들어가며
저는 현재 Routie라는 프로젝트를 진행하고 있습니다. Routie는 사용자가 하루 여행 동선을 함께 짜는 협업형 서비스입니다.
해당 서비스는 한 화면 안에서 장소 목록, 동선, 지도 세 영역이 동시에 갱신된다는 특징을 가지고 있습니다.
각 영역이 서로 영향을 주기 때문에, 데이터를 일관되게 유지하는 것이 핵심이었습니다.
초기에는 React Context로 데이터를 공유했습니다. 하지만 기능이 늘어나자, 작은 변화에도 화면 전체가 리렌더링되고, 매번 refetch를 반복해야 하는 상황이 되었습니다.
이 글은 그러한 구조를 TanStack Query로 개선한 과정과, 그 결과 얻은 교훈을 코드 레벨의 근거와 함께 공유하기 위해 쓴 글입니다.
이해를 위한 동작 흐름 간단 소개
먼저 설명에 앞서서 이해를 돕기 위해 서비스의 동작을 잠깐 소개하겠습니다. 서비스는 세 영역이 동시에 갱신되는 구조입니다. 그림으로 간단히 설명하면,
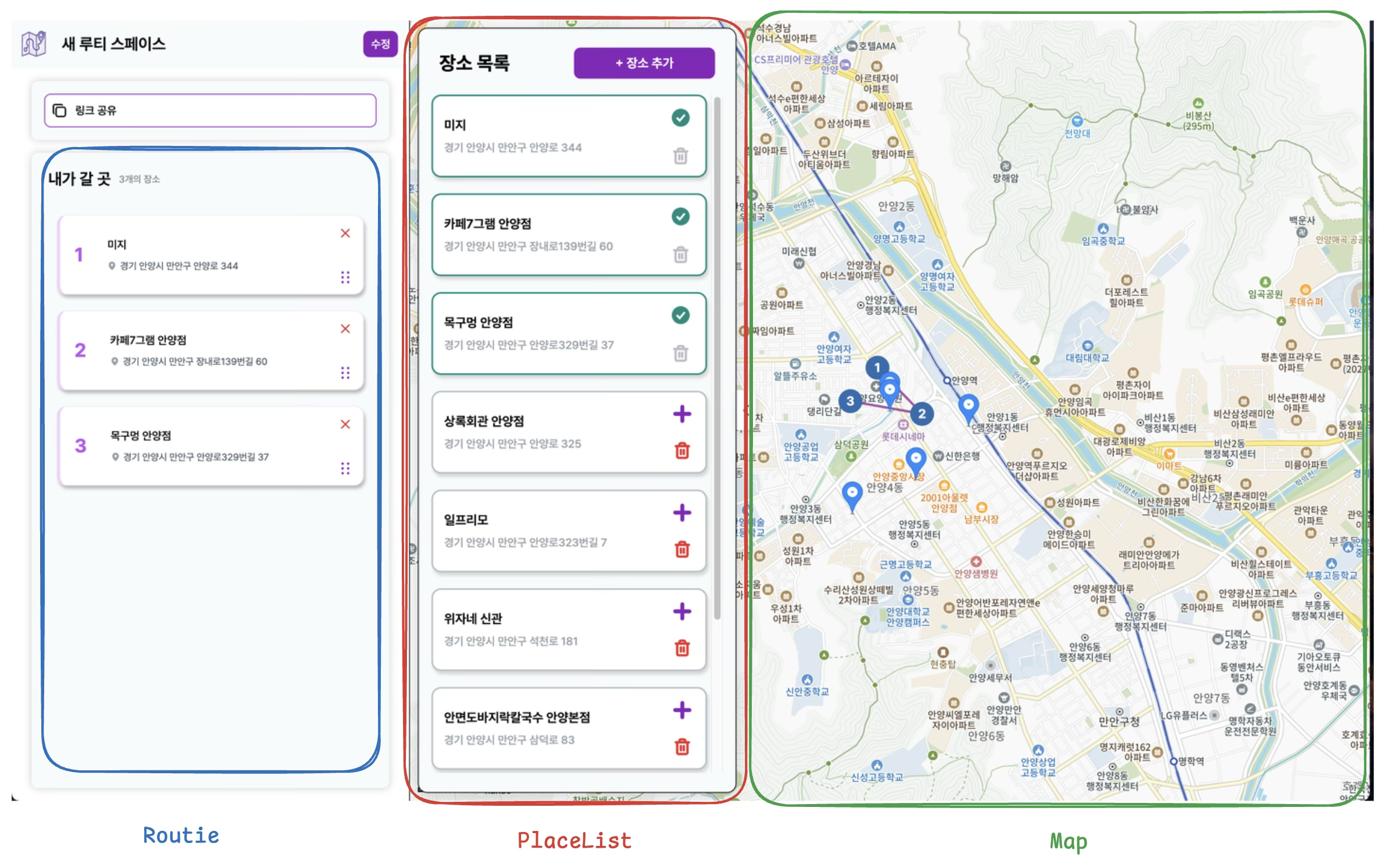
동선, 장소목록, 지도 순으로 3개의 영역으로 구성되어 있습니다.
