
책은 파이썬이지만 c 언어 병행해서 공부하기
- 9/1부터 6주차로 진행하는 스터디를 정리한 것이다.
- 코딩테스트 합격자 되기 - 파이썬편 책 소개
- 인프런 동영상 링크
스터디 커리큘럼
1주차 시간복잡도 ✅
2주차 스택 ✅
3주차 큐 ✅
4주차 해시 ✅
5주차 트리
6주차 집합
8-1 개념
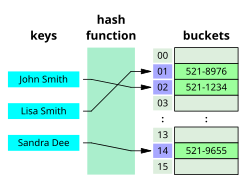
1) 해시 함수를 사용
- 변환한 값을 인덱스 삼아 키와 값을 저장해서 빠른 데이터 탐색을 제공하는 자료 구조
- 키와 데이터는 일대일 대응
- 임의 크기 데이터를 고정 크기 값으로 매핑하는 데 사용할 수 있는 함수
2) 좋은 해시 함수의 특징
- 해시 함수 값 충돌의 최소화
- 쉽고 빠른 연산
- 해시 테이블 전체에 해시 값이 균일하게 분포
- 사용할 키의 모든 정보를 이용하여 해싱
- 해시 테이블 사용 효율이 높을 것
3) 해시의 특징
- 단방향: 키를 통해 값을 찾을 수 있다.(반대x). 네트워크 보안에서 많이 활용됨.
- : 해시 함수를 활용해서 특정 값이 있는 위치를 바로 찾을 수 있어 탐색 효율이 좋다.
- hash table: 키와 대응한 값이 저장되어 있는 공간
- bucket: 해시 테이블의 각 데이터
4) 활용
- 비밀번호 관리
- 데이터베이스 인덱싱
- 블록체인: 각 블록은 이전 블록의 해시값을 포함. 이를 통해 데이터 무결성을 확인
- data integrity: 데이터의 정확성, 일관성, 유효성이 유지되는 것. 정보에 결점이 없도록 유지하는 성질.
➕ 참조:
https://en.wikipedia.org/wiki/Hash_table
https://en.wikipedia.org/wiki/Hash_function
https://ko.wikipedia.org/wiki/생일_문제
https://en.wikipedia.org/wiki/Birthday_problem
https://en.wikipedia.org/wiki/Four_color_theorem
8-2 해시 함수
해시 함수를 구현할 때 고려할 내용
1) 해시 함수가 변환한 값을 인덱스로 활용해야 하므로 해시 테이블의 크기를 넘으면 안 된다.
2) 해시 함수가 변환한 값의 충돌은 최대한 적게 발생해야 함(충돌이 많이 발생할 수록 성능이 떨어짐)
- 해시 테이블을 크게 만든다.(메모리 문제)
- 해시 함수가 다양한 값을 반환하게 만든다.
자주 사용하는 해시 함수 알아보기
- 나눗셈법: 구현이 매우 쉽지만, 큰 소수 찾기가 어렵다.
- 곱셈법: 구현이 나눗셈법과 비교했을 때 복잡해진다.
- 문자열 해싱: 키의 자료형이 문자열인 경우.
- (a+b)%c=((a%c)+(b%c))%c -> 중간마다 mod를 취하면서 오버플로우 방지
8-3 충돌처리
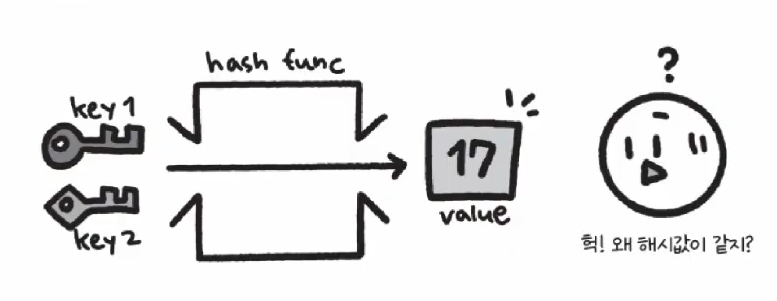
- 충돌: 서로 다른 키에 대해서 해시 함수의 결과값이 같은 경우
- 하나의 버킷에 2개의 값을 넣을 수는 없으므로 해시 테이블을 관리할 때는 반드시 충돌 처리를 해야
함
해결
1) 체이닝
- 충돌이 발생하면 해당 버킷에 링크드리스트로 같은 해시값을 가지는 데이터를 연결
- 체이닝의 단점
- 해시 테이블 공간 활용성이 떨어짐
- 저장되는 데이터들이 고르게 분포되지 않고 뭉치는 경향
- 검색 성능이 떨어짐
2) 개방 주소법
-
선형 탐사 방식
- 충돌 시 인덱스를 1씩 늘려가며 빈 공간을 찾음.
