Sample Table Information
Q1.
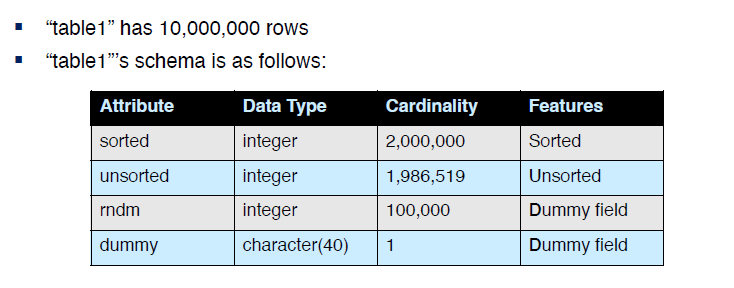
a. Create two indexes on “table1”
- Indexed attributes are “sorted” and “unsorted”
- PostgreSQL automatically makes clustered and non-clustered index
based on attribute’s data distribution- Which is clustered index or non-clustered index?
- Type “\h CREATE INDEX” for detailed index creation syntax
A1.
Sorted 된 쪽이 clustered. Unsorted가 non-clustered. 정렬되어 있어야만 clustered index 사용 가능하기 때문.
Q2.
PostgreSQL supports following index-based query execution plans
- Seq scan: All rows in a table are read sequentially
- Index scan: Some (or all) rows in a table are read after traversing an index
- Index only scan: Query is processed in an index, not accessing table data
‘EXPLAIN ANALYZE’ statement shows the query plan and execution time of the query
- E.g., > EXPLAIN ANALYZE SELECT * FROM table1;
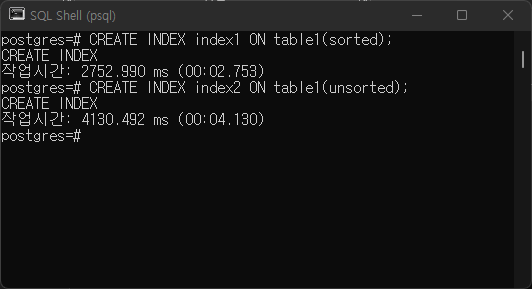
a. Make (and execute) three queries each of which uses seq scan, index scan, and index only scan respectively
b. Make two queries using clustered index and non-clustered index, then compare their execution times
c. Execute and compare the following two queries:
- SELECT sorted, rndm FROM table1 WHERE sorted>1999231 AND
rndm=1005; - SELECT sorted, rndm FROM table1 WHERE sorted<1999231 AND
rndm=1005; - Explain why their query plans are different
A2.
a.
index scan

Seq scan

Index only scan

b.
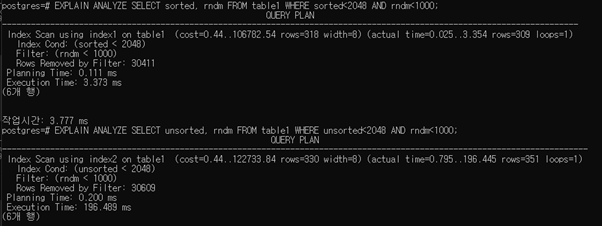
Non-clustered 쪽이 실행 속도가 느림을 알 수 있다.
c.
두 query의 실행 결과는 다음과 같다.
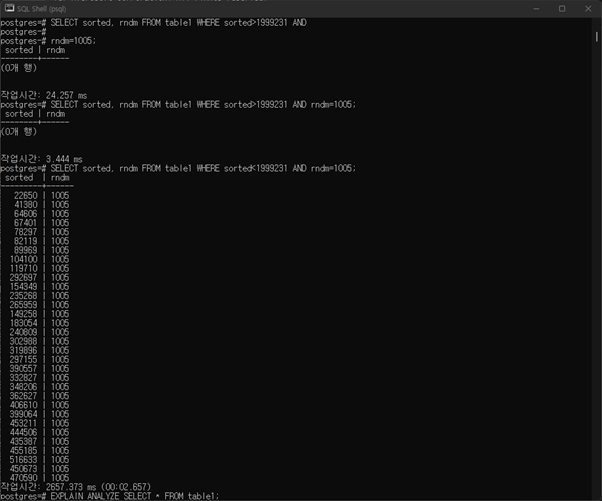
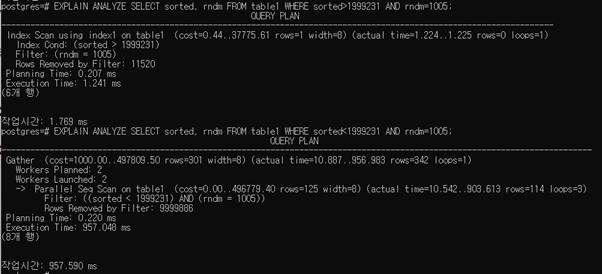
쿼리 플랜이 다른 이유는 첫 쿼리가 index scan할 때 cost가 상당히 줄어들기 때문에. 두번째 쿼리는 별로 차이 없기 때문에 내부적으로 쿼리 플래너가 다른 판단을 했음.
Q3-Lab Setup.
Type on psql command line
- SET enable_bitmapscan=false;
- \timing
Create a synthetic data set that has 5,000,000 rows
- CREATE TABLE pool (val integer);
- INSERT INTO pool(val) SELECT * FROM (SELECT
generate_series(1,5000000)) as T;
Q3.
Consider two cases below. Which case will take a longer time?
- Inserting tuples in a table, and then creating index
- Creating index, and then inserting tuples in a table
Compare the execution time 𝑡1 and 𝑡2
- 𝑡1 = 𝑡1.insert + 𝑡1.create-index.
- Tuple insertion → Index creation
- 𝑡2 = 𝑡2.create-index + 𝑡2.insert
- Index creation → Tuple insertion
3 - Hints
Create an empty table named “table10” and “table20”
- CREATE TABLE table10 (val integer);
- CREATE TABLE table20 (val integer);
Use “table10” to measure 𝑡! and “table20” to measure 𝑡"
- Inserting tuples into tables
Utilize the “pool” table for a synthetic dataset
Insert all the tuples of “pool” into “table10” and “table20”- E.g., > INSERT INTO table10 (SELECT * FROM pool);
A3.
T1
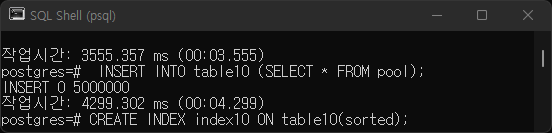
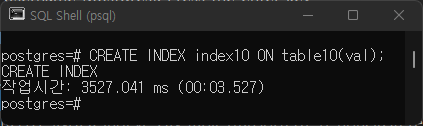
T2
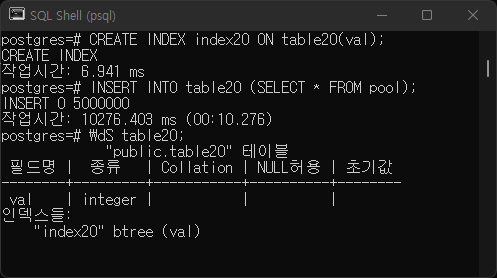
t1<t2

Hello.