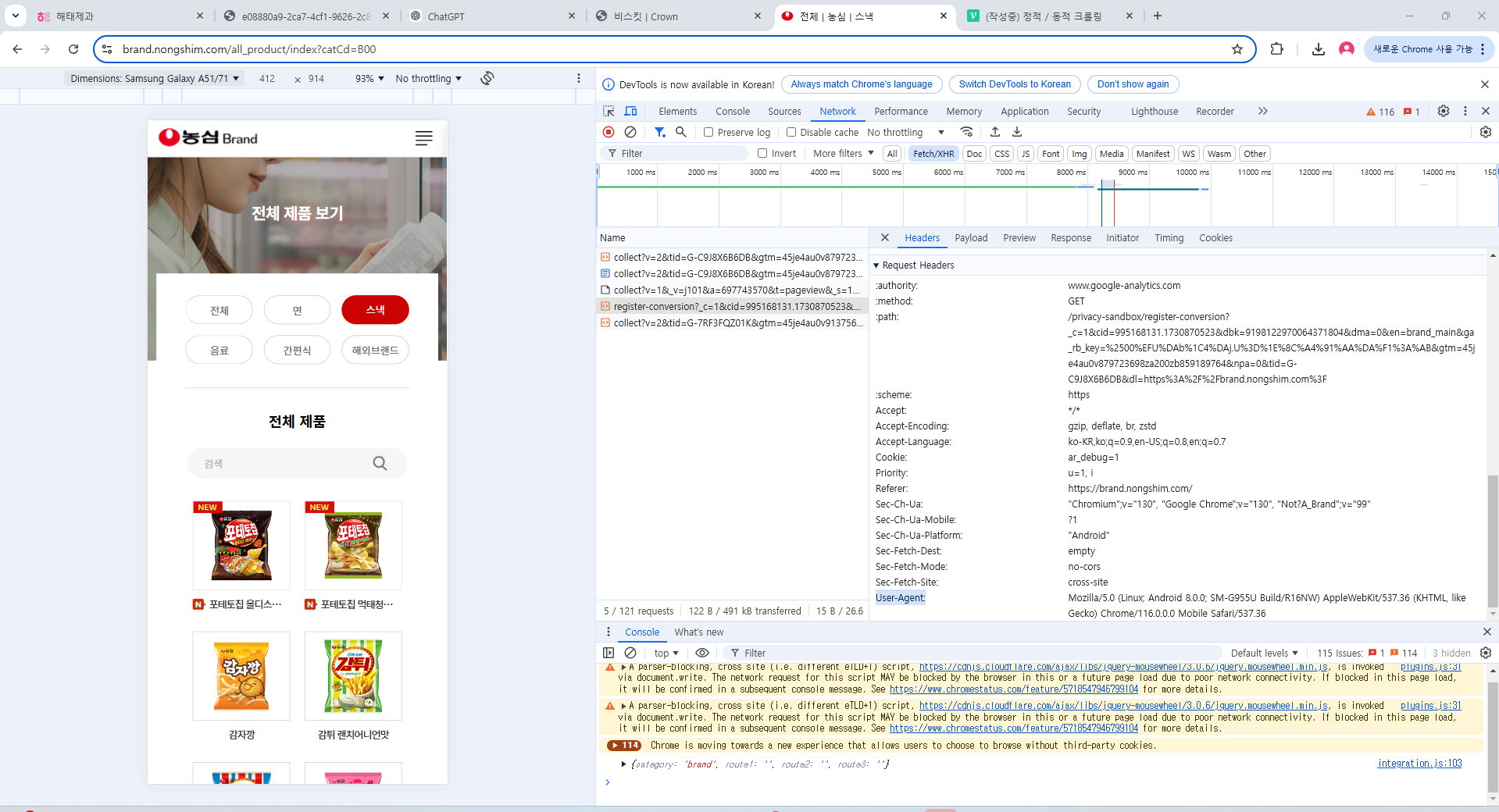
1. 정적크롤링
implementation 'org.jsoup:jsoup:1.18.1'👉 jsoup gradle 추가하기
package org.zerock.crawlingdemo;
import lombok.extern.log4j.Log4j2;
import org.jsoup.nodes.Element;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import javax.net.ssl.SSLContext;
import javax.net.ssl.TrustManager;
import javax.net.ssl.X509TrustManager;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.net.URLConnection;
import java.security.KeyManagementException;
import java.security.NoSuchAlgorithmException;
import java.security.cert.X509Certificate;
@Log4j2
@SpringBootApplication
public class CrawlingDemoApplication {
public static void main(String[] args) throws NoSuchAlgorithmException, KeyManagementException, IOException {
TrustManager[] trustAllCertificates = new TrustManager[]{
new X509TrustManager() {
public X509Certificate[] getAcceptedIssuers() {
return null;
}
public void checkClientTrusted(X509Certificate[] certs, String authType) {
}
public void checkServerTrusted(X509Certificate[] certs, String authType) {
}
}
};
SSLContext sc = SSLContext.getInstance("TLS");
sc.init(null, trustAllCertificates, new java.security.SecureRandom());
SSLContext.setDefault(sc); // 여기까진 고정 SSL 에러 때문에 사용함.
