(참고로, SelfPose: 3D Egocentric Pose Estimation from a Headset Mounted Camera. 와 같은 논문입니다.)
Egocentric pose estimation관련 논문들을 찾아보면, 기본 reference로 사용하는 논문에는 지난번 리뷰한 과 오늘 리뷰할 논문 xr-EgoPose가 많이 등장합니다. 이 두 논문을 완벽히 이해하며 읽으면, EgoCentric pose estimation의 기본 approach는 알고 간다고 해도 무방합니다.
https://arxiv.org/pdf/1907.10045.pdf
https://github.com/facebookresearch/xR-EgoPose
xR-EgoPose는 2019년의 facebook reserach의 논문으로,와 비슷한 연구를 합니다. 3D joint를 뽑아내는 방법과 이에 필요한 데이터셋을 제안하죠.
자세한 내용은 아래 리뷰 본문을 읽어주시면 됩니다.
Abstract
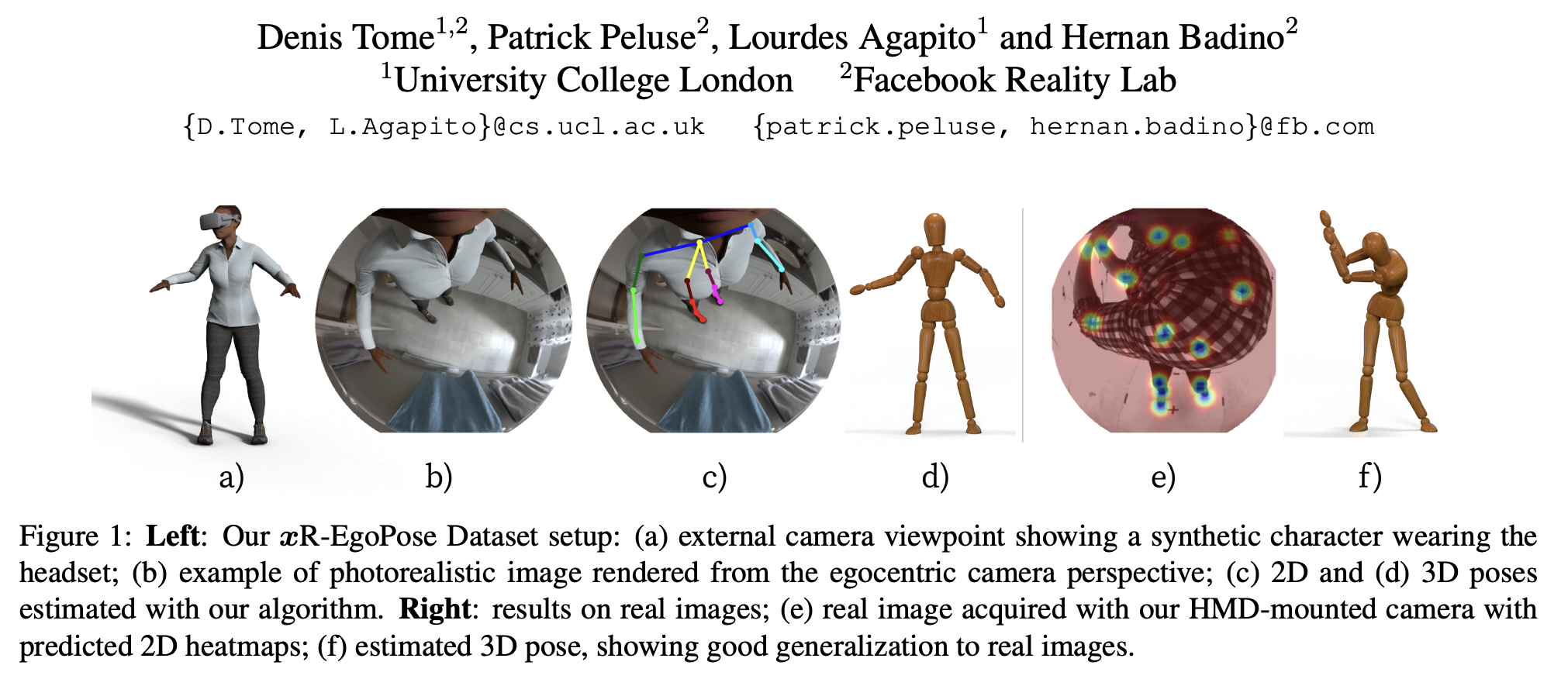
xR-EgoPose는 fish-eye를 머리에 달아 아래 방향으로 촬영한 이미지로부터 egocentric 3D body pose를 추정하는 방법입니다. 저자들은 논문에서 아래 두가지를 이야기합니다.
