
2주차 회고
1주차에 이어서 벌써 2주차 회고를 쓸 시간이 왔습니다. 시간이 엄청 빠르게 지나갑니다.
이번 주차 회고록은 좀 간결하게 진행해볼까 합니다. 길게 문장을 나열해서 더 좋은 것도 없고, 필요한 내용과 저의 생각만 들어가도 충분한 회고가 될 것 같기 때문입니다.
기획 구체화
단순히 피드 시스템으로 주제를 잡은 것에서, 좀 더 현실성있게 구성하기 위해서는 우리만의 구체적인 주제가 있어야 할 것 같다고 생각했습니다.
그렇게 나온 주제는
해시태그 기반 맛집 피드 서비스
입니다.
우리의 목적은 이제 아침, 점심, 저녁의 식사시간에 몰려오는 트래픽을 감당하고, 안정적으로 운영할 수 있는 아키텍처를 구성하는 것이 되었습니다.
아키텍처 변경사항
1주차에 이어서 아키텍처를 또 변경했습니다.
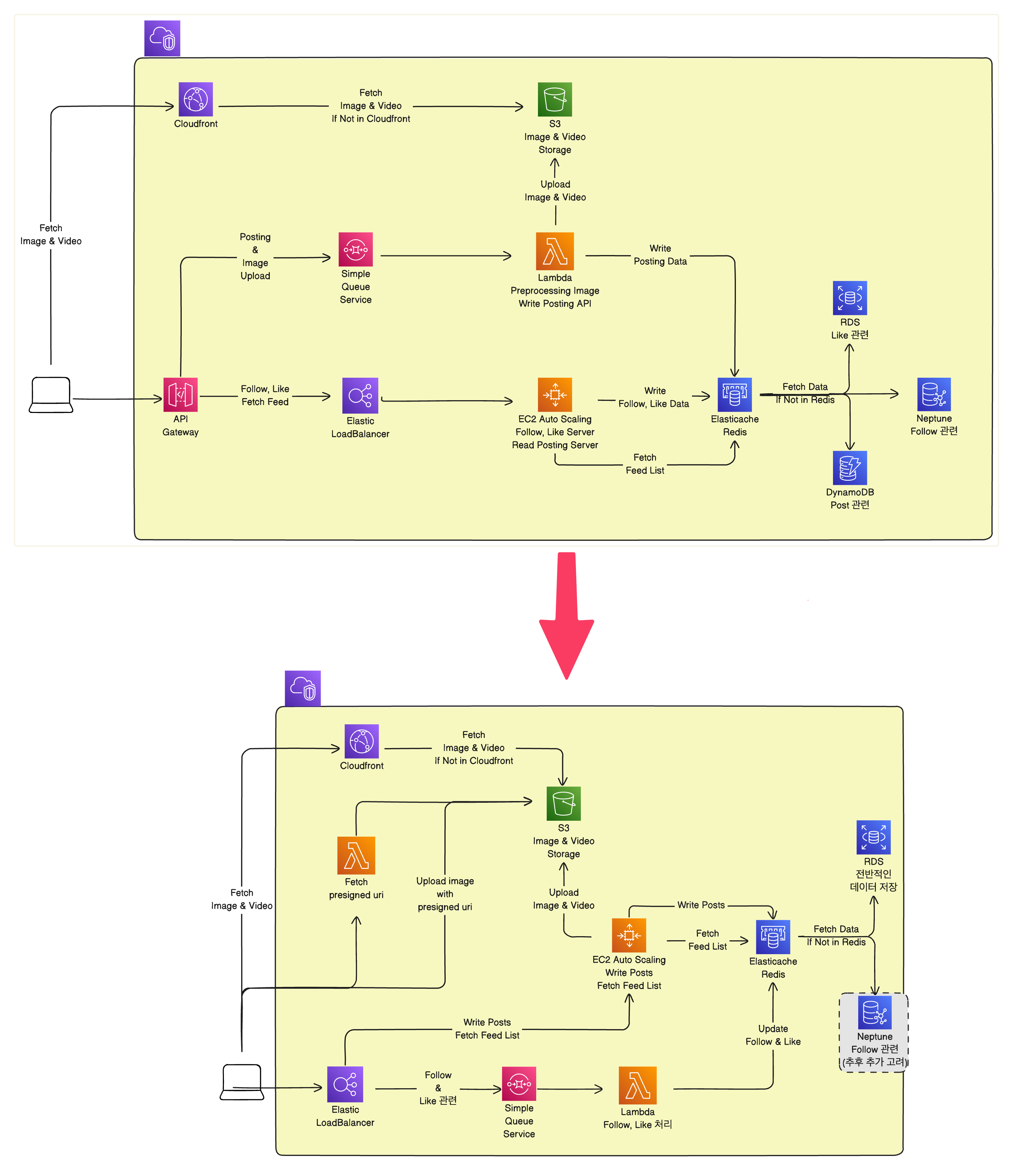
요렇게 말이죠! 약간 간소화 된 것 같으면서도 구성이 좀 바뀌었습니다.
