루기 전에 물리트랜잭션과 논리트랜잭션에 대한 간단한 개념에의 이해가 요구됩니다.
트랜잭션 전파에서 물리적 트랜잭션과 논리적 트랜잭션의 개념이 상이한데 각각의 내용은 다음과 같습니다.
- 물리 트랜잭션
- DB와의 연결 단위에서 실행되는 트랜잭션
- 하나의 물리 트랜잭션은 데이터베이스 커밋이나 롤백으로 종료된다.
- 논리 트랜잭션
- Spring(어플리케이션)이 관리하는 트랜잭션으로 프로그래밍 관점에서 하나의 트랜잭션으로 취급
- 여러 논리 트랜잭션이 하나의 물리 트랜잭션 범위 내에 들어갈 수 있다.(공유될 수 있다.)
@Transactional 선언시, 트랜잭션 전파에 줄 수 있는 옵션은 다음과 같습니다.
-
REQUIRED
- 이미 시작된 트랜잭션이 있으면 참여한다. 없으면 새로 트랜잭션 시작한다.
- A와 B가 같은 트랜잭션으로 묶인다.
-
REQUIRED_NEW
- 항상 새로운 트랜잭션을 시작한다. 이미 진행중인 트랜잭션이 있으면 새로운 트랜잭션을 만들어 시작한다.
- 이미 시작된 트랜잭션이 있다면, 트랜잭션을 잠시 보류시키고 새로운 트랜잭션을 만든다.
-
SUPPORTS
- 이미 시작된 트랜잭션이 있으면 참여하고 없으면, 트랜잭션 없이 진행
- 트랜잭션이 없어도 Connection 객체, 하이버네이트의 Session 등은 공유 가능하다.
-
NOT_SUPPORTED
- 이미 진행중인 트랜잭션이 있다면 이를 보류시키고, 트랜잭션을 사용하지 않도록 한다.
-
NEVER
- 이미 진행중인 트랜잭션이 있으면 예외를 발생시키고, 트랜잭션을 사용하지 않도록 강제한다.
-
NESTED
- 이미 진행중인 트랜잭션이 있으면 중첩(자식) 트랜잭션을 생성한다.
- 중첩 트랜잭션은 트랜잭션 안에 트랜잭션을 만드는 것으로 REQUIRED_NEW의 새로운 트랜잭션 생성과 궤가 다르다. NESTED 방식은 먼저 시작된 부모 트랜잭션의 커밋과 롤백에는 영향을 받지만, 자신의 커밋과 롤백은 부모에게는 영향을 주지 않는다.
-
MANDATORY
- 기존 트랜잭션이 있어야만 실행되며 없으면 예외를 발생시킨다.
예를 들자면 다음과 같습니다.
@Service
@RequiredArgsConstructor
public class UserServiceA{
private final UserServiceB userServiceB;
@Transactional
public void methodA(){
userServiceB.methodB();
}
}
---
@Service
public class UserServiceB{
@Transactional(propagation = Propagtion.REQUIRED_NEW)
public void methodB(){
//.. someLogic
}
}
위와 같은 예제에서 methodA가 methodB를 호출하지만 트랜잭션 전파 옵션으로 인해 서로 다른 물리적 트랜잭션에 속하고 논리적 트랜잭션 범위 역시 각각 다르게 됩니다.
@Transactional 사용시 주의사항
처음의 배경부분에서 설명했던 부분으로 돌아가보겠습니다.
아래의 코드에서 methodA와 methodB의 (논리적으로) 트랜잭션이 각각 수행될까요?
@Service
public class ExampleService {
@Transactional
public void methodA() {
System.out.println("methodA: 트랜잭션 시작");
methodB(); // 내부 호출
}
@Transactional
public void methodB() {
System.out.println("methodB: 별도의 트랜잭션 시작");
}
}
정답은 ‘아니오’입니다.
이는 프록시 객체의 동작방식에 기인합니다.
스프링은 AOP를 통해 프록시 객체를 생성합니다.
스프링은 @Transactional이 선언된 Bean의 경우 해당 Bean의 프록시 객체를 별도로 생성하여, POJO로 생성된 Bean을 프록시 객체가 감싸게 됩니다.
@Transactional이 선언되어있는 메서드가 호출될 경우, Advice를 실행하게 되는데 이 동작에서
프록시 객체는 ‘외부 호출’만 가로채게 됩니다. 즉, 동일 클래스의 내부 호출 등은 프록시 객체의 동작대상에 포함되지 않습니다.
따라서 methodB()의 경우 프록시 객체를 거치지 않고 실제 객체의 메서드가 호출되게 됩니다.
즉 본 코드의 의도는 methodA와 methodB의 논리 트랜잭션을 각각 설정해주고자 함이었을 겁니다.
그렇다면 본 의도에 맞게 , 문제를 해결하려면 어떻게 해야할까요?
@Service
public class MethodAService {
private final MethodBService methodBService;
public MethodAService(MethodBService methodBService) {
this.methodBService = methodBService;
}
@Transactional
public void methodA() {
System.out.println("methodA: 트랜잭션 시작");
methodBService.methodB(); // 프록시를 통해 호출
}
}
@Service
public class MethodBService {
@Transactional
public void methodB() {
System.out.println("methodB: 별도의 트랜잭션 시작");
}
}
위와 같이 변경하면, methodA와 methodB가 각각 프록시 객체를 통해 개별적인 논리적 트랜잭션이 적용될 수 있습니다.