- encoder-(dual)decoder 구조를 통한 2d joint 추론
- 대량의 egocentric 데이터셋
Introduction
논문 제목의 xR은 AR, VR, MR 기술들을 이야기합니다. 아마 저자들은 타이틀을 통해서 xR기술에 본인들의 연구가 유의미함을 강조하고 싶지 않았을까 추측해봅니다.
우선, fisheye 카메라는 코에서 2cm 정도 떨어진 HMD(Head Mounted Display)에 설치했다는 가정에서 시작합니다. 이런 뷰에서 촬영된 이미지는 lower body에 self-occ가 많이 일어나고, camera distortion으로 upper body와 lower body에 대한 resolution이 다르다는 문제점이 생길 수 밖에 없는데요. 그래서 저자들은 데이터셋을 만들고, self-occ문제와 resolution문제를 해결하기 위한 맞춤형 구조를 제안합니다.
그 구조는 두 스텝으로 되어 있는데요. 바로 3D pose를 추론하는 것이 아니라, 먼저 2D heatmap을 추론하고 두개의 decoder를 가진 auto-encoder로 3D pose를 추론하도록 구성되어 있습니다. 이런 방법으로 uncertainty에 대해 학습하여 최종 결과 정확도를 향상시켰습니다.
저자들의 main contribution을 다시 한번 간략히 정리해보자면, 아래와 같습니다.
- 새로운 encoder-decoder 구조
