Contents1. K-Means 알고리즘이 학습하는 방법 2. scikit-learn 에서 K-Means 사용하기 3. 최적의 k 값 찾기 4. K-Means 알고리즘의 한계
K-평균 알고리즘은 주어진 데이터를
k개의 클러스터로 묶는 알고리즘 입니다.
또한 K-평균 알고리즘은 클러스터링 중에서도 분할법에 속합니다.
분할법은 주어진 데이터를 여러 그룹으로 나누는 것을 의미합니다.
 source : amazon machine learning blog
source : amazon machine learning blog
다음 그림은 K-평균 알고리즘이 학습하는 방법을 표현한 것입니다.

-
초기 k 평균값은 데이터 내에서 무작위하게 뽑힌다.
( 위 그림에서는 3개의 데이터가 무작위하게 뽑혔다 ) -
k 개의 군집들은 가장 가까이 있는 평균값을 기준으로 나뉜다.
( 이때 유클리드 거리가 사용된다 ) -
할당된 데이터들의 평균값으로 새로운 중심점을 업데이트 한다.
-
변화가 거의 없을때 까지(수렴할때 까지) 2, 3 과정을 반복한다.
위 과정들을 수식으로 나타내면 아래 비용 함수를 최소화 하는것을 목표로 학습하게 됩니다.

즉 군집의 중심점과 데이터들의 거리의 제곱합 을 최소화 하는방향으로 학습하게 됩니다.
# 02 - scikit-learn 에서 K-Means 사용하기
scikit-learn 에서 KMeans 클래스를 사용하여 쉽게 구현할 수 있습니다.
다음과 같은 코드로 KMeans 클래스를 사용할 수 있습니다.
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(train_set)여기서 n_clusters 가 바로 군집 갯수를 정해주는 매개변수 입니다.
군집된 결과는 KMeans.labels_ 로 접근하여 확인할 수 있습니다.
K-평균 알고리즘의 특징이자 단점이 바로
클러스터 개수를 정해줘야 한다는 점입니다.
그래서 클러스터 개수인 적절한 k 값을 찾아야 하는것이 중요합니다.
여러가지 방법론들이 있지만 대표적인 방법중에 엘보우 방법이 있습니다.
클러스터의 중심과 클러스터에 속한 샘플 사이의 거리의 제곱합을 이너셔
라고 부릅니다. 따라서 이너셔의 값을 클러스터의 샘플들이 얼마나
가까이 있는지 나타내는 하나의 척도로 볼 수 있습니다.
엘보우 방법은 이너셔 의 변화를 관찰하여 최적의 K 값을 찾는 방법입니다.
아래의 그림은 K 값이 증가함에 따른 이니셔의 변화를 나타낸 그래프 입니다.

클러스터 개수 즉 K 값을 증가시키면서 이너셔를 그래프로 그리면
감소하는 속도가 꺾이는 지점이 있는데 이 지점을 지나면
K 값이 증가하여도 이너셔의 값이 감소하는 정도가 크게 줄어들게 됩니다.
즉 그래프의 꺾이는 지점 ( 위 그래프에서는 대략 3 ) 이 바로
최적의 K 값 입니다.
K-Means 알고리즘은 몇가지 한계를 가지고 있습니다.
첫번째로 K 값을 미리 결정해야 한다 는 단점입니다.
실제 분류해야하는 데이터가 몇종류 인지도 모르는 상태에서
K 값을 찾아야 한다는 것은 그리 쉬운일이 아닐수도 있습니다.
두번째로는 이상치(outlier) 에 민감하다는 것입니다.
이상치 란 대부분의 데이터에 비하여 멀리 떨어져 있는 데이터를 말합니다.
이러한 이상치는 클러스터의 중심점을 제대로 찾지 못하게 합니다.
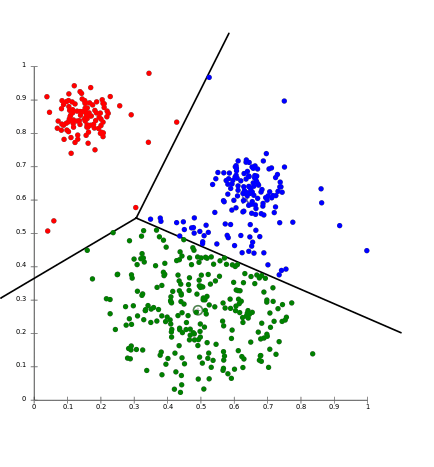
마지막으로 비구형 클러스터에는 적절치 않다 는 점입니다.
K-Means 알고리즘은 중심점이라는 개념이 있어서
구형의 형태가 아닌 클러스터를 분류하는데에는 무리가 있습니다.

위와 같이 비구형 클러스터에서는 잘 작동하지 않는것을 확인할 수 있습니다.
Referencehttps://ko.wikipedia.org/wiki/K-%ED%8F%89%EA%B7%A0_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98 https://yganalyst.github.io/ml/ML_clustering/#k-means%EC%99%80-dbscan-%EB%B9%84%EA%B5%90
