Semantic Segmentation Competition Wrap-up Report
Naver boostcamp 2기
CV12조 CV-Coin
1. 프로젝트 개요
1.1 프로젝트 주제
: 재활용 품목 분류를 위한 Semantic Segmentation
1.2 프로젝트 목표
: 정상적인 분리배출은 환경에 도움이 되고 재활용되어 자원으로서 가치를 인정받는다. 본 프로젝트는 인공지능을 활용하여 대량생산, 대량소비로 인한 쓰레기 대란을 보다 효율적으로 해결하는 것을 목표로 한다.
2. 수행 과정
: 본 프로젝트는 다음과 같은 실험환경구축을 기초로 한다.
GPU - Tesla V100-SXM2 32GB
OS - Ubuntu 18.04.5 LTS
DE - Jupyter notebook, Visual Studio Code
2.1 탐색적 데이터 분석 (EDA)
2.1.1 Dataset
Dataset : 512*512 사이즈, 4091개의 image(train - 3272장, test - 819장, COCO format)
Class : Background, General Trash, Paper, Paper pack, Metal, Glass, Plastic, Styrofoam, Plastic bag, Battery, Clothing 11개의 Class
2.1.2 EDA
1) class의 annotation 분포
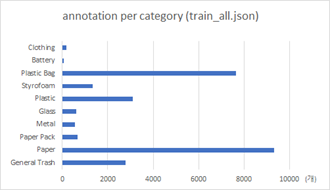
: class 별 annotation 개수는 Paper, Plastic Bag이 9311, 7643개로 비교적 많았고, Battery, Clothing이 63, 177개로 비교적 적은 수를 보였다.
2) image 별 annotation 개수 분포
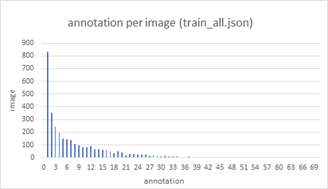
: image별 annotation 개수는 1~12개 범위의 image가 전체의 77.4%를 차지했다. annotation이 가장 많은 이미지는 70개, 가장 적은 image는 0개의 annotation을 가졌다.
3) 라벨링 규칙(Labeling Rule)
• 플라스틱 병에 붙어있는 비닐은 플라스틱 병과 함께 Plastic으로 분류한다.
• Plastic Bag 내부의 쓰레기는 Plastic Bag으로 분류한다.
• Plastic Bag 외부의 쓰레기는 따로 분류한다.
• 병뚜껑은 따로 Metal로 분류하지 않는다.
• 종이 박스에 붙은 쓰레기는 분류 규칙이 일관되지 않았다.
2.1.3 Validation dataset
각 image 별로 annotation category의 최빈값을 뽑아 대표 category를 정한 뒤, stratified k-fold 이론을 바탕으로 각 category 그룹을 5등분하여 validation set을 구성한다.
한 image의 annotation category의 최빈값이 여러 개일 경우 random하게 하나를 선정한다.
battery category의 경우 전체 annotation의 개수가 63개밖에 되지 않기 때문에 예외적으로 battery를 포함하는 image의 대표 category는 battery로 설정한다.
2.2 실험 모델
2.2.1. 개요
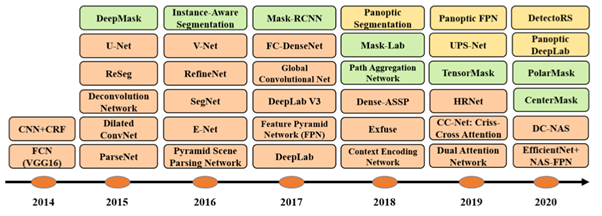
출처 : https://arxiv.org/pdf/2001.05566.pdf
이번 재활용 품목 분류를 위한 과제에 있어 이번 프로젝트에서는 Semantic Segmentation의 시초인 FCN부터 이미지의 전반적인 정보와 지역적 정보를 동시에 활용하고자한 Unet, 그리고 HRNet - OCR과 같이 현재 SOTA를 차지하고 있는 모델까지 가지각색으로 진화하고 있는 다양한 모델을 검토 및 실험 해보았다. 이번 챕터에서는 많은 실험과 검토 끝에 선택한 최종 모델에 대해서 간략히 소개하고, 선택 이유 및 원인을 살펴보고자 한다.
