
책은 파이썬이지만 c 언어 병행해서 공부하기
- 9/1부터 6주차로 진행하는 스터디를 정리한 것이다.
- 코딩테스트 합격자 되기 - 파이썬편 책 소개
- 유튜브 동영상 링크
DP 이후는 제대로 보지 못했지만 이번 스터디까지 포함하면 3회독이다.
3회독 때문인지 아니면 동영상으로 시각/청각으로 함께 공부해서 그런지 개념이 쏙쏙 들어온다.
물론, 그 사이 링크드리스트도 써보고 큐나 스택 자료구조를 구현한 덕분이기도 하다.
항상 바쁘다는 핑계로 그리디 즈음부터는 집중하지 못했는데, 이번에는 이 느낌 그대로 끝까지 하기를!
🙇 10/13 기준으로 미션이 완료되지 않았습니다..!
스터디 커리큘럼
1주차 시간복잡도 ✅
2주차 스택 ✅
3주차 큐 ✅
4주차 해시 ✅
5주차 트리 ✅
6주차 집합 ✅ - 마지막주!
10.집합
10-1 개념
1) 순서와 중복이 없는 원소들을 갖는 자료구조
2) 상호배타적 집합(Disjoint set): 교집합이 없는 집합 관계
- 그룹화한다.
- 중복이 없다.
3) 상호배타적 집합 특성을 활용하는 분야
배워야 하는 이유: 그래프 알고리즘에서 많이 활용하기 때문
- 이미지 분할: 서로 다른 부분으로 나누는 데 사용 ex) 사람/배경
- 도로 네트워크 구성: 각 도로가 교차하지 않도록 설계-> 교차로 혼잡을 줄임
- 최소 신장 트리 알고리즘 구현(그리디): 최소한의 선을 이어서 모든 노드간 경로 형성 -> 간선을 추가할 때마다 사이클을 형성하는지 여부
- 게임 개발: 캐릭터 동작을 자연스럽게 구현 ex) 두 캐릭터가 겹치지 않도록 함
- 클러스터링 작업
4) 구현
- 배열을 활용한 트리로 집합 표현하기
- 대표 원소: 각 그룹을 대표하는 원소(루트 노드)
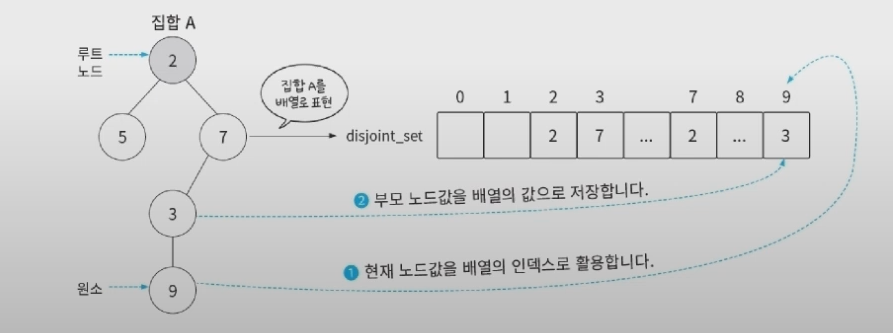
- 현재 노드의 값은 배열의 인덱스로 활용
- 부모 노드값을 배열의 값으로 저장
- 참고: {1,2,3,99999999999999999} 와 같은 경우 메모리 낭비. 이런 경우는 딕셔너리를 활용하면 좋다.
10-2 집합의 연산
유니온-파인드 알고리즘
- 파인드 연산: 특정 노드의 루트 노드가 무엇인지 탐색하는 방법. 특정 노드가 같은 집합에 있는지 확인할 때 사용
- 파인드 연산의 연산 비용 문제, 경로 압축으로 해결
➡️ 부모 테이블에 루트 노드를 바로 저장. 루트노드에 빠르게 접근
참고) 아크만상수(Ackermann Constant) - 유니온 연산: 두 집합을 하나로 합치는 연산
- 유니온 연산의 연산 비용 문제, 랭크로 해결
➡️랭크: 현재 노드를 기준으로 하였을 때 가장 깊은 노드까지의 경로 길이
cf) 코테에서는 경로 압축이면 충분. 개념적으로는 둘 다 알아두는 게 좋다.
마무리
집합을 언제 사용할까?
- 여러 그룹 나누기/ 연결 요소 찾기 -> 몇 개의 그룹으로 나뉘는가(대표 원소의 갯수를 찾으면 된다)
- 실시간 연결 관계가 변한다. 두 원소의 연결 여부를 반복적으로 확인한다.
- 사이클
leetcode 1971. Find if Path Exists in Graph
https://leetcode.com/problems/find-if-path-exists-in-graph/description/
- 유니온-파인드 알고리즘 개념대로 전개하면 풀리는 게 너무 신기해서 기록.
