
이번에 리뷰할 논문은 CVPR 2023에 등재된 논문인데요. 새로운 각도로 pose estimation을 수행합니다. 여기서 새로운 각도라는 것은 Egocentric으로, 우리가 흔히 보던 사진 속의 사람을 보는 것이 아닌, 추정하고자하는 객체의 머리 또는 특정 위치에서 해당 객체를 바라보는 이미지에서 객체의 포즈를 추정하는 방법입니다. 발상 자체가 너무 신선하고 재밌는 것 같습니다. (하지만, 이 분들이 처음 제안한 것은 아닙니다.)
그리고, multi-person 3D pose estimation의 challenge 중 하나는 tracking인데요. 아무리 multi-view를 사용하고, 다양한 알고리즘을 사용해도, 모든 뷰에서 occlusion이 되거나, 겹쳤을때 작은 확률로 서로의 ID가 바뀌어 버리거나 하면..... 골치아픕니다.
그러나, 해당 논문에서는 카메라 한대가 하나의 객체를 따라다니기 때문에 ID가 겹치거나 갑자기 사라지거나 하는 문제를 해결할 수 있죠. 물론, 우려되는 점이 없는 건 아닙니다. 사람이 너무 많은 crowd의 경우, 비용 문제를 해결할 수 없을 것입니다. 모든 건 다 일장일단이 있는거겠죠?😅
이 논문은 간략히 얘기본다면, 저자들이 이 방법 자체를 제시한 것은 아니고, EgoPW의 방식에 depth를 활용하는 방법을 추가하고, 또 이 depth를 더 효율적으로 사용하기 위한 방법론에 대한 내용입니다. 다른 말로하자면, Egocentric 방법론을 더 자세히 알려면, reference 논문들을 살펴봐야한다는 것입니다. (이래서, 논문을 읽으면 다양한 시각도 생기고, 계속해서 알고 싶은 점들이 많아지는 장점이 있는 것 같습니다.😍)
리뷰 시작하겠습니다.
https://people.mpi-inf.mpg.de/~jianwang/projects/sceneego/
https://people.mpi-inf.mpg.de/~jianwang/projects/sceneego/data/camera_ready.pdf
https://github.com/yt4766269/SceneEgo
Abstract
기존 human pose estimation은 물체에 가려지거나 주변 scene으로 인해서 어려움을 겪고 있습니다. 그래서 저자들은 scene을 아는 상태에서 egocentric pose를 추정합니다. 저자들은 fisheye camera를 이용하여 얻은 넓은 뷰로 부터 depth map을 추정하는 depth estimation network와 사람의 body의 occlusion을 완화하는 depth-inpainting network를 제안합니다. 그리고, 2D 이미지 feature와 추정된 depth map을 voxel 공간에 project하여, V2V network로 3D pose를 추론해냅니다. 이런 방법을 이용해서 다른 egocentric pose estimation 모델들의 성능을 뛰어 넘었다고 합니다.
Introduction
- 주변 scene을 파악하여, 정확하고 현실적인 3D pose를 추론하는 첫번째 scene-aware egocentric human pose estimation framework
- egocentric pose label과 주변 scene의 지형적 label을 포함한 synthetic & in-the-wild datasets
- human body를 둘러싼 scene의 depth map을 추론하는 새로운 depth estimation과 inpainting network
- body pose feature의 voxel-based representation과 scence 지형을 함께 활용하여, 기존 연구 결과들을 뛰어넘고, scene context가 고려된 plausible pose 생성
Method

Training Dataset
기존 egocentric pose dataset은 주변 지형정보가 없기 때문에, 저자들은 새로운 데이터셋을 만들었습니다.
- EgoGTA
- GTA-IM 데이터셋과 SMPL-X를 이용하여 제작
- image, depth map(human body, scene), segmenatation(human body, scene), pose label
- EgoPW-Scene
- EgoPW 데이터셋 활용
- image, depth map(only scene), pose label
두 데이터셋은 public으로 자유롭게 사용할 수 있는 데이터로, pose label과 각 씬에서의 depth map을 포함합니다.
