[week13] 2021/10/25-29
강의 리뷰
Semantic Segmentation 9강 - Semantic Segmentation 연구 동향 1
- HRNet의 필요성
- 기존의 모델들은 특정 이미지 내 모든 특징이 필요하지 않고, 해상도가 줄어들어 효율적인 연산이 가능하며, 각 픽셀이 넓은 receptive field를 갖게 되고, 중요한 특징만을 추출하여 과적합을 방지하기 위해서 해상도를 점점 줄여나가 classification 수행을 한다.
- 하지만 segmentation은 위치정보를 잘 파악해야하고, 높은 해상도를 유지해야하기 때문에 DeconvNet,SegNet,U-Net이 등장했다.
- 그러나 고해상도로 보정하는 방법은 sparse한 feature map을 생성한다는 단점으로 dilated conv또는 pooling 제거가 출현했다. => dense한 feature map. 저해상도가아닌 중해상도를 고해상도로 복원.
- 여전히 높은 time complexity, low position-sensitivity , 강력한 위치정보를 갖는 visual recognition문제에 적합한 구조가 필요함 => HRNet(High Resolution Network)
- HRNet 구조
- 구성요소

- 전체과정에서 고해상도 특징을 계속유지: strided conv를 이용해 해상도를 1/4로 줄임(512->128), unet의 경우 1/20.
- 고해상도부터 저해상도까지 다양한 해상도를 갖는 특징을 병렬적으로 연산: 해상도를 줄여 넓은 receptive field를 갖는 특징 + 고해상도
- 다중 해상도 정보를 반복적으로 융합: Parallel Multi-Resolution Convolution Stream (새로운 스트림은 1/2 해상도)-> Repeated Multi-Resolution Fusions(고해상도=위치정보, 저해상도=풍부한 의미정보) - 고해상도 정보를 저해상도 stream에 전달: Stridded Conv, 저해상도 정보를 고해상도 Stream에 전달: Bilinear upsmapling 및 conv 1*1 conv
- representation head: 해결하고자 하는 문제에 따라 세가지의 서로 다은 출력을 형성
- 구성요소
Semantic Segmentation 10강 - Semantic Segmentation 연구 동향 2
- WSSS(Weekly-Supervised Semnatic Segmenatation)
- 만드는 시간이 짧은 image-level label만 가지고 segmentation
- weak supervision: 테스트시에 요구하는 output보다 학습에 간단한 annotation을 이용하여 학습