- 아직까지 아크만 상수는 잘 모르겠다..!
class Solution:
def validPath(self, n: int, edges: List[List[int]], source: int, destination: int) -> bool:
parent: list[int] = [i for i in range(n)]
# 루트 노드 찾기
def find(x: int) -> int:
while parent[x] != x:
parent[x] = parent[parent[x]] # 이게 경로 압축
x = parent[x]
return x
# 두 노드를 같은 집합으로 묶음
def union(a: int, b: int) -> None:
root_a = find(a)
root_b = find(b)
if root_a != root_b:
parent[root_b] = root_a
# 모든 간선에 대해 union
for u, v in edges:
union(u, v)
# 같은 루트 노드를 가지는지 확인한다.
return find(source) == find(destination)6주차 미션
집합 - 개념
문제 1.
유니온-파인드 자료구조는 어떤 종류의 문제를 해결하기 위해 고안되었나요? 이 자료구조의 핵심 목표는 무엇인지 서술하세요.
핵심 연산인 find(x)와 union(x, y)이 각각 어떤 역할을 하는지 설명하세요. (find는 원소 x가 속한 집합의 대표 원소를, union은 두 원소가 속한 집합을 하나로 합치는 역할을 합니다.)
-
어떤 종류의 문제를 해결하기 위해 고안: 겹치지 않는 여러 개의 집합을 효율적으로 관리하기 위한 구조. 두 원소가 같은 그룹(집합)에 속하는가? 두 그룹을 하나로 합칠 수 있는가? 와 같은 문제를 해결할 때 사용
-
핵심 연산인 find(x)와 union(x, y)이 각각 어떤 역할
- find(x): 원소 x가 속한 집합의 루트 원소를 찾는다.
- union(x, y): 원소 x와 원소 y가 속한 두 집합을 하나로 합친다.
- 문제 중에 답이 나와 있....
문제 2.
union 연산을 단순히 한쪽 트리의 루트를 다른 쪽 트리의 루트 자식으로 연결하는 방식으로 구현했다고 가정해 봅시다.
이러한 방식에서 최악의 경우 어떤 형태의 트리가 만들어질 수 있나요? (힌트: 이진 탐색 트리의 편향 트리와 유사한 형태를 생각해보세요.)
이렇게 만들어진 구조에서 find 연산의 시간 복잡도는 O(N)까지 저하될 수 있습니다. 그 이유를 트리의 높이와 연관 지어 설명하세요.
편향 트리
매번 한쪽 트리를 다른 쪽의 밑으로만 붙이게 됨. 연결 리스트와 다를 바가 없다.
- find 연산은 현재 노드에서 부모를 타고 올라가 루트 노드를 찾는데, 연산 속도는 트리 높이에 비례한다. 아래 그림처럼 높이 h가 노드의 갯수 N과 거의 같으므로, 시간 복잡도가 O(N)까지 될 수 있다.
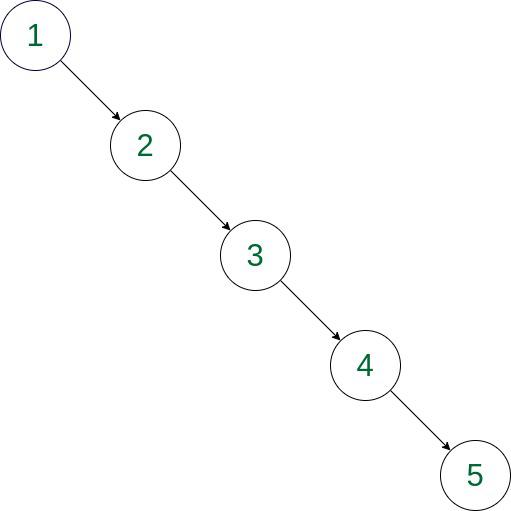
문제 3.
기본적인 유니온-파인드의 성능을 획기적으로 개선하는 두 가지 최적화 기법이 있습니다.
경로 압축(Path Compression): find 연산을 수행하면서 거쳐 가는 모든 노드가 직접 루트를 가리키도록 만드는 이 기법의 동작 원리를 설명하세요.
- 트리 구조를 평평하게 만드는 기법
- 특정 노드 x에서 루트 노드를 찾아 올라가는 과정에서 방문하는 모든 노드의 부모를 찾아낸 루트 노드로 직접 갱신하다.
- 경로 압축을 하면, 경로상의 모든 로드가 루트에 직접 연결되므로 단 한 번의 참조로 루트에 도달할 수 있다.
Union by Rank/Size: 두 트리를 합칠 때, '높이(rank)'나 '크기(size)'를 기준으로 합치는 규칙은 무엇이며, 이 규칙이 왜 트리가 한쪽으로 길어지는 것을 방지하는 데 효과적인지 설명하세요.
- 랭크 기준: 높이(rank)가 낮은 트리를 높은 트리 밑에 붙인다. -> 전체 트리의 최대 높이가 변하지 않음.
