영어 토큰화
NLTK(Natural Language Toolkit) 패키지는 자연어처리 및 문서 분석용 파이썬 패키지이다. 주요 기능은 다음과 같다.
- 말뭉치
- 토큰 생성
- 형태소 분석
- 품사 태깅
import nltk
import warnings
warnings.simplefilter("ignore")nltk.download('punkt')간단한 토큰화 연습
sentence = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."
text = "I am actively looking for PH.D. students. and you are a Ph.D student."from nltk.tokenize import sent_tokenize
print(sent_tokenize(text))['I am actively looking for PH.D. students.', 'and you are a Ph.D student.']from nltk.tokenize import word_tokenize
print(word_tokenize(sentence))['Do', "n't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr.', 'Jone', "'s", 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
print(tokenizer.tokenize(sentence))['Don', "'", 't', 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr', '.', 'Jone', "'", 's', 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Starting a home-based restaurant may be an ideal. it doesn't have a food chain or restaurant of their own."
print(tokenizer.tokenize(text))['Starting', 'a', 'home-based', 'restaurant', 'may', 'be', 'an', 'ideal.', 'it', 'does', "n't", 'have', 'a', 'food', 'chain', 'or', 'restaurant', 'of', 'their', 'own', '.']소설 원문을 바탕으로 한 토큰화 연습
nltk.download('book', quiet = True)
from nltk.book import **** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908nltk.corpus.gutenberg.fileids() #저작권이 말소된 문학작품['austen-emma.txt',
'austen-persuasion.txt',
'austen-sense.txt',
'bible-kjv.txt',
'blake-poems.txt',
'bryant-stories.txt',
'burgess-busterbrown.txt',
'carroll-alice.txt',
'chesterton-ball.txt',
'chesterton-brown.txt',
'chesterton-thursday.txt',
'edgeworth-parents.txt',
'melville-moby_dick.txt',
'milton-paradise.txt',
'shakespeare-caesar.txt',
'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt',
'whitman-leaves.txt']caesar = nltk.corpus.gutenberg.raw('shakespeare-caesar.txt')
print(caesar[:1300])[The Tragedie of Julius Caesar by William Shakespeare 1599]
Actus Primus. Scoena Prima.
Enter Flauius, Murellus, and certaine Commoners ouer the Stage.
Flauius. Hence: home you idle Creatures, get you home:
Is this a Holiday? What, know you not
(Being Mechanicall) you ought not walke
Vpon a labouring day, without the signe
Of your Profession? Speake, what Trade art thou?
Car. Why Sir, a Carpenter
Mur. Where is thy Leather Apron, and thy Rule?
What dost thou with thy best Apparrell on?
You sir, what Trade are you?
Cobl. Truely Sir, in respect of a fine Workman, I am
but as you would say, a Cobler
Mur. But what Trade art thou? Answer me directly
Cob. A Trade Sir, that I hope I may vse, with a safe
Conscience, which is indeed Sir, a Mender of bad soules
Fla. What Trade thou knaue? Thou naughty knaue,
what Trade?
Cobl. Nay I beseech you Sir, be not out with me: yet
if you be out Sir, I can mend you
Mur. What mean'st thou by that? Mend mee, thou
sawcy Fellow?
Cob. Why sir, Cobble you
Fla. Thou art a Cobler, art thou?
