https://arxiv.org/pdf/2303.07399.pdf
https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose
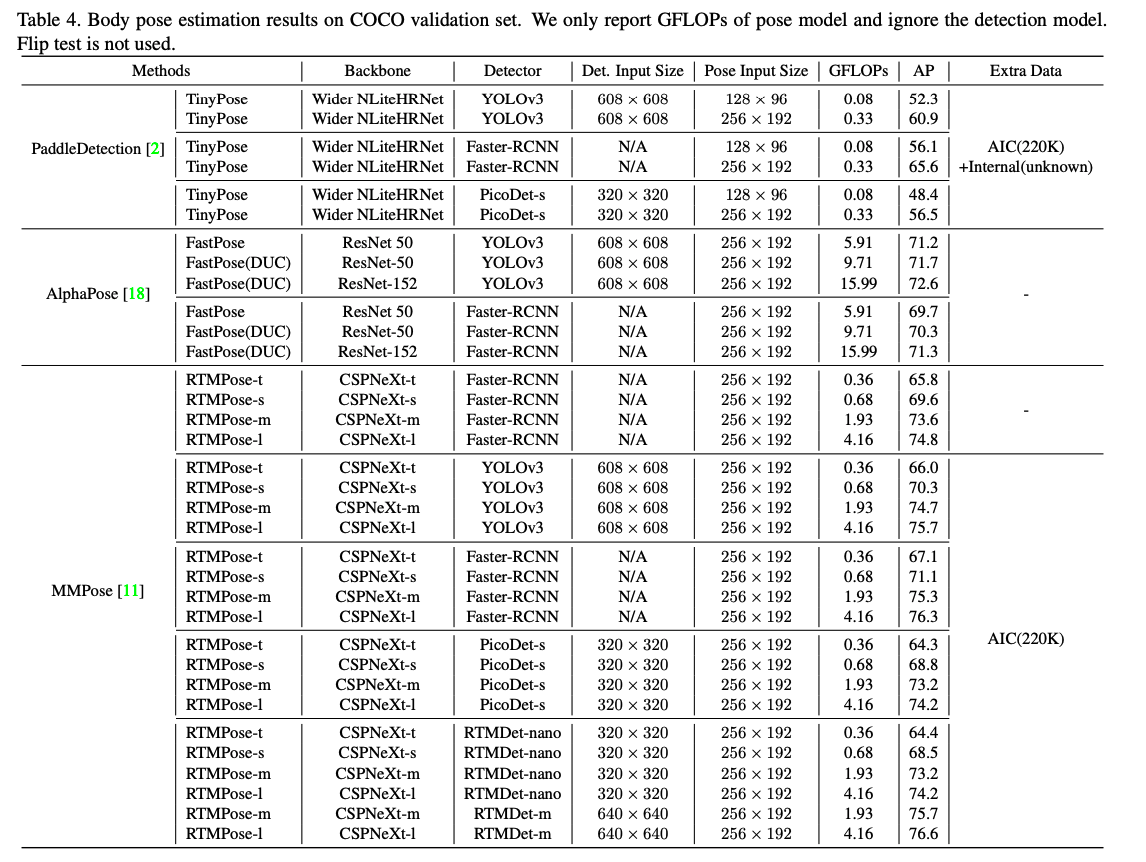
오늘 리뷰할 논문은 RTMPose입니다. 이 논문을 통해서 SimCC를 알게 되었고, 처음에는 히트맵이 아닌 classification을 통해서 좌표를 예측한다는 아이디어에 놀랐습니다. 그래서 사실 이 이점만 가져가야지 했다가 정독해보고 더더더더더 놀랐습니다. 여기서 저자들이 실험을 엄청 했더라구요... 심지어 소수점 대의 AP 상승도 유의미하게 보고 실험을 하나하나 차근차근 진행한것을 보고서 조금 소름 돋았습니다. 아래 표가 그 노력의 흔적입니다.

