
본 포스트는 DSBA 연구실의 Business Analytics 강의를 정리한 글입니다.
유튜브 DSBA Business-Analytics
Introduction
1. Skills of Preprocessing
- 데이터 전처리에는 여러 기법들이 요구됩니다. 예를 들어, Normalization, Feature selection/extraction 등이 존재하는데 본 포스트에서는 Feature selection과 extraction을 대표하는 Dimensionality Reduction에 대해 소개하고자 합니다.
우리는 차원축소란 개념을 배우기 전에 좀 더 근본적인(essential) 질문을 던져야 합니다
왜 데이터의 차원을 축소시켜야 하는가?
간단히 예를 들어보겠습니다.현실 데이터를 가공하여 사용하고자 할 때 이 데이터를 설명하는 하나하나의 feature는 차원 하나를 의미하게 됩니다
1. 문서 요약에서는 한 문서를 표현하는 차원의 수는 해당 문서 속 언어의 토큰 혹은 단어의 개수와 동일합니다.
- 과거의 토큰 Representation 기법으론 TF-IDF와 BoW 등이 그러한 특징을 가집니다.
이러한 특징으로 추천시스템에서 사용하는 넷플릭스의 movieLens 데이터나 생물학 데이터 분석에서 중요한 접근 방식 clustering gene expression profiles 등 각각의 데이터가 가지는 차원이 너무 큰 문제를 안게 됩니다.
그렇다면, 모델의 downstream task를 수행하는데 모든 컬럼의 정보가 필요할까? 라는 질문을 던지게 되면
No! 아닐수도 있다.
라는 결론이 나오게 됩니다. 그렇기에, 차원축소는 데이터 분석 시 변수를 어떻게 효율적으로 찾아갈 것인가부터 시작된 아이디어라고 볼 수 있습니다.
- 또한, 본 강의는 산업공학 전공의 수업이므로 반도체 공정을 예로 들게 됩니다.
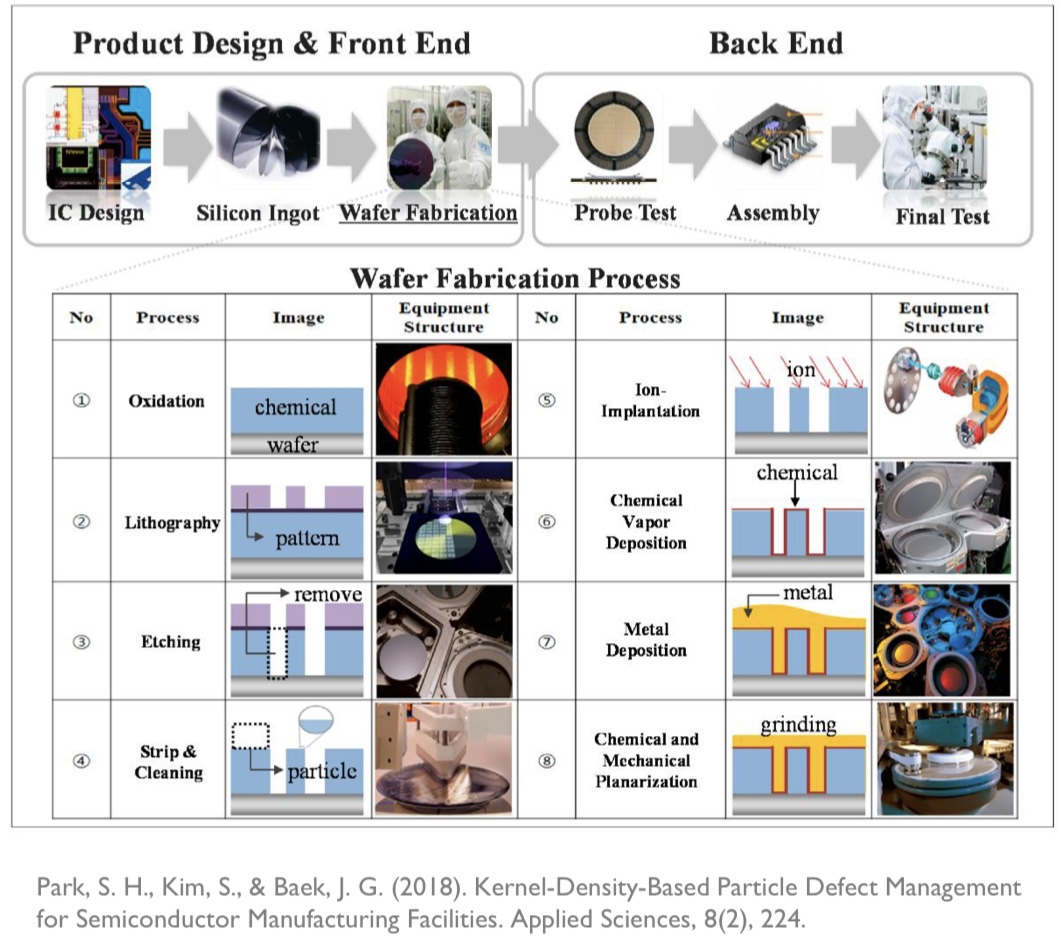
본 그림은 반도체 공정의 process를 보여줍니다.
