
📅 23.01.27 TIL
- 1 ~ 5 완료
- 초심을 생각하며 복습. 단, 빠르게 훑기
About

강의평 : 강의 수강 중..
- 포스팅에 사용된 이미지 출처: 해당 강의 ppt
Section 1:강의 소개
🔷 강의 중 질문 해결하기
1. 강의 확인
2. QnA 찾아보기
3. StackOverflow 에러 메시지 찾아보기
4. QnA 질문 작성 : 강의 번호와 문제가 있는 부분 스크린샷. 영어로 문의
🔷 강의를 성공적으로 수행하는 방법
🔹For projects:
1. 코드 직접 실행
2. 주피터 빈 노트북 실행 후, 영상과 함께 스스로 코드 작성
🔹For mini challenges:
1. 직접 풀어보기
2. 강의 내 정답과 본인의 정답 비교하기
🔷 ML skill track: sdsclub ← 강사가 추천하는 로드맵 강의
🔷 5. ML vs DL vs AI
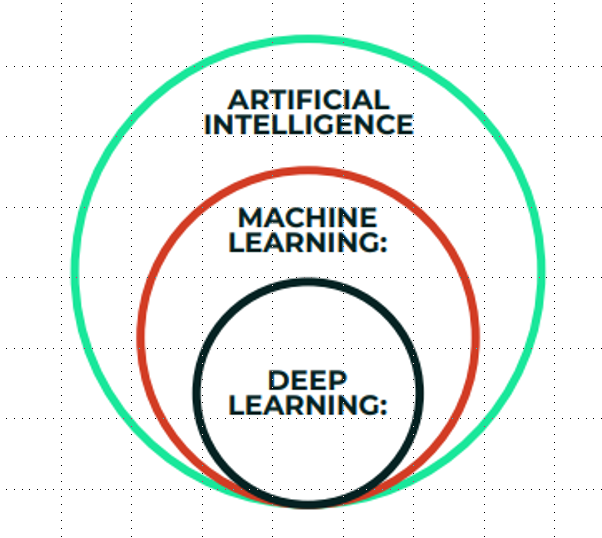
- AI:
- 컴퓨터가 의사 결정, 텍스트 처리, 시각적 인식과 같은 인지를 모방할 수 있게 하는 과학. 인간의 사고와 의사 결정을 모방할 수 있도록 하는 것
- 머신러닝, 로봇 공학, 컴퓨터 비전 포함
- ML:
- 컴퓨터가 학습을 통해 업무를 향상시킬 수 있도록 하는 인공지능의 하위 분야
- DL:
- 머신러닝의 특화된 분야. 이미지나 텍스트 같은 거대한 데이터 세트를 사용하는 심층 신경망에 기반

- 검은 점: 인공 뉴런, 생물학적 뉴런의 작동 방식을 흉내내는 수학 방정식들. 특정한 층으로 모든 뉴런을 연결. 입력층, 여러개의 은닉층, 연결치는 가중치.
- deep: 뉴런 수가 증가하면, 신경망 또한 깊어진다.
- 경험을 통해 더 똑똑해진다.