이렇게 나열한 것이 잘된 것만 올려놓은 걸 텐데, 그럼 실험을 엄청나게 많이 한거잖아요... GPU가 엄청 빵빵하다고 해도 놀랍습니다. 물론, 다른 분들도, 그리고 저도 여러가지 실험으로 시행착오를 겪으면서 모델의 성능을 올리긴하는데.... 배워야겠습니다.🫡
아, 그리고 이 모델은 mmPose에 있기 때문에, 실행에는 큰 어려움이 없습니다. 역시 open mmLab 👍
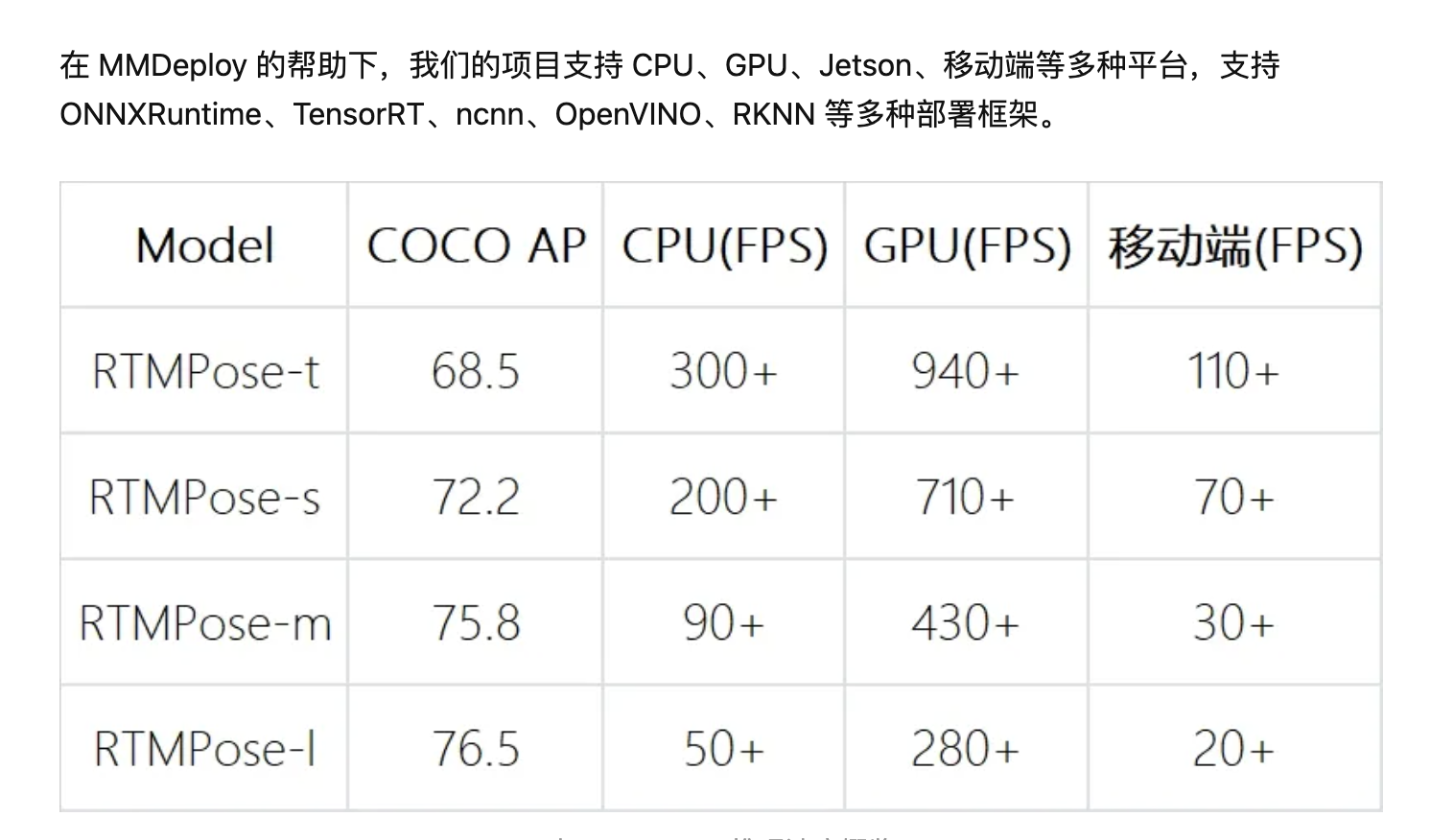
知乎에 가보면 최근에 mmDeploy의 도움을 받아서 아래와 같은 성능(속도)까지 끌어 올렸다고 합니다.. 대단쓰
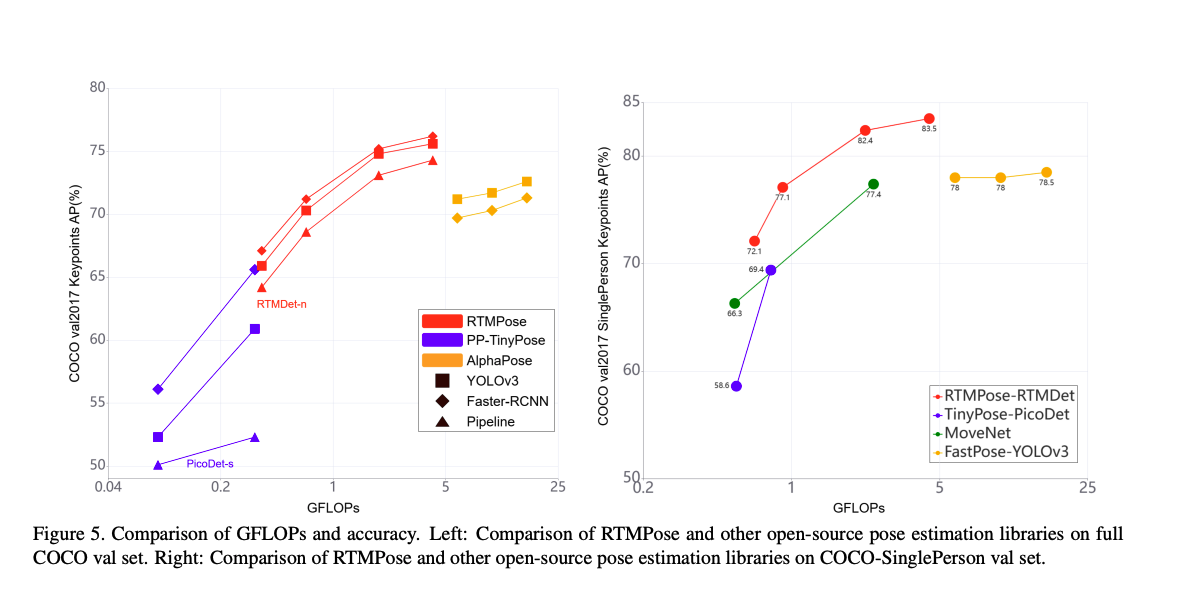
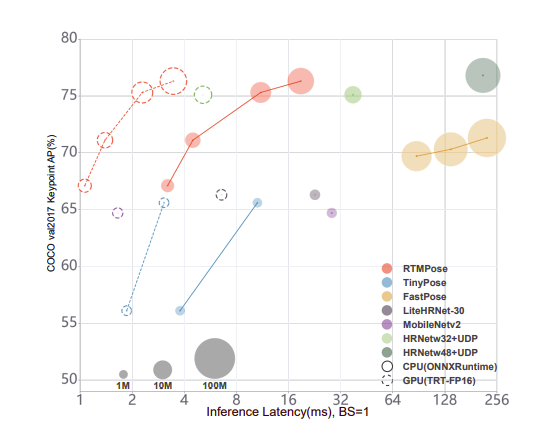
그러나, 조금 아쉬운 점이 있었습니다. 아무리 본인들이 만든 rtmdet을 앞단의 human detection으로 써써 top-down방식을 따랐다고해도, 그 부분을 평가에 포함시키지 않았다는 것은 bottom-up방식을 사용하면서 human detection까지 포함한 모델이 더 빠르고 정확하다면 주장하는 그 의미가 약간은 절감되지 않을까라고 감히 아쉬움을 표현해봅니다. 그리고, 정량평가는 있지만, 정성적인 평가 결과는 없네요 🥲
여튼, 시작해보겠습니다!
Introduction
이 논문에서는 2D multi-person pose estimation의 주요 요소를 패러다임, 백본, localization 방법, 학습 전략, 이용법(deploy)로, 총 5개로 보고, 이러한 요소들을 최적화하여 만든 모델을 RTMPose라고 칭합니다.
- RTMPose는 top-down 패러다임을 따릅니다. 기존에 저자들이 개발한 RTMdet이나 Nanodet-plus를 human detector로 사용합니다.
- 속도와 정확도 밸런스가 잘 맞는 object detection용으로 디자인된 CSPNeXt를 백본으로 사용합니다.
- SimCC 기반의 joint localization을 사용합니다.
- SimCC는 기존의 heatmap방식이 아닌 classification을 이용하는 방식인데, 적은 연산으로도 경쟁력있는 성능을 보여주며, 구조가 두개의 FC layer로 이루어졌기 때문에, 다양한 backend에서 사용하기에 아주 좋습니다.
- 실험을 통한 가장 좋은 학습 전략을 이용합니다.
- 조인트 마다 inference 파이프라인을 최적화합니다.
- latency를 줄이고, NMS를 이용한 pose-processing을 개선하고, 더 좋은 robutness를 위한 필터링을 하기 위해서, skip-frame detection을 합니다.
