Search Process?
수업을 들었던 내용을 바탕으로 포스팅 하는 것이라 내용에는 한계가 있을 것이다.
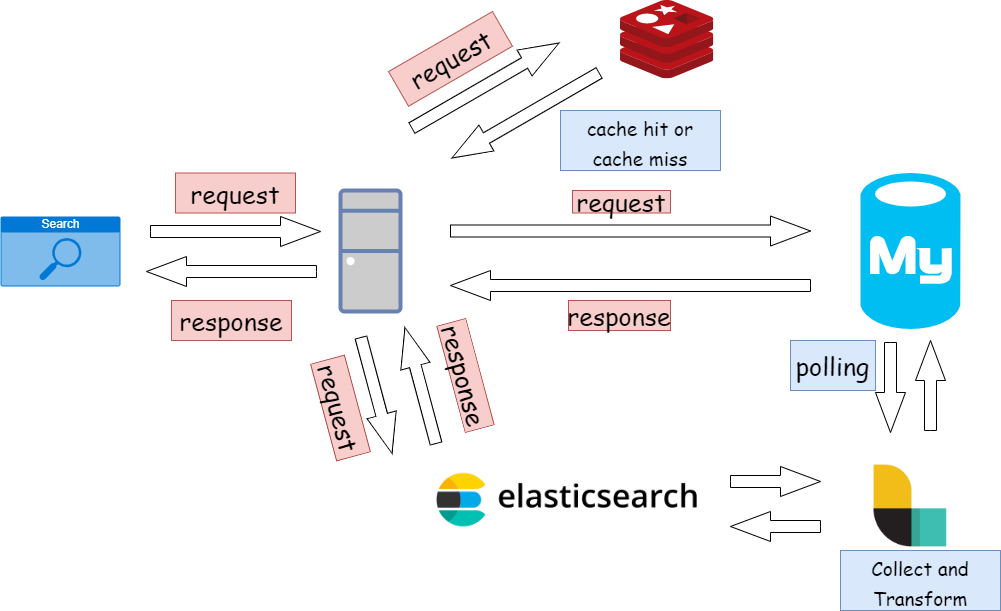
위 그림은 수업 때 배운 것을 바탕으로 Search process 를 그림으로 그리것이다.
순서
- frontend에서 request.
2-1. redis 라는 cache 메모리에 request.
2-2. 있을 경우 cache hit로 결과값 frontend에 response.
2-3. 없을 경우 elastic search에서 request. - elastic search에서 받은 결과값을 redis에 저장
->다음 요청이 있을 경우 빠른 redis로 결과값 반환. - 결과값을 frontend에 response.
이와 별개로 데이터 저장과정은 다음과 같다고 한다.
1. frontend에서 data save 요청
2. Mysql DB에 저장
3. Logstash는 지정된 세팅 값이나 시간에 DB내용을 elastic search에 저장.
대략적인 Search Process는 위와 같다.
왜 redis, elastic search를 사용하는가?
결론부터 말하자면 속도 때문이라고 한다.
Mysql에서도 검색을 지원한다. 우선 다른 방식도 많겠지만 일단 1차원 적으로 접근해 보겠다. Select * from tablename where~ 과 같이 내용이 'apple' 단어가 포함되어 있는 게시물을 찾는다면, 1번부터 마지막 번호까지 해당 조건이 포함된 게시물을 찾을 것이다. 하나씩 하나씩 확인하면서 말이다.
물론 컴퓨터가 하는일이라 빠르겠지만 수 만명이 동시에 이용 할 수도 있는 웹 환경에서 작은 지연 시간들이라도 쌓이다보면 1분, 10분 이상이 될 수 도 있을 것이다. 그리고 서비스 문제로 연결 될 수 있는 일이다.
그렇다면 검색속도를 높일 수 있는 방법은 무엇일까? 방법 중 한 가지는 index(색인) 방법이라고 한다.
Mysql에서 2번 게시물 내용에 'apple'이라는 내용이 있다면, 조건에 'apple'을 올려서 찾는 것보다 당연하겠지만 2번 게시물을 찾아 달라는 요청을 하면 훨씬 빠를 것이다.
inverted index?
한 단계 더 나아가서 게시물 내용 중 단어별로 나누어서 그 단어를 게시물 번호와 연결 시킨다면, 단어별 검색할 때 빠를 것이다. 처음부터 찾는 것이 아닌 단어와 연관된 게시물 번호인 주소만 참조 하여 결과를 보여주면 되는 것이기 때문이다.
이것을 inverted index(역색인)이라고 한다. 책에서 앞에 목차가 있다면, 뒤에는 단어별로 찾아보기가 나와 있을 것이다. 이것이 역색인과 같은 것이다.
Elastic Search 이런 역색인으로 저장하는 DB 라고 한다.
마치면서
사실 자료 사진이라던가 직접 실습했던 내용을 올려야 더욱 전달이 잘 되었을 것이다ㅠ. 또한 Text analysis같은 내용도 추적으로 포스팅했다면 말이다...이쯤에서 마무리 하는 것으로...
참조
[[Elasticsearch] 기본 개념잡기, tistory, 2022년05월04일 접속]
https://victorydntmd.tistory.com/308
