Sample Table Information
Q1.
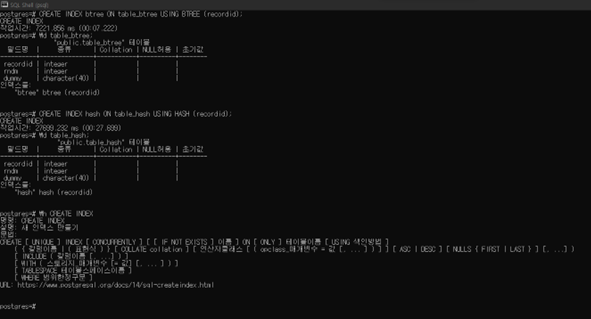
Create two indexes
- Create indexes on attribute “recordid” in “table_btree” and “table_hash”
- Create b-tree in “table_btree.recordid”
- Create hash index in “table_hash.recordid”
- Type “\h CREATE INDEX” for detailed index creation syntax
- Use a method name “btree” for creating b-tree and “hash” for creating hash index
A1.
Q2.
a. Run two queries and compare the query execution plan and total execution time
- SELECT * FROM table_btree WHERE recordid=10001;
- SELECT * FROM table_hash WHERE recordid=10001;
b. Run two queries and compare the query execution plan and total execution time
- SELECT * FROM table_btree WHERE recordid>250 AND recordid<550;
- SELECT * FROM table_hash WHERE recordid>250 AND recordid<550;
A2.
a.
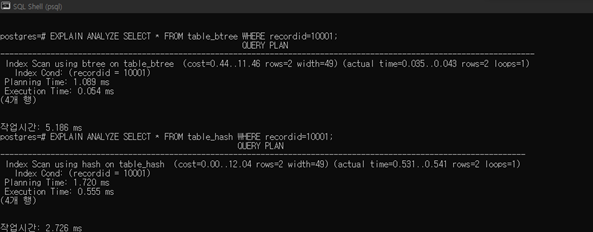
두 쿼리 모두 index scan을 사용한다. 첫 쿼리의 총 수행 시간은 1.143ms, 두 번째 쿼리의 총 수행 시간은 2.275ms이다.
b.
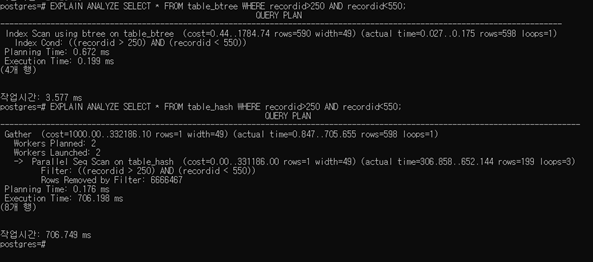
첫 쿼리는 index scan을 사용하며, 두 번째 쿼리는 sequential scan을 사용한다. 첫 쿼리의 총 수행 시간은 0.871ms, 두 번째 쿼리의 총 수행 시간은 706.374ms이다.
Q3.
a. Update a single “recordid” field in “table_btree”. And update a single “recordid” field in “table_noindex”. Then find a difference
- Update “recordid” from 9,999,997 to 9,999,998
b. Update 2,000,000 “recordid” fields in “table_btree”. And update 2,000,000 “recordid” fields in “table_noindex”. Then find a difference
- Increase “recordid” fields by 100% whose value is greater than 8,000,000
c. Update all “recordid” fields in “table_btree”. And update all “recordid” fields in “table_noindex”. Then find a difference
- Increase all “recordid” fields by 10%
A3.
a.
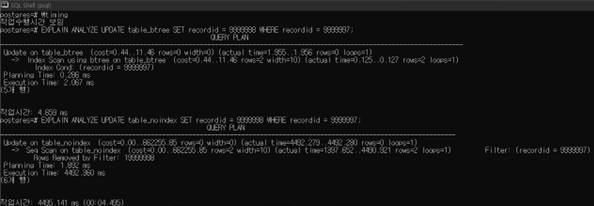
table_btree에서 single “recorded” field를 업데이트 할 때는 index scan을 사용하고, table_noindex에서 업데이트 할 때는 sequential scan을 사용한다.
b.
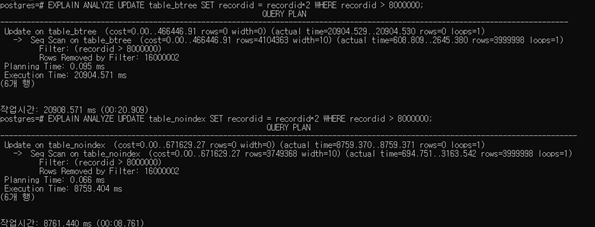
table_btree에서 update하는 경우와 table_noindex에서 업데이트 하는 경우 모두 sequential scan을 사용한다. (index가 있어도 index를 사용하는 것이 유리하지 않기 때문이다.)
c.


table_btree에서 update하는 경우와 table_noindex에서 업데이트 하는 경우 모두 sequential scan을 사용한다. (index가 있어도 index를 사용하는 것이 유리하지 않기 때문이다.)