- API Gateway가 사라졌습니다.
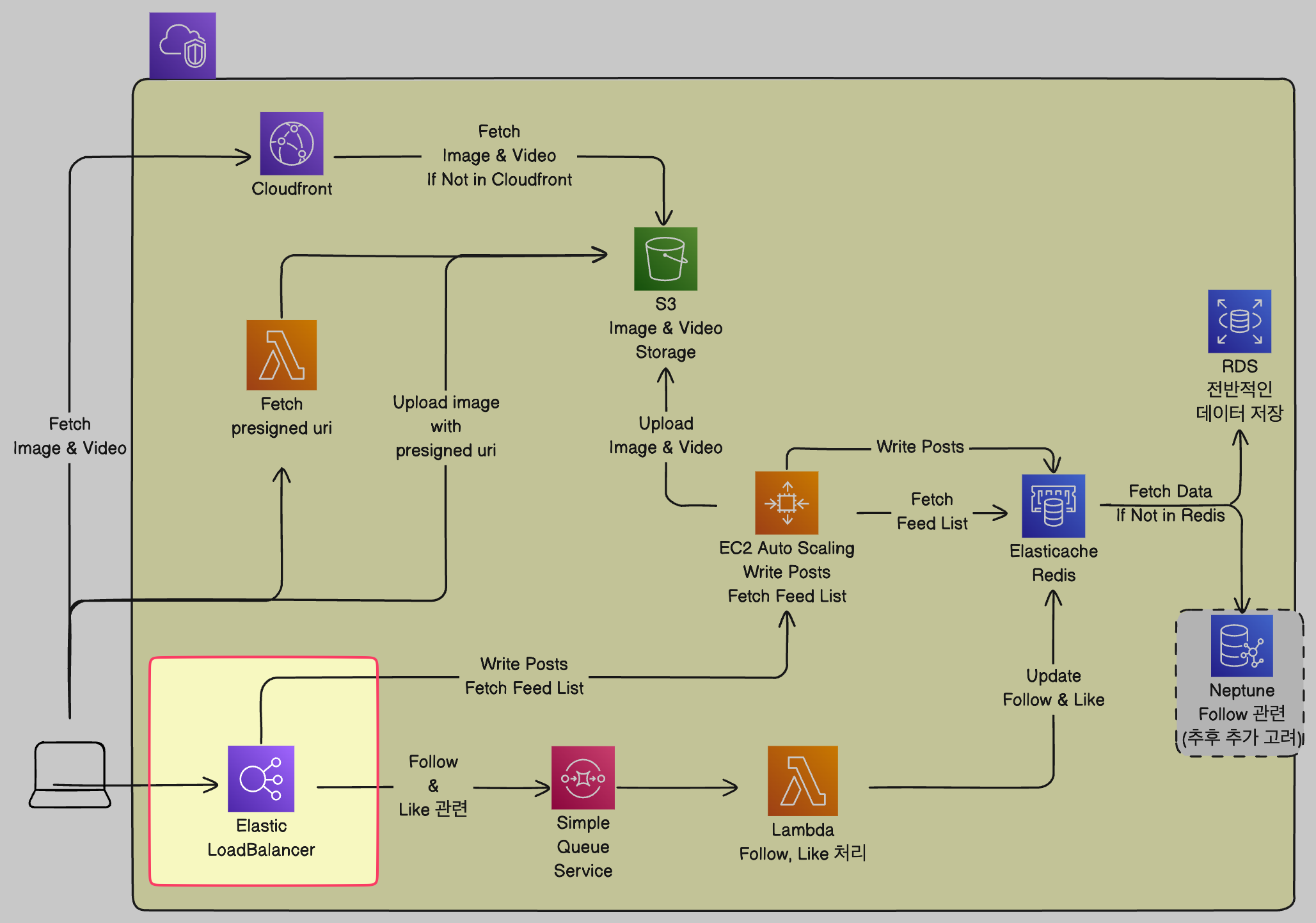
저는 프로젝트를 할 때 API Gateway만 사용해보고 LoadBalancer는 사용해본 적이 없습니다. 따라서 LoadBalancer는 단순히 부하를 나누는 역할을 한다고 생각을 하고 있었죠.
멘토님의 조언으로 ALB(Application LoadBalancer)를 사용하게 된다면 부하를 나누는 것 뿐만 아니라 Path 기반 규칙을 통해 API Gateway의 역할도 할 수 있다는 것을 알았습니다!
(API Gateway는 회사에서 사용해본적이 없다고도...)
- Posting 과정에서 Lambda를 사용하였는데, 이를 좀 분리하여 이미지 업로드 부분에서 Lambda를 사용하는 것으로 변경하였습니다.