- 조정 없이, 외부 front-view에서도 일반화할 수 있는 방법
- 383K frame을 가진 public dataset
Challenges in Egocentric Pose Estimation
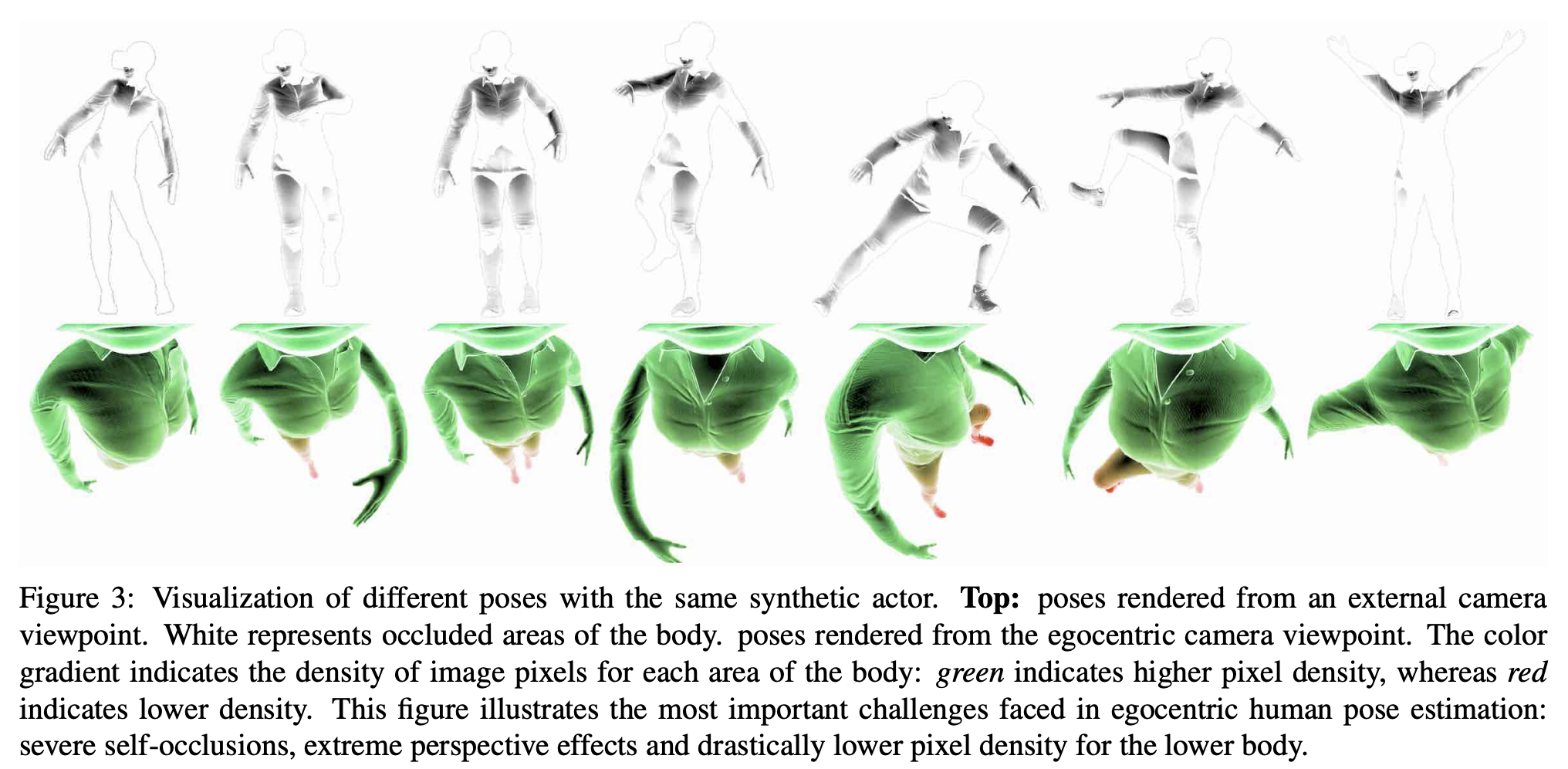
Fig 3은 저자들의 HMD egocentric 셋업의 유니크함을 보여주고 있습니다. 첫번째 열에서는 어떤 부분이 egocentric 뷰에서 self-occ가 일어나는지 보여주고 있고, 초록색은 가장 높은 픽셀 resolution을, 빨간색은 낮은 픽셀 resolution을 의미합니다. 그들의 모델 구조는 upper body와 lower body간의 다양한 resolution으로 인한 uncertainty를 encode합니다.
다른 방법으로는 VR 화면에 fisheye camera를 장착하는 형태의 새로운 synthetic 데이터셋 xR-EgoPose를 만들어냅니다. 이 데이터셋은 데이터셋보다 더 사진같은 느낌이 있으며, 대용량이라고 합니다. 추가로, 실제 이미지에서의 평가를 위해서 이라는 작은 데이터셋도 만들었다고 합니다.
R-EgoPose Synthetic Dataset
저자들의 데이터셋은 캐릭터, 주변 환경, 조명, 액션등의 다양한 환경에서의 scale에 초점을 두었습니다. 액션은 mocap 데이터셋을 사용했고, 카메라의 위치는 headset의 랜덤 위치에 두도록하였습니다.