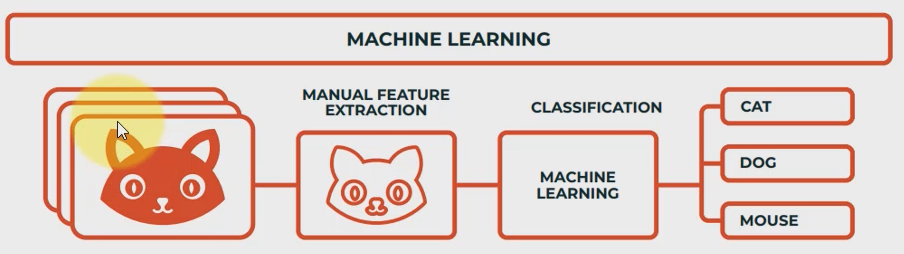
- ML vs DL 비교
-
ML: 1) 모델 선택(SVM, 나이브 베이즈 분류기Naive Bayes Classifier 등) 2) feature 추출
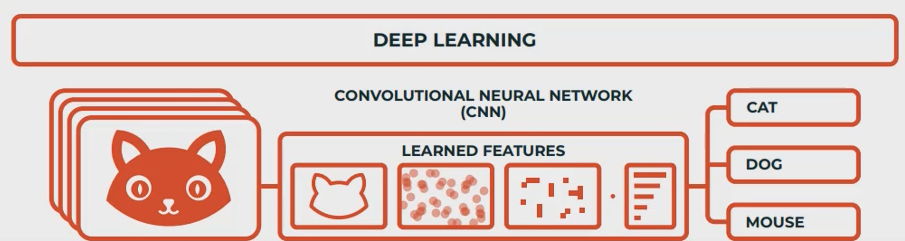
-
DL: 1) 신경망 구조 선택 2) feature를 자동으로 추출
📅 23.01.29 TIL
- 6 ~ 13 수강완료
- Section2) Jupyter notebook/ tensorflow-2.11.0 설치
- 환경변수 설정
🔷 6. Machine Learning
- 지도 학습: 라벨링 된 입력 및 출력 데이터
- 분류
- 회귀: 연속적인 출력값을 예측
- 비지도 학습: 라벨이 없는 입력 데이터. 출력 데이터가 없음.
- 군집화(클러스터링)
- 강화 학습: 누적 보상을 극대화하는 강력한 학습 방법. 보상과 페널티
📅 23.01.31 TIL
- 강의 15에서 책 2권(전공서적 두께의 Ml 그리고 통계)을 pdf로 제공해주는데, 영문이다.🥲