- Naive approach
(일반적)
- 가지고있는 정보인 image level label을 활용하기위한 classification모델 학습
- 학습한 classification 모델을 통해서 CAM, Grad-CAM, 혹은 attention추출
- 추출한 결과물은 pseudeo mask로 segmenatation모델 학습에 이용.
=> pseudo mask의 결과가 좋지않다
- CAM기반의 접근
- CAM(Class Activation Mapping) & Grad-CAM
- classification모델을 학습하면서 생성 가능
- 특정 class의 물체가 사진의 어떤 영역에 있는지 유추 가능
- 문제점: 마지막레이어는 꼭 GAP를 가져야함: 일반적인 적용이 불가능, 마지막 레이어에서만 CAM을 만들 수 있음: 어디가 활성화되고 있는지 알 수 없음.
- Grad-CAM: 특정 feature map에 변화가 생길때 class score변화가 크면 중요도가 높다. class socre변화량/feature mape변화량 = 기울기 = 미분값으로 중요도를 정함
- 문제점: 결과가 sharp하지 않음(입력이미지의 크기와 feature map이 작음) - CAM을 sharp하게 만들기 위한 조건(연구)
- 물체의 형태를 알 수 있게 제공 (CRF)
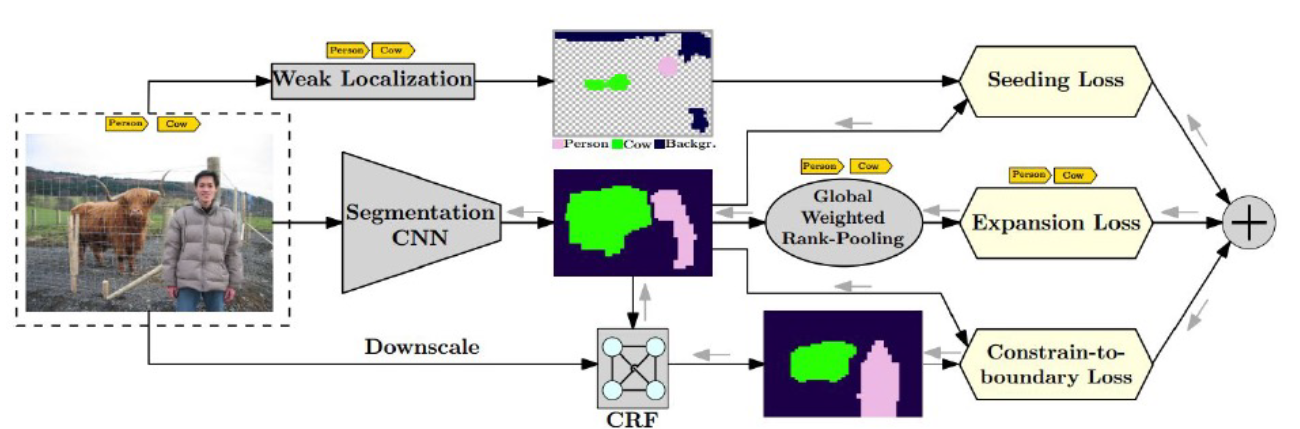
- Transfer learning을 이용
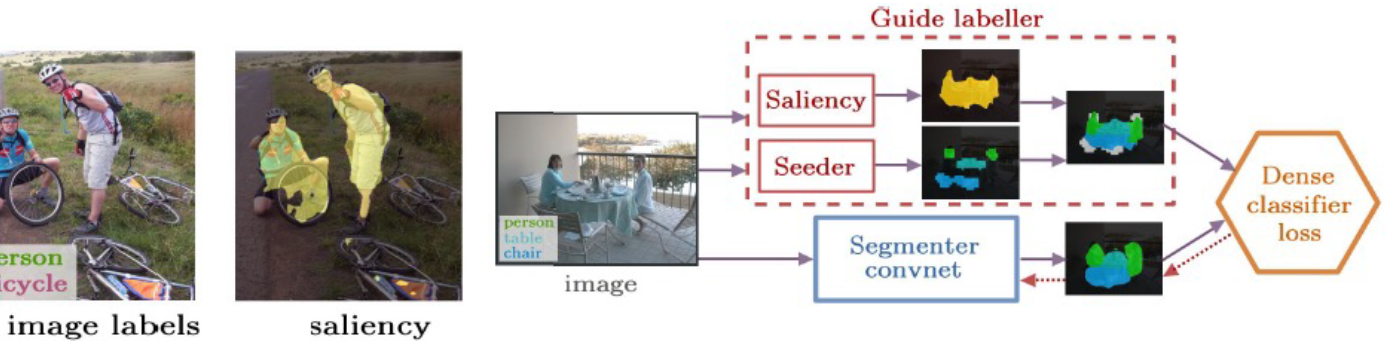
- Self-supervised Learning: 서로 다른 크기 이미지의 CAM의 결과를 동일하게 만들 수 있는 L1 loss사용 (ER loss) - CAM영역을 확장하기 위한 접근(CAM이 특징역역에만 집중하는 경향: classication을 통한 간접적인 학습결과이기 때문, 다른 class임을 확실하게 알 수 있는 특징이 있기 때문, 같은 class여도 다른 모습을 갖는 경우가 있기 때문)
- 특징적인 영역을 지우고 다시 학습및 반복하여 CAM을 얻음(하지만, 번거롭고 class마다 필요한 반복횟수가 다름, over erasing)
- Input 이미지의 ramdom 영역을 지움(하지만, 영역확장의 보장성은 없음)
- 방법1의 Erasing을 네트워크 하나로 수행
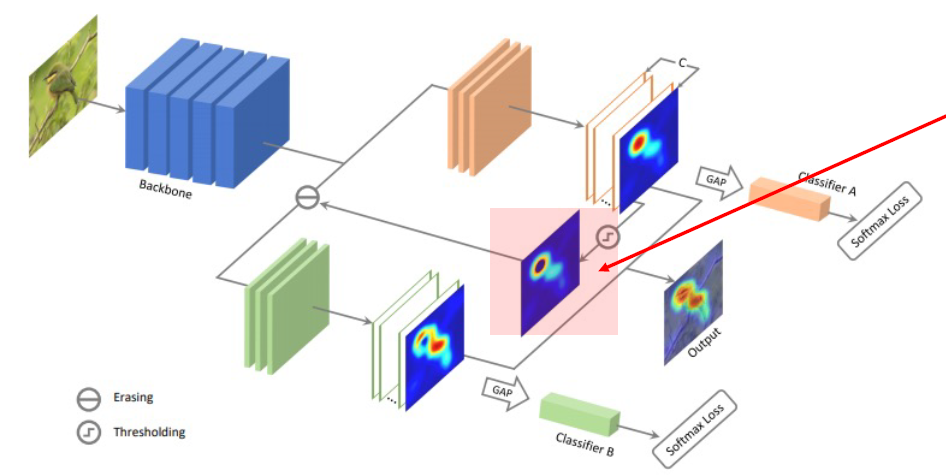
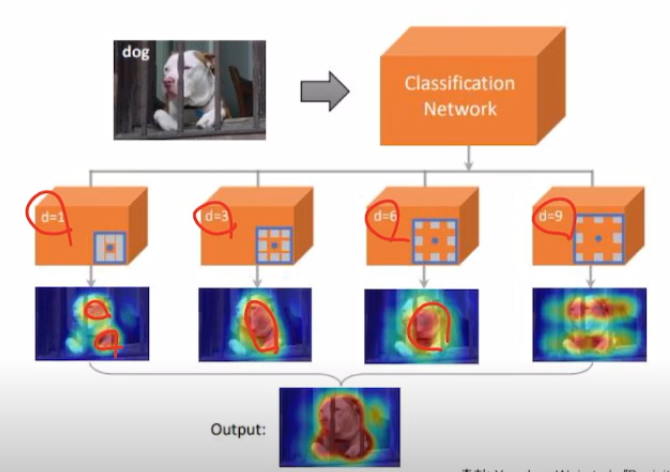
- 다양한 Receptvie field 사용
- Mixup
- CAM(Class Activation Mapping) & Grad-CAM

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)