1. 하나의 제품을 만드는데 8개의 공정이 있고, 그 공정에는 수십 수백개의 step이 존재합니다.
2. 또한, 각각의 step마다 무수히 많은 센서가 존재하게 됩니다.
그렇게되면, 하나의 제품을 만드는 공정 속에서 발생하는 변수의 개수는
= 개수 (각각의 설비에 달려있는 변수 or 센서의 개수)
가 됩니다. 결론적으로, 어떤 공정으로 제품의 수율을 예측하고자 할 때 모든 설비, 센서가 필요하느냐 라는 질문에도 "아닐 수도 있다!"라는 답변이 동일하게 적용 가능하게 되는 것 입니다.
2. Curse of Dimensionality
변수의 개수가 증가하는 상황에서 데이터가 동일한 설명력을 가지려하면 객체의 개수는 지수함수의 형태로 증가하게 됩니다. 그 예로, 아래 그림을 살펴보겠습니다.
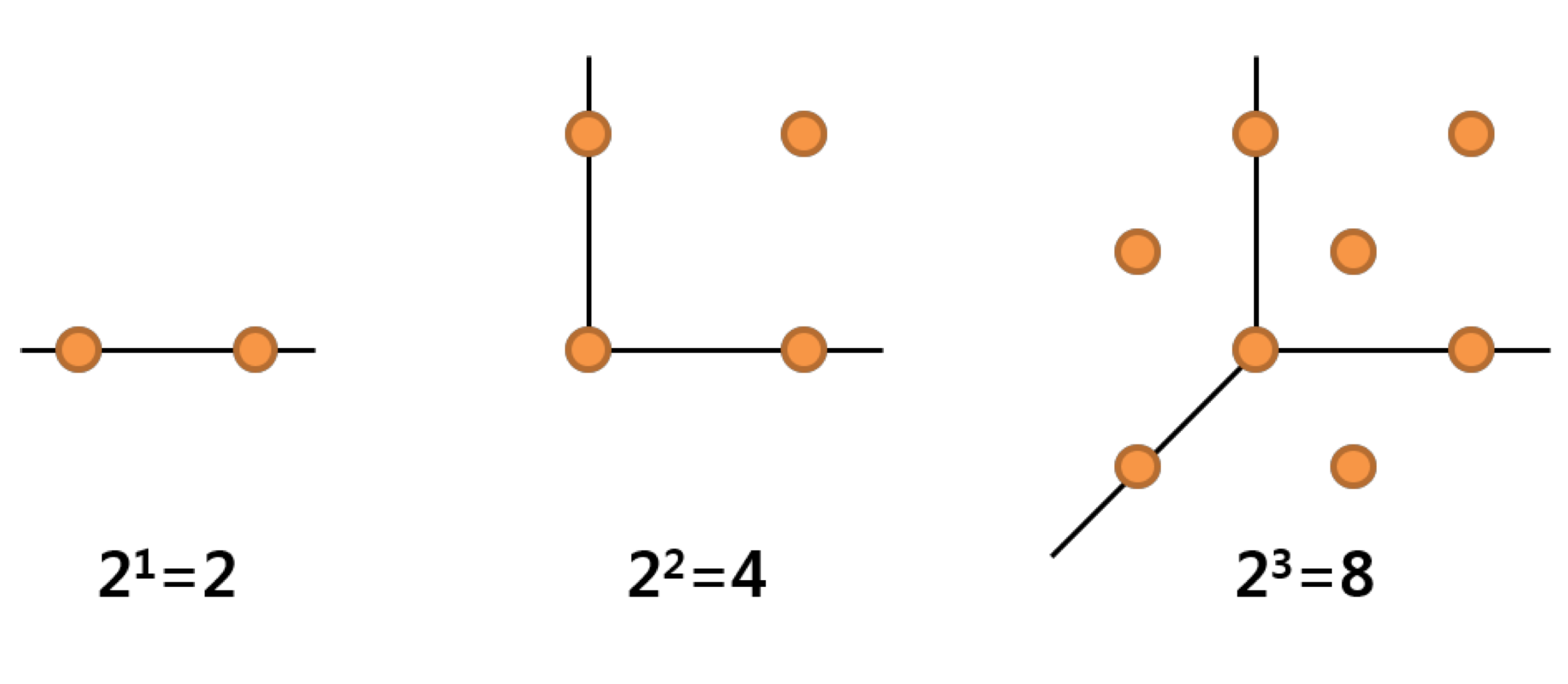
두 점의 거리가 1인 정보를 보존할 때, 1차원에서는 점 두개만 있다면 거리 1을 보존할 수 있습니다. 2차원에서는 두번째 그림처럼 점 4개로 만들어진 정사각형이 있어야 거리를 보존할 수 있습니다. 마지막으로 3차원에서는 점 8개로 이루어진 정육면체가 있어야 합니다. 이건 결국
이만큼의 점이 있어야만 거리가 1을 보존할 수 있다는 뜻이 됩니다.