- 회귀 모델 실습 이전에 개념 다지기
- single-layer perceptron 계산 문제를 adsp와 빅분기에서 만난 적 있다. 이제 헷갈리지 않고 계산 할 수 있겠다.😊
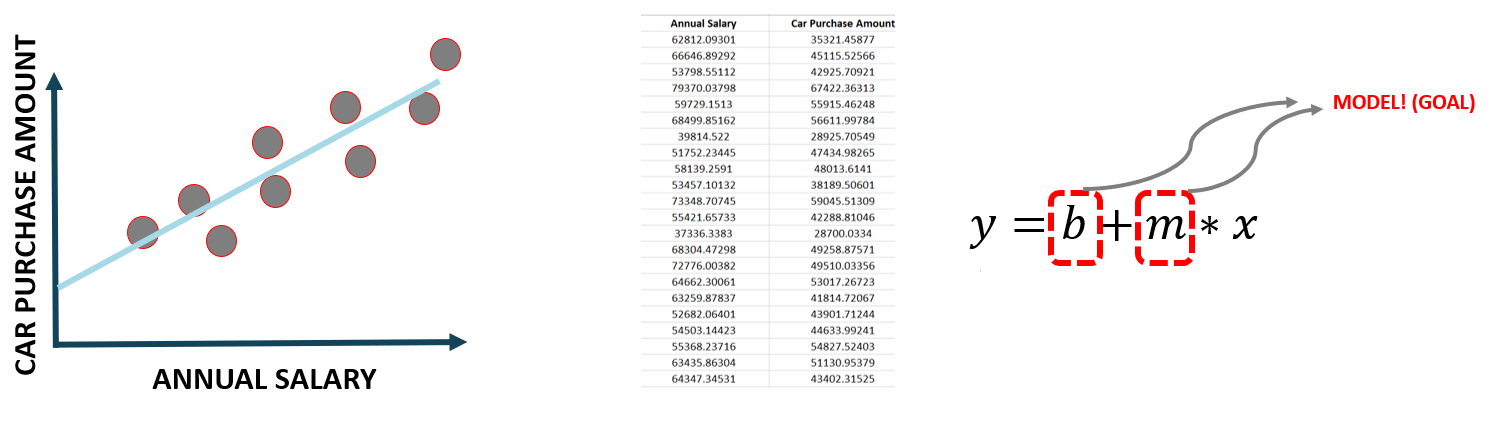
Section 3: 회귀 (자동차 판매 예측)
🔷 15. x 독립변수, y 종속 변수. 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법
🔷 17. 인공 신경망(artificial neural network)
- 단일 뉴런 수학 모델
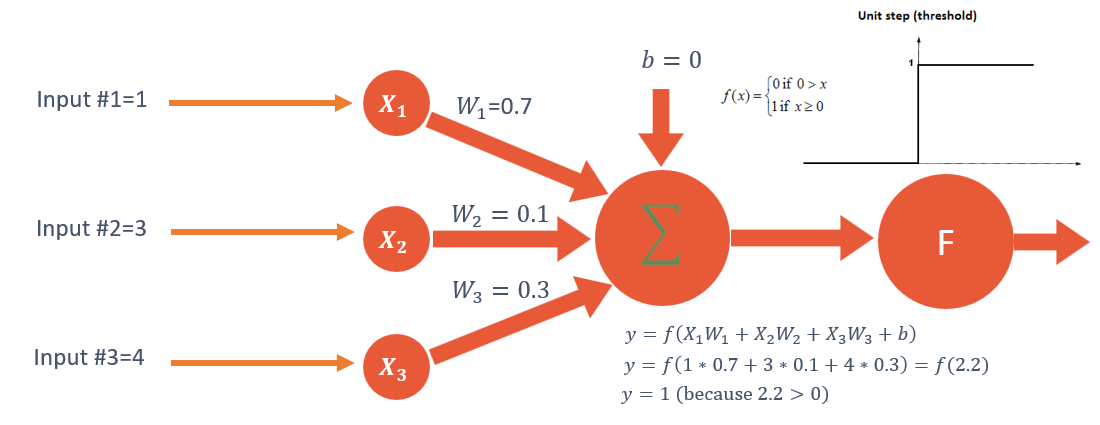
🔷 18. 역전파(back propagation)
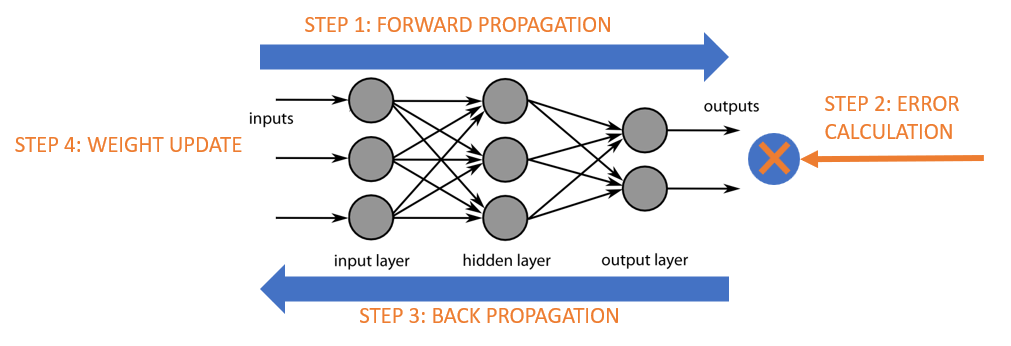
- 경사 하강법
- 최적화의 목적: 손실 함수의 증감률을 계산해 뉴런의 가중치를 조정(오류를 최소화 할 수 있는)