Q4-Lab Setup.
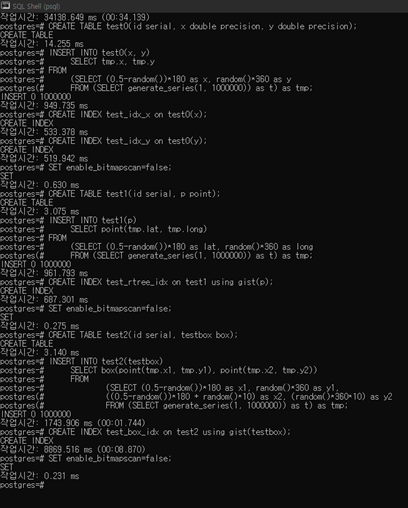
Synthetic data – randomly distributed points
- CREATE TABLE test0(id serial, x double precision, y double precision);
- INSERT INTO test0(x, y)
SELECT tmp.x, tmp.y
FROM
(SELECT (0.5-random())180 as x, random()360 as y
FROM (SELECT generate_series(1, 1000000)) as t) as tmp; - CREATE INDEX test_idx_x on test0(x);
- CREATE INDEX test_idx_y on test0(y);
- SET enable_bitmapscan=false;
Synthetic data – randomly distributed points
- CREATE TABLE test1(id serial, p point);
- INSERT INTO test1(p)
SELECT point(tmp.lat, tmp.long)
FROM
(SELECT (0.5-random())180 as lat, random()360 as long
FROM (SELECT generate_series(1, 1000000)) as t) as tmp; - CREATE INDEX test_rtree_idx on test1 using gist(p);
- SET enable_bitmapscan=false;
Synthetic data – randomly distributed points
- CREATE TABLE test2(id serial, testbox box);
- INSERT INTO test2(testbox)
SELECT box(point(tmp.x1, tmp.y1), point(tmp.x2, tmp.y2))
FROM
(SELECT (0.5-random())180 as x1, random()360 as y1,
((0.5-random())180 + random()10) as x2, (random()36010) as y2
FROM (SELECT generate_series(1, 1000000)) as t) as tmp; - CREATE INDEX test_box_idx on test2 using gist(testbox);
- SET enable_bitmapscan=false;
Q4.
a. Find all points within a rectangle ((1,1), (10,10)) on the tables “test0” and “test1”
- Compare an index scan and seq scan
- SET enable_indexscan=true;
- SET enable_indexscan=false;
b. Find all boxes overlapped with rectangles ((0,0), (1,1)) and ((9,9), (10,10)) at the same time on the table “test2”
- Compare an index scan and seq scan
- SET enable_indexscan=true;
- SET enable_indexscan=false;
c. Find 10 nearest points to (0,0) on the tables “test0” and “test1”
- Compare an index scan and seq scan
- SET enable_indexscan=true;
- SET enable_indexscan=false;
A4.
a.
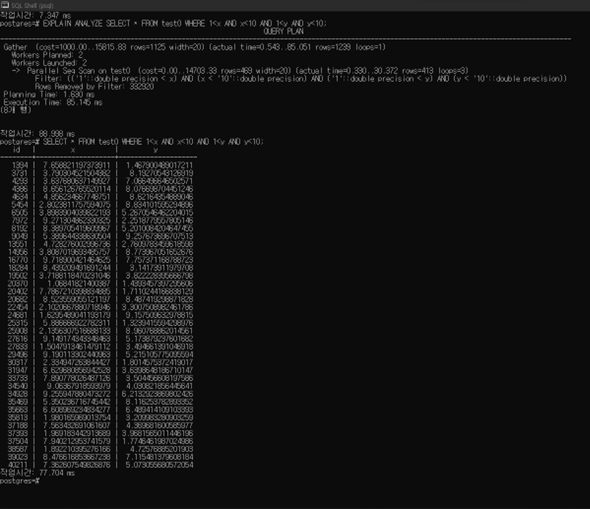
"test0" indexscan=true
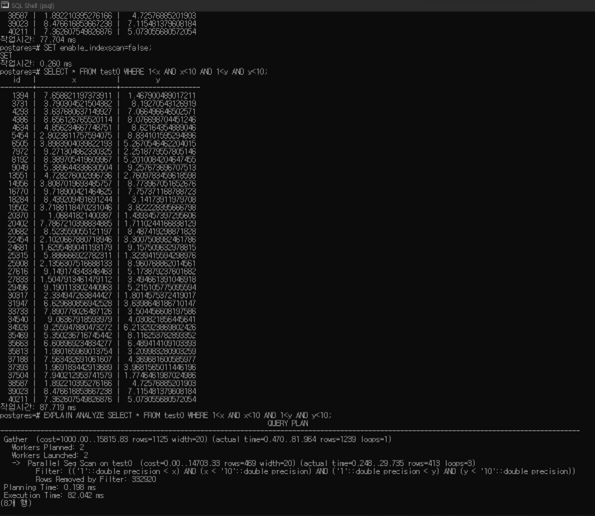
"test0" indexscan=false

Hello.