3/16 일에 새로운 회사인 RIDI에 입사하게 되었다.
새로운 환경에 적응하는 일은 늘 어려운 일이다. 특히 나 같은 경우는 먼저 다가가서 친해지는 성격도 아니고 은근히 내성적이기 때문에 약간 새로운 환경을 두려워하기도 한다.
무튼 그러나 회사는 회사기 때문에 최대한 빠르게 적응하여 1인분을 하고싶은게 현재 마음이다.
![]()
RIDI 에 입사하게 되면 팀바이 팀에 따라 다르겠지만, 내가 속한 팀에서는 입사자 과제를 내주었다. 전자책 파일을 가지고 만드는 간단한 웹뷰어이다.
말이 간단하지 살면서 전자책을 다뤄보지 못한 나에게는 정말 막막했다.
그렇게 대략적으로 전자책에 대한 설명을 보고, @ridi/epub-parser 를 연구해보면서 개발을 시작하였다.
일단 프로젝트 스펙은 그 전 회사에서 다루었던 Next 기반으로 구성하기로 하였다.
- TypeScript
- Next JS
- Express JS
- Styled-component
- Redux
- GraphQL
- React Apollo요 정도가 내가 미니뷰어 프로젝트에 사용한 스펙이다.
일단 프로젝트를 진행해나가면서 고민하고 생각했던 점은 다음과 같다.
고민...
1. epub파일은 도데체 무엇이고 어떻게 다루어야하나?
질문에 대한 대답은 생각보다 간단하였다. epub 파일은 전자책 파일이라고 이해하면 쉽다. 출판사에서 전자책을 만들 수 있게 책에 필요한 정보들을 코드화 해서 만든 파일이라고 생각하면된다.
따라서 @ridi/epub-parser 바탕으로 epub 파일을 압축을 해제하고, read 를 하게 되면 spine이라고 불리우는 책의 각 챕터? (html 형식으로 되어있다), ncx 라고 불리우는 목차정보, title, author, description, meta 정보 등 epub을 바탕으로 전자책을 그릴 수 있는 다양한 정보드를 가져올 수 있게 된다. 이를 바탕으로 단순히 viewer를 그리기만 하면된다.
2. 책 넘김 효과는 어떻게 해야하나?
두번째 질문이 생각보다 많은 고민을 하게 되었다. 결국 epub파일을 read 해서 spine 쭉 나열하면 되지만 당연하게도 세로로 나열이 된다. 하지만 책은 가로로 넘기는게 일반적이다.
그래서 사용한게 column-width 속성을 사용하였다. 책이 보여지는 큰 틀을 만들고 거기에 width 를 바탕으로 각각 spine에 column-width 속성을 먹였다. 그렇게 되면 가로로 쭉 정렬이 되고 전체 스크롤 / column-width 하여서 한 spine이 몇개의 page 로 나오는지 계산하여 사용하게 되었다.

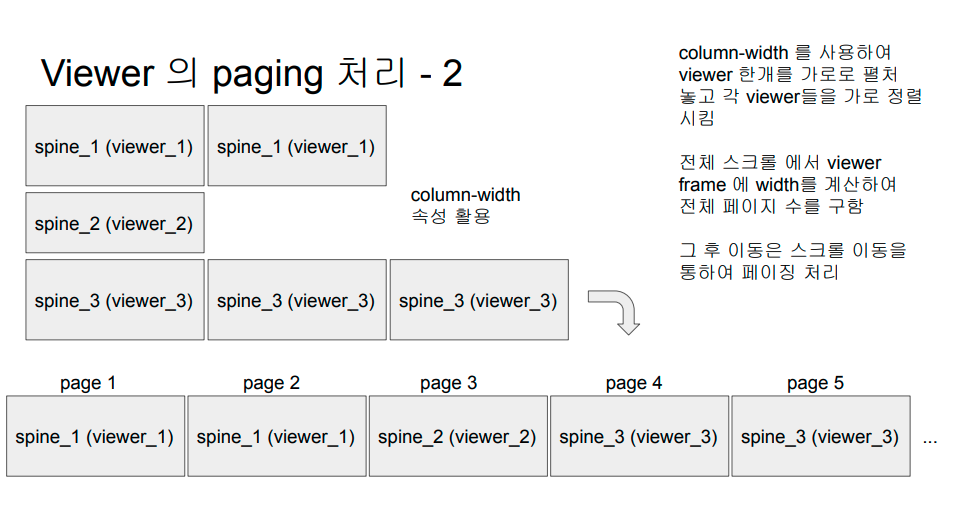

위와 같이 한 뒤 scrollLeft 속성을 이용하여 스크롤이 이동하는 방식으로 구현하게 되었다.
3. pageCount 계산
viewer 에서 현재 page를 변경할 수 있는 방법은 총 3가지라고 생각이 들었다.