2.2.2. 실험 과정 및 결과
segmentation 모델을 구현하기 위하여 다양한 방법들을 사용했지만, 그 중에서도 주로 open-mmlab에서 제공하는 mmsegmentation을 활용하였다. mmsegmentation library를 통해서 다음과 같은 이점을 얻을 수 있었다.
• 모델, optimizer 및 loss 등 실험에 있어 필요한 많은 요소들이 사전에 구현되어 있어, 다양한 방법을 어려운 구현없이 쉽게 실험할 수 있다.
• mmsegmentation이라는 통일된 라이브러리를 사용하기 때문에, 팀원들 간에 실험을 할 경우 비교적 동일한 환경설정에서 실험하기 쉬웠다.
• 모델의 설명에 해당하는 config 파일에는 정보가 압축되어 있고, 이를 해독하기 쉬워, 팀원들 간 서로의 코드를 이해하고 전체적인 흐름을 파악하기 쉬웠다.
• 유연한 library이기 때문에, 필요한 부분에 대해서는 customizing하여 구현이 가능하다.
• 많은 사람들이 사용하고 있기 때문에, 오류에 대해 문제 해결 방법이 인터넷에 잘 제시되어 있다.
따라서, mmsegmentation을 기반으로 많은 실험을 수행하고 그 결과 중 큰 맥락만을 짚어보도록 하겠다.
실험에서는 upernet에 transformer 계열의 backbone을 합친 모델들이 좋은 결과를 내었고, 그 이외로는 ocrnet + hr을 합친 모델이 이와 견줄만한 성과를 내었다. 그래서 upernet에 transformer을 합친 모델이 왜 좋은 성과를 내었는지에 대한 추측과 모델 선정을 위해 간략한 모델의 소개를 하고자 한다.
2.2.3. Swin-Transformer와 upernet
- Swin Transformer
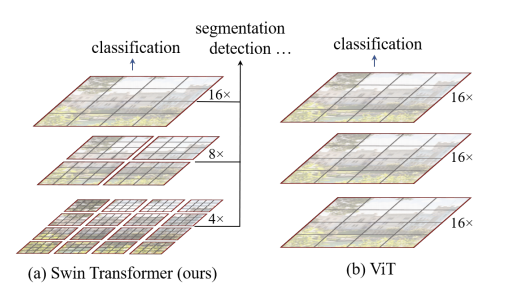
먼저, transformer은 NLP 연구에서 하나의 단어와 다른 단어들과의 관계를 추측할 수 있는 multi-head self-attention을 활용하여 시간과 성능을 획기적으로 개선했다. 이는 NLP분야에서 CV분야에도 적용되기 시작하여 이전에 대부분의 모델을 차지하던 CNN 구조를 벗어나, 다양한 구조의 모델을 세울 수 있도록 하였다. 이러한 결과 끝에, ViT 및 DETR과 같은 논문이 object detection과 segmentation 분야에서 성능을 획기적으로 개선시키며 크나큰 반향을 불러일으켰다. 현재 그 중에서도 swin transformer은 object detection 분야의 SOTA의 입지를 지키고 있으며, semantic segmentation에서는 backbone으로서 활용되고 있다.
Transformer이 어떠한 부분에서 CV에서 큰 활약을 할 수 있었는 지를 살펴보면, 그림 (b)와 같이 이미지를 패치 단위로 잘라 패치를 하나의 토큰으로 보는 방법이 먼저 제시가 되었다. 이는 픽셀 단위에서 패치 단위로 바뀌면서 계산량이 감소하면서, 픽셀 하나하나가 아닌 패치 단위로 보면서 의미있는 정보를 가지게 되었다. 이를 통해 ViT는 image classification의 SOTA를 달성했다. 하지만 토큰들의 크기가 고정되어 토큰에 비해 상당히 크거나 작은 물체에 대한 정보를 잘 담아내지 못하여, 이는 Object detection과 segmentation에서는 큰 빛을 발하지 못 하였다. 이를 해결하기 위하여 Swin Transformer이 제시되었다.
