서론
저는 지금 "티끌"이라고 하는 프로젝트 팀에서 백엔드 개발을 도맡아 하고있습니다. 아마 이번주나 다음주 중으로 배포를 진행할 것으로 보이는데요. 몇 주 전에 했던 고민에 대해서 분석해보고, 결론을 내린 과정을 서술하고자 합니다.
고민상황
저희 서비스는 현재 크게 두 가지 기능을 준비하고 있습니다. 대학교 공지 통합 제공과 채용공고 통합 제공이 바로 그 기능입니다. 그 중 채용공고를 제공하는 상황에서 고민이 생겼습니다.
아래 이미지가 바로 저희가 제공하려는 채용공고의 일부인데요. 이 화면에서 채용공고에 관련된 문자 데이터들도 많지만, 회사의 로고도 반환해야한다는 것이 저희가 고민을 하게 된 부분입니다.

채용공고에 나타나는 회사의 로고는 저희 서비스 내 S3에서 가지고 있는것도 많지만, 회사의 수가 엄청나게 많기 때문에 모든 회사의 로고를 채용공고를 제공할 때 제때 가지고 반환해줄 수는 없었습니다. 그리고 수집해야하는 회사 로고의 정보를 가지고 있어야하죠. 그래서 발생한 요구사항은 다음과 같습니다.
채용공고를 반환할 때 회사 로고가 있는지를 확인하고, 없으면 수집해야한다는 정보를 남긴다.
채용공고 데이터를 가져올 때 해당 데이터의 존재 여부를 판단할 수도 있겠지만, 우선 백엔드에서 가능할지 한번 테스트를 해보기로 했습니다.
테스트
그러면 기존에 존재하던 채용공고 조회 API에서 추가해서 확인해야하는 기능은 다음과 같습니다.
- boto3를 사용해서 S3에 해당 파일들이 있는지 파악한다.
- S3에 해당 파일이 없다면 수집해야하는 회사 로고의 정보를 저장하는 람다를 실행한다.
이 두 절차를 거치지만, 1번을 실행한 후 2번을 실행하기 때문에 우선 1번부터 추가해서 얼마나 걸리는지 시간을 측정해보기로 합니다.
준비
# s3에서 해당 파일이 있는지 확인
def check_prefix_exists(path):
s3_client = boto3.client('s3')
try:
logger.info("try: " + path)
res = s3_client.head_object(Bucket=BUCKET_NAME, Key=path)
logger.info(f"Object exists: {path}")
return path, True
except ClientError as e:
if e.response['Error']['Code'] == '404':
logger.info(f"Object does not exist: {path}")
return path, False
else:
logger.error(f"Error checking {path}: {e}")
return path, None
# 비동기 처리
def check_multiple_prefixes(paths):
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
results = list(executor.map(check_prefix_exists, paths))
return dict(results)다음처럼 함수를 준비했습니다.
S3에 파일이 존재하는지 확인하기 위해서 Boto3를 이용하기로 했는데요. 명령어의 목록은 여기에서 확인할 수 있습니다.
파일이 있는지 여부를 확인할 수 있는 명령어의 종류는 여러개가 있었지만, "path가 완벽하게 일치하는" 파일의 유무를 확인하는 명령어는 많지 않았습니다. 또한 여러 파일의 path를 보내서 한번에 유무를 파악하고 싶었는데, 그런 명령어는 찾기 힘들었습니다. (대부분 특정 단어로 시작하는, 특정 단어를 포함하는 파일의 여부를 파악하는 명령어였음)
그래서 그나마 다음과 같이 head_object 명령어를 사용해서 가져오는 것이 가장 나은 방법이라고 생각했고, 다음과 같이 진행했습니다.