Scene Depth Estimator
저자들은 egocentric 관점에서의 scene geometry 정보를 알기 위한 depth estimation을 제안 했습니다. 보통은 사람의 depth를 추론하는 경우가 많지만, plausible pose를 만들기 위해서는 scene의 depth 정보도 아주 중요하기 때문입니다.
해당 논문에서sms 두 단계로 나눠 depth map을 만듭니다. 우선, 두개의 모델로 각각 사람을 포함한 depth map과 semantic segmentation을 추론합니다. 그런 다음, depth inpainting network로 사람에게 가려진 depth를 복원합니다. 이 두 단계가 필요한 이유는 RGB 이미지상의 사람의 시각 정보가 매우 강해 depth estimator에게 무시될 수 있기 때문입니다.
- Depth Estimator Network
- input a single egocentric image
- predict depth map with human body
- model architecture: Revisiting single image depth estimation: Toward higher
resolution maps with accurate object boundaries.
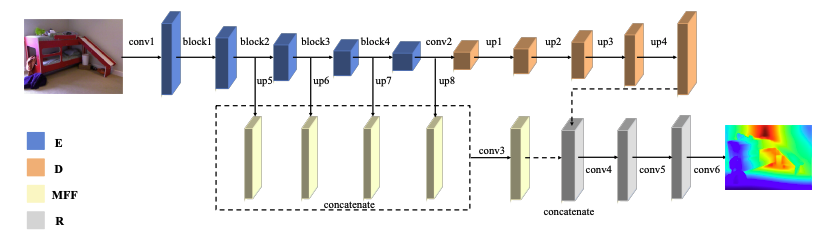
- dataset: NYU-Depth V2 (pretrain), EgoGTA (finetune)
- Segmentation Network
- input a single egocentric image
- predic segmentation mask
- model architecture: HRNet (Object-contextual representations for semantic segmentation 에서 제안)
- dataset: LIP (pretrain), EgoGTA (finetune)
- Depth Inpainting Network
- input the masked depth map
- Hadamard product
- generate the finnal depth map of the scene without human body
- dataset: EgoGTA, EgoPW-Scene
- Loss:
- input the masked depth map
Scene-aware Egocentric Pose Estimator
저자들은 사람의 몸이 scene과 접촉(contact)되어 있다라는 가정하에 연구를 진행했습니다. 그러나 egocentric view에서 contact를 명확하게 추론하는것은 굉장히 어려운 일이기 때문에, 저자들은 모델이 input image로 부터 뽑은 feature들과 추론된 scene geometry에서 가능한/있을법한(plausible) 3D pose를 학습함으로써, 데이터 기반의 방법을 사용하였습니다.
- 우선, EgoPW 데이터셋의 body joint heatmap estimator를 이용하여, 2D body pose feature 를 뽑고 위 섹션에서 나온 depth estimator의 human bpdy없는 scene depth map을 뽑아냅니다.
- 그 후에, fisheye cameral projection model을 고려하여 body feature와 depth map은 정해진(volumetric) 3D 공간에 projection합니다.
- 그리고, volumetric 공간에 표현된 body feature 와 scene depth 를 V2V Network를 활용하여 3D body pose를 추론합니다.
위와 같은 방법은 매번 달라지는 joint 결과들이 volumetric scene위에 있게 해주어 땅 밑에 사람 다리가 들어가는 것 같은 pose-scene penetration이나 다리가 공중에 떠다니는 body floating 현상을 방지해주었다고 합니다.
Scene and Body Encoding as a 3D Volume
volumetric space 만들기 위해서, 저자들은 사이즈의 egocentric camera coordinate system의 사람을 둘러싼 3D bounding box를 만들었습니다. 이때, 카메라의 위치는 3D bouding box위의 중앙으로, egocentric camera coordinate system상의 에서 사이에 위치하게 됩니다. 다은은 그 bbox를 volumetric cube 으로 세분화하고, 각각의 에 위치한 voxel 를 egocentric camera coordinate system의 에서 그 중앙에 해당하는 좌표로 채워집니다.