- epoch: 가중치를 갱신하는 매 과정
🔷 19. 다층 퍼셉트론 인공 신경망
- 행렬 표현
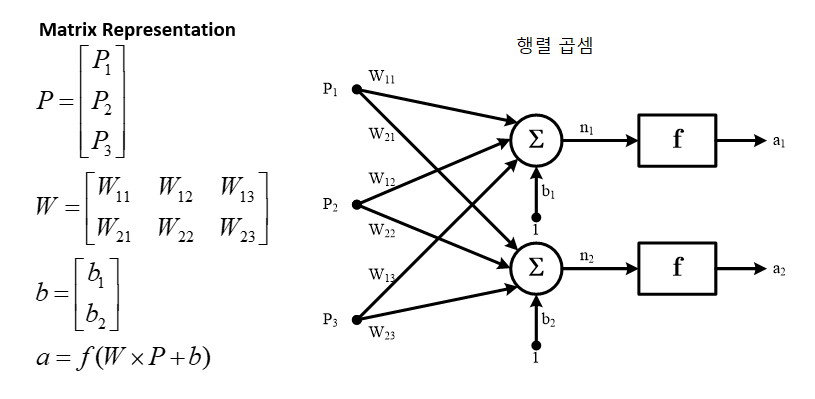
- 다층 퍼셉트론 인공신경망(Multi-layer perceptron model) 행렬 표현
📅 23.02.22 TIL
- 20 ~ 25 완료
- 회귀 모델, 케라스(인공신경망으)로 training, 모델 평가
- 딥러닝도 자주 볼수록 가까워지는 느낌🫢
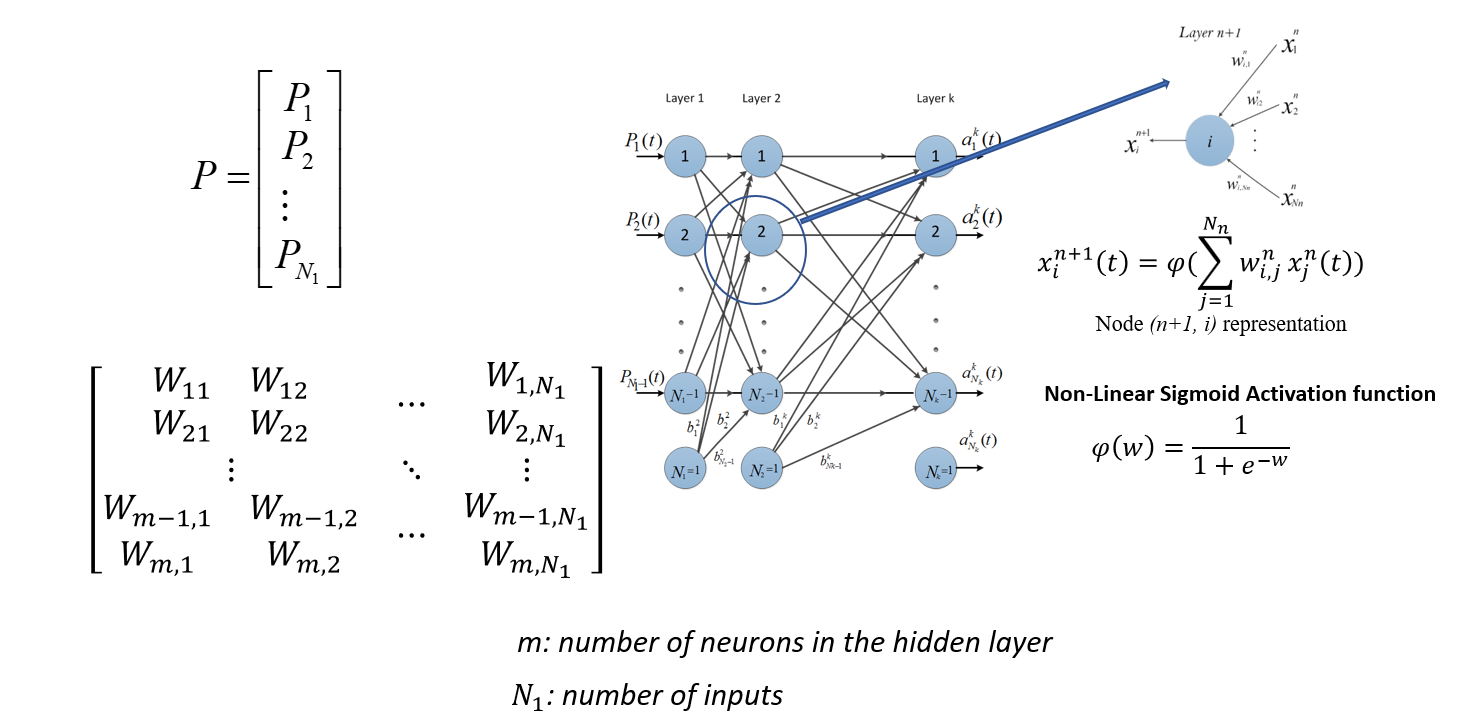
🔷 인공신경망에서 파라미터 수 계산하기
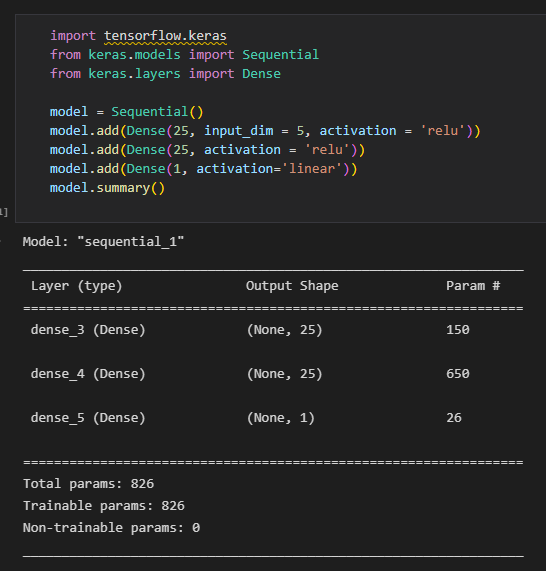
input_5 * 25 + bias_25 (은닉 뉴런 25개에 각각 bias가 붙어 있음.) = 150
뉴런 25 * 뉴런 25 + bias_25 = 650
25 + bias_1 = 26
🔹 Dense, 뉴런의 수, epoch, batch size를 바꾸면 일어나는 일
- 은닉층이 적으면 학습을 잘 못할 수도 있다.