Methodology
여기서 부터는 좌표 classification 패러다임을 따르는 RTMPose의 roadmap을 보여줍니다.
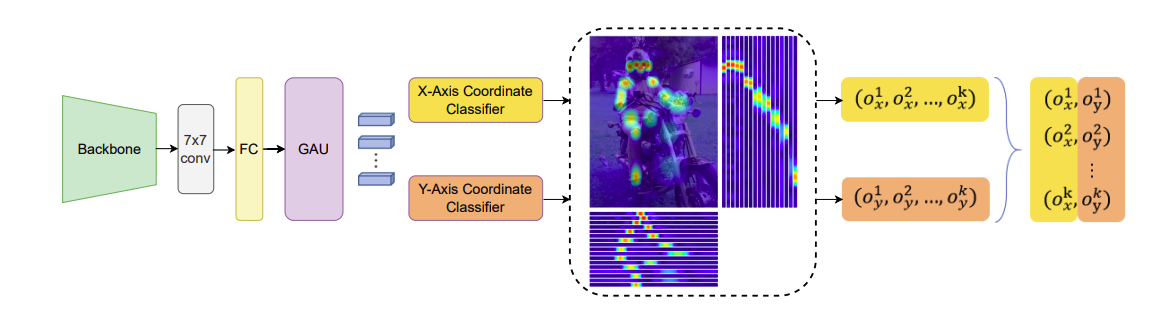
SimCC: 가볍지만 강한 baseline
SimCC의 메인 아이디어는 이렇습니다.
- 수평, 수직의 축으로 나누어서 continuous한 좌표들을 칸칸이 나뉜 label을 부여하는겁니다.
- 예를 들어, 한 이미지에 (2.33, 10.1234)에 특정 좌표가 있다고 합니다. 그럼, 전체 이미지를 가로 48칸, 세로 48칸의 라벨로 바꿔 버리고, 2.33은 x축중에서 라벨3에 해당하고, 10.1234는 라벨11로 있다고 하는 겁니다.
- 여기서 가져갈 수 있는 이 점은 quantization error가 작아지는 데 있죠. 왜냐하면 sub pixel레벨을 생각하지 않아도 되니깐요.
- 구조 또한 간단해요. 백본에서 나온 feature들을 1 x 1 conv로 벡터화된 keypoint representations으로 바꾸고, 두개의 FC layer로 classaification을 하면 됩니다.
- 그리고 학습할 때, GT에 대해서 Gaussian Label을 이용하여 label smoothing을 해주죠.
- 아주 큰 효과를 보았다고 합니다.
Baseline
-
기본 SimCC에서 upsampling을 빼서 complexity를 줄여줬습니다. 아래 표처럼 정확도에 거의 영향을 주지 않았습니다.

- localization을 할때의 쫙 펴진 1 차원 공간에 global 정보를 encoding하는데 효율적인 방법이죠
-
기존 백본인 ResNet-50을 CPSNext-m으로 교체 하여 높은 정확도와 빠른 속도를 얻어냈습니다.
Training Techniques
- Pretraining: UDP method를 이용하여 backbone training을 하여 정확도를 올렸습니다.
- 69.7% AP -> 70.3 AP
- Optimization Strategy: overfitting을 줄이기 위해서 Exponential Moving Average (EMA)를 사용. Flat Cosine Annealing strategy 사용. normalization layer에서 weight decay를 억제.
- Two-stage training augmentations
- augmentation을 강하게 하여 180에포크 돌리고 약하게 해서 30 에포크를 더 돌립니다.
- 사용 augmentation: random scaling, random rotation, Cutout
Module Design
- Feature dimension
- 모델의 성능이 feature resolution과 상관관계라는 것을 발견했고, 그에 맞는 256-dimension을 선택해서 71.2% AP에서 71.4%로 끌어 올렸다고 합니다.
- Self-attention module
- global과 local spatial 정보를 더 잘 이용하기 위해서 self-attention 모듈을 이용하여 keypoint representation을 refine 하였는데, Gated Attention Unit을 써서 속도와 메모리면에서 이점을 얻어 갔다고 합니다.
- 특히, GAU는 transformer layer에서 Gated Linear Unit(GLU)를 통해서 Feed-Forward Networks(FFN)를 향상시켰다고 하고, 아래와 같은 식으로 attention module을 통합하였다고 합니다.
- 는 pairwise multiplication(Hadamard product), 는 activation function입니다.
- 여기서는 아래와 같은 식으로 self-attention을 했습니다.
- s=128, Q와 K는 간단한 linear transformation
- 이 방법으로 0.5%AP를 또 끌어 올렸다고 하네요.(정말 야금야금 대박..)