또한 비동기 처리를 하기 위해서 max_workers를 설정해서 진행했는데요. 지금 생각해보니까 FastApi자체가 비동기로 동작하기도 하고, boto 자체에도 비동기 관련 패키지가 있었을텐데 코드 자체에 좀 문제가 있었네요. 좀 더 나은 방식도 있었을거고... 그래도 비동기로 처리하려는 호출이 10개도 안되기 때문에 비슷한 성능을 보일 것이므로, S3에 접근하는 것 자체에서 발생하는 속도를 테스트하겠다는 의도에서는 큰 차이가 없을 것이라고 생각합니다.
해당 함수처럼 준비하고, 실제 서비스상에서 상황을 생각했을 때 검색해야할 S3 이미지를 10개라고 가정하고 테스트를 진행했습니다.
결과
현재 FastApi가 동작하고 있는 서버는 lambda입니다. 또한 기본 구성은 실행시간만 늘렸고, 메모리는 기본설정인 128MB로 구성했습니다.
또한 테스트 도구는 간단하게 Postman을 사용하여 진행했습니다.

Postman에서의 부하 테스트 세팅은 다음과 같습니다.
- Performance 모드
- 가상 유저: 20명
- 부하 시간: 1분
하나의 API를 테스트할 것이기 때문에 1분이면 적정한 수준의 결과를 얻을 수 있을 것이라 생각했습니다.
기능구현 X & 128MB
Postman에서는 테스트를 하고, 결과를 문서로 출력해서 확인할 수 있습니다. 응답 속도와 처리량을 보여주고, 이 값으로 비교하려고 합니다. 원하는 것은 응답 속도니까요
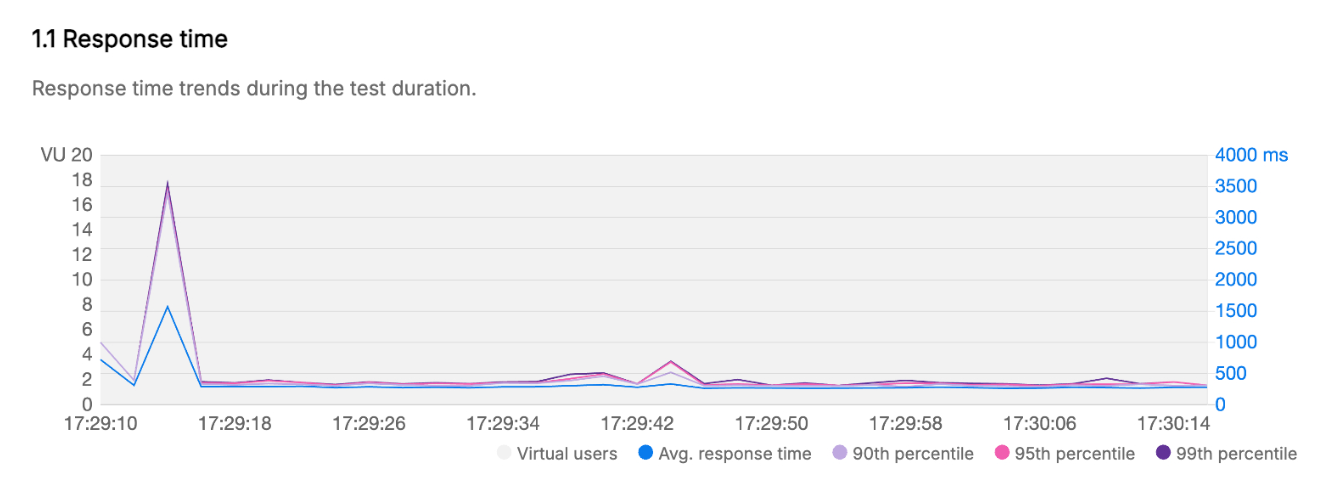
이렇게 응답 속도/처리량에 대한 데이터를 그래프로 확인할 수 있는데요. 사실 그래프도 그렇게 중요하지 않습니다. 저는 이 그래프를 전문적으로 분석할 줄도 모르고 (분석할만한게 있는지도 모르겠지만) 원하는 것은 응답 속도니까요!
