질문
- 병목현상이란?
- 병목현상의 원인?
- 해결방법 몇가지
- 프로젝트 중 관련 경험이 있는지?
병목현상 이란?
- 시스템 내에서 전체적인 처리 속도를 떨어뜨리게 되는 특정한 부분을 가리키는 용어
- 시스템의 CPU나 메모리, 디스크 등의 자원 중 하나가 다른 자원들에 비해 처리 속도가 느려서, 전체적인 성능을 제한하는 경우를 말함
- 효율적인 자원분배 및 최적화를 고려해야함
원인
- 네트워크 대역폭 부족
- 하드웨어 자원 부족
- 어플리케이션 설계 문제
- 데이터베이스 부하
해결
Throughput(처리율) 개선
-
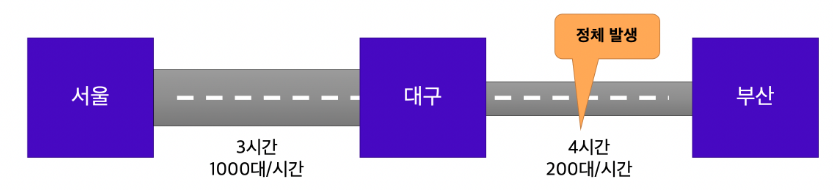
시스템의 흐름을 고속도로에 비유해보자
-
대구와 부산 사이에 병목현상이 발생하고 있다.
-
통행량을 늘려 병목현상을 해결한다.
-
처리량에 대해서 네트워크 대역폭이나 부족한 자원을 증가시켜 처리할 수 있다.
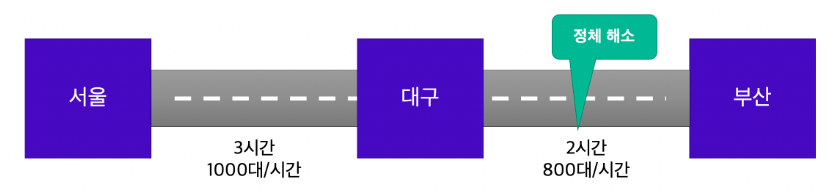
Throughtput의 개선이 Latency 개선으로 이어진다. '대기 시간'에 문제가 있었기 때문
Latency(지연시간) 개선
어플이케이션 개선
-
Latency 개선은 어플리케이션을 개선하는 것으로 시작
-
어플리케이션 성능 최적화는 현상을 파악 (Application Performance Monitoring) 하는 것으로 시작
-
알고리즘 개선, I/O 최소화 등의 개선 방안이 뒤따름
-
DevOps가 이를 모니터링 할 수 있으나 개발자가 APM 도구와 프로파일러 등을 이용해 이를 개선
응답 성능의 병목 원인과 대책
-
많은 사용자의 서비스 등록
-
많은 데이터의 저장1,2번과 같은 경우 DB에 데이터가 증가합니다.
-> secondary 복제본 등을 이용해 읽기/쓰기를 분리하거나, 검색에 최적화된 인덱스 사용을 고려할 수 있습니다. -
단기간 동안의 사용자 요청 증가(peak traffic)
-> Auto Scaling이 해결책이 될 수 있습니다. 다만 버스트 성능에 대해 이해해야 합니다. -
배치 작업을 진행하는 데이터베이스
-> DB가 주기적으로 스냅샷을 만들거나, 데이터 일관성을 위해 레플리카와의 sync 과정을 진행하는 등의 배치 작업이 이루어질 경우, primary DB는 성능 저하가 발생할 수 있습니다. 이 때 사용자들의 요청과 맞물려 서비스 수준을 맞추기 어려울 수 있습니다. -
많은 양의 로그 수집 처리
-> 애플리케이션이 잘 작동할 때에는 로그를 많이 남기지 않지만, 애플리케이션에 문제가 발생하면 추적을 위해 많은 로그를 남깁니다. 다만 이러한 상황이 반복적으로 진행될 경우, 에러 로그 수집 그 자체가 애플리케이션 병목을 일으킬 수 있습니다. -
시스템 재시작 후의 캐시 초기화
-> 큰 문제를 발생시키는 것은 아니지만, 캐시가 초기화되면서 시스템으로 직접적인 요청 횟수가 증가할 수 있습니다.
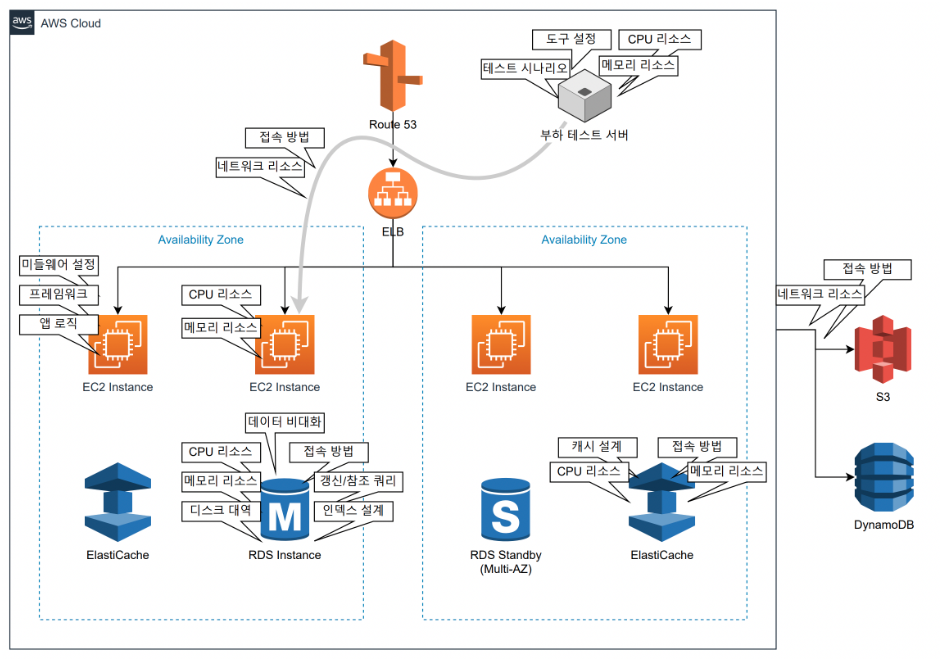
AWS 주요 병목 구간 & 부하 테스트 시 고려 할 부분