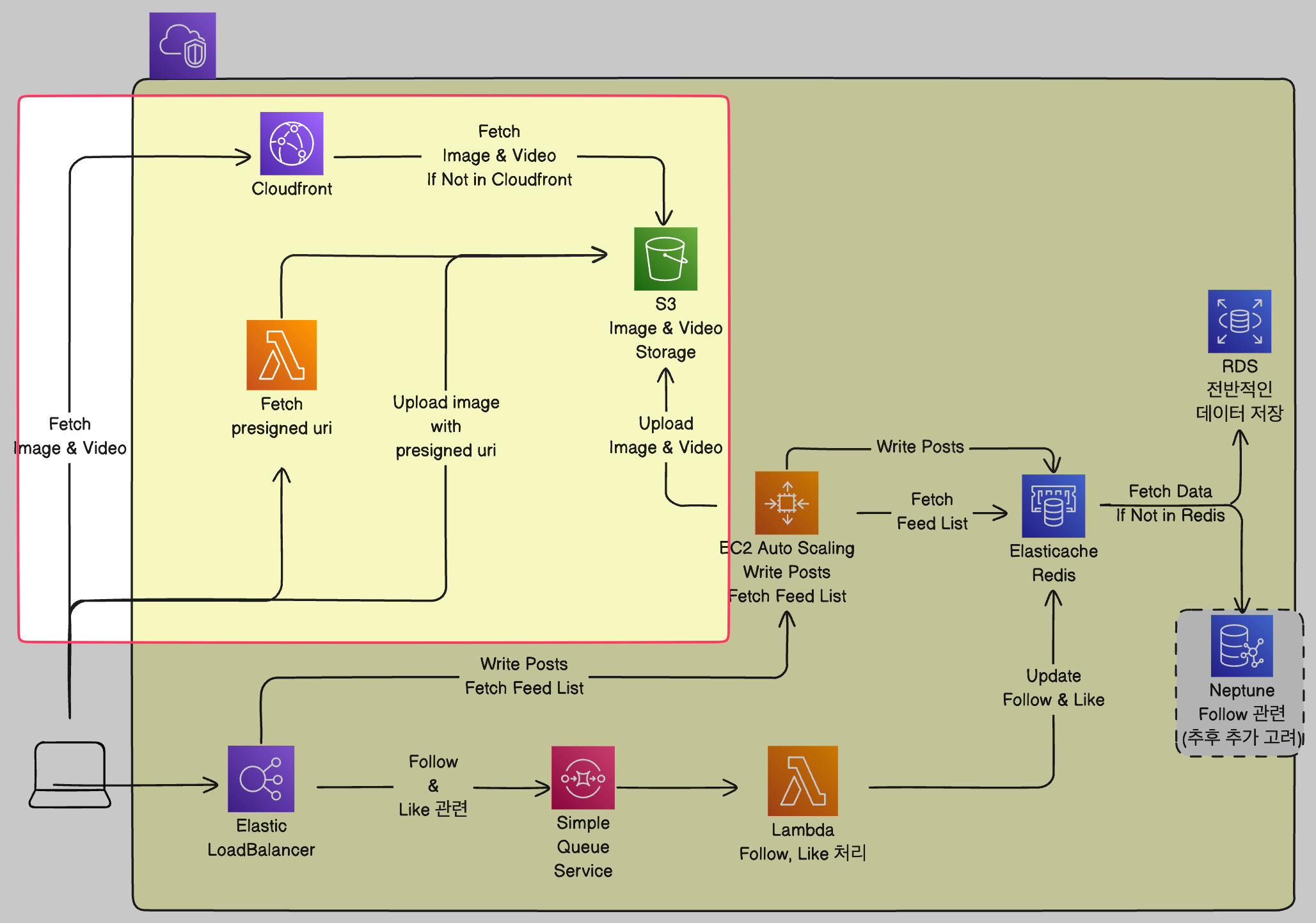
기존에 Posting을 모두 Lambda에 책임을 맡겼는데, 이는 비용을 줄이기 위해 들어온 이미지를 모두 1MB정도의 크기로 리사이징하여 S3에 업로드 하는 전처리를 위해서 두었던 것이었습니다.
여기서 또 멘토님의 조언이 도움이 되었는데, 현업에서는 이미지를 업로드된 그대로 저장한다는 것이었습니다.
그 이유는 기존 이미지에서 원하는 크기로 줄이는 것은 쉽지만, 이미 줄어든 이미지를 늘리는 것은 퀄리티에 큰 문제가 생긴다는 것이었는데요.
현재 해커톤에서는 이미지 퀄리티로 발생할 수 있는 문제는 없지만, 이를 실제 비즈니스로 생각한다면 미래에 원본 이미지가 필요할 수도 있기 때문에 저희도 해당 의견을 수용하여 리자이징 과정을 없애기로 하였습니다.
(사실 이게 비용 절감의 한 측면으로 말 할 수 있을 것 같았는데... 아니었다는 점!)
그래서 Presigned Uri 방식으로 이미지를 업로드하기로 하였습니다. 그 이유는 이미지를 서버로 거치고 넘어가는 것은 서버의 네트워크 I/O 트래픽이 증가할 수 있기 때문입니다. 프론트에 책임을 전가한다면 해당 트래픽을 줄일 수 있어 좀 더 안정적인 서버 운영도 가능할 것이라 생각했습니다. (람다에서 처리해도 이미지 업로드에 드는 시간을 줄일 수 있다고 생각했습니다.)
이미지 업로드는 Lambda로 Presigned Uri를 전달하고, 나머지 Post 작성은 업로드한 이미지의 uri와 함께 Ec2 서버에서 받아서 처리하는 것으로 정하였습니다.
-
Lambda를 Follow, Like를 처리하는데에 이용하기로 했습니다.