그래프해서 확인할 수 있는건 초반에 Lambda의 ColdStart를 고려해서 생각해야한다는 겁니다. 그렇기 때문에 평균 응답시간을 보는 것도 좋지만 90th 응답시간을 보는게 ColdStart를 제외했을 때 일반적인 최악 시간(대부분의 상황에서 이 시간 내에 처리됨)을 볼 수 있기 때문에 해당 응답값으로 확인하고자 했습니다..
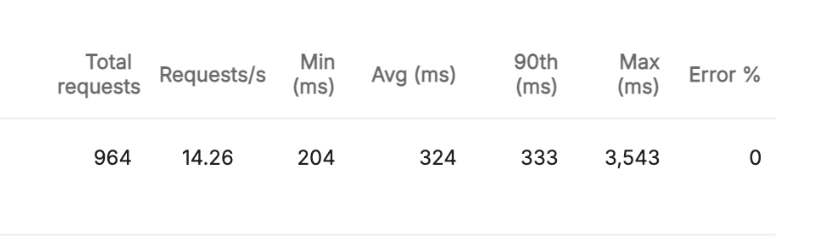
이 데이터를 확인하면 되고, 이 중 90th의 값을 확인하면 됩니다. 현재 상황에서는 333ms의 90th응답시간(이하 응답시간)을 가지네요.
기능구현 O & 128MB
이 설정에서는 테스트 결과가 없습니다. 왜냐하면 메모리 초과로 응답이 서버 에러가 발생했기 때문이죠. ㅋㅋㅋㅋ 따라서 해당 함수를 사용하였을 때 메모리 사용량이 급격하게 많아졌다고 판단할 수 있습니다.
이제 람다의 메모리 설정값을 수정해가면서 테스트해보려고합니다. 그 이유는 다음과 같습니다.
- 추가된 기능을 람다에서 처리할 수 있을 때 응답 시간을 확인하고자 함
- 128MB보다 유의미한 응답시간의 차이를 보이는 수준까지 메모리 설정값을 높이고자 함
따라서 128MB뿐만이 아닌 256MB, 384MB, 512MB를 테스트해보았고, 해당 값을 모두 테스트한 이후에 추가된 기능의 응답시간 감소가 어디까지 진행될 수 있을지 확인하고자 1024MB도 한번 테스트해보았습니다.
기능구현 X & 256MB!
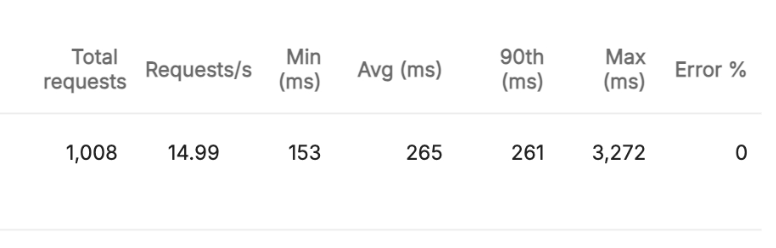
128MB와 비교했을 때 333ms -> 261ms로 약 70ms의 성능 개선을 확인할 수 있었습니다. 이정도면 유의미한 응답시간의 개선이 이루어졌다고 볼 수 있습니다.
기능구현 O & 256MB
마찬가지로 메모리 사용량을 초과했습니다. 더 높은 메모리 설정값을 가져야지만 해당 기능을 구현할 수 있을 것 같네요.