- size 기준: 집합의 원소 개수를 기준으로, 원소 수가 적은 트리를 많은 트리 밑에 붙인다.
- 이 규칙이 한쪽으로 길어지는 것을 방지하는 데 효과적인 이유: 랭크든 사이즈든 작은 쪽을 큰 쪽에 붙이면 전체 트리의 최대 높이가 변하지 않는다.(높이가 다른 트리)
- 높이가 같은 두 트리라면 전체 높이가 1증가한다.
- N 개의 노드가 있을 때 트리의 높이는 항상 항상 이내로 유지 -> 그래서 한쪽으로 길게 늘어지는 편향 현상을 막을 수 있다.
이 두 가지 최적화를 모두 적용했을 때, 유니온-파인드 연산의 시간 복잡도는 어떻게 개선되는지 서술하세요. (힌트: 아커만 함수)
- 데이터 크기에 상관없이 상수시간에 가까운 시간복잡도를 가진다.
집합 - 구현
문제 4.
일반적으로 유니온-파인드는 원소가 0부터 n-1까지의 정수일 때, 크기가 n인 배열을 이용해 부모 노드를 저장합니다. 하지만 만약 원소가 10억과 같이 매우 큰 정수이거나, 문자열이라면 어떻게 구현해야 할까요?
- 딕셔너리를 사용해서 구현 -> 딕셔너리는 내부적으로 해시 테이블을 사용한다. 10억 숫자나 문자열이 들어오면 해시 함수를 통해 고유한 버킷 주소로 변환. 그래서 타입에 상관없이 범용적으로 유니온-파인드 구현이 가능하다.
parent 자료구조로 배열 대신 딕셔너리(Dictionary)를 사용하여 유니온-파인드 자료구조를 구현하세요. 아래 operations에 따라 union과 find 연산을 수행하고, 각 find 연산의 결과를 설명하세요. 이 구현이 왜 큰 수나 해시 가능한(hashable) 모든 타입을 다룰 수 있는지 그 원리를 서술하세요.
class GenericUnionFind:
def __init__(self, elelments):
self.parent = {item: item for item in elements}
self.rank = {item: 0 for item in elements}
def find(self, x):
if x not in self.parent:
raise ValueError(f"원소 {x}가 집합에 존재하지 않습니다.")
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_x] = root_y
self.rank[root_y] += 1
return True
return False
elements = [1, 10, 100, 1000, 10000]
uf = GenericUnionFind(elements)
uf.union(1, 10)
uf.union(100, 1000)
uf.union(10, 100)
find_1 = uf.find(1)
find_10000 = uf.find(10000)
print(f"find(1)의 결과: {find_1}")
print(f"find(10000)의 결과: {find_10000}")- find(1)의 결과는? 1000
- find(10000)의 결과는? 10000
- 이 구현이 왜 큰 수나 해시 가능한(hashable) 모든 타입을 다룰 수 있는지 그 원리를 서술: 딕셔너리는 내부적으로 해시 테이블을 사용한다. 10억 숫자나 문자열이 들어오면 해시 함수를 통해 고유한 버킷 주소로 변환. 그래서 타입에 상관없이 범용적으로 유니온-파인드 구현이 가능하다.
# 초기 원소 및 연산
elements = [1, 10, 100, 1000, 10000]
operations = [
("union", 1, 10),
("union", 100, 1000),
("union", 10, 100),
("find", 1),
("find", 10000)
]
# find(1)의 결과는? find(10000)의 결과는?문제 5.
유니온-파인드의 최악의 경우는 트리가 한쪽으로 길게 늘어선 편향 트리 형태가 될 때입니다. 아래 union_worst_case 연산은 의도적으로 이러한 상황을 만듭니다.
경로 압축이 없는 경우: find 함수에 경로 압축 로직을 적용하지 않고, find_operations를 순서대로 수행할 때 find 함수 내부에서 부모를 찾아 올라가는 연산(루프 또는 재귀 호출)이 총 몇 번 일어나는지 계산하세요.
- 5 + 5 + 5 = 15번
경로 압축이 있는 경우: find 함수에 경로 압축 로직을 적용하여 find_operations를 순서대로 수행할 때, 총 연산 횟수는 몇 번인지 계산하고, 1번과 비교하여 성능이 어떻게 개선되는지 설명하세요.
- 5 + 1 + 1 = 7번. 경로 압축하는 과정 중에 5->4->3->2->1->0 과정으로 루트가 0임을 확인하며 연산 5회 수행.
- 15번 -> 7번으로 성능이 개선되었다.
# 0부터 5까지 총 6개의 원소
# 의도적으로 편향 트리를 만드는 union 연산 (0 <- 1 <- 2 <- 3 <- 4 <- 5)
union_worst_case = [
("union", 0, 1),
("union", 1, 2),
("union", 2, 3),
("union", 3, 4),
("union", 4, 5)
]
# find 연산 목록
find_operations = [
("find", 5),
("find", 5),
("find", 5)
]