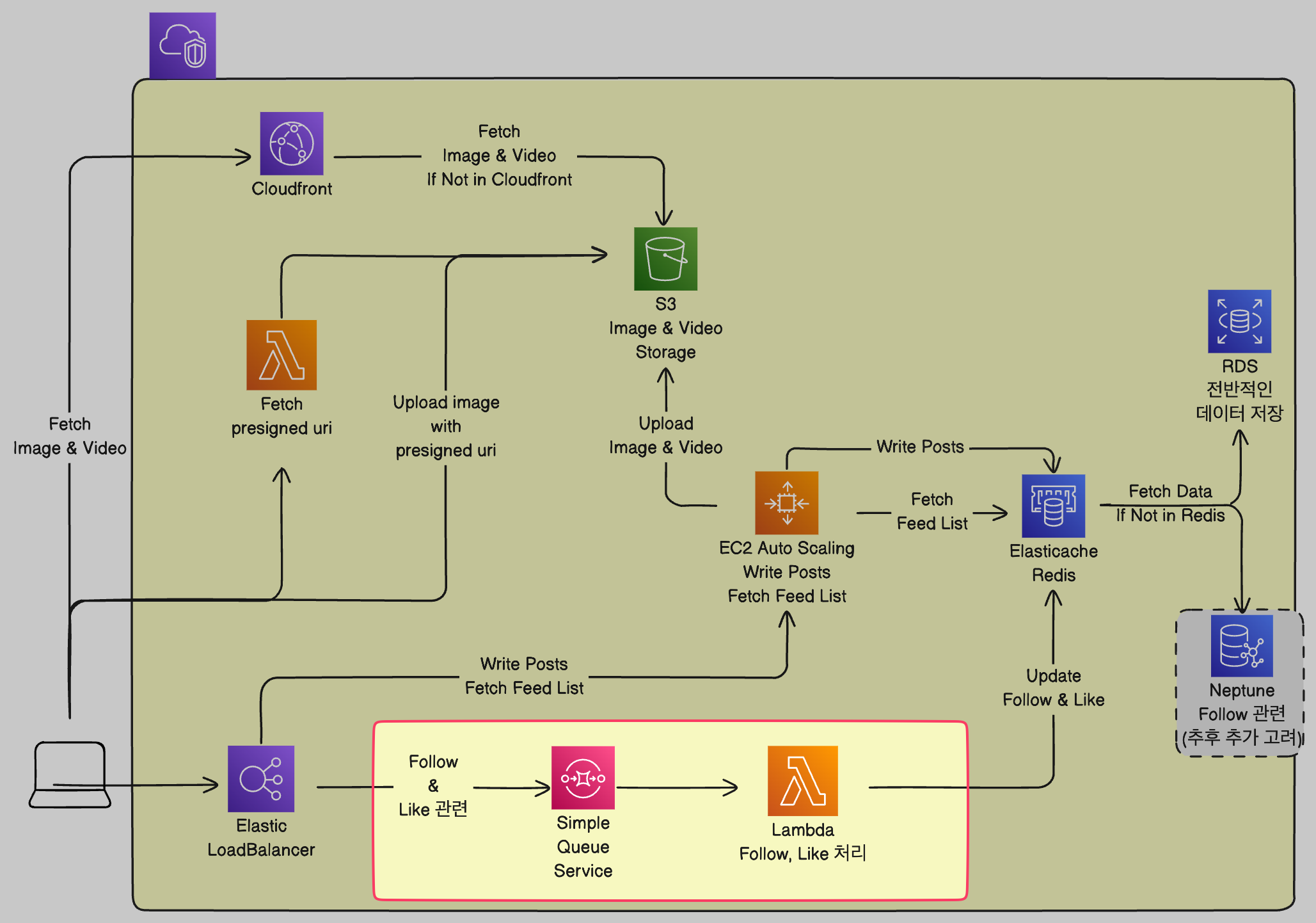
저는 항상 가지고 있던 생각이, "Lambda는 비용이 싸니까! 쓸 수 있으면 최대한 쓰는게 좋은 것 같다!" 였습니다. 당연히 이번에도 같은 생각이었고, 기존에 Post 업로드에서 사용하던 람다가 이미지 uri 반환 기능만을 가지게 되었으니... 좀 더 Lambda에 많은 책임을 할당할 수 있지 않을까 생각했습니다.