Swin Transformer은 이미지를 다양한 크기의 그림 (a)와 같이 다양한 크기로 자르는 것부터 시작했다. 이렇게 다른 scale을 가진 이미지들은 제각각 다양하고 다른 정보를 가지게 된다. 이러한 이미지들을 전체 영역에 대한 attention이 아닌, 각 window내에 여러 patch로 구성된 window에 대해서만 self-attention을 계산하는 shifted window를 통해 서로 학습시켰다. 이러한 학습은 FCN이 발전해온 과정과 같이 계층적 정보를 활용할 수 있게 하여, 디테일한 정보부터 전체적인 정보까지 전부 다 포함할 수 있도록 구성하였다.
따라서, 실험과 이론적인 기대치에 논거하여 self-attention을 활용한 모델, 그 중에서도 Swin Transformer이 많은 정보를 추출하는데에 있어 가장 강력한 backbone이라고 판단하였다. 그 중에서도 저희는 계산 속도 및 학습 속도보다는 성능에 초점을 맞추었기에 Swin Transformer에서 무거운 모델에 해당하는 Swin-L를 활용하였다.
논문 링크 : https://arxiv.org/pdf/2103.14030v2.pdf - Upernet
현재 모델들이 하나의 task를 수행하기 위해 만들어지는 경우가 많은데, 다양한 vision task를 동시에 학습하여 수행하는 것이 가능한가에 대한 의문에 답하기 위해 만들어졌다. 서로 다른 task를 수행하기 위해서는 이미지에서 규합하는 정보가 달라질 수 밖에 없는데, 이러한 정보를 low level feature부터 high level feature까지의 정보를 모두 활용함으로써 해결하고자 합니다.
UperNet은 기본적으로 다중 레벨 feature를 추출할 수 있는 피라미드 구조와 feature map의 encoder인 ResNet으로 구성되어 있지만 본 실험에서는 위에서 소개한 swin-transformer로 수행하였다. decoder에서는 bilinear interporation을 사용했다. 각기 다른 데이터셋을 합치고 간단한 조정을 통해 만들어진 Broden을 사용하여, 단순한 하나의 데이터 셋을 넘어선 다양한 데이터를 학습할 수 있도록 돕는다.
이 모델의 장점은 단순한 성능이 아닌, multi-task를 동시에 수행하는 데에 있어 수행할 수 있다는 점과, 단일 task를 수행할 때도 우수한 결과를 보인다는 점이다. 이는 다양한 level의 feature을 잘 활용하기에 가능하다. 따라서 기존의 CNN 계열의 모델보다 계층적인 정보를 잘 추출해낼 수 있는 swin-transformer와 합쳐 쓰기에, 우수한 성능을 보인 것으로 사료되어 선택하였다.
논문 링크 : https://arxiv.org/pdf/1807.10221.pdf
2.2.4. 원인 추론
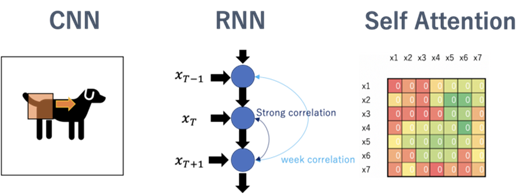
앞서 말한듯, 기존에 활용되던 CNN의 모델들보다 transformer 계열의 모델들이 더 좋은 성과를 보인다. 이러한 결과에 대해서는 명확한 원인 규명은 힘들지만, 여러가지 가설들을 세워보았다.
• 먼저, CNN 기반 모델에서 pixel 단위로 average 및 max pooling으로 정보를 압축하는 것보다 을 패치 단위로 Multi-scale의 이미지들이 self-attention을 통해 서로 중요한 정보 교환이 더 유효하다고 사료된다.