String url = "https://www.lottewellfood.com/brand/product?searchType1=LC400"; // 원하는 주소 넣기
Document doc = Jsoup.connect(url).get(); // jsoup를 통해 doc 정보 가져오기
Elements viewer = doc.select(".clfix img"); // url의 html 코드를 분석해서 img가 포함되어있는 class를 넣고 그 이후 img 적기
for(Element element : viewer) { // 많은 viewer를 for문으로 가져오기
String imgSrcResult = element.attr("src");
// String imgSrcResult = "https://www.orionworld.com/"+imgSrc; // 이건 사진에 따라서 주소창이 안붙을때 별도로 만들어주기. ex) 오리온
log.info(imgSrcResult);
String fileName = imgSrcResult.substring(imgSrcResult.lastIndexOf("/")+1); //
log.info(fileName);
URLConnection urlConnection = new URL(imgSrcResult).openConnection();
// urlConnection.setRequestProperty("User-Agent", "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Mobile Safari/537.36");
InputStream inputStream = urlConnection.getInputStream();
OutputStream outputStream = new FileOutputStream("C:\\snack\\lotte\\"+fileName); // 이미지 부분만 잘라서 가져오기
byte[] buffer = new byte[1024*8]; // buffer를 통해 가져오기
while (true) {
int count = inputStream.read(buffer);
if(count == -1) break;
outputStream.write(buffer, 0, count);
}
outputStream.close();
inputStream.close();
log.info(inputStream.toString());
}
}
}👉 urlConnection.setRequestProperty("User-Agent", "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Mobile Safari/537.36");
해당코드는 401에러가 떠서 권한이 없을때 아래사진 처럼 해당영역을 복사하여 작성해야하는데, 이는 우리가 브라우저라고 속이기 위함이다.
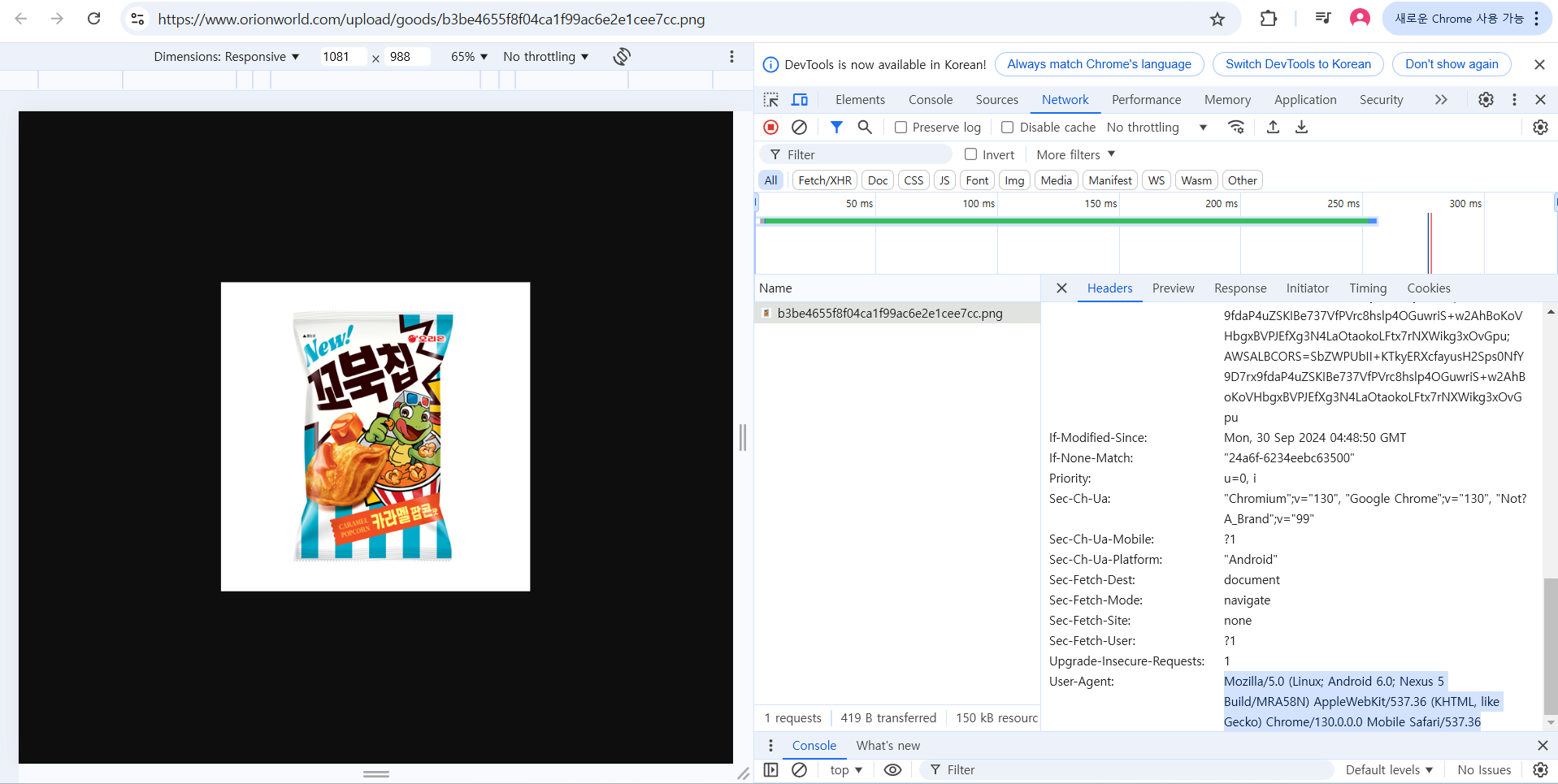
👉 현재 몇몇의 사이트는 정적크롤링을 통해서 사진을 가져왔지만 동적크롤링이 필요한 해태제과는 셀레늄을 사용하여 가져와야한다.
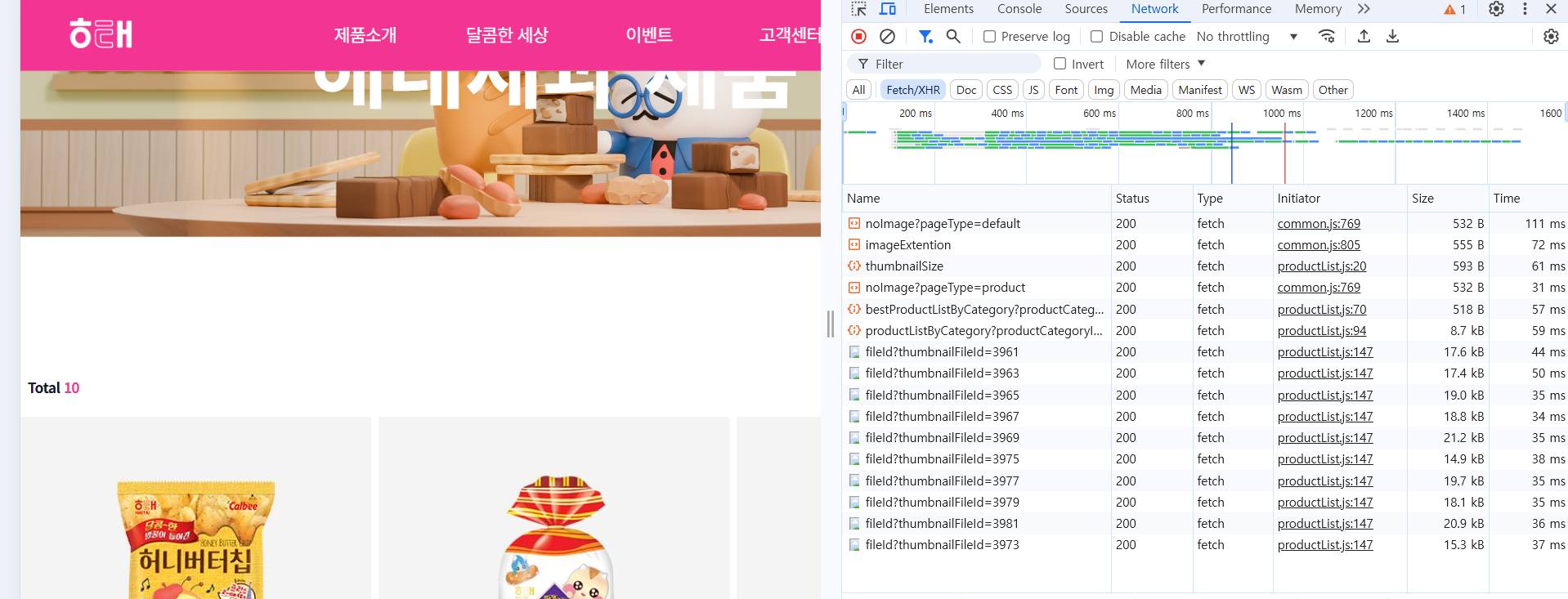
👉 동적으로 사진을 가져오는것이므로 정적크롤링이 불가능함.
