[논문] Mo2Cap2 : Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Pose Estimation 논문 리뷰
Egocentric pose estimation은 정말 미래지향적인 기술인데요. VR, AR과 같은 곳에 활용할 수 도 있을 것이라는 생각이 듭니다. 최근 많은 기업들이 그 분야에 많은 투자를 하고 있구요. 정확도만 올리고 확장된 기술 개발만 있으면 안성맞춤이지 않을까요? 👍
지난번 논문 Scene-aware Egocentric 3D Human Pose Estimation 를 접하게 되면서, Egocentric pose estimation이 굉장히 흥미롭게 다가왔습니다. 하지만, 내용이 scene에 인식하여 더 나은 pose를 추론하는데 초점을 두다보니, Egocentric pose estimation 자체를 깊이있게 다루진 않았는데요. 그래서 reference 논문인 를 리뷰해보기로 했습니다.
논문을 보면, 데이터 제작부터 시작한 것을 알 수 있는데요. 정말 많은 노력을 들이셨을것 같아 더 흥미있게 진지하게 봤습니다.
https://vcai.mpi-inf.mpg.de/projects/wxu/Mo2Cap2/
https://vcai.mpi-inf.mpg.de/projects/wxu/Mo2Cap2/content/mo2cap2.pdf
오늘 리뷰할 은 야구 모자에 fisheye 카메라를 달아 realtime으로 동작할 수 있는 pose estimation을 제안했습니다. 이 논문의 main contribution은 아래와 같습니다.
- top-down fisheye에 맞는 대량의 데이터셋
- egocentric view에서 3D pose를 단계나눠(disentagled) 추론
이러한 접근은 기존 방법들 처럼 2D를 overlay하는 것보다 더 좋은 성능을 보였다고 합니다.
그럼 좀 더 자세히 살펴 보기 위해서 리뷰를 시작해보겠습니다.
Introduction
워낙 pose estimation 분야들이 많이 발달된 가운데, 현재 필요한 점들은 다음과 같습니다.
- 휴대성
- real-time 성능
- 충분한 길이의 sequence를 소화할 성능
- tracking 성능
그 외에도, occlusion 문제도 있고, 카메라 밖으로 나가버리면 더 이상 추론이 불가능하다는 문제가 있죠.
기존 연구들을 더 살펴 보자면, inertial measurement units (IMUs), multi-camera structure-frommotion (SFM)등이 있는데, 장비나 환경도 셋팅해야하고 실시간으로 안되는 경우도 많고, 무엇보다 가격이 비쌉니다. rokoko의 suit를 예로 들자면, 무려 $2000 입니다...😱
그리고, Egocentric pose estimation의 시초가 된 EgoCap의 경우, 카메라는 두개나 필요하고, 두개의 카메라를 사용해서 무겁고, 모델 초기화 작업도 있어야하고, 긴 영상에는 적합하지 못한 점들이 있었습니다.
그와 달리, 저자들이 제안한 방법은 다음과 같은 장점이 있습니다.
- lightweight, power efficient -> daily mobile use에 적합
- no actor calibration
- 60Hz의 real-time
- suitable for long sequences and automatically recovers from occasional failures

하지만, 저자들의 연구는 다음과 같은 이유로 쉽지만은 않았는데요. 첫째, 기존 연구들과는 다른 방식이여서 데이터가 없습니다. COCO처럼 흔한 데이터를 사용할 수 없는거죠. 그리고, 기존 연구들처럼 바로 3D를 추론하거나, pelvis를 중심으로 잡아 상대적인 좌표를 찾거나 하는 방법은 선성능이 떨어졌습니다. 셋째로, 그리고 위에서 아래로 찍기 때문에, upperbody는 이미지상에서 크게 보이고 lower body는 작게되고, 따라서, lower body의 정확도가 떨어지게 되는 문제가 있었다고 합니다.
그래서!
저자들은 dataset을 직접 만들었고, 3D pose estimation을
1) two-scale location invariant convolutional network로 넓은 perspective와 radial distortion을 가진 이미지로 부터 2D joint를 추론하고,
2) 머리에 고정된 카메라와 radial radial distortion에서 부분 depency를 활용하는 location sensitive distance module을 이용하여 카메라와 joint간의 절대적 거리를 추론하고,
3) fisheye 렌즈의 optical 특성과 거리 측정을 활용하여 2D joint를 back-project함으로써 3D joint를 추정하였습니다.