• 특히, transformer의 경우 모델의 크기가 커질 수록 성능이 더욱더 올라가는 현상을 보였는데, 이는 CNN 기반 모델의 경우 데이터 정보가 지역적으로 규합된다는 가정하는 3x3 커널을 통해 데이터가 처리됩니다. 이는 RNN 모델에서 겪었던 long term dependency와 유사성을 띄고 있으며, 이를 해결한 self-attention 기반의 데이터의 경우 처음부터 데이터 간의 규합만을 중시하기에 전반적인 이미지를 보는 경향을 가진다. 이는 CNN 기반의 경우 처음부터 정보가 지역적으로 집계하는 성격이 강하다는 것이고, self-attention의 경우는 모든 특징을 처음부터 고려하기에 그러한 편향이 적은 편이다. 때문에 CNN은 모델이 커지더라도 처음부터 편향적인 성격을 갖기에 빠르게 한계가 올 가능성이 높은 반면, self-attention의 경우는 데이터가 많아질 수록 더 강력해질 수 있다. 따라서 효율을 따지지 않고, 고성능만이 요구되는 이번 대회의 경우 self-attention을 활용한 모델이 더 좋다고 판단된다.
• CNN은 커널을 통해 시야를 점점 넓혀가는 반면, self-attention들은 처음부터 전반적인 이미지를 고려한 후 국소적인 부분을 보게 된다. 이는 이미지를 처음부터 확대해서 보면, 무엇인지 알기 어렵다가 점점 이미지를 전체적으로 보게 되면 잘 알 수 있는 것에 비해, 반대인 경우는 전체적인 이미지를 통해 전반적인 정보의 습득 후 국소적인 부분을 고려할 수 있게 되는 것과 유사하다. 즉, 이는 두 모델의 시야의 차이에서 기반한 결과라고도 판단될 수 있다.
2.3 하이퍼파라미터(Hyperparameter)및 Loss
2.3.1.Loss 함수
Dice loss*0.25 + Cross entropy loss *0.75를 사용했다. Dice loss는 Dice coefficient를 활용하는데 Dice coefficient 는 각 클래스의 TP,FP,FN에 대해
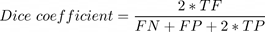
로 구할 수 있고, Dice loss는 각 클래스에 대해 1- Dice coefficient를 모든 클래스에 대해서 평균을 낸
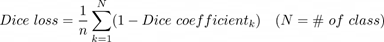
가 된다. Dice loss를 활용하는 이유는 segmentation task 에서 background인 부분이 다른 부분에 비해 월등히 많아 class imbalance에 대한 부분을 dice loss로 잡아주지 않으면 적게 분포하는 class에 대해 예측하지 않는 방향으로 학습이 전개될 가능성이 높기 때문이다.
Cross entropy loss 와 Dice loss 를 가중치를 두고 혼합하여 Cross entropy loss 로 pixel 의 정확도를 유도하면서도 Dice loss 로 클래스의 imbalance를 보정해 주는 방향으로 loss 함수를 정했다.
2.3.2.Optimizer
AdamW를 사용했다. 일반적으로 optimizer를 정할 때, Adam이 널리 쓰인다. 그러나 L2 regularization 텀이 추가된 loss func를 Adam을 이용해서 최적화 할 경우, 의도와 달리 일반화 효과가 떨어질 수 있다. 그 이유는 Adam은 L2 regularization 텀이 포함 된 loss func를 전개해 보았을 때, SGD에 적용한 것 보다 decay rate이 더 작아질 가능성이 있는 것을 확인할 수 있다.이를 방지하기 위해 AdamW는 decouled weight decay를 활용하고, 이는 실제로 그냥 Adam을 활용할 때 보다 더 좋은 학습 진행을 보여준다고 하여 사용하였다.
2.4 데이터 전처리(Data Preprocessing)
- Object Mix: 모델 검증 결과를 카테고리별 IOU로 살펴보았을때, General Trash, Paper pack, Metal, Plastic 카테고리에서 낮은 IOU값을 형성하고 있음을 확인 할 수 있었고 해당 카테고리의 이미지를 늘리는 방법으로 문제를 해결하고자 했다.