1. 좌/우 버튼 클릭
2. 목차정보를 바탕으로 page 이동
3. slider 를 가지고 이동
이를 이용하여서 pageCount속성을 store에 저장해놓고 pageCount 변경시 각각의 현재 보여지는 spine index, spine position 을 변경하여서, 스크롤을 이동시키는 방식으로 구조를 잡고 진행하였다.
- spine position: column-width 속성을 사용하여 나누어진 spine에 pagination이라고 하면 좋을것 같다. 위에 그림에서 spine_1 이 두개의 나뉘었는데 첫째 spine_1을 보고있으면 position을 0, 두번째 spine_1을 보고있으면 position을 1 이라고 명명하였다.
이를 바탕으로 구성하고 나니 후에는 개발 속도가 붙어서 재미있게 viewer를 만들 수 있었다.
4. 서재에서 책 순서 변경
viewer말고도 책이 모여있는 library를 개발했어야하는데, 요구 사항 중에 사용자가 임의로 책의 순서를 변경 할 수 있고, 변경된 순서는 저장 되어야했다. 생각보다 어렵지 않게 개발을 진행하였다. 순서 변경은 drag and drop 방식으로 진행하였고 저장은 localStorage에 각 책의 이름만 저장하여 책을 불러왔을 때에 저장된 sort방식에 따라 책을 다시 재정렬 시켜주었다.
react drag and drop
5. 그래프큐엘 적용
한달 정도의 시간이 주어졌는데 사실 생각보다 일이 빨리 끝나서 기존에 공부하고 있었던 그래프큐엘을 적용해 보았다. 큰 프로젝트는 아니고 간단한 프로젝트 였기에 한번 해보면 좋을것 같았다.
그래서 책 목록을 가져오는것, 책을 지우는것 이 두가지는 REST API 가 아닌 그래프 큐엘로 적용해 봤는데, 크게 좋은 점은 못느꼈고 그래프큐엘 서버가 적용되어있다면 프론트 입장에서는 상당히 좋을 것 같다고 생각했다. overFetch, underFetch 같은 문제가 정말 손쉽게 해결 될것 같았고, 프론트 입장에서 필요한 데이터만 가져오게 되니 서버 쪽에서 resolver를 잘 구성해 놓으면 정말 좋은 api? 가 될 수 있다고 생각이든다. 하지만 속도면에서는 흐음 딱히 장점은 느끼지 못하였다. 정리하자면 원래 있던 서버에 간단하게 graphql 서버를 만들어 놓으면 프론트 개발자 입장에서는 편하게 작업 할 수 있을것 같다라는 생각이 들었다.
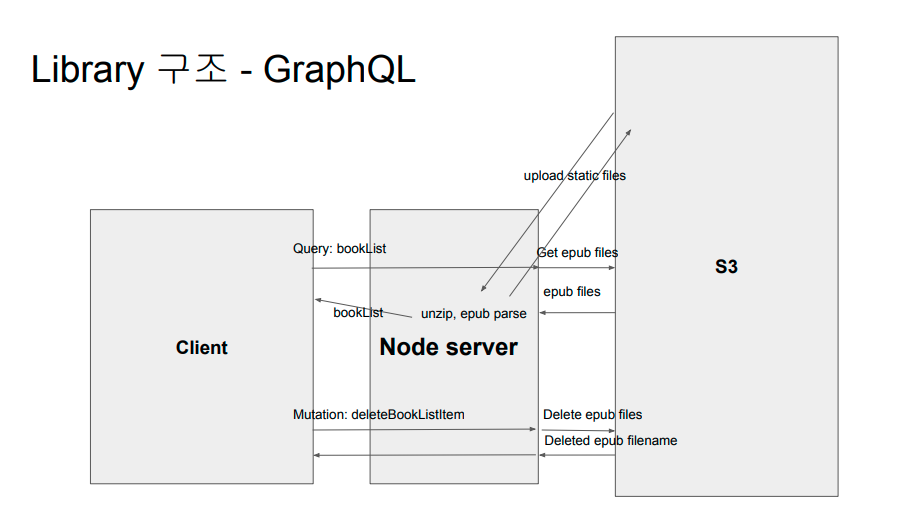
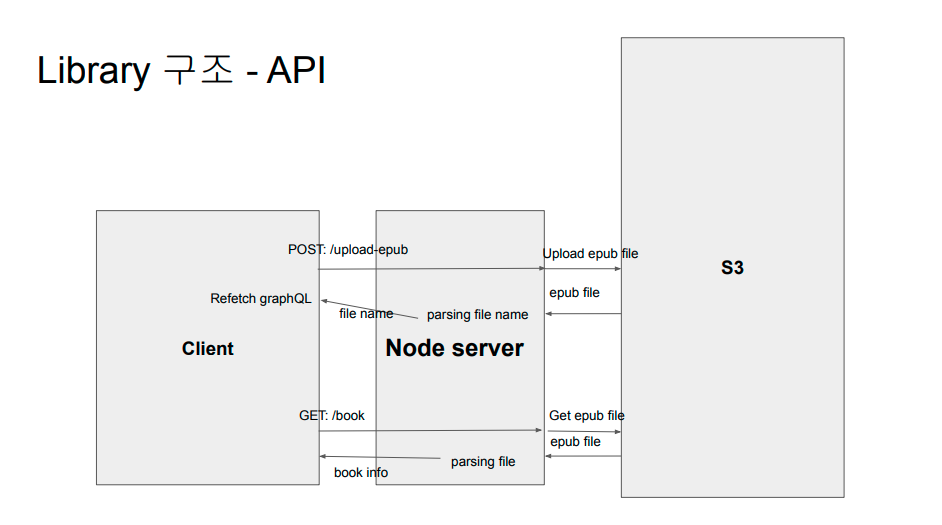
6. Upload epub