"If there are various logical ways to explain a certain phenomenon, the simplest is the best" - Occam's Razors
데이터 마이닝에서 오컴의 면도날이 어떤 뜻을 가지게 되냐면, "어떤 현상을 설명하려는 많은 대안이 존재할 때 가장 단순한 것이 가장 좋은 방법이다." 라고 말합니다.
- 즉, 산업공학 관점에서 90% 수율 예측력을 가지는 모델이 두 개가 있다고 가정할 때, 변수 10개만 사용한 것과 변수 100개를 사용한 것 중 변수 10개만 사용하여 수율 90%를 예측하는 모델이 더 좋다고 말할 수 있다는 것 입니다.
2-1. Intrinsic Dimension
-
객체의 본질적인 정보를 보존하는 내재적인 차원을 뜻하며 이 차원은 가끔 원본 차원보다 낮은 차원의 수를 가지게 될 수 있습니다.
-
예를 들어보겠습니다. 아래 그림은 우리가 흔하게 접할 수 있는 MNIST 데이터셋입니다.
 이 데이터셋은 16 * 16 pixel로 총 256개의 차원을 가집니다. 이 데이터를 PCA나 ISOMAP으로 차원 축소를 실시해보겠습니다.
이 데이터셋은 16 * 16 pixel로 총 256개의 차원을 가집니다. 이 데이터를 PCA나 ISOMAP으로 차원 축소를 실시해보겠습니다.