데이터를 늘리는 방법으로 Object mix를 활용하였는데, 이번 프로젝트에서 사용한 Object Mix는 해당 카테고리가 있는 이미지에서 Annotation을 활용하여 오브젝트만 추출하고 추출된 오브젝트는 랜덤한 이미지에 합성시키는 방법으로 진행 했다. 낮은 IOU를 가지는 카테고리 중 General Trash 경우에는 추출된 Object들이 모호한 형태를 가지고 있어서 제외 하였고, 카테고리와 크기가 너무 작은 Annotation은 모호하거나, 잘린 형태의 오브젝트를 나타내는 경우가 많았기 때문에 일정 크기 이상의 Annotation을 활용하여 Paper pack, Metal, Plastic 3개의 카테고리에 대하여 1200정도의 이미지를 생성 하였다.
생성된 이미지를 가지고 학습 한 결과 CV에서 mIOU는 크게 향상이 없었지만 LB에서 mIOU는 약 0.015정도 향상되었다.
2.5 TTA및 Dense CRF
2.5.1 TTA(Test Time Augmentation)
TTA란 Train하기전 Data에 augmentation하는 방법이 아닌, 모델의 Test 단계에서 augmentation을 수행하는 것이다. 일반적인 TTA기법으로는 Flip과 Multiscale이 대표적이다. 보다 좋은 모델의 예측 정확도를 중요시하는 competition에서 다수 사용되는 방법이다. 본 프로젝트에서는 Flip과 multiscale을 TTA로 사용했으며 대부분의 모델 결과에서 0.02-0.03 점을 향상시키는 경향을 보였다.
2.5.2 Dense CRF
픽셀단위의 세세한 예측이 필요한 Semantic Segmentation은 feature map의 크기가 줄어드는 과정에서 detail한 정보를 얻기에 어려움이 존재했고, 이러한 문제는 dilated convolution도입을 초래했지만, 여전히 한계는 존재한다. Unary term 과 pairwise term으로 구성된 CRF는 선명하지 못한 예측 결과를 보완하고 이전 방법론들과 함께 적용했을 때 성능을 향상시키는 역할을 수행한다. Dense CRF의 Gaussian kernel은 비슷한 컬러를 갖는 픽셀에 대해 비슷한 라벨링을 하고, 픽셀의 근접도에 따라 smooth수준을 결정한다. 논문에서는 이 과정을 반복할수록 선명한 결과를 보였다. 아래 수식은 CRF 연산방법을 의미한다.

Dense CRF의 장점과 연산을 구성하는 다양한 하이퍼파라미터의 수정에도 불구하고, 실험모델의 최종결과의 경계선이 이미 비교적 명확했기때문에 실제 실험에서 mIoU를 0.001 - 0.003점을 낮추어 점수 향상에는 어려움을 보였 사용하지 않기로 결정하였다.
2.6 앙상블(Ensemble)
2.6.1 앙상블(Ensemble)
앙상블은 다수의 모델을 혼합해 투표함으로써 더 높은 정확도를 재현하는 기법이다. 앙상블의 정확도 상승을 정량화하는 수학공식은 아래와 같다.
위 식에서 실패율이 0.35인 독립적인 25개의 모델을 앙상블 한다고 가정했을 때, 이론상 실패율은 0.06%로 94%의 정확도를 나타낸다.
2.6.2 앙상블 적용
- 시도1. Standard Ensemble(Hard voting)
- 근거: 앙상블은 낮은 정확도의 모델들로 더 높은 정확도의 모델을 구성할 수 있다. 따라서 다양한 모델들의 앙상블을 통해 정확도 상승을 기대하였다.
- 내용: OcrNet, Swin-Base, UperNet, FCN 등 7개의 상위 모델 앙상블을 통해 약 0.01의 LB Score가 증가하였다.
- 결과해석: 일부 모델의 잘못된 값을 버리고 다수 모델의 옳은 선택을 통해 정확도가 상승하였다고 예상된다. - 시도 2. Weighted Ensemble
- 근거: LB score를 기준으로 가장 LB score가 높은 모델에 높은 가중치를 부여함으로써 정확도가 높은 모델의 채택 가능성을 증가시켜 정확도의 상승을 기대하였다.
- 내용: 카테고리별 Validation 정확도를 기반으로 가중치를 부여한 앙상블을 통해 약 0.001의 LB Score가 증가하였다.