- 뉴런의 수가 작으면 학습을 잘 못할 수도 있다.
- epoch 수가 많을 수록 신경망을 훈련 데이터에 더 많이 노출시키게 된다.
- 배치 사이즈는 모델 학습 중 parameter를 업데이트할 때 사용하는 데이터 개수다. 배치 사이즈가 커지면 그만큼 loss는 증가하고 듬성듬성 학습할 수도 있다.
📅 23.02.25 TIL
- 26 ~ 31 완료
🔷 28. 이론
🔹이미지를 디지털로 표현하는 방법
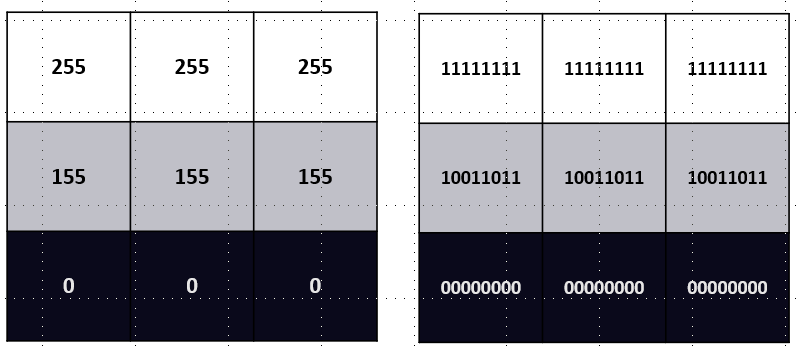
(우측은 이진법)
🔹Feature Detectors
https://setosa.io/ev/image-kernels/
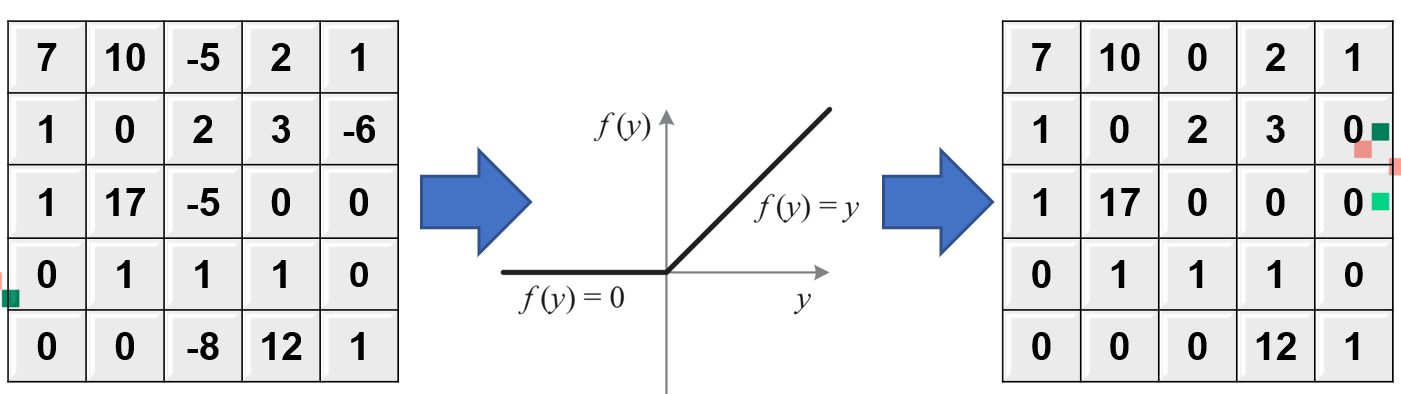
🔹ReLU(Rectified Linear Units)
- 음수 값을 모두 제거
- 중요한 특정 부분이 있는 특징 지도(feature map)를 확인
- 주로 은닉층에서 사용
🔹Pooling(downsampling)
