Contents1. K-최근접 이웃 알고리즘의 특징과 거리공식 2. K-최근접 이웃 분류 알고리즘 3. K-최근접 이웃 회귀 알고리즘
KNN (K-Nearest Neighbor) 알고리즘은 이름 그대로 가장 가까운
샘플 K개를 선택한 다음 샘플들을 비교하는 방식입니다.
분류와 회귀는 다른 역할을 합니다.
분류는 샘플의 클래를 정하고
회귀는 임의의 숫자를 예측합니다.
# 01 - K-최근접 이웃 알고리즘의 특징과 거리공식
K-최근접 이웃 알고리즘은 가까운 샘플들을 선별해야 하기에
거리기반 알고리즘이라는 특징을 가지고 있습니다.
그러면 샘플들의 거리를 KNN 알고리즘은 어떻게 계산할까요?
우선 scikit-learn 기준 기본으로 사용하는 공식은 Minkowski Distance 입니다.
민코프스키 거리는 유클리드 거리와 맨해튼 거리를 일반화한 공식입니다.

n 차원 점 x, y 에 대해 p 차 민코프스키 거리는 위와 같습니다.
p=1 이면 맨해튼 거리 p=2 이면 유클리드 거리와 같습니다.
scikit-learn 은 p=2 를 기본값으로 계산하여
scikit-learn 이 사용하는 기본 공식은 정확히는 유클리드 거리 입니다.
또한 KNN 알고리즘에 사용되는 거리공식은 주로 유클리드 거리 라고 합니다.
다음은 p값에 따른 민코프스키 거리를 단위원으로 나타낸 것입니다.

위에서 언급하였듯 KNN 알고리즘에 주로 사용되는 거리공식은
유클리드 거리공식 입니다. 유클리드 거리공식은 일반적으로
두 점에대해서 즉 2차원에 대한 거리를 구할 때에 흔히 떠올리는 방식으로
피타고라스 정리를 사용하여 계산합니다.
2차원에 대한 점 p, q의 유클리드 거리는 다음과 같습니다.

n차원에 대한 점 p, q의 유클리드 거리는 다음과 같습니다.
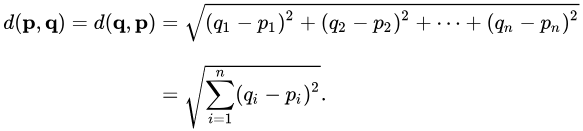
K-최근접 이웃 분류 알고리즘은 굉장히 간단합니다.
우선 예측하려는 샘플에 가장 가까운 샘플 K개를 선택합니다.
그 다음 다수의 클래스를 예측하려는 샘플의 클래스로 분류합니다.
scikit-learn 에서 KNN 분류 알고리즘을 사용하는 방법은 다음과 같습니다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target) # 모델 훈련하기
print(kn.score(test_input, test_target)) # 모델 평가하기
print(kn.predict([[25, 150]])) # 모델의 예측값 출력회귀는 분류와 다르게 어떠한 값을 예측해야 합니다.
KNN 알고리즘에서 회귀의 예측값은 주변 이웃 샘플 값들의 평균값입니다.
KNN 회귀 알고리즘은 다음과 같이 사용할 수 있습니다.
from sklearn.neighbors from KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target) # 모델 훈련하기
print(knr.score(test_input, test_target)) # 모델 평가하기앞서 KNN 회귀 알고리즘은 주변 샘플들의 평균을 예측의 결과값으로
반환한다고 하였습니다. 하지만 거리에 따라서 평균의 가중치를 더할 수 있습니다.
knr = KneighborsRegressor(weights = 'distance')위와 같이 weights 파라미터에 'distance' 를 전달해 주면
거리에 따른 가중치를 더해줄 수 있습니다.
거리에 따른 가중치를 더하면 평균값 계산이 조금 달라지게 되는데요
분자는 각각의 이웃들의 값을 거리에 나눈것을 모두 더하고
분모는 1을 거리에 나눈것을 모두 더해서 평균을 구하게 됩니다.
KNN 알고리즘은 간단하고 정확도가 높은 알고리즘 이지만
데이터가 커질수록 계산이 느려지고 k 값에 따라서
결과 차이가 많이 난다는 단점이 있습니다.