3D 좌표는 fisheye camera model을 이용하요 egocentric image 공간에 project 합니다. 수식으로 표현하면, 아래와 같은데,
이때의 는 camera projection 함수입니다.
body volumetric representation 는 의 feature map을 2D 좌표를 사용하고 K channel bilinear sampling을 하여 만들어진 큐브 로 채워져 만들어집니다.
그 후, depth map을 3D volumetric 공간에 project합니다. 먼저, fisheye camera proojection function인 을 사용하여, depth map 에서 scene geomtry의 point cloud 를 만듭니다. scene depth map의 volumetric representation 은 아래식 처럼 point cloud 안에 한 점 이 있을 때, 1로 표현되는 (x,y,z)에서의 voxel로 설정된 binary cube 로 채워져있습니다.(은 threshold distance)
저자들은 실험환경을 다음과 같이 설정하였다고 하였을때, 정확도가 가장 높았다고 합니다.
Predicting 3D Body Pose with V2V Network
저자들이 사용한 V2VNet은 V2v-posenet과 같은 구조로, 와 을 합하여 input으로 받고 body joint 3D heatmap 을 만드는 CNN 모델입니다.
traingulation 방법 중 하나를 제안한 논문을 따라, 에 softmax를 씌워 spatial axes에서 body pose 를 얻습니다.
Experiments
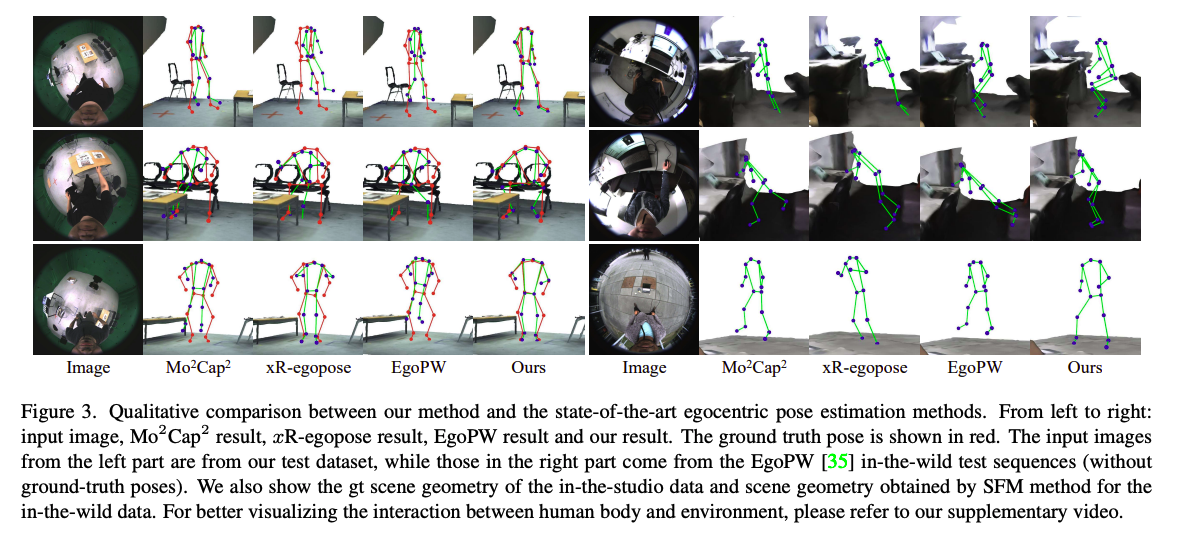
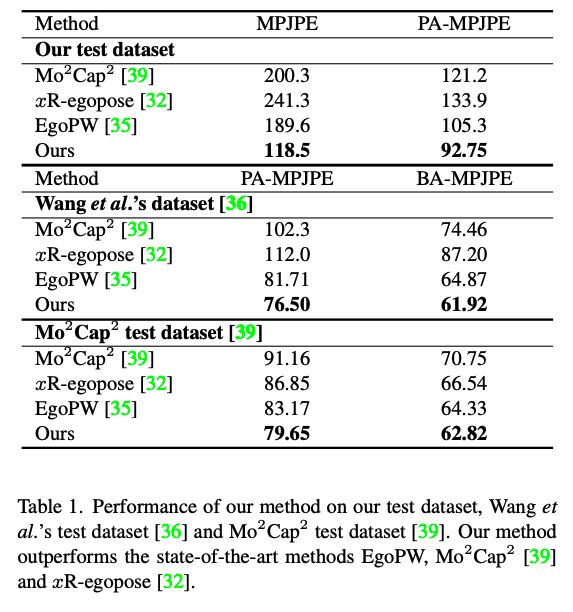
아래는 다른 모델들과 성능을 비교한 이미지와 표입니다.