Cob. Truly sir, all that I liue by, is with the Aule: I
meddle with no Tradesmans matters, nor womens matters;
but withal I am indeed Sir, a Surgeon to old shooes:
when they are in great danger, I recouer them. As proper
men as euerfrom nltk.tokenize import sent_tokenize
print(sent_tokenize(caesar[:1000])[4])Hence: home you idle Creatures, get you home:
Is this a Holiday?from nltk.tokenize import word_tokenize
word_tokenize(caesar[:100])['[',
'The',
'Tragedie',
'of',
'Julius',
'Caesar',
'by',
'William',
'Shakespeare',
'1599',
']',
'Actus',
'Primus',
'.',
'Scoena',
'Prima',
'.',
'Enter',
'Fla']from nltk.tokenize import RegexpTokenizer
retokenize = RegexpTokenizer('[\w]+') #문자와 숫자에 해당하는 것만 가져오도록
retokenize.tokenize(caesar[:100])['The',
'Tragedie',
'of',
'Julius',
'Caesar',
'by',
'William',
'Shakespeare',
'1599',
'Actus',
'Primus',
'Scoena',
'Prima',
'Enter',
'Fla']단어별 빈도수를 활용한 워드클라우드 그리기
from nltk import Text
text = Text(retokenize.tokenize(caesar))import matplotlib.pyplot as plt
text.plot(20)
plt.show()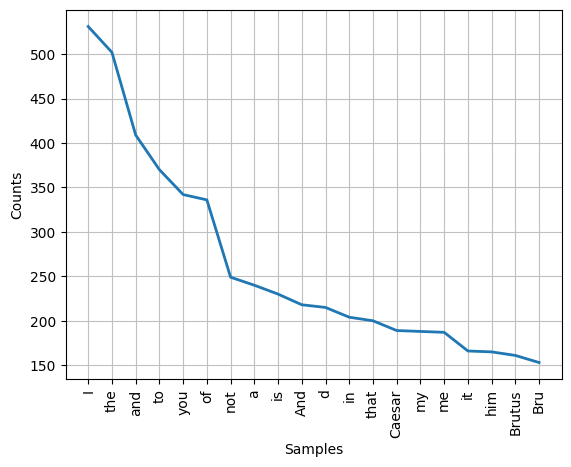
text.dispersion_plot(['Cassius', 'Caesar', 'Flavius', 'Decius Brutus'])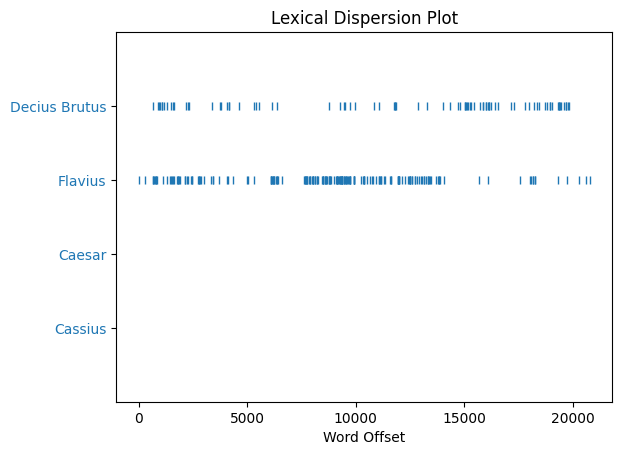
text.concordance("Caesar")Displaying 25 of 190 matches:
The Tragedie of Julius Caesar by William Shakespeare 1599 Actus P
indeede sir we make Holyday to see Caesar and to reioyce in his Triumph Mur W
seruile fearefulnesse Exeunt Enter Caesar Antony for the Course Calphurnia Po
auius Caes Calphurnia Cask Peace ho Caesar speakes Caes Calphurnia Calp Heere
ile curse Ant I shall remember When Caesar sayes Do this it is perform d Caes
on and leaue no Ceremony out Sooth Caesar Caes Ha Who calles Cask Bid euery n
e shriller then all the Musicke Cry Caesar Speake Caesar is turn d to heare So
n all the Musicke Cry Caesar Speake Caesar is turn d to heare Sooth Beware the
llow come from the throng look vpon Caesar Caes What sayst thou to me now Spea
st respect in Rome Except immortall Caesar speaking of Brutus And groaning vnd
owting I do feare the People choose Caesar For their King Cassi I do you feare
g as I my selfe I was borne free as Caesar so were you We both haue fed as wel
ubled Tyber chafing with her Shores Caesar saide to me Dar st thou Cassius now
we could arriue the Point propos d Caesar cride Helpe me Cassius or I sinke I
the waues of Tyber Did I the tyred Caesar And this Man Is now become a God an
Creature and must bend his body If Caesar carelesly but nod on him He had a F
some new Honors that are heap d on Caesar Cassi Why man he doth bestride the
s that we are vnderlings Brutus and Caesar What should be in that Caesar Why s
s and Caesar What should be in that Caesar Why should that name be sounded mor
tus will start a Spirit as soone as Caesar Now in the names of all the Gods at