-
Chracters: 다양한 인종과 피부 parameter, 23 male, 23 female
-
Chothing: 다양한 의상과 신발
-
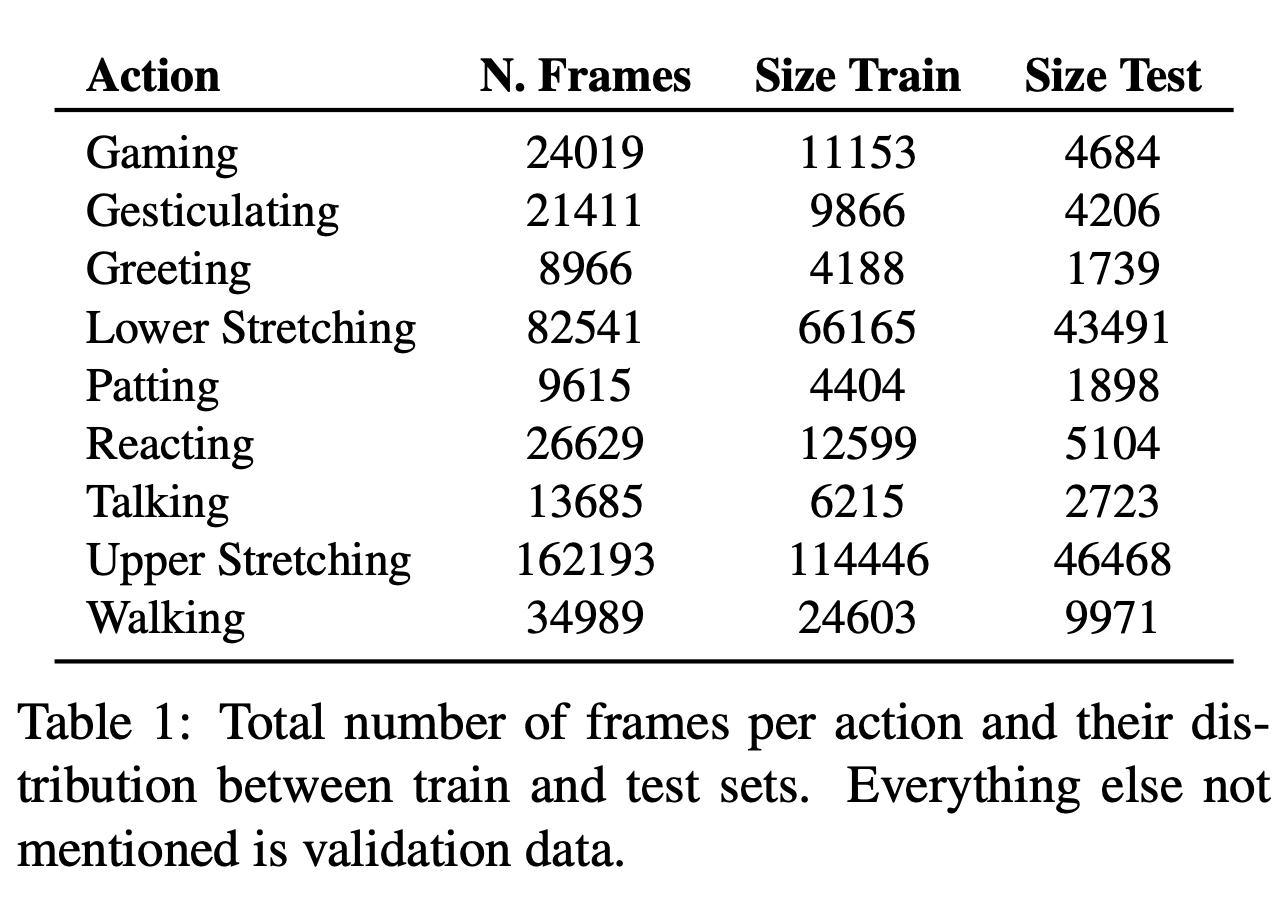
Actions: Table 1
-
images: , 16-bit color depth, 30 fps, RGB, depths, normals, body segmentation 제공
- 학습시에는 color depth 8로 축소
-
Render quality: Maya를 사용한 rednering, V-Ray setup
-
383K frame
- Train: 252K
- Validation: 16K
- Test: 115K
- gender distribution
- Train: 13M/11F
- Validation: 3M/3F
- Test: 7M/5F
Architecture

저자들이 제안한 구조는 Fig.4에서 볼 수 있듯, 두개의 module을 가진 두개의 step이루어져있습니다.
- Module 1: ResNet 구조, 2D joint heatmap 생성
- Module 2: dual branch auto encoder 구조,2D joint heatmap에서 3D 좌표 추론
이렇게 두 개의 모듈로 나뉘었을때, 데이터를 더 잘 활용할 수 있었고, fine-tuning도 용이하기 때문입니다. 또한, 두번째 branch의 경우는 학습에만 필요하고, test에는 필요없기 때문이기도 해서 더 좋은 결과와 성능을 보인다고 합니다.