그래서 생각한게 Follow, Like같은 관계를 나타내는 것을 Lambda로 처리하자! 라는 거였는데요. 제가 생각하기엔 이 두가지 종류는 사용자에게 바로 반환되지 않았을 때 큰 영향을 끼칠 것 같지 않았습니다. (Follow는 영향이 갈 수도 있을 것 같지만... 뭐 업데이트하는데 시간이 좀 걸린다! 하면 되는 것 아닐까요?)
그래서 SQS를 두고 비동기로 처리하자는 결론에 이릅니다. 사용자가 요청을 남기면 일단 응답을 하고 이후에 처리하는 것이죠.
(실패했을 때 Follow같은 경우에는 문제가 될 수 있을 것 같지만... 나중에 알림 기능을 추가한다거나 하면 되겠죠 뭐...ㅎㅎ)이번 해커톤에서 하루 평균 활성 사용자는 1000명으로 잡으라고 안내가 내려왔습니다. 우리 팀은 자체적으로 10000명까지 늘리기도 했죠.
그리고 람다가 한번에 만들 수 있는 컨테이너의 수는 총 1000개입니다. 여기서 저는 생각했죠. "1000개의 컨테이너라면 Like, Follow Presigned Uri를 모두 처리한다고 해도 SQS에 대기열이 많이 쌓이지는 않을 것이다."라고요
10000명이 하루에 사용한다고 하면, 우리 기획의 특성상 맛집 리뷰 피드 시스템이기 때문에 점심시간에 많이 몰릴겁니다. (아침, 저녁도 있겠지만.. 상대적으로 점심이... 더 많은 사람이 찾을겁니다.) 이 때 사용자들이 몰려서 1분에 5000개의 람다 요청이 생긴다면, 과연 잘 처리할 수 있을까 생각했습니다.
하나의 람다에서 follow, like를 처리하는 과정은 단순히 redis에 값을 삽입하는 것으로 끝납니다. 나머지는 Batch를 통해 RDS에서 반영하죠. 이 과정은 아무리 길어봐야 (Cold Start를 고려해도) 10초를 넘기지 않을 것이라고 생각했습니다. (일반적으로 람다에서 DB에 접근하고 처리하는 과정은 5초 내로 끝나기 때문에.. - redis라면 더 빠를 것이고..)
그래서 1분에 5000개가 몰린다 해도 해당 1분 내에 모든 처리가 끝날 것이라고 생각했습니다. 1000개의 컨테이너면 이 3가지의 기능을 모두 수월하게 처리할 수 있다는 판단을 한 것이죠.그래서 이렇게 SQS에 Lambda를 물린 방식을 사용하여 Follow, Like를 사용하게 되었습니다. (Presigned uri도 SQS에 물려야 할 것 같기도 하지만... 비동기 처리를 하더라도, 이 요청은 프론트에서 처리 결과를 받아야하기 때문에... 좀 더 고민해봐야할 것 같습니다.)