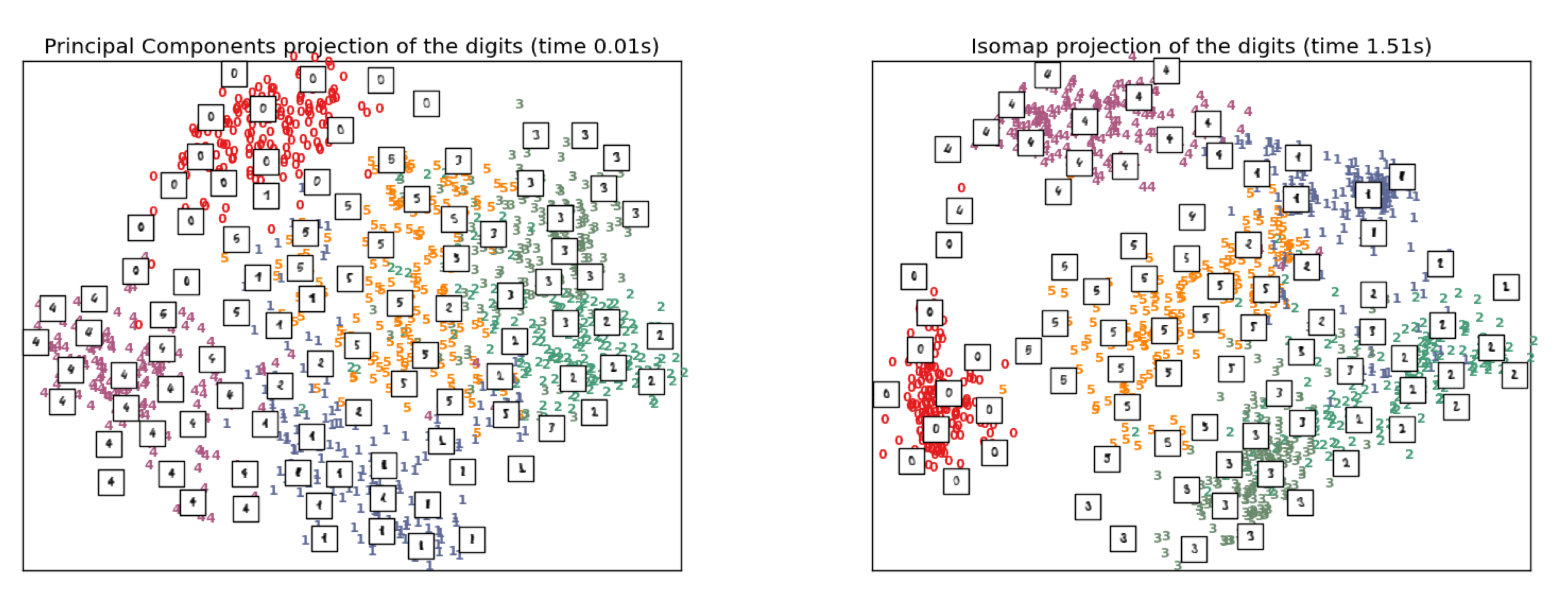 왼쪽은 PCA, 오른쪽은 ISOMAP을 적용한 시각화 결과입니다.
왼쪽은 PCA, 오른쪽은 ISOMAP을 적용한 시각화 결과입니다.
- 그림과 같이 기존 256차원으로 표현되던 MNIST 데이터셋은 단 2차원만으로도 데이터의 특성을 나타낼 수 있게 됩니다.
2-2. Problems caused by high-dimensionality
- 데이터가 고차원을 가지게 됨으로써 발생하는 문제로는 첫 번째, 예측 성능의 저하(degenerate the prediction performence)가 있습니다. 그 이유는, 데이터는 변수의 개수가 많아질수록 noise가 발생할 확률 또한 올라가기에 저하가 생기게되는 것입니다.
- 두 번째, 계산 복잡도(computational burden)의 증가입니다. 이 문제는 예측 모델의 학습 및 적용 과정에서 가장 큰 영향을 미치게 됩니다.
- 세 번째, 일반화된 능력(generalization ability)을 가지는 예측 모델을 유지하기 위해서는 많은 수의 데이터가 요구됩니다. 이 문제 또한 계산 복잡도, 컴퓨팅 리소스 측면에서 문제를 일으키게 됩니다.
이러한 문제를 해결하기 위해서 통상적인 세 가지 해결책으로는
1. 도메인 지식의 활용
2. Lasso, Lidge 등 회귀 모델에 존재하는 regularization term을 목적 함수에 사용
3. 정량적인 축소 기술을 적용
입니다.
2-3. Summary
정리를 해보자면, 이론적으로 모델은 변수의 개수가 증가할수록 모델의 성능 또한 올라가게 됩니다. 하지만, 이 가설은 "모든 변수는 독립적인 관계를 가져야한다."라는 다소 무리한 조건이 충족되어야만 합니다.
-
실제로는 모델의 성능은 변수간의 의존성과 노이즈로 인해 저하되는 것이 현실입니다.
따라서, 차원 축소의 목표는 가장 적합한 성능을 낼 수 있게 만드는 변수의 부분집합을 정의하는 것 입니다.
가장 적합한 집합을 찾게되면 아래 4가지의 효과를 가져올 수 있습니다.