Micro Design
-
Loss function
-
저자들은 좌표 classification을 일반적인 regression 테스트로 보고, SORD에서 제시한 soft labeling을 따랐다고 합니다.
- 는 rank 가 true metric인 에서 얼마나 덜어져 있는지 만큼 penalize합니다.
-
또한 여기서는 unnormalized Gaussian distribution을 inter-class distance metric으로 채택했습니다.
-
마지막으로, 모델 출력과 소프트 라벨에 대해 Softmax 연산에 temperature 를 추가하여 정규화된 분포 모양을 추가로 조정합니다.
-

-
여기서의 일때 성능이 제일 좋았다고 합니다.(71.9% -> 72.7%)
-
-
-
Seperate
- SimCC에서 수직, 수평 라벨은 같은 를 사용하여 encode되는데, 이때의 가 일때 제일 좋다는 것을 실험적으로 알아냈다고 합니다.
- 는 각각의 수직 수평의 칸 수 (라벨 수) 입니다. (여기서는 그 칸은 bin이라고 칭합니다.)
- 그리고 이 방법은 (72.7% -> 72.8%)의 향상이 있었다고 합니다.
- SimCC에서 수직, 수평 라벨은 같은 를 사용하여 encode되는데, 이때의 가 일때 제일 좋다는 것을 실험적으로 알아냈다고 합니다.
-
Larger convolution kernel
- 마지막 conv layer의 큰 kernel 사이즈가 1 x 1 kernel 이상의 성능을 보인다는 것 또한 발견했고, 73.3% AP를 달성했습니다. (여기까지 왔으면, 정말 무서운 분들인게 분명합니다.....😱)

- 마지막 conv layer의 큰 kernel 사이즈가 1 x 1 kernel 이상의 성능을 보인다는 것 또한 발견했고, 73.3% AP를 달성했습니다. (여기까지 왔으면, 정말 무서운 분들인게 분명합니다.....😱)
-
More epochs and multi-dataset training
- 270 epoch에서 73.5% AP, 420 epoch에서 73.7% AP
- COCO와 AI Challenger 데이터로 pretraining와 fine tuning을 했고, 그 비율도 잘 조정해서, 또!! 75.3% AP로 상승....
Inference Pipeline
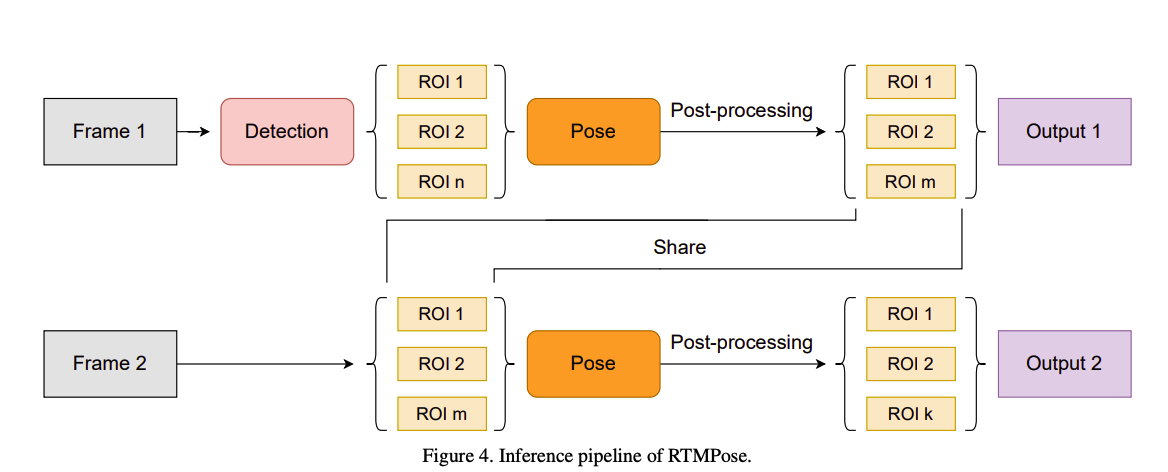
- BlazePose에서 사용한 skip-frame detection mechanism을 사용했다고 합니다.
- 그 방법은 매 K frame마다 human detection이 수행되고, 그 사이 프레임에서는 바로 그전에 마지막 프레임의 bounding box를 썼다고합니다.
- 추가로, smooth한 예측을 위해서 OKS에 기반한 NMS와 OneEuro filter를 post-process에서 사용했다고 합니다.
모델 평가