위에 그림처럼 당연하게도 epub 파일은 업로드는 s3를 이용하였다. 사용자가 epub파일 업로드 시 s3에 올린뒤, express server에서 가져다가 파일을 압축 해제를 하고 압축이 해제된 파일을 다시 s3에 올려놨다. 그러고 viewer를 띄울 때 viewer에 필요한 파일만 가져와서 프론트로 보내주는 방식을 채택하였다. 기존에는 viewer를 띄울 때 마다 epub파일을 가져와서 압축 해제 하여 보내주었는데, 최초 upload시에만 해제를 하고 viewer를 띄울 때는 이미 해제된 파일에서 필요한것만 넘겨주니 viewer를 띄울 때 속도는 확실히 개선된듯 보였다.
물론 웹이 아니라 모바일이나, 앱일 경우 자체 메모리를 사용하여 epub파일 압축 해제를 진행한다면 api없이도 가져올 수 있으니 훨씬 빠르게 될것 같다. 그래서 웹 뷰어 보다는 앱 뷰어가 있다는 생각이 들었다.
7. 배포
사실 배포는 ec2 를 이용하여 node를 돌릴 수도 있었겠지만 제일 간단하게 heroku를 사용하였다. 원래는 zeit/now를 사용하려고 했는데, 그 당시에는 upload를 생각하고 있지 않아서 프로젝트 내에 epub파일을 static하게 가지고 있었다. 그런데 zeit/now에서는 어떤일인지 노드 서버 쪽에서 static경로로 접근이 잘 안되어서 애를 쫌 먹었었는데, 그래서 바로 heroku로 갈아탔다. 물론 지금은 static경로 접근할 필요가 없어서 zeit/now를 사용해도 괜찮을지도 모르겠다?
결론
이렇게 대략 3주? 정도에 시간을 들여서 RIDI에 온보딩 시스템인 입사자 과제를 완료 하였다. 물론 퍼블리시하게 나가기에는 아직 많이 부족하고 실제 사용되는 서비스에 비하면 정말 기본적인 기능들만 있는 뷰어이지만, 그래도 진행하면서 epub에 대하여 조금 친숙하게 되었고 현재 RIDI가 어떤식으로 뷰어를 렌더링하는 지 알게 되었다. 프로젝트를 진행하면서 궁금한게 있을 때에 팀장님과 사수에게 물어보면서 진행을 하였는데 현재 내가 생각하여 적용한 방식이 실제 RIDI에서도 채택한 방식이라고 이야기를 들었을 때에는 안도의 한숨이 나오기도 하였다. 좋은 방향으로 가고 있구나라고 생각이 들었기 때문이다.
RIDI는 내가 입사한 3번째 회사이지만 (사업 제외) 지금 까지 다녔던 회사들 보다 체계적이고 이런 온보딩 시스템이 새로 입사하는 사람에게 정말 많은 도움이 되는것 같다.
마지막으로 입사자 과제를 진행하면서 전에 다니던 회사에서 개발하였던 react-tree-multi-selector 모듈을 npm 에 올렸는데, 필요시 다운받아서 star 도 조금 올려주셨으면 좋겠다... 이글을 읽으시는 분들은... 호호





안녕하세요!
리디엔 이런 입사자 과제가 있군요! 흥미롭네요
같은 회사인데도 잘 몰랐어요.. ㅋㅋㅋ 아직 개발팀끼리 소통을 많이 못 해서 ㅠㅠ
사무실 이사를 해서 좀 소통을 하게 될 줄 알았는데 코로나 때문에 재택근무하느라 교류하기가 어렵군요
라프텔 팀에서도 이런걸 준비하면 좋을 것 같다는 생각이 드네요!
리디에도 벨로그 사용자가 생기다니 뿌듯합니다. 캬캬
언젠가.. 회사에서 만나요~