The Approach
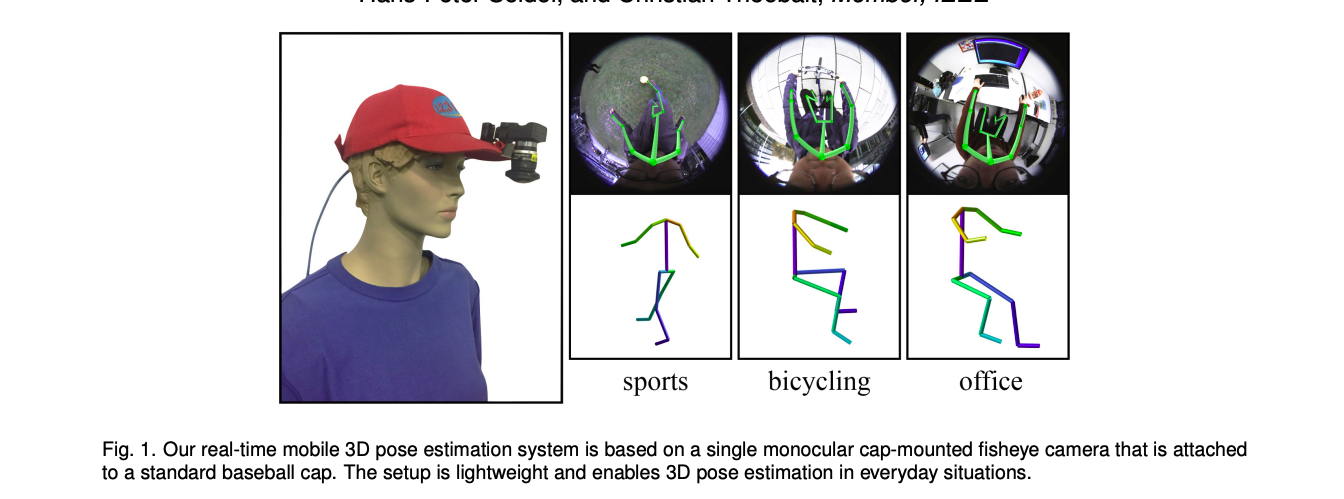
Lightwwight Hardware Setup
저자들은 기술의 실용성을 위해서 175g의 fisheye 카메라 한대만 사용했고, 8cm되는 일반 모자 캡부분에 장착하였다고 합니다. 이 fisheye 카메라는 수직 수평으로 각각 까지의 뷰를 가졌다고 합니다.
하지만, 이런 셋팅은 depth를 사용하지 못한다는 점과 카메라와 이마사의 거리가 짧아 몸이 약간 비스듬히 보인다는 문제가 있는데, 이 단점을 보완하는 것이 그들의 main contribution이라고 합니다.
Synthetic Training Corpus

저자들은 EgoCap과는 환경적 요건이 다르기 때문에, 데이터셋을 활용할 수 없었기 때문에, 직접 만들어서 사용했습니다. 만든 방법은 SURREAL에서 body tecture를 가져오고, SMPL로 렌더링하고, CMU MoCap을 활용하여 동작들을 만들어, 총 3000개의 다른 모션과 7,000개의 body tecture를 가진 총 530,000장의 이미지를 만들었습니다. 그리고, 카메라에서 보이는 것처럼, real-world와 같게 만들기 위해서 조명등을 활용했고, 각도또한 연구환경과 맞게 만들었습니다. 또한 omni-directional camera calibration 툴 박스인 ocamlib을 활용해 calibrate했고, virtual camre에 intrinsic parameter를 적용했습니다. fisheye의 radial distortion을 위해서 custom shader도 사용했다고 합니다.
이외에도, 5000개의 실내외 배경 이미지를 직접 촬용했고, random gamma correction도 적용하여 최대한 실제 이미지들과도 비슷하게 만들었습니다.
