본 포스팅은 카이스트 산업및시스템공학과 문일철 교수님의 Introduction to Artificial Intelligence/Machine Learning(https://aai.kaist.ac.kr/xe2/courses) 강의에 대한 학습 정리입니다.
Unsupervised Learning
: tag(label)이 없는, true value가 모르는 상황에서 패턴을 찾는 방법.
- 군집(cluster)을 찾는 방법
- latent factor를 찾는 방법
- graph structure를 찾는 방법
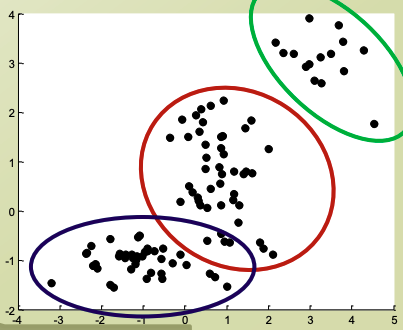
Clustering problems
- 어떻게 라벨이 없는 데이터들을 군집화할 것인가?
- 케이스들의 기초 지식이 없음
- class의 latent(hidden) variable이 있음
- latent classes의 optimal assignment를 찾아야 함.
K-means Algorithm
- K-means Algorithm
- 잠재적으로 내부적인 동력이 K개가 있다고 할때, 이 동력들에 의해서 n개의 데이터가 존재하게 된다라는 가정으오 clustering하는 것.
- 일반적으로,
- J=∑n=1N∑k=1Krnk∣∣xn−μk∣∣2
- 최적화를 통한J를 최소화
- rnk: cluster할 데이터들의 assignment (0 또는 1)
- μk: 중심점(centroid)의 위치
- Iterative optimization
- rnk와 μk가 상호작용하기 때문.
Expectation and Maximization (EM Algorithm)
- J=∑n=1N∑k=1Krnk∣∣xn−μk∣∣2
- E:
- 주어진 파라미터에 의한 log-likelihood의 expectation
- neareat centroid에 데이터 포인트를 assign
- M:
- log-likelihood관점에서 파라미터를 maximization
- assignment가 주어진 상황에서 centroid를 update
- rnk
- rnk=0,1
- discrete variable
- logical choice: μk에 대해 데이터 xn를 assignment
- μk
- dμkdJ=0
- μk=∑n=1Nrnk∑n=1Nrnkxn
K-Means Algorithm의 특징(problems)
- cluster의 개수는 불분명
- 중심정의 초기화를 정하는 방법
- 어떤 초기 중심점은 적당한 결과를 줄 수 없다
- distance metric의 한계점
- Hard clustering
- 군집에 대한 데이터 포인트의 hard assignment
- rnk=0,1
- 이 경우를 smoothing할 수 있지 않을까? => gaussian mixture model
Gaussian Mixture Model
Multinomial Distribution
- Binary varaible
- K options의 경우
- K=6,X=0,0,1,0,0,0인 경우
- ∑kxk=1,P(x∣μ)=∏k=1Kμxk
- μk≥0,∑kμk=1
- binomial distribution의 generalization => Multinomial distribution
- dataset D를 N개의 선택을 할때,
- P(x∣μ)=∏n=1N∏k=1Kμxk=∏k=1Kμk∑n=1N=∏k=1Kμkmk
- μ의 MLE를 어떻게 결정할 것인가?
- Maximize P(x∣μ)=∏k=1Kμkmk
- 조건: μk≥0,∑kμk=1
- => Lagrange Method
Lagrange Method
- 제약 조건에서 local maximum을 찾는 방법
- maximize f(x,y)
- 제약조건 g(x,y)=c
- 1) lagrange function 만들기
- L(x,y,λ)=f(x,y)+λ(g(x,y)−c)
- L(μ,m,λ)=∑k=1Kmklnμk+λ(∑k=1Kμk−1)
- 2)
- dμkd=μkmk+λ=0→μk=−λmk
- 3)
- ∑kμk=1→∑k−λmk=1→∑kmk=−λ→∑k∑n=1Nxnk=−λ→N=−λ
- μk=Nmk: multinomial distribution의 MLE 파라미터
Mixture Model
- 세개의 서로 다른 normal distribution이 있다고 할때,
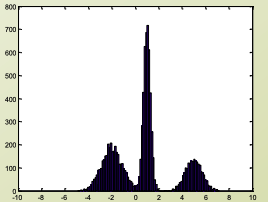
- subpopulation이 존재
- 전통적인 distribution은 fitting이 안되니,
- mix해야 한다
- Mixture distribution: P(x)=∑k=1KπkN(x∣μk,σk)
- Mixing coefficients πk
- 가중치 연산
- ∑k=1Kπk=1,0≤πk≤1
- Mixture componentN(x∣μk,σk): subpopulation의 distribution
- πk를 P(zk)
- N(x∣μk,σk)를 P(x∣z)
- P(x)=∑k=1KP(zk)P(x∣z)
Gaussian Mixture Model
- 데이터 포인트들을 mixture distribution에 있을 수 있게 하는 방법
- P(x)=∑k=1KP(zk)P(x∣z)∑k=1KπkN(x∣μk,∑k)
- 어떻게 mixture로?
- mixing coefficient 또는 selection variable zk
- multinomial distribution을 따르도록 selection은 stochastic하게.
- mixture component
- P(X∣zk=1)=N(x∣μk,∑k)→P(X∣Z)=∏k=1KN(x∣μk,∑k)zk
- 이것은 marginalized probability인데. conditional일때는?
- r(znk)=P(zk=1∣xn)=∑j=1KP(zj=1)P(x∣zj=1)P(zk=1)P(x∣Zk=1)=∑j=1KπjN(x∣μj,∑j)πkN(x∣μk,∑k)
- 전체 데이터셋의 log-likelihood
- lnP(X∣π,μ,∑)=∑n=1Nln{∑k=1KπkN(x∣μk,∑k)}