기능구현 X & 384MB
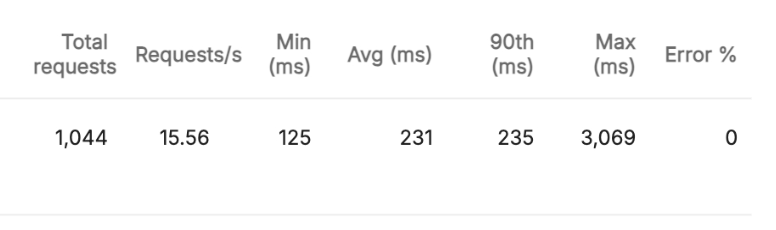
256MB와 비교했을 때 261ms -> 235ms로 약 30ms의 성능 개선을 확인할 수 있었습니다. 애매한 응답시간의 개선이 있었네요.
기능구현 O & 384MB
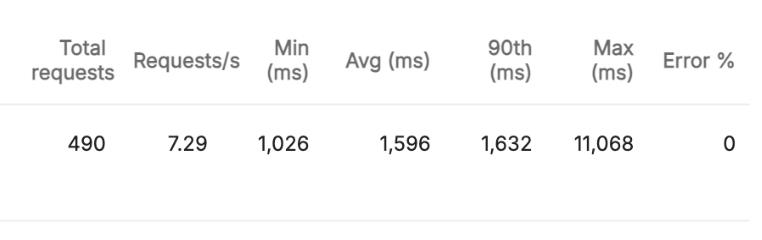
드디어 메모리가 터지지 않고, 명확한 결과를 볼 수 있었습니다. 이 테스트는 기능이 없을 때와 비교하면 될 것 같은데요. 대충 봐도 단위에서 차이가 보입니다.
기능이 없을 때에는 235ms의 응답 속도를 보이지만, 기능이 있을 때에는 1,632로 대략 1.4초의 응답 시간의 차이를 보입니다.
기능구현 X & 512MB
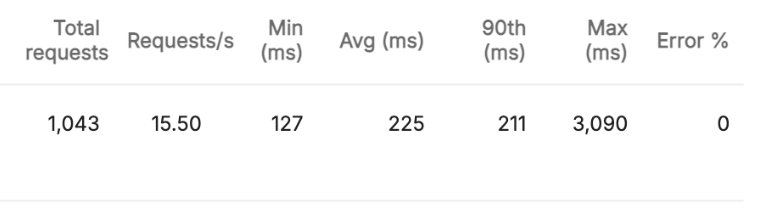
384MB와 비교했을 때 235ms-> 211ms로 약 20ms의 성능 개선을 확인할 수 있었습니다. 역시 점점 메모리 설정값이 올라가니 응답 시간이 개선되는 정도도 점점 감소하는 것 같습니다. 이정도까지 메모리 설정값을 올리는 것은 낭비가 될 것 같네요.
기능구현 O & 512MB
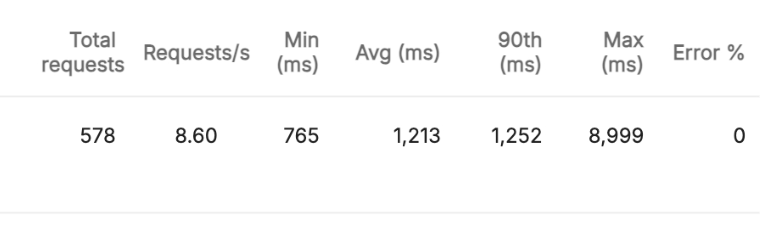
384MB와 비교했을 때 1,632ms -> 1,252ms로 약 400ms의 성능 개선을 확인할 수 있었습니다. 384MB의 메모리가 해당 기능이 구현되었을 때 실행하는 것에 부담이 컸다는 것을 알 수 있습니다. 안정적으로 운영하기 위해서는 최소한 512MB를 가져야겠네요. (해당 기능을 백엔드에서 사용한다면)
기능구현 X & 1024MB
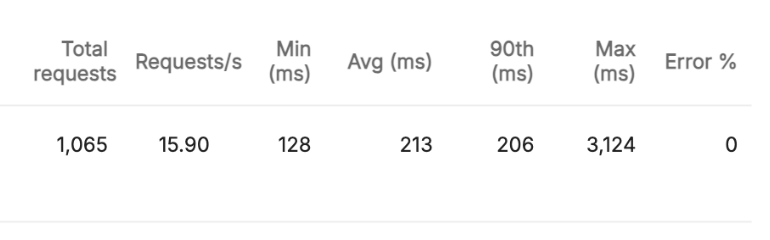
512MB와 비교했을 때 211ms -> 206ms로 약 5ms의 성능 개선이 있었는데요. 이정도면 차이가 없다고 봐도 무방할 것 같습니다. 뭐 이정도까지 메모리를 올리기에는 비용적으로도 부담일 것이기 때문에 단순 테스트로만 보면 될 것 같습니다.