핵심 동작 흐름은 다음과 같습니다.
-
장소를 추가한다.
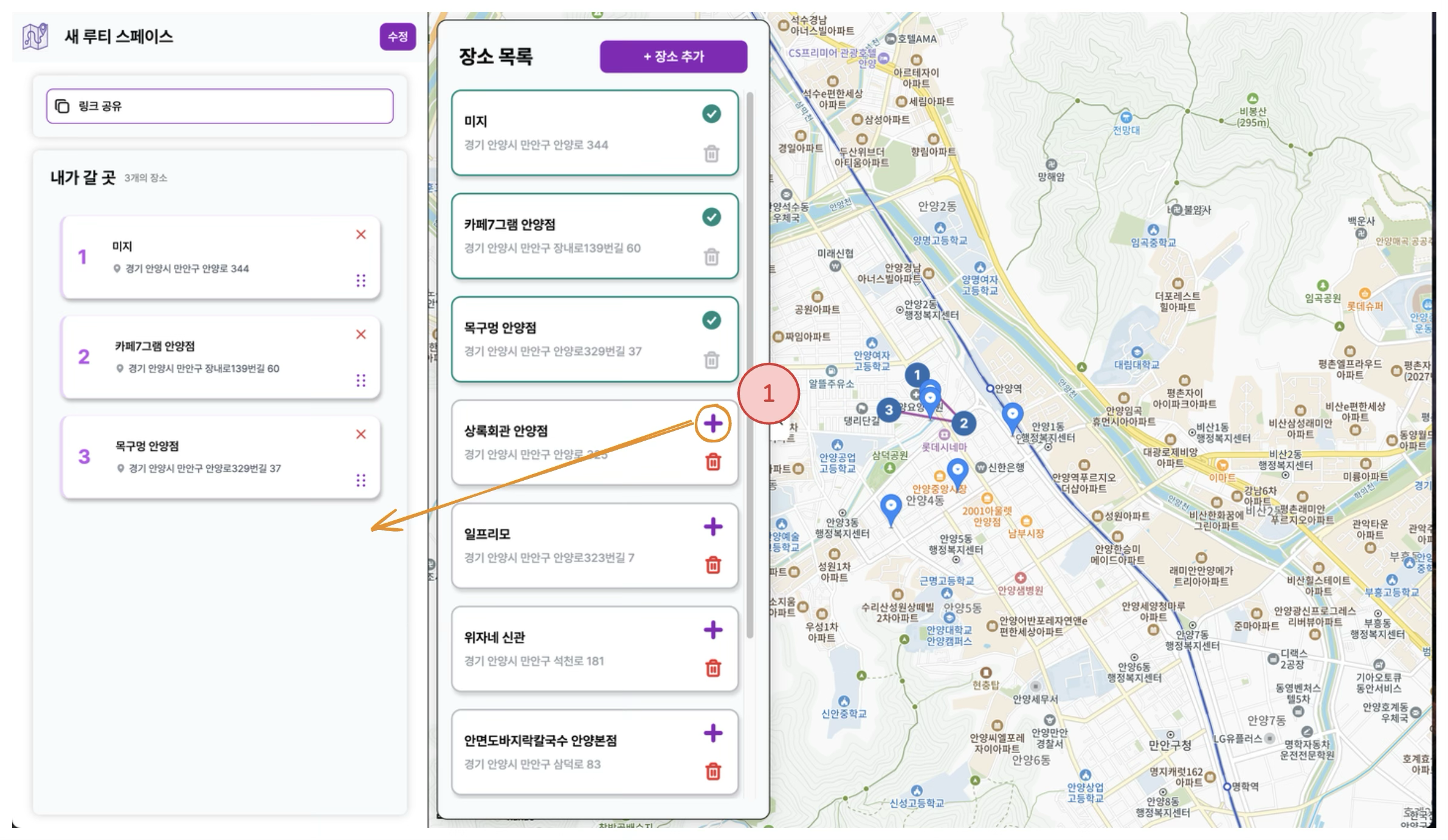
-