-
이중 해싱 방식
- 두 개의 다른 해시 함수를 사용해서 탐색 간격을 정함.
🟢코딩테스트에서는 해시를 구현할 일은 없다
- 키가 될 수 있는 것: immutable, 고유한 이름.
- tuple은 키가 될 수 있지만 list는 키가 될 수 없다. 이름을 활용해서 찾고 싶은 값.
- 코딩테스트에서 해시를 주로 사용하는 경우
1) 뭔가를 카운팅: dictionary, count
2) 존재 여부 확인: 참가자 명은 key로
3) 정보를 짝지어 저장 (mapping)
4주차 미션
해시 - 개념
문제 1
해시 함수를 만드는 가장 간단한 방법 중 하나는 나눗셈법 (h(k) = k mod m) 입니다. 여기서 m은 해시 테이블의 크기를 의미합니다. 이때, m의 값으로 2의 거듭제곱 (예: 2p)이나 10의 거듭제곱을 피하고 소수(prime number)를 사용하는 것이 좋다고 알려져 있습니다. 그 이유는 무엇인가요? m의 값에 따라 입력 키(key)들이 특정 패턴을 가질 경우, 해시 충돌이 어떻게 빈번하게 발생할 수 있는지 그 원리를 설명하세요.
[힌트]
공약수: m과 키(key) 값들 사이의 관계
키의 특정 패턴: 입력 키가 모두 짝수이거나 특정 배수일 경우중복된 키를 사용하여 값을 추가하려고 하면 딕셔너리는 어떻게 동작할까요?
하위 비트(Lower Bits): m이 2의 거듭제곱일 때 mod 연산의 결과
데이터 쏠림 현상(Clustering) 과 균등한 분포
1) 2의 거듭제곱 (예: 2p)이나 10의 거듭제곱을 피하는 이유
10의 거듭제곱이라면, 해시 값은 항상 0. 2의 거듭제곱이면서도 모두 짝수이면 끝 비트는 항상 0.
위 경우 모든 키가 한 칸에 몰려서 최악의 충돌이 발생할 수 있다.
2) 소수를 사용하는 경우
다른 수를 사용할 때보다 충돌이 적다. 소수의 약수는 1과 자기 자신 뿐.
키 집합이 어떤 배수로 주어져도 슬롯 전체를 완전하게 순환한다.
(슬롯 전체 활용. 전역으로 고르게 분산. 충돌은 최소화)
문제 2
곱셈법 (h(k) = floor(m * (kA mod 1)))은 나눗셈법에 비해 해시 테이블의 크기 m의 선택에 덜 민감하다는 장점이 있습니다. 곱셈법의 계산 과정을 단계별로 설명하고, 어째서 이 방법이 m 값의 제약으로부터 비교적 자유로우며, 입력 키의 패턴에 따른 충돌 발생 가능성을 어떻게 효과적으로 낮추는지 그 원리를 나눗셈법과 비교하여 서술하세요.
[힌트]
소수점 부분(Fractional Part): kA mod 1 연산이 키 값을 0과 1 사이의 실수로 만드는 과정의 의미
상수 A의 역할: 해시 결과의 분포에 영향을 주는 상수 A (0 < A < 1)의 중요성
키의 모든 비트 활용: 나눗셈법과 달리, 곱셈법이 키의 모든 부분을 해시값 계산에 어떻게 반영하는지
테이블 크기 m의 역할: 나눗셈법과 비교했을 때, 곱셈법에서 m의 역할은 어떻게 다른가
1) 곱셈법의 계산 과정
- 키에 황금비(1.6180339887)를 곱한다
- 구한 값의 정수 부분을 모두 버리고 소수 부분만 취한다. => 0.xxx
- 구한 값을 가지고 실제 해시 테이블에 매핑한다. => 0.xxx 에 테이블의 크기인 m을 곱하면 테이블의 인덱스인 0 ~ (m-1)에 매치할 수 있다.
2) 곱셈법의 장점
황금비를 사용하므로 나눗셈법처럼 소수가 필요 없다. 해시 테이블의 크기가 커져도 추가 작업이 필요 없다.
해시 - 구현
문제 3
파이썬 딕셔너리의 키는 '해시 가능해야 한다'는 제약 조건이 있습니다. 아래 코드를 실행했을 때 발생하는 TypeError의 원인을 설명하고, 이를 통해 '해시 가능'하다는 것의 의미가 무엇인지 서술하세요. 어떤 타입이 해시 가능하며, 리스트(list)와 같은 특정 타입이 해시 가능하지 않은 이유는 무엇인가요?