2. 동적크롤링
👉 동적크롤링을 하기위해 셀레늄이 필요한 이유는 js를 통해서 지속적으로 브라우저가 변경되므로, JavaScript의 변경 이후의 값을 얻을수있다. 하지만 이때 사용자의 제어가 불가능하므로 코드를 통해서 복사를 해줘야함.
셀레늄의 driver.get을 통해 해당 웹사이트로 이동하여, 원하는 이미지가 있는 cssSelector부분의 클래스, id값을 넣어서 img를 추출하는 방법을 사용해야한다.
- gradle 추가
implementation 'org.seleniumhq.selenium:selenium-java:4.25.0'- chromeDriver setting
해당 크롬 버전에 따른 drvier를 설치해줘야함.
나는 해당 driver.exe파일이 c드라이브의 vhromedriver-win64 폴더 내부에 있음.
- code
package org.zerock.crawlingdemo;
import lombok.extern.log4j.Log4j2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
@Log4j2
public class CrawlingS {
private static WebDriver driver;
private static String url = "https://brand.nongshim.com/all_product/index?catCd=B00";
public static void main(String[] args) throws Exception {
// 크롬 드라이버 경로 설정 (필요한 경우 경로를 설정)
System.setProperty("webdriver.chrome.driver", "C:\\chromedriver-win64\\chromedriver.exe");
// 두번째 해당경로를 드라이버가 있는쪽의 경로로 설정한다.
driver = new ChromeDriver();
// 셀레늄의 driver객체를 생성
try {
getImageList();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 드라이버 종료
driver.quit();
}
private static void getImageList() throws InterruptedException, IOException {
driver.get(url); // 웹사이트로 이동
Thread.sleep(3000); // 페이지 로딩 완료 대기 (자바스크립트 동적 로딩 시간 확보)
// 이미지 URL을 담을 리스트 생성
List<String> imageUrls = new ArrayList<>();
// 페이지에서 모든 이미지 태그를 찾기
List<WebElement> images = driver.findElements(By.cssSelector(".contlist img"));
// cssSelector에다가 원하는 이미지의 상위class혹은 id값을 넣어주고, 한자리 띄우고 img를 넣어준다.
for (WebElement image : images) {
String imgSrc = image.getAttribute("src"); // 이미지의 src 속성 값 (URL) 추출
if (imgSrc != null && !imgSrc.isEmpty()) {
log.info("Found image URL: " + imgSrc);
imageUrls.add(imgSrc);
}
// 최종적으로 크롤링한 이미지 URL 출력
log.info("Total images found: " + imageUrls.size());
String fileName = imgSrc.substring(imgSrc.lastIndexOf("/")+1);
log.info(fileName);
URLConnection urlConnection = new URL(imgSrc).openConnection();
urlConnection.setRequestProperty("User-Agent", "Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36");
// 해당코드는 지워도되는데, 만약 403에러가 뜬다면 헤당 페이지에 대한 네트워크의 user-agent: 값을 넣어줘야함.
InputStream inputStream = urlConnection.getInputStream();
OutputStream outputStream = new FileOutputStream("C:\\snack\\nongshim\\"+fileName); // 이미지 부분만 잘라서 가져오기
byte[] buffer = new byte[1024*8]; // buffer를 통해 가져오기
while (true) {
int count = inputStream.read(buffer);
if(count == -1) break;
outputStream.write(buffer, 0, count);
}
outputStream.close();
inputStream.close();
log.info(inputStream.toString());
}
}
}
- user-agent