- 15개 조인트 지원 (neck, shoulders, elbows, wrists, hips, knees, ankles and toes)
- 저자들이 사용한 fisheye camera coordinate이 적용된 3D pose 좌표
- 2D heatmap형식의 2D annotation
- 3D 좌표를 project size: 한 후
- 각 조인트에 gaussian kernel , std 적용
- 로 downsampling
Monocular Fisheye 3D Pose Estimation
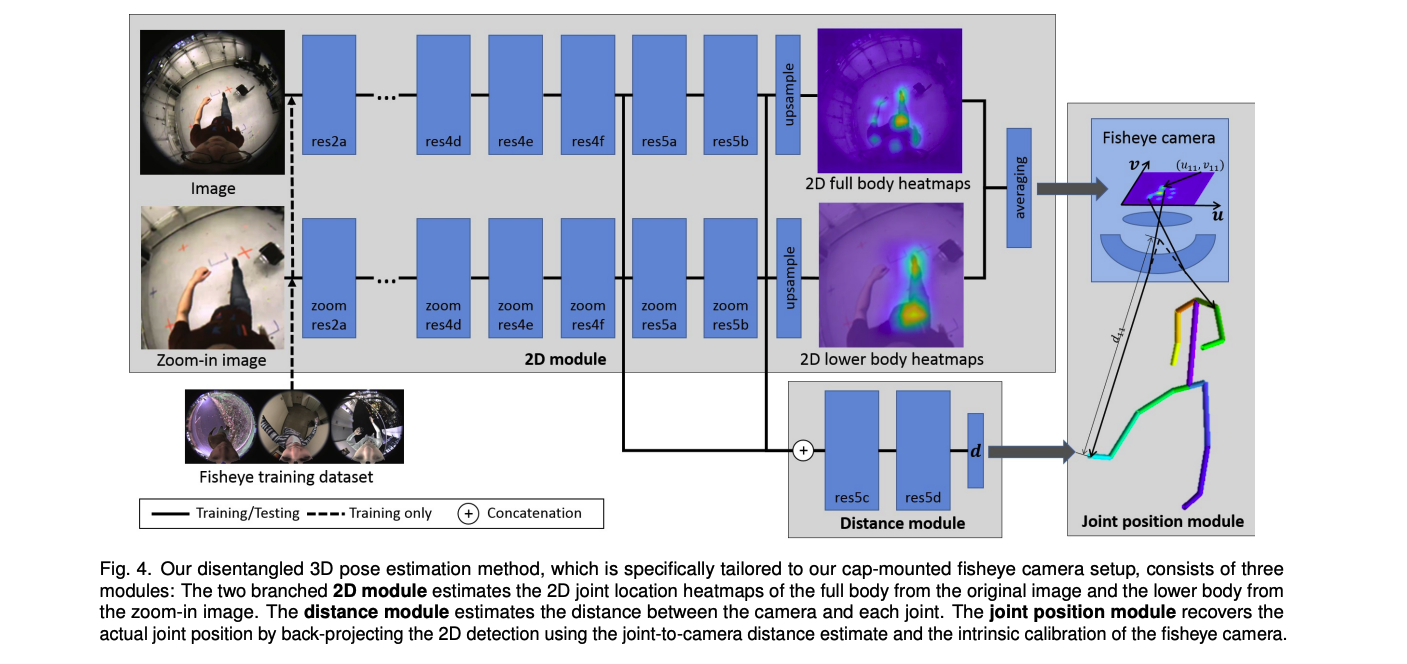
2D module
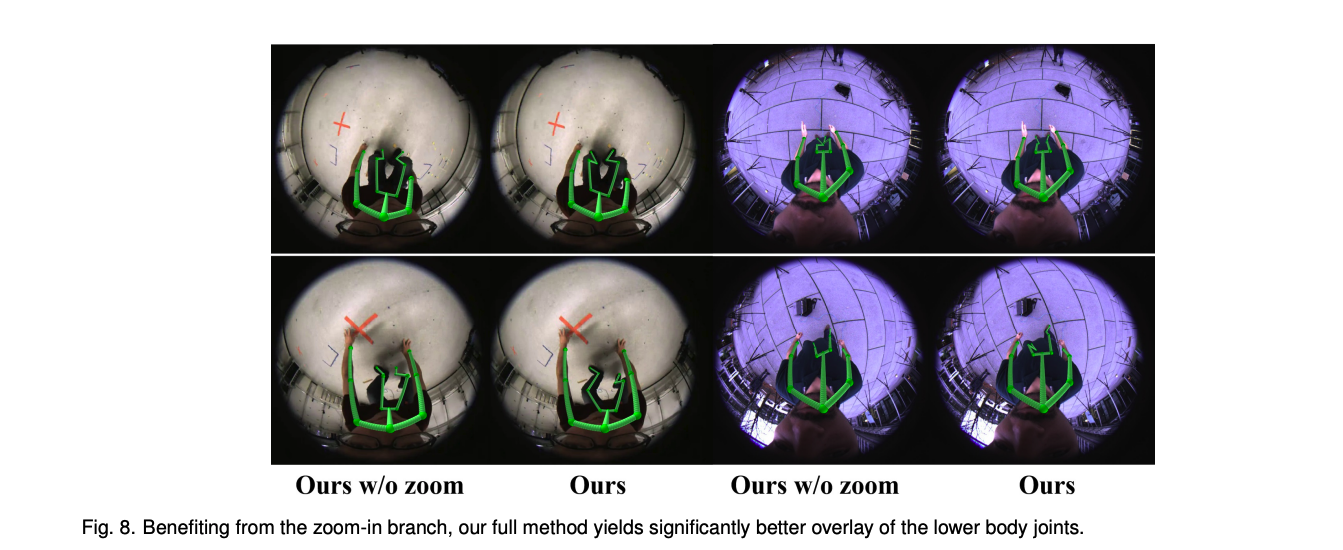
fisheye는 radial distortion때문에, 하체를 작게 보이게 하는데요. 그래서 저자들은 full body와 lower body로 나눠 각각의 heatmap을 추론하도록 하였습니다.