once Vpon what meate doth this our Caesar feede That he is growne so great Ag
much shew of fire from Brutus Enter Caesar and his Traine Bru The Games are do
s Traine Bru The Games are done And Caesar is returning Cassi As they passe by
what the matter is Caes Antonio Ant Caesar Caes Let me haue men about me that
men are dangerous Ant Feare him not Caesar he s not dangerous He is a Noble Rotext.similar('Caesar')me it brutus you he rome that cassius this if men worke him vs feare
world thee what know daytext.common_contexts(['Caesar', 'me'])with_and on_cassi d_doth beare_hard to_as pardon_caesarfd = text.vocab()
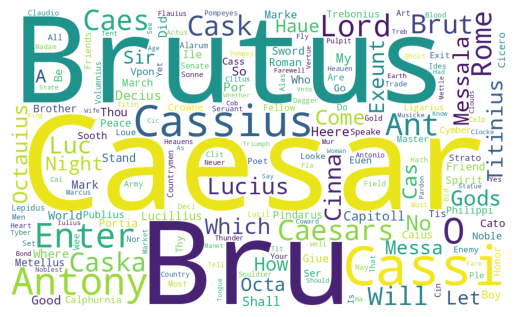
fdFreqDist({'I': 531, 'the': 502, 'and': 409, 'to': 370, 'you': 342, 'of': 336, 'not': 249, 'a': 240, 'is': 230, 'And': 218, ...})from wordcloud import WordCloud
wc = WordCloud(width=1000, height=600, background_color="white", random_state=0)
plt.imshow(wc.generate_from_frequencies(fd))
plt.axis("off")
plt.show()
from nltk.tag import pos_tag
caesar_tokens = pos_tag(retokenize.tokenize(caesar))
caesar_tokens[('The', 'DT'),
('Tragedie', 'NNP'),
('of', 'IN'),
('Julius', 'NNP'),
('Caesar', 'NNP'),
('by', 'IN'),
('William', 'NNP'),
('Shakespeare', 'NNP'),
('1599', 'CD'),
('Actus', 'NNP'),
('Primus', 'NNP'),
('Scoena', 'NNP'),
('Prima', 'NNP'),
('Enter', 'NNP'),
('Flauius', 'NNP'),
('Murellus', 'NNP'),
('and', 'CC'),
('certaine', 'NN'),
('Commoners', 'NNP'),
('ouer', 'VBZ'),
,
...]from nltk import FreqDist
stopwords = ["Mr.", "Mrs.", "Miss", "Mr", "Mrs", "Dear"]
caesar_tokens = pos_tag(retokenize.tokenize(caesar))
names_list = [t[0] for t in caesar_tokens if t[1] == "NNP" and t[0] not in stopwords]
fd_names = FreqDist(names_list)from wordcloud import WordCloud
wc = WordCloud(width=1000, height=600, background_color="white", random_state=0)
plt.imshow(wc.generate_from_frequencies(fd_names))
plt.axis("off")
plt.show()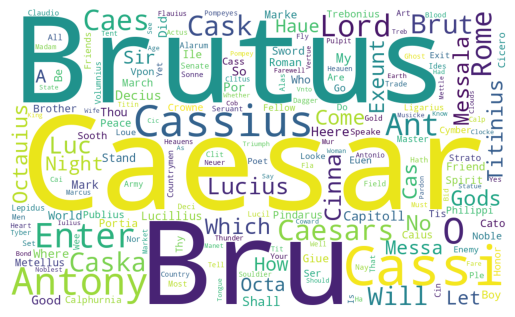
한국어 토큰화
!pip install konlpy
!pip install kss문장 토큰화
import kss
text = "딥러닝 자연어 처리가 재미있기는 합니다. 그런데 문제는 영어보다 한국어로 할 때 너무 어려워요. 이제 해보면 알걸요?"
print(kss.split_sentences(text))['딥러닝 자연어 처리가 재미있기는 합니다.', '그런데 문제는 영어보다 한국어로 할 때 너무 어려워요.', '이제 해보면 알걸요?']단어 토큰화
from konlpy.tag import *
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
okt = Okt()
# mecab = Mecab()from konlpy.corpus import kolaw
kolaw.fileids()['constitution.txt']c = kolaw.open('constitution.txt').read()
print(c[:100])대한민국헌법
유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로 건립된 대한민국임시정부의 법통과 불의에 항거한 4·19민주이념을 계승하고, 조국의 민주개혁과 평화적 통일의from konlpy.corpus import kobill
kobill.fileids()['1809892.txt',
'1809890.txt',
'1809898.txt',
'1809891.txt',
'1809895.txt',
'1809899.txt',
'1809894.txt',
'1809893.txt',
'1809897.txt',
'1809896.txt']d = kobill.open('1809898.txt').read()
print(d[:300])국군부대의 소말리아 해역 파견연장 동의안
의안
제출연월일 : 2010. 11. 15.