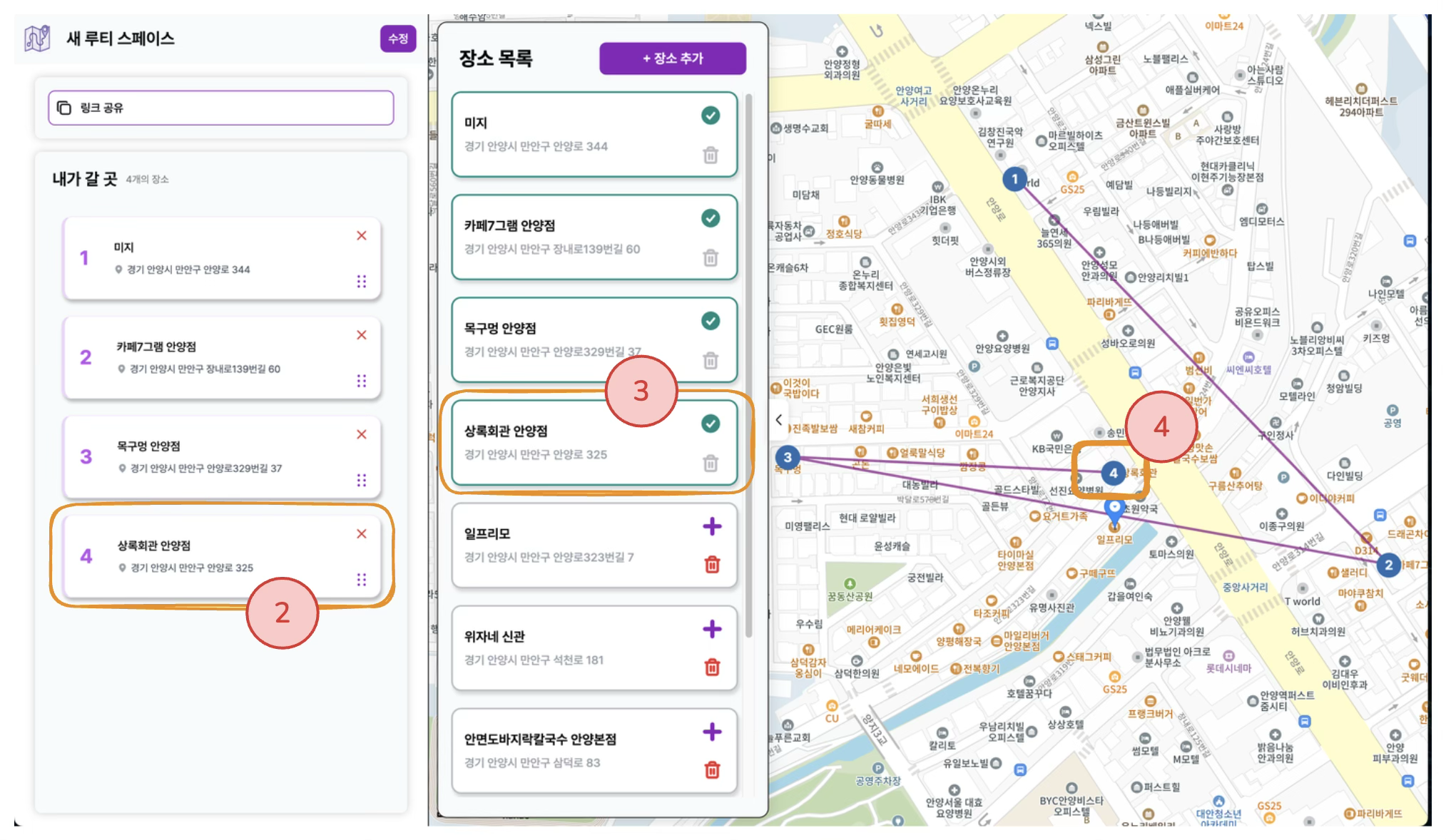
동선에 장소가 추가된다.
-
장소목록에 체크 표시가 된다.
-
지도에 순서 마커로 표시된다.