- 결과해석: 시도 1의 단점인 수는 적지만 정확도가 가장 높은 모델이 옳은 결정을 했을 때, 그 결정이 버려지는 상황을 극복하여 정확도가 소폭 상승한 것으로 예상된다. - 시도 3. Selective Ensemble
- 근거: 시도1,2의 Ensemble은 모든 모델에 동일한 가중치 부여하거나, 카테고리별 정확도를 기반으로 가중치를 부여하여 투표를 시행하였기 때문에 단일 모델이 특정 카테고리에 대해 높은 정확도를 보이더라도 해당 모델이 채택될 확률은 적다. 따라서 Validation의 특정 카테고리에서 95% 이상의 높은 정확도를 보이는 모델이 투표한 카테고리를 반드시 채택하도록 함으로써 정확도 상승을 기대하였다.
- 내용: 새로운 Swin-L 모델은 Battery 정확도가 95%에 근접한 값을 보였다. 반면, 기존의 모델들은 Battery 정확도가 모두 낮았기에 Swin-L 모델이 Battery라고 판단한 경우 무조건 Battery로 결정하도록 앙상블을 수행하였고, 그 결과 약 0.01의 LB Score가 증가하였다.
- 결과해석: 다수의 모델이 Battery 정확도가 낮을 때, Battery 정확도가 높은 모델의 투표를 강제함으로써 Battery의 정확도가 상승하였고 이것이 LB Score의 상승으로 이어진 것으로 예상된다. - 시도 4. Soft Voting with Accuracy Score
- 근거: 시도2,3의 장점을 그대로 취하며, 모델이 높지 않은 정확도로 클래스를 예측하는 경우 그에 대한 효과를 반영하고자 하였다. 추가적으로 object detection에서 confidence score를 기준으로 ensemble을 하였고 semantic segmentation에서도 이를 부분적으로 적용하고자 하였다.
- 내용: 임의의 모델이 1번 클래스에 대해 p 만큼의 정확도를 갖고 있고 그 모델이 한 픽셀을 1번 클래스라고 예측했을 때, 그 클래스의 score를 p 나머지 클래스의 score를 (1-p)/(전체 class 개수-1) 로 부여하였다. 각 모델마다 클래스 별 accuracy를 가지고 있고 같은 방식으로 여러 모델의 score map을 취한 후 픽셀에 대해 평균 score를 매겨 class를 예측하게 하였다. 이 때, 가장 정확도가 높은 모델에는 이 score에도 높은 weight를 곱하여 더 좋은 가중치를 두도록 하였다.
- 결과해석: 시도2+시도3에서의 score와 시도4 에서의 score를 비교했을 때, 그 score가 거의 일치한 것으로 보아 결론적으로 두 방법 간에 큰 차이는 없는 것으로 보인다
3. 총평
3.1 프로젝트 결과
3.1.1 최종모델 성능
| public | private | |
|---|---|---|
| LB score | 0.776 | 0.745 |
3.1.2 재활용 품목 Semantic Segmentation 시각화

Upernet과 Swin Transformer Large를 통한 semantic segmentation는 위 그림과 성능표를 통해 최종결과를 보인다. 물체가 겹쳐있지 않은 상태에선 경계가 뚜렷하고 높은 mIoU를 보였지만, 물체가 많고 겹쳐있는 상태에선 위치정보와 분류결과가 다소 부족한 경향이 있다. 특히 다른 클래스들과 달리 plastic과 general trash 클래스는 종류와 형태가 다양하여 학습에 어려움이 있어 낮은 mIoU를 보였다.
3.2 개인회고
본 프로젝트에서 이전보다 발전된 모습을 보였다는 것에 함께 해준 팀원들과 스스로를 높이 평가한다. 활발한 토의뿐만 아니라 wandb등의 협업툴을 이용해 협력했다. 각자 모델을 맡아 더 많은 모델 시도해보았고 다양한 하이퍼파라미터, loss 와 augmenatation기법들을 통해 성능향상과 gpu의 효율적 사용에 힘썼다. 다만, 제일 좋은 BEIT모델을 적용하지 못한 점은 아쉬운 부분이다. segmentation을 직접 경험해보며 모델을 다루는 능력과 개선할 점에 대해 생각한 점에서 또 한번의 성장을 했다.