1. 변수간에 상관관계를 제거할 수 있습니다. 변수들 간의 상관관계가 존재하면 다중공선성에 의해 통계 모델의 성능을 저하시킬 수 있는 문제가 있습니다.
2. Post Processing이 단순해집니다.
- 그 예로, 적은 수의 변수만을 사용한 모델은 각 변수의 중요성을 이해하고 설명할 수 있게 되기 때문입니다.
3. 관련된 정보는 유지하면서 중복되거나 불필요한 변수를 제거할 수 있습니다.
4. 시각화가 용이해집니다.
2-4. Taxonomy of Dimensionality Reduction
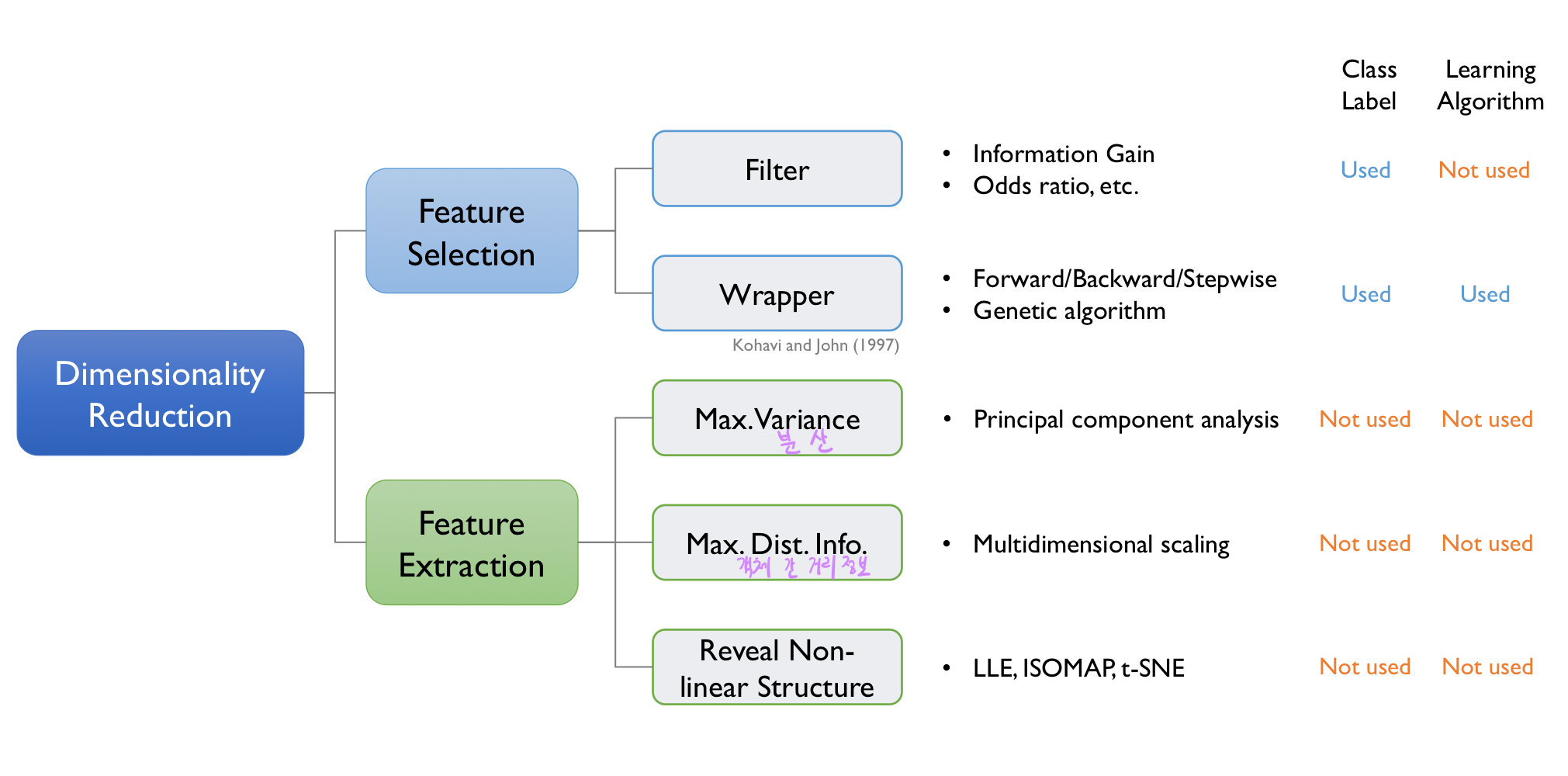
- Feature Selection(변수 선택)에서는 Filter 방식과 Wrapper 방식이 있습니다. 변수 선택 방법은 class label을 사용한다는 특징이 있습니다.