기존 데이터 관리 방식 - Context에 얽힌 서버 상태
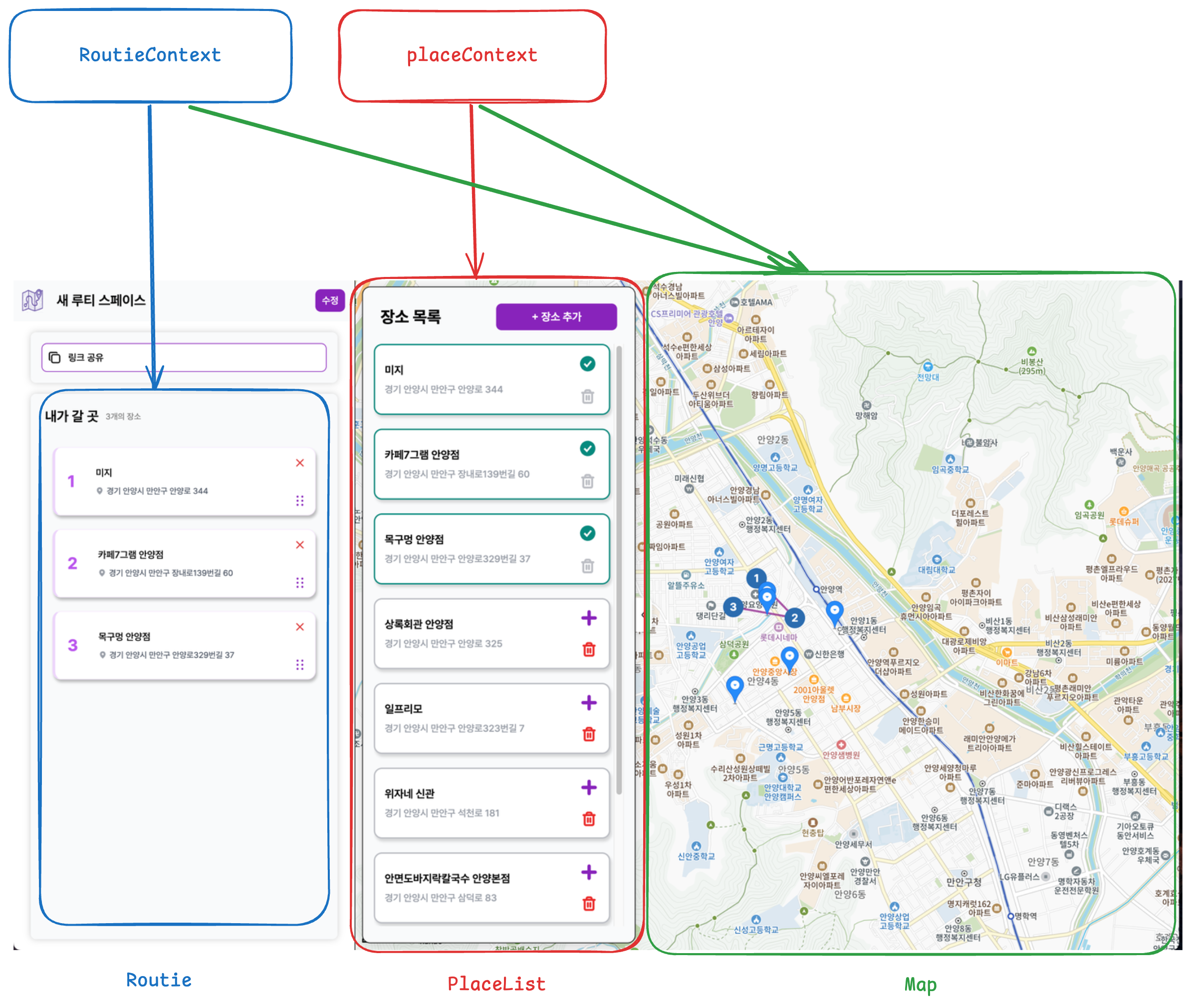
프로젝트 초반에는 도메인별 Context를 통해 데이터를 관리했습니다.
RoutieContext는 동선 데이터를, PlaceListContext는 장소 목록 데이터를 담당했고, 각각의 Provider가 필요한 컴포넌트를 감싸는 구조였습니다.
데이터는 fetch + useState + refetch 조합으로 직접 불러오고 갱신했습니다.