-
DB의 종류를 축소하여 RDS, Redis만 사용합니다. (일단은)
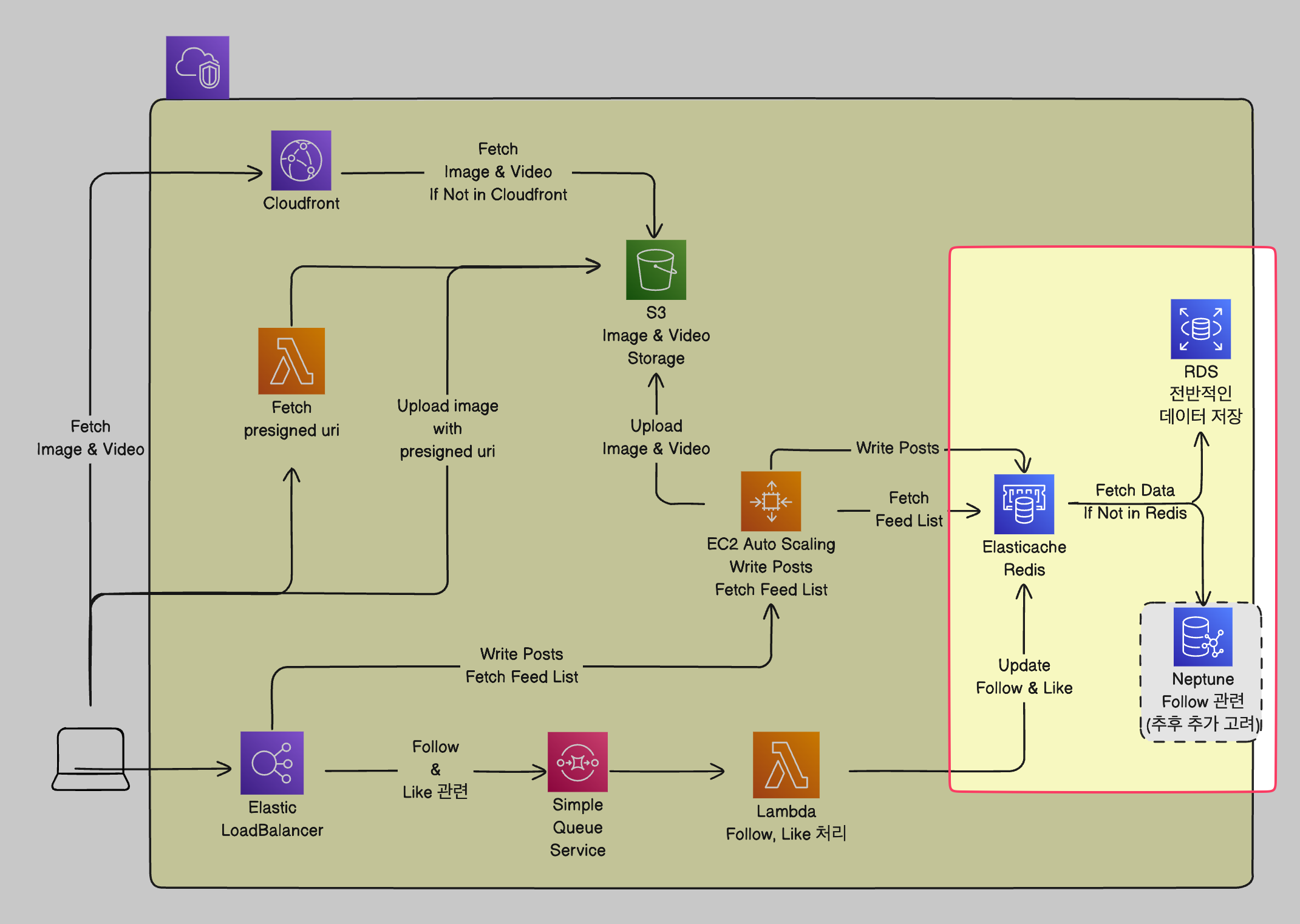
기존에는 DynamoDB, Neptune까지 해서 이것저것 다 써버린다고 했었는데, 다 컷 당했습니다.
그 이유는 1000~10000명 규모에서는 RDS로도 매우 빠른 속도의 응답을 받을 수 있다는 판단 때문입니다.
멘토님께서 조언을 해주셨습니다. "RDS와 DynamoDB를 왜 같이 쓰냐? 그러면 DynamoDB가 아무리 싸다고 해도 RDS만 쓰는것보다 비용이 더 나올텐데." 라고말이죠.
저번 주차에는 정확한 규모를 알려주지 않아 100만명으로 잡고 진행했었는데, 그때 이후로 규모가 축소되고 굳이 필요없어진겁니다. (DynamoDB가 싸다는 인식에 매몰되어 있었던 겁니다. - 이래서 외부인의 시선으로 봐야 냉정한 피드백이 가능하다는 거죠...) 그래서 저희 모두 매몰되어있었다는 것을 깨닫고 RDS만 쓰는 것으로 줄였습니다.