# 예제 코드
sales_log = {}
items = ["apple", "banana", "apple"]
special_item = ["orange", "milk_pack"]
# 문자열을 키로 사용 (성공)
for item in items:
sales_log[item] = sales_log.get(item, 0) + 1
# 리스트를 키로 사용 (실패)
try:
sales_log[special_item] = 1
except TypeError as e:
print(f"오류 발생: {e}")
print(sales_log)1) 코드 실행 결과
오류 발생: unhashable type: 'list'
{'apple': 2, 'banana': 1}2) unhashable type: 'list'
해시는 불변(immutable) 객체여야 하는데 리스트는 가변(mutable) 객체다. 해시 가능하다의 의미는 2가지 조건을 만족해야 한다.
- 해시 값을 가질 수 있어야 한다. 만약 a == b 라면 반드시 hash(a) == hash(b)가 되어야 한다.
- 불변성을 가진다. 이 내용을 조금 풀면 해시 테이블은 키가 삽입될 때 계산된 해시 값이 객체의 생애 동안은 변하지 않아야 한다는 뜻이다. 만약, 키 객체의 상태가 바뀌어 해시 값이 달라지면 키를 찾을 수 없게 된다. 이런 문제를 방지하고자 파이썬은 리스트나 dict와 같은 가변 객체에서 아예 hash()를 제공하지 않는다.
3) 어떤 타입이 해시 가능하며, 리스트(list)와 같은 특정 타입이 해시 가능하지 않은 이유:
문자열(str), 숫자(int), 튜플(tuple) 등은 해시 가능하다.
문제 4
대량의 데이터에서 특정 값을 찾는 작업을 할 때, 어떤 자료구조를 사용하느냐에 따라 성능이 크게 달라집니다. 100만 개()의 제품 ID가 담긴 리스트 all_products에서 1만 개()의 search_products가 각각 존재하는지 확인하는 상황을 가정해 봅시다.
for 루프를 돌며 search_products의 각 원소를 all_products 리스트에서 in 연산자로 찾는 방식.
all_products 리스트를 먼저 set이나 dict으로 변환한 뒤, for 루프를 돌며 search_products의 각 원소를 찾는 방식.
두 방식의 시간 복잡도는 각각 어떻게 되며, 왜 2번 방식이 압도적으로 빠른 성능을 보이는지 해시 테이블의 '평균 O(1)' 시간 복잡도와 연관 지어 설명하세요.
1) for 루프를 돌며 search_products(M)의 각 원소를 all_products(N) 리스트에서 in 연산자로 찾는 방식.
이중 for문이므로 O(MN) = O(10^4) * O(10^6) = O(10^10)
2) all_products 리스트를 먼저 set이나 dict으로 변환한 뒤, for 루프를 돌며 search_products의 각 원소를 찾는 방식.
- 리스트를 먼저 set이나 dict로 변환 = O(N) = O(10^6)
- for 루프를 돌며 search_products의 각 원소를 검색 = O(M) = O(10^4)
- 집합/딕셔너리는 내부적으로 해시 테이블을 사용한다. 원소 검색 평균 시간은 O(1)
- 전체 = O(N + M) = O(10^6 + 10^4)
3) 왜 2번 방식이 압도적으로 빠른 성능을 보이는지 해시 테이블의 '평균 O(1)' 시간 복잡도와 연관 지어 설명하세요.
리스트 탐색은 각 검색마다 O(n)이 걸리므로 전체가 O(nm)이 되는 반면, 집합/딕셔너리를 사용하면 한 번의 변환 O(n) 이후 각 검색이 O(1)이므로 전체가 O(n + m)으로 줄어든다. 해시테이블의 이와 같은 성질 때문에 두 번째 방식이 압도적으로 빠르다.
문제 5
파이썬 딕셔너리는 키의 중복을 허용하지 않습니다. 만약 중복된 키를 사용하여 값을 추가하려고 하면 딕셔너리는 어떻게 동작할까요? 아래와 같이 가격 정보 업데이트 기록이 price_updates 리스트로 주어졌을 때, 최종적으로 생성될 product_prices 딕셔너리의 상태를 예측하고 그 이유를 설명하세요.
# 예제 코드
price_updates = [
("apple", 1000),
("banana", 3000),
("orange", 2000),
("apple", 1200) # apple 가격 업데이트
]
product_prices = {}
for product, price in price_updates:
product_prices[product] = price
# 최종 product_prices 딕셔너리는 어떤 모습일까요?
print(product_prices){'apple': 1200, 'banana': 3000, 'orange': 2000}중복 키를 사용하여 값을 추가하게 되면 기존 키의 값이 덮어쓰기 된다.