하지만 이 방식은 여러 불편함이 있었습니다. 데이터 변경마다 수동 리패칭이 필요했고, 데이터를 여러 영역에서 함께 사용하다 보니 Provider로 화면 전체를 감싸야 하는 구조가 되었습니다.
또한 한 Provider 안에 서버 상태와 클라이언트 상태가 섞여 관리되는 문제도 있었습니다.
각 문제를 자세히 살펴보도록 하겠습니다.
문제 1 - 수동 리패칭 피로감
프로젝트에서는 장소 추가, 삭제, 동선 수정 등 다양한 사용자 액션 이후 항상 최신 데이터를 다시 불러와야 했습니다.
const handleAddPlace = async (id: number) => {
await addPlace(id);
await refetchPlaceList(); // 액션마다 수동 refetch 강제위와 같이 모든 액션마다 refetch 동작을 포함해야 했고, 결과적으로 코드 전반에 refetch 호출이 17회 이상 반복되었습니다.
이는 코드 중복과 유지보수 비용을 높였을 뿐 아니라, 매번 전체 데이터를 다시 갱신하면서 비효율적으로 동작했습니다.
문제 2 - Context 구조의 문제
Context를 사용하기 위해서는 필요한 영역을 Provider로 감싸야 하지만, 각 도메인이 서로 강하게 연결되어 있다 보니 점점 Provider의 범위가 확장되었습니다.
<RoutieProvider>
<PlaceListProvider>
<Sidebar />
<MapWithSideSheet />
</PlaceListProvider>
</RoutieProvider>초기에는 필요한 부분만 선택적으로 감싸는 형태를 목표로 했지만, 각 도메인이 서로 참조하는 구조로 커지면서, 결국 모든 화면을 전역 Provider로 감싸야 하는 형태가 되었습니다.
Provider 중첩은 곧 전역 리렌더링 범위를 키우고, 코드 재사용성을 떨어뜨렸습니다. 이로 인해 Context 계층이 깊어지고, 특정 데이터만 분리해서 재활용하기도 어려워졌습니다.
문제 3 - 서버 상태와 클라이언트 상태 혼재
Context 내부에서는 서버에서 받아오는 데이터(routiePlaces, routes)와 UI 렌더링을 위한 로컬 상태(routieIdList)가 함께 관리되고 있었습니다.
<RoutieContext.Provider
value={{
routiePlaces, // 서버 상태
routes, // 서버 상태
routieIdList, // 클라이언트 상태
refetchRoutieData,
handleAddRoutie,
handleDeleteRoutie,
handleChangeRoutie,
}}
>
{children}
</RoutieContext.Provider>이로 인해 어떤 값이 서버의 원본 데이터인지, 어떤 값이 화면 표시만을 위한 로컬 상태인지 구분하기 어려웠습니다.
상태의 책임이 모호해지면서, 데이터 변경 시 예기치 않은 리렌더링이나 의도치 않은 데이터 흐름이 발생하기도 했습니다.
요약하자면, 기존 Context 기반 구조는
- 데이터 변경 시마다 수동으로 리패칭해야 하고,
- Provider 계층이 비대해졌으며,
- 서버 상태와 클라이언트 상태가 뒤섞여 관리되는 구조적 한계를 가지고 있었습니다.
그래서 저희 팀은 이러한 문제를 해결하기 위해 TanStack Query를 도입하기로 결정했습니다.
왜 TanStack Query인가
프로젝트에서 필요한 것은 서버 상태를 효율적으로 관리할 수 있는 도구였습니다.
데이터가 변경될 때마다 refetch를 수동으로 호출하고, Context를 전역으로 감싸야 하는 기존 구조는 유지보수가 어렵고 반복적인 코드가 많았습니다.
이 문제를 해결하기 위해 여러 상태 관리 도구를 검토했고, 세 가지 기준을 세웠습니다.
- 팀이 빠르게 도입하고 학습할 수 있을 것
- 복잡한 서버 상태 관리를 단순화할 수 있을 것
- 액션 이후 refetch 호출과 같은 수동 동기화 비용을 줄일 것
TanStack Query는 이 세 가지 조건을 모두 충족했습니다.
무엇보다 제한된 시간 안에 빠르게 기술을 도입해야 하는 상황이었습니다.
TanStack Query는 활발한 커뮤니티와 풍부한 자료 덕분에 문제 상황에서 참고할 수 있는 사례를 쉽게 찾을 수 있었고,
팀 내에도 이미 사용 경험이 있는 구성원이 있어 학습 비용을 줄이고 빠르게 적용할 수 있다고 판단했습니다.