기능구현 O & 1024MB
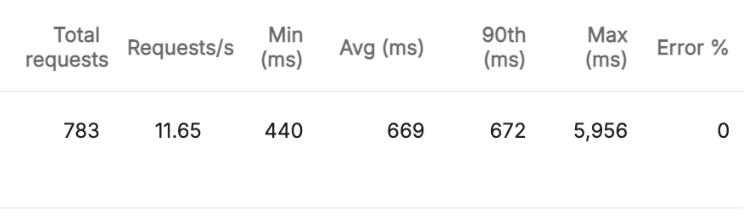
512MB와 비교했을 때 1,252 -> 672ms로 약 600ms의 성능 개선이 있었습니다. 생각했던 것보다 훨씬 큰 감소율을 보였는데요. 메모리가 커질수록 람다는 성능이 비례해서 올라가기 때문에 CPU 스펙의 증가로 인한 감소일 가능성이 높아보입니다. (Core 수가 많아질수록 동시에 처리할 수 있는게 많아지기 때문에)
하지만 람다에서 실행하는 기능이 이것만 있는게 아닌 다른 기능도 많기 때문에... 해당 메모리는 너무나도 비효율이라고 생각했습니다. (사용자 정보를 불러오는 기능같은 간단한것도 같이 실행하니...)
결론
이렇게 기능이 구현되었는지 여부로 테스트를 해보았고, 메모리 설정값에 따라서도 테스트를 진행해보았습니다. 테스트를 진행한 결과로 도출한 결론은 다음과 같습니다.
-
S3에 접근하는 기능은 그 자체만으로도 실행 속도가 길기 때문에 백엔드 API 내에 합쳐서 사용하기에 리스크가 큼
-
해당 기능을 백엔드에서 사용하기 위해서는 메모리를 1,024MB 이상으로 올려야하는데, 이는 동일한 람다에서 실행될 수 있는 다름 기능들을 보았을 때 매우 큰 낭비임
-
따라서 해당 기능을 백엔드 API 내에서 실행하는 것은 매우 지양해야함
-
이와 동시에 해당 기능을 실행하기 위한 가장 효율적인 메모리는 대략 256MB이라고 볼 수 있음 (응답속도의 개선만 보았을 때, 비용은 추후 계산 예정)
S3의 파일 확인하는 기능은 백엔드에서 넣는것을 지양
이것이 저의 결정사항입니다. S3를 확인하는 기능으로만으로도 결정할 수 있었네요. 아마 요구되었던 처리는 백엔드가 아닌 데이터 수집 단계에서 진행해야할 것 같다고 의견을 전달해두었고, 그쪽 파트에서 진행할 것 같습니다.
프론트엔드 단에서 이미지를 로딩했을 때 404가 발생하면 람다가 실행되도록 구성할까도 고민했지만, 그렇게 된다면 람다를 실행하는 횟수가 기하급수적으로 증가할 것 같았기 때문에 배제했습니다.
이상으로 제가 티끌 프로젝트를 하면서 고민했던 부분을 정리해봤습니다.

와 너무 재밌는 주제에요 잘 읽고 갑니다 > < !!