이외에도 DynamoDB는 키 설계를 매우 잘 해야 사용하기 편한 DB이며, RCU, WCU의 단위도 존재해서 큰 데이터를 불러올 때 비용이 2번씩, 3번씩 발생할 수도 있다는 단점도 있긴 하지만... 저 매몰된 인식에서 벗어난게 DynamoDB를 놓게 된 가장 큰 이유입니다.Neptune도 마찬가지로 RDS로 대체가 가능하기 때문에 포기하게 되었습니다. Neptune은 RDS처럼 서버를 대여해서 사용하는 온디멘드 방식이라 비용이 RDS만 사용했을 때보다 같이 쓰면 2배가 되어버리는 마술을 부릴 수도 있기 때문에 포기했습니다.
하지만 추후 추가 고려라고 두었는데, 이는 그래프 데이터베이스라는 종류를 경험해보고싶은 학습욕구 때문입니다. 저는 Neo4J를 몇 년 전에 사용해보았지만, 일반적으로는 사용해볼 기회가 별로 없기 때문에 이번 기회에 접해본다는 팀원들의 욕구가 반영되었습니다.그래서 Redis와 RDS 이렇게 두개로 구성하게 되었습니다.
Redis의 경우에는 RDS로 모두 처리가 가능하지만 둔 이유는 해커톤 안내에서 ElastiCache를 적극 활용해달라는 내용이 있었으며, RDS보다 짧은 시간에 많은 요청을 처리할 수 있는 장점이 있으며 (이정도 규모에서는 큰 차이가 없을지도 모르지만), 가장 작은 사이즈의 서버로 구성해도 저희가 캐시로 넣고싶어하는 데이터는 다 넣을 수 있을 것 같기 때문입니다. (그러니 있는게 좋을 것 같다... + 학습욕구도 매우 크긴 합니다)
이렇게 아키텍처는 수정되었고, 아마 해커톤 당일까지 또 수정될 수도 있을 것 같지만... 점점 더 완성도가 높아지고 있다는 생각이 듭니다. (더불어 지식도 많이 늘어가는중...)
마무리
이렇게 2주차는 아키텍처 구체화를 중심으로 마무리 되었습니다.
실제로는 ERD도 구성하고, API 명세도 작성했지만... 아키텍처를 주제에 맞추어 사용하기 위한 보조 역할이 더 강한 것 같아 생략했습니다.
이제 마지막 한주가 남았는데, 이 기간동안 많은것을 배우고 더욱 성장할 수 있었으면 좋겠습니다.
KPT 회고
Keep
- 항상 무언가를 적용할 때 구체적인 이유를 댈 수 있도록 이해하는 것
- 적극적으로 회의에 참가하고 활동하는 것
- 항상 배우려는 자세로 모든 사람의 의견에 경청하는 것
Problem
- 좀 더 구체적인 비용 계산이 필요해보임
- 캐시에 데이터를 넣을 때 구체적으로 어느정도의 메모리를 차지할지 마찬가지로 계산이 필요해보임
- 이전 프로젝트(토론티어)에서의 문제였던 기획에 너무 깊이 들어가서 정작 실제 구현은 늦어지는게 약간 보임
Try
- AWS 비용 계산기를 통해 실제로 어느정도의 비용이 발생할지, 기존 아키텍처에서 수정된 아키텍처를 사용한다면 어느정도의 예산 세이브가 가능할지 테스트해보기
- 캐시에 넣을 엔티티를 모두 구성해보고, TTL을 고려했을 때 몇 개의 데이터가 저장될지, 그게 총 몇 MB인지 계산해보기
- 빠른 개발을 시작하고, 피드백과 개선을 오래 가져가기
(07.28. 현재 개발 진행중)