기술적인 측면에서도 TanStack Query는 서버 상태 관리에 가장 널리 사용되는 라이브러리로, 자동 리패칭과 캐싱 기능을 제공해 별도의 수동 동기화 로직이 필요 없었습니다.
이러한 이유로 TanStack Query를 도입하기로 결정했습니다.
도입 과정
1. 초기 세팅
도메인별로 분리된 여러 Provider를 모두 제거하고, QueryClientProvider 하나로 서버 상태를 통합했습니다.
이제 전역 상태는 QueryClient가 관리하고, 각 컴포넌트는 필요한 데이터만 구독하게 되었습니다.
기존에는 RoutieProvider, PlaceListProvider 등 여러 Context Provider가 중첩되어 있었습니다.
const Route = () => {
return (
<ToastProvider>
<RoutieProvider>
<PlaceListProvider>
<Sidebar />
<MapWithSideSheet />
</PlaceListProvider>
</RoutieProvider>
<Toast />
</ToastProvider>
);
};이 구조를 QueryClientProvider 기반으로 단순화했습니다.
import { QueryClient, QueryClientProvider } from '@tanstack/react-query';
const queryClient = new QueryClient();
const Route = () => {
return (
<QueryClientProvider client={queryClient}>
<ToastProvider>
<RouterProvider router={router} />
<Toast />
</ToastProvider>
</QueryClientProvider>
);
};
export default Route;이 변경으로 Provider 계층이 단일화되어 트리가 가벼워지고, QueryClientProvider 하나로 서버 상태를 관리할 수 있게 되었습니다.
2. 쿼리 키 세팅
TanStack Query는 queryKey를 기준으로 데이터를 캐싱하고, 무효화(invalidate)하며, 중복 요청을 방지합니다. 따라서 쿼리 키를 명확하게 설계해야 서버 상태를 세밀하게 제어하고, 불필요한 리렌더링이나 전체 갱신을 막을 수 있습니다.
프로젝트에서는 다음과 같은 이유로 쿼리 키를 세팅했습니다.
- 데이터 구분: 동일한 API라도 목적(목록, 상세, 검색)에 따라 키를 분리해 캐시 충돌을 방지했습니다.
- 부분 무효화:
invalidateQueries시 필요한 쿼리만 갱신할 수 있도록 구조화했습니다. - 중복 요청 방지: 여러 컴포넌트에서 같은 데이터를 요청하더라도, 키가 같으면 한 번만 요청하도록 했습니다.
- 확장성 확보: 도메인별로 키를 모듈화(
placesKeys,routiesKeys)해 이후 API가 늘어나도 일관성 있게 관리할 수 있습니다.
정리하자면, 쿼리 키를 세팅한 이유는 서버 상태의 주소를 명확히 정의해 체계적으로 관리하기 위해서입니다.
실제로는 다음과 같은 쿼리 키를 설정해주었습니다.
| 도메인 | 키 함수 | 실제 키 예시 | 용도 / 의미 |
|---|---|---|---|
| Routie | routiesKeys.all | ['routie'] | 동선 관련 전체 캐시 루트 |
| Places | placesKeys.all | ['places'] | 장소 도메인 캐시 루트 |
| Places | placesKeys.list() | ['places', 'list'] | 장소 목록 조회 |
| Places | placesKeys.detail(placeId) | ['places', 'detail', 42] | 특정 장소 상세 조회 |
| Places | placesKeys.search(query) | ['places', 'search', 'seoul cafe'] | 검색 결과 |
| Places | placesKeys.liked() | ['places', 'liked'] | 장소 목록 좋아요 |
| RoutieSpace | routieSpaceKeys.all | ['routieSpace'] | 동선 방 생성 관련 캐시 루트 |
| RoutieSpace | routieSpaceKeys.edit(name) | ['routieSpace', name] | 특정 동선 방 편집 |
| RoutieSpace | routieSpaceKeys.list() | ['routieSpace', 'list'] | 동선 방 목록 조회 |
이렇게 도메인별로 쿼리 키를 명확히 정의해두니, 데이터 무효화나 캐시 갱신 시 불필요한 범위를 건드리지 않고도 원하는 데이터만 효율적으로 갱신할 수 있습니다. 결과적으로 서버 상태 관리의 일관성이 높아지고, 예측 가능한 동작을 유지할 수 있었습니다.
