본 포스팅은 카이스트 산업및시스템공학과 문일철 교수님의 Introduction to Artificial Intelligence/Machine Learning(https://aai.kaist.ac.kr/xe2/courses) 강의에 대한 학습 정리입니다.
Expectation of GMM
- K-means와 비슷
- 두 개의 상호작용하는 parameter
- K-means: ,centroid 위치
- GMM: 와으로 표현되는 covariance
- Expectation: assignment between clusters and data points
- Maximization: the update of parameters
- 두 개의 상호작용하는 parameter
- Expectation step
- K-means: nearest cluster로 data point를 assignment
- GMM: assignment probability를 활용
- 모든 파라미터는 주어진 상태()
- 처음은 랜덤하게 세팅
Maximization of GMM
- Maximization step
- 미분해서 0으로 두고- constraint가 있으면 Lagrange method사용
GMM 과정
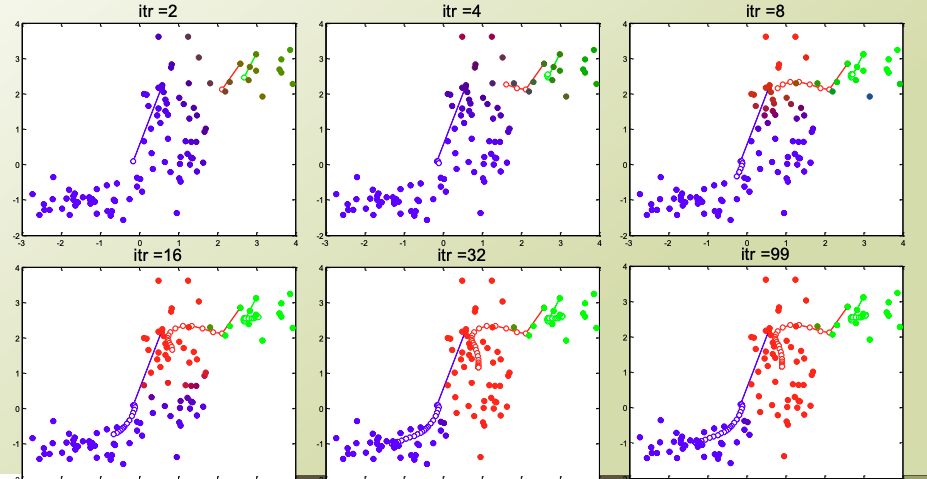
GMM의 특징
- 장점:
- Soft cluster
- K-means: hard cluster
- 훨씬 더 많은 정보
- 잠재적인 요소에 대한 이해
- Soft cluster
- 단점:
- 계산량 증가
- local maximum에 빠질 수도 있음
- parameter K를 정해줘야함(k-means와 같은 단점)

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)