- Filter : 변수 중요도 관점에서 필터 방식은 지도/비지도 방식이 갈리게 되는데, 차원 축소 관점에서는 비지도 학습에 가깝다고 볼 수 있습니다.
- 그 이유는, Information Gain, Chi-squared Test는 클래스 레이블과 각 변수의 상관성을 평가하는데 사용됩니다. 이 과정은 단순히 변수의 순위를 매기는 데 활용될 뿐, 변수 간의 상호작용이나 모델의 학습 과정에 깊이 개입하진 않습니다.
- 즉, 클래스 레이블을 사용하더라도 데이터의 구조적 특성을 중심으로 동작하기 때문에 학습 알고리즘을 전혀 고려하지 않는 점에서 비지도 학습의 특성을 일부 띠게 됩니다.
- 또한, Wrapper 방식과는 다르게 Feedback Loop가 존재하지 않아 One-time으로 변수 선택을 진행하게 됩니다.
- Wrapper : 알고리즘을 사용해 피드백 루프를 돌면서 사용하는 알고리즘에 가장 적합한 변수의 부분집합을 찾습니다.
- Filter : 변수 중요도 관점에서 필터 방식은 지도/비지도 방식이 갈리게 되는데, 차원 축소 관점에서는 비지도 학습에 가깝다고 볼 수 있습니다.
- Feature Extraction(변수 추출)은 클래스 레이블 정보와 알고리즘을 전부 사용하지 않습니다. 즉, 데이터의 본질적인 정보를 찾아 최대한으로 보존하면서 차원을 줄여나가는 방식입니다.
- 그렇다면, 데이터가 가진 본질적인 정보가 무엇이냐라고 물을 때 아래 방법을 통상적으로 사용하게 됩니다.

-
Max Variance : 분산을 최대화하는 방법입니다. 분산은 데이터의 값들이 평균으로부터 얼마나 퍼져 있는지를 나타내는데 분산이 크면 다양한 값(변동성)을 포함하고 있다는 의미이며 데이터에 포함된 정보량도 많을 가능성이 높다는 것을 의미하며, 분산이 작다면 데이터가 특정 값 근처에 집중되어 있어 대부분의 값이 비슷하여 중요한 정보를 많이 잃을 가능성이 있다는 의미입니다.
-
즉, 2차원 데이터가 있을 때 분산이 큰 축은 데이터의 중요한 변화를 담고 있고, 분산이 작은 축은 데이터의 노이즈나 중요하지 않은 정보가 담겨있을 가능성이 크다는 뜻 입니다. 그렇기 때문에, 분산을 최대화하면 데이터의 주요 패턴을 유지하면서 중요하지 않은 정보를 제거할 수 있다는 것 입니다.
-
대표적인 예로, PCA가 있습니다. PCA는 분산을 최대화하는 새로운 축(주성분, Principal Component)를 찾기 위해 공분산 행렬을 계산합니다. 공분산 행렬의 고유값(Eigenvalue)와 고유벡터(Eigenvector)를 이용해, 데이터의 분산을 가장 잘 설명하는 방향(고유 벡터)를 찾습니다. 고유값이 클수록 해당 고유벡터(축)가 설명하는 분산이 크다는 뜻입니다.
-

- Max Dist Info : 객체 간의 거리를 최대화하는 것 즉, Pairwise Distance Information을 최대화하는 것입니다. 그리고 이것이 사회과학에서 많이 쓰이는 다차원 척도법(Multidimensional Scaling)입니다.
- PCA와 MDS는 모두 선형 변환에 속합니다.

- Non-linear Structure : 비선형적으로 Latent Structure를 찾는 방법입니다. 대표적으로 ISOMAP, LLE, t-SNE가 있습니다.
Conclusion
끝으로, 딥러닝 기반 Representation Learning 방식 중 하나인 Auto-encoder를 예시를 들며 마칩니다.