또, 처음엔 단순히 캐시 키를 구분하는 정도로 생각했지만, 명확한 규칙을 세워두니 이후 API가 늘어나도 구조가 흔들리지 않았습니다. 덕분에 팀원 간 협업 시에도 어떤 데이터를 갱신해야 하는지 쉽게 파악할 수 있었고, 유지보수 효율이 크게 높아졌습니다.
3. Query 훅으로 전환
데이터 fetch 로직을 모두 useQuery로 통합하면서, 데이터 요청, 로딩, 에러 상태를 자동으로 관리하는 구조로 개선했습니다.
이제 컴포넌트는 단순히 queryKey만 선언하면, 데이터 흐름을 신경 쓰지 않고 UI에 집중할 수 있습니다.
기존에는 fetch와 useState를 조합해 데이터를 직접 불러오고,
요청 실패나 로딩 처리 로직을 매번 반복해야 했습니다.
const refetchPlaceList = useCallback(async () => {
try {
const newPlaceList = await getPlaceList();
setPlaceList(newPlaceList);
} catch (error) {
console.error('장소 목록을 불러오는데 실패했습니다.', error);
// ...
}
}, []);이 로직을 useQuery 기반으로 단순화했습니다.
const usePlaceListQuery = () => {
return useQuery({
queryKey: placesKeys.list(),
queryFn: getPlaceList,
});
};
// 사용 예시
const { data, isLoading, isError, error } = usePlaceListQuery();반복되던 에러, 리패칭 처리가 사라지고, 데이터 로직과 UI 로직이 명확히 분리된 구조로 바뀌었습니다.
4. Mutation 적용
서버에 데이터를 추가·수정·삭제하는 액션을 모두 useMutation으로 전환해, 액션 이후 수동 refetch를 없애고 자동으로 관련 데이터만 갱신하도록 개선했습니다.
이전에는 성공 후마다 refetch를 직접 호출해야 했고, API가 늘어날수록 중복 코드와 불필요한 요청이 급격히 늘어났습니다.
// 장소 선택 후 동선 무효화
const handleAddRoutie = useCallback(
async (id: number) => {
try {
await addRoutiePlace({ placeId: id });
await refetchRoutieData();
// ...
} catch (error) {
// ...
}
},
[refetchRoutieData, ...]
);useMutation을 적용해 다음처럼 단순화했습니다.
// 장소 선택 후 동선 무효화
const useAddRoutieMutation = () => {
const queryClient = useQueryClient();
return useMutation({
mutationFn: (placeId: AddRoutiePlaceRequestType) => addRoutiePlace(placeId),
onSuccess: () => {
queryClient.invalidateQueries({ queryKey: routiesKeys.all }); // 무효화
},
onError: (error) => {
// ...
},
});
};이제 액션 성공 시 관련 캐시만 invalidate되어 필요한 부분만 새로 패칭되고, 전역 refetch 호출과 중복 네트워크 요청이 모두 사라졌습니다.
도입 효과
TanStack Query를 도입한 이후, 프로젝트 전반에서 여러 개선이 있었습니다.
특히 반복적인 리패칭, Provider 중첩, 데이터 흐름의 모호함 등 기존 구조의 비효율적인 부분이 대폭 줄어들었습니다.
수동 refetch 제거
도입 전에는 데이터 변경이 일어날 때마다 refetch를 직접 호출해야 했습니다.
예를 들어 장소 추가, 삭제, 수정 등 각 액션마다 전역 데이터를 다시 불러와야 했었죠.
결국 전역적으로 refetch가 17회 이상 반복되며, 같은 요청을 여러 번 수행하는 비효율이 발생했습니다.
TanStack Query 도입 후에는 자동 리패칭과 캐싱이 기본 제공되어, 액션이 성공하면 관련된 쿼리만 자동으로 갱신되도록 구조를 단순화할 수 있었습니다. 그 결과 코드 곳곳에 흩어져 있던 refetch 호출이 모두 사라졌고, 데이터 일관성은 유지하면서도 네트워크 요청 수는 크게 줄었습니다.
Provider 단순화
기존 구조에서는 도메인별로 Context Provider를 만들어야 했습니다.
예를 들어 RoutieProvider, PlaceListProvider를 계층적으로 감싸는 형태였고, 새로운 기능이 추가될수록 Provider가 늘어나 복잡도가 증가할 위험이 있었죠.
TanStack Query로 전환한 이후에는 QueryClientProvider 하나만으로 서버 상태를 전역 관리할 수 있게 되었습니다.