2D Pose Detection
- Input: RGB image , normalized
- Output: heatmap
- ResNet 101
- 마지막 avg pooling과 FC layer는 deconv(kernel=3, stride=2)로 대체
- Xavier로 weight 초기화
- Loss:
2D-to-3D Mapping
- Input: heatmap
- 2d 좌표를 넣을때 보다, heatmap을 넣으면 uncertainty에 더 좋음
- Output: 3D pose
- 15 조인트 + head
- Encoder에서 embedding
- Decoder 1: 3D 좌표 추론
- Decoder 2: heatmap 생성
- 2D heatmap의 probability density function을 encode하도록 하기위해서
- Loss:
- cosine similarilty error
- limb length error
- , limb of the pose
- : 데이터셋에 2D annotation만 있을때
Training Details
- training set으로 3 epoch
- lr:
- batch normalization on a mini-batch of size 16
- encoder conv & deconv: kernel 3, stride 2
- all layers of encoder use leaklyReLU
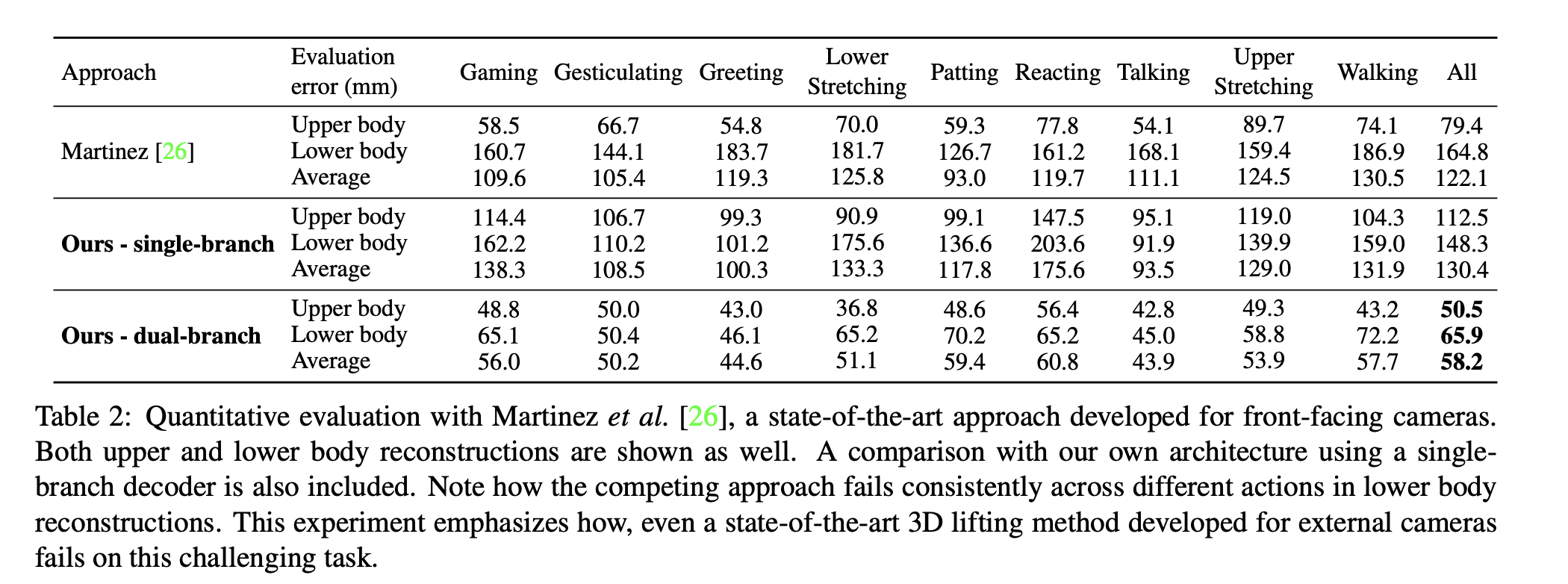
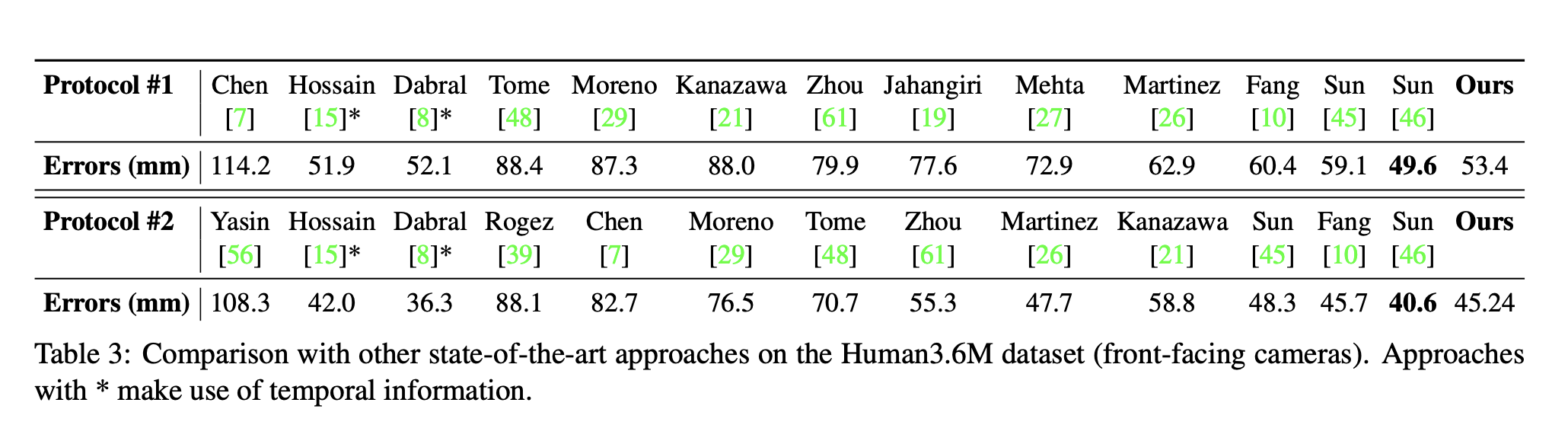
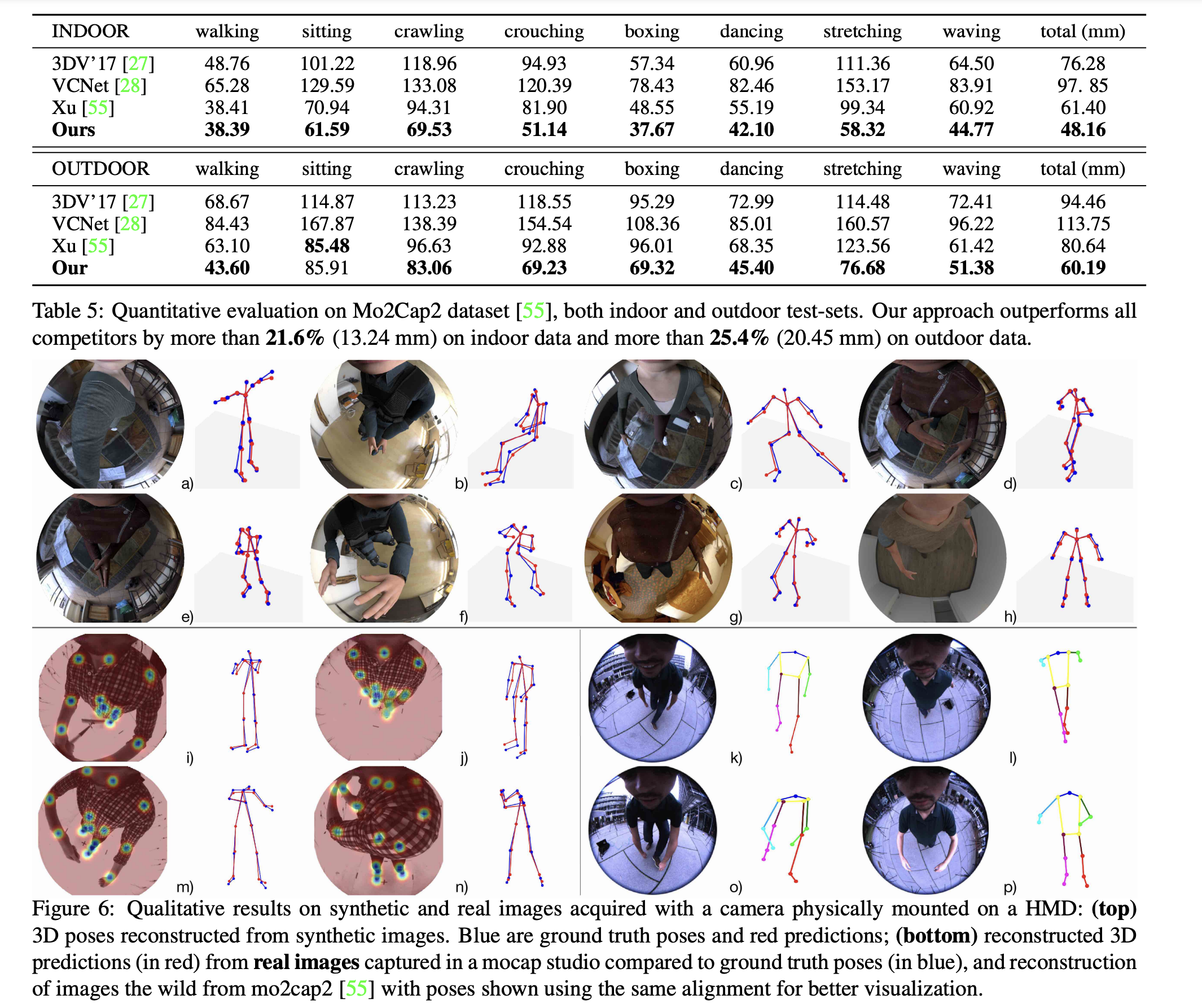
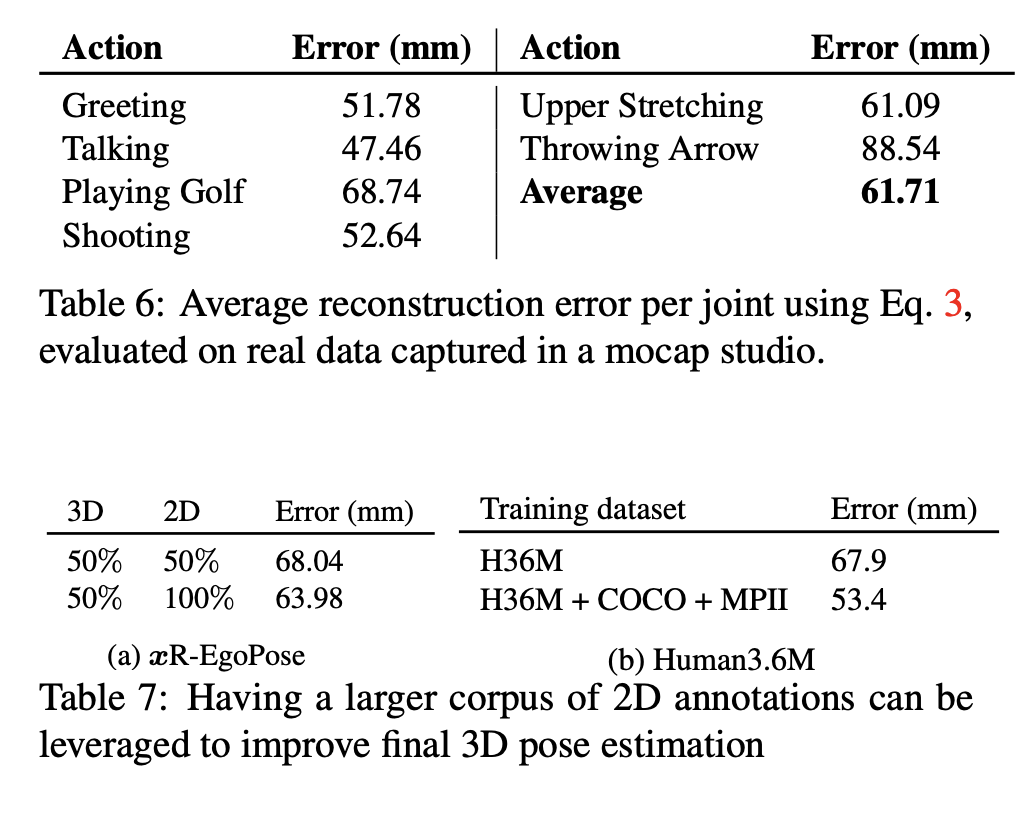
Evaluation



이렇게 유용한 정보를 공유해주셔서 감사합니다.