- 목적: 특징 지도의 차원 수를 줄이기 위해, 과적합을 방지해 모델이 일반화 할 수 있도록 도와준다.
- max pooling: 최댓값 -> 가장 중요한 특성만 유지, 특정의 실제값 보전. 사진인 경우, max pooling을 적용 시 위치가 아닌 주된 중요한 픽셀에만 집중. 특징 지도에 주어진 샘플의 사이즈에 반응하는 특징의 최댓값을 유지하는 방식으로 작동.
🔹신경망의 성능 개선
- 특성 검출 개수를 바꾼다. 32보다는 64
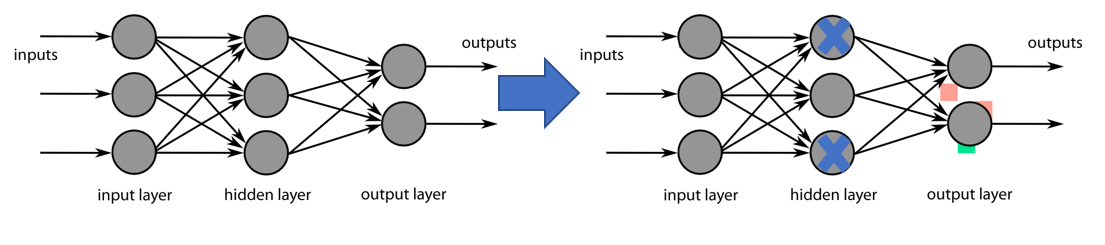
- dropout 신경망 내의 뉴런 탈락
🔹혼동행렬
KPI: 핵심 성과 지표
- Classification Accuracy = (TP+TN) / (TP+TN+FP+FN)
- Misclassification rate(Error rate) = (FP+FN)/(TP+TN+FP+FN)
- precision = TP / total True predictions, 얼마나 정답을 자주 맞혔는가
- recall = TP / Actual True