UI 상태는 각 컴포넌트에서 관리하고, 서버 상태는 QueryClient가 담당하면서 책임이 명확히 분리되고 계층이 단순해졌습니다.
Provider 중첩 문제도 사라져 컴포넌트 트리가 훨씬 가벼워졌습니다.
리렌더링 범위 축소
Context 기반 구조에서는 데이터 변경 시 Provider를 구독하고 있는 모든 하위 컴포넌트가 리렌더링되었습니다.
특정 리스트만 수정해도 전체 페이지가 다시 그려지는 일이 잦았죠.
TanStack Query에서는 invalidateQueries를 통해 변경된 쿼리만 부분 무효화할 수 있게되었습니다. 즉, 실제로 바뀐 데이터만 다시 패칭되고 나머지 컴포넌트는 캐시 데이터를 그대로 유지합니다. 이 덕분에 리렌더링 범위를 최소화할 수 있었고, 렌더링 성능과 반응성 모두 개선되었습니다.
에러 처리 표준화
이전에는 각 fetch 함수마다 에러 핸들링, 토스트 노출 로직을 따로 작성해야 했습니다. 코드 패턴이 제각각이라 유지보수가 어려웠고, 같은 에러가 발생해도 화면마다 다르게 처리되는 문제도 있었습니다.
useQuery와 useMutation으로 통일한 이후에는 에러 상태를 일관된 인터페이스로 관리할 수 있게 되었습니다. 또 성공/실패 시의 후속 동작을 onSuccess, onError로 명시적으로 분리해 로직이 한눈에 들어오고, 패턴을 통일할 수 있었습니다.
서버/클라이언트 상태 역할 분리
Context를 사용할 때는 서버에서 받아온 데이터와 UI 상태가 한 Provider 안에 뒤섞여 있었습니다.
이로 인해서 두 상태의 불일치로 인한 화면 깨짐이 자주 발생했습니다. 예를 들어 UI 상태가 먼저 렌더링된 뒤, 서버 데이터가 늦게 도착하면서 이미 렌더링된 컴포넌트가 뒤늦게 다시 그려지는 문제가 있었죠.
TanStack Query를 도입한 이후에는 이러한 구조적 충돌을 분리할 수 있게되었습니다.
서버 상태는 Query 캐시에서 관리해 항상 최신 데이터를 기준으로 동작하도록 하고, 화면 표시나 사용자 입력에 따른 UI 상태는 컴포넌트 내부에서만 관리하도록 정리했습니다.
그 결과 서버 데이터 갱신 시 UI가 예측 불가능하게 변하는 상황을 줄일 수 있었고, 상태의 책임이 명확해지면서 데이터 흐름을 단방향으로 안정화할 수 있게 되었습니다. 이제는 화면이 서버 응답 타이밍에 흔들리지 않고, 유지보수와 디버깅이 훨씬 수월해졌습니다.
결론
Context는 여전히 UI 상태 관리에는 강력한 도구지만, 서버 상태 관리에는 한계가 있었습니다.
TanStack Query를 도입하면서 데이터 변경 시 자동으로 최신 상태가 반영되고, UI 전용 로직은 컴포넌트가 책임지는 단순하고 예측 가능한 구조로 정리할 수 있었습니다.
이 과정을 통해서 느낀 점은 결국 핵심은 특정 라이브러리의 선택이 아니라, 서버 상태를 Single Source of Truth(SSoT)로, UI 상태는 컴포넌트 중심으로 분리한다는 사고방식이었습니다.
이 관점을 통해 팀 내에서 데이터 흐름을 바라보는 기준을 통일할 수 있게되었고, 코드의 일관성과 유지보수성도 향상시킬 수 있었습니다.
지금까지
- 수동 리패칭 부담 감소
- Context 기반 구조 단순화
- 코드 가독성 및 유지보수성 향상
- 클라이언트 상태와 서버 상태의 명확한 분리
위와 같이 프로젝트가 가진 문제를 해결하기 위한 수단으로 Tanstack Query를 도입하는 과정을 살펴보았습니다.
앞으로는 staleTime, select, enabled 등의 옵션도 공부해보면서 더 세밀한 데이터 흐름을 설계하고, 필요한 시점에 부분 갱신이나 캐시 정책을 적용해볼 계획입니다. 또 키를 명확히 설계해서 효율적인 API 호출이 가능하게 개선시킬 예정입니다.