원래 이미지를 통해서, 15개의 조인트에 대한 heatmap을 예측하도록 했였습니다. 그리고, 중앙에서 2배 확대한 이미지에서는 8개의 하체 조인트 (hips, knees, ankles, toes)를 예측하도록 했습니다. 두 개 모두 같은 input size니까, 상대적으로 하체에 대해서는 2배의 resolution을 주게되는 것이죠. 마지막에, 하체에 대해선 평균처리를 합니다.
- 각각의 block
- 15개의 residual block
- 1개의 deconv와 2개의 upsmapling conv
- input
- 마지막 heatmap에 euclidean loss
- 11번째와 14번째에 intermediate supervision loss
- LSP와 MPII로 pretrain
- 직접 만든 데이터셋으로 fine-tuning
distance module
distance module은 higher과 medium level에서의 2D module에서 각 joint의 절대적 camera space depth를 vectorized regression합니다. 이 모듈은 fully conv 구조가 아니라, 머리에 고정된 카메라와 radial distortion이 있는 그들의 환경을 활용할 수 있는 하나의 fuly connected layer를 사용합니다.
- 2 conv + 1 FC layer
- 2D heatmap의 13번째 15번째 output feature를 input으로
joint position module
마지막으로, joint postion module은 distance estimate와 intrinsic calibration을 활용하여 2D 결과를 back-project합니다.
그 과정을 좀 더 상세히 보면,
- 평균 계산된 각 joint에 대한 2D heatmap의 좌표를 읽어냅니다.
- fisheye calibration으로, 각 조인트의 가 3D 로 맵핑됩니다. fisheye camera coordinate systemd의 polynomial fucntion은 아래와 같습니다.
- ,
- 각 joint의 3D position 는 예측된 카메라로부터 조인트까지의 거리 와 방향 벡터를 곱하여 얻어집니다.
Results
- Nvidia GTX 1080 Ti에서 60Hz, forward에 16.7ms
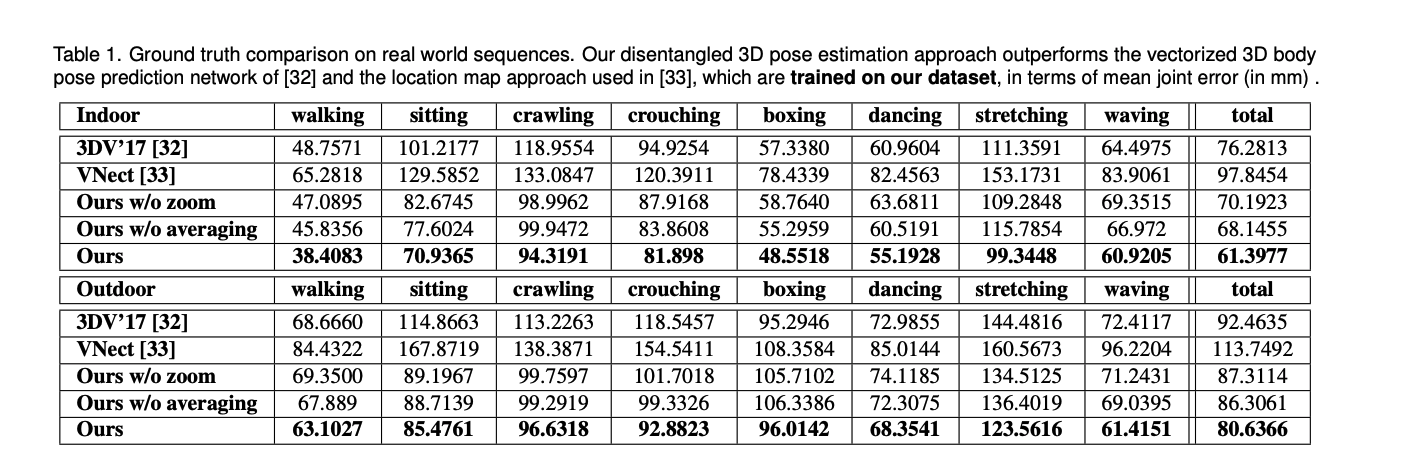
저자들은 위 section에서 설명한 approach들로 기존 연구들보다 더 좋은 결과를 보여줬습니다. 또한 두단계(whole, lower)로 나눠 추론했을때의 성능 향상 결과도 아래에서 볼 수 있습니다.