Ablation Study

Simple Combination of 2D Features and Depth Maps.
Table3를 보시면 저자들이 주장했던 egocentric 2D feature들과 scene depth map이 human body와 주변 scene의 관계를 더 잘 표현한다는 것을 근거있다는 것을 알 수 있습니다.
Optimization
저자들은 제한적인 scene을 고려한 3D pose를 refine하는 optimization baseline으로 그들의 방법들을 비교했다고 합니다. 제일 먼저, egocentric motion 전제를 학습하기 위한 CNN기반의 encoder 와 decoder 를 포함한 VAE를 학습시켰습니다. 다음은 아래 objective function을 최소화 하는 pose 와 일치하는 latent vector 를 찾음으로써 egocentric pose 를 최적화하였습니다.
- : egocentric reprojection term
- : egocentric regularization term
- : contact term
여기서 latent vector 는 EgoPW로 부터 추정된 pose로 초기화됩니다. 과 는 이전 논문에 나온 정의와 같다고 합니다. 그리고 egocentric pose 에서 n번째 조인트는 이고, point cloud 에서의 번째 점은 입니다. 그랬을때, 는 다음과 같이 표현됩니다.
위 식에서, 은 각 조인트와 scene depth map에서의 project된 point cloud 간의 거리를 의미하는데, 만약 이 보다 작다면 scene과 접촉되어 있고 최적화작업이 되어 있다는 것을 의미합니다.
Table 3의 "EgoPW+Optimizer"를 보면 저자들의 방법이 더 좋다는 것을 알 수 있죠. 왜냐하며느 최적화작업은 초기 포즈에 기반하는데, 초반 포즈가 정확하지 않으면 contact이 정확해지지 목하는 문제가 생기기 때문입니다.
Scene Depth Estimator
또한, Table3를 보면, 저자들의 방법론인 Depth map, Depth map without body가 GT에 더 가까운, 즉, 더 정확한 포즈를 추론해냄을 알 수 있습니다.
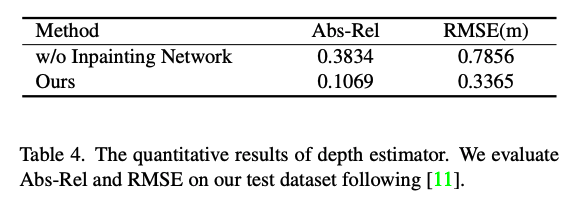
그리고, 마지막으로 inpainting 또한 성능 향상에 도움이 되었음을 확인할 수 있습니다.
conclusion
물론, 저자들의 여러가지 단계와 method를 걸쳐서 이전 연구들보다도 더 좋은 성능을 보였음은 사실이지만, 그들이 기술한 것 처럼, 한계점 또한 있었는데요.
아무래도, 정확도가 depth에 의존하다보니, 여전히 occlusion상황에는 정확도가 떨어지는 경우가 있었다고 합니다.

이렇게 유용한 정보를 공유해주셔서 감사합니다.