9898
번호
제 출 자 : 정 부
제안이유
소말리아 아덴만 해역에 파견된 국군부대 ( 청해부대 )의 파견기간이
2010년 12월 31일 종료될 예정이나,# 메캅 설치에 문제가 있음...
# !git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git
# %cd Mecab-ko-for-Google-Colab/
# !bash install_mecab-ko_on_colab190912.sh# !bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/d9206305195583c08400cb2237c837cc42df2e65/scripts/mecab.sh)from konlpy.tag import *
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
okt = Okt()
# mecab = Mecab()위 형태소 분석기는 공통적으로 아래의 함수를 제공해줌.
nouns 명사 추출
morphs 형태소 추출
pos 품사 부착
print(c[:40])대한민국헌법
유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로명사추출
hannanum.nouns(c[:40])['대한민국헌법', '유구', '역사', '전통', '빛', '우리', '대한국민', '3·1운동']kkma.nouns(c[:40])['대한',
'대한민국',
'대한민국헌법',
'민국',
'헌법',
'유구',
'역사',
'전통',
'우리',
'국민',
'3',
'1',
'1운동',
'운동']# komoran은 빈줄이 있으면 에러가 남
komoran.nouns("\n".join([s for s in c[:40].split("\n") if s]))['대한민국', '헌법', '역사', '전통', '국민', '운동']okt.nouns(c[:40])['대한민국', '헌법', '유구', '역사', '전통', '우리', '국민', '운동']형태소 추출
hannanum.morphs(c[:40])['대한민국헌법',
'유구',
'하',
'ㄴ',
'역사',
'와',
'전통',
'에',
'빛',
'나는',
'우리',
'대한국민',
'은',
'3·1운동',
'으로']kkma.morphs(c[:40])['대한민국',
'헌법',
'유구',
'하',
'ㄴ',
'역사',
'와',
'전통',
'에',
'빛나',
'는',
'우리',
'대하',
'ㄴ',
'국민',
'은',
'3',
'·',
'1',
'운동',
'으로']# komoran은 빈줄이 있으면 에러가 남
komoran.morphs("\n".join([s for s in c[:40].split("\n") if s]))['대한민국',
'헌법',
'유구',
'하',
'ㄴ',
'역사',
'와',
'전통',
'에',
'빛나',
'는',
'우리',
'대하',
'ㄴ',
'국민',
'은',
'3',
'·',
'1',
'운동',
'으로']okt.morphs(c[:40])['대한민국',
'헌법',
'\n\n',
'유구',
'한',
'역사',
'와',
'전통',
'에',
'빛나는',
'우리',
'대',
'한',
'국민',
'은',
'3',
'·',
'1',
'운동',
'으로']hannanum.pos(c[:40])[('대한민국헌법', 'N'),
('유구', 'N'),
('하', 'X'),
('ㄴ', 'E'),
('역사', 'N'),
('와', 'J'),
('전통', 'N'),
('에', 'J'),
('빛', 'N'),
('나는', 'J'),
('우리', 'N'),
('대한국민', 'N'),
('은', 'J'),
('3·1운동', 'N'),
('으로', 'J')]kkma.pos(c[:40])[('대한민국', 'NNG'),
('헌법', 'NNG'),
('유구', 'NNG'),
('하', 'XSV'),
('ㄴ', 'ETD'),
('역사', 'NNG'),
('와', 'JC'),
('전통', 'NNG'),
('에', 'JKM'),
('빛나', 'VV'),
('는', 'ETD'),
('우리', 'NNM'),
('대하', 'VV'),
('ㄴ', 'ETD'),
('국민', 'NNG'),
('은', 'JX'),
('3', 'NR'),
('·', 'SP'),
('1', 'NR'),
('운동', 'NNG'),
('으로', 'JKM')]# komoran은 빈줄이 있으면 에러가 남
komoran.pos("\n".join([s for s in c[:40].split("\n") if s]))[('대한민국', 'NNP'),
('헌법', 'NNP'),
('유구', 'XR'),
('하', 'XSA'),
('ㄴ', 'ETM'),
('역사', 'NNG'),
('와', 'JC'),
('전통', 'NNG'),
('에', 'JKB'),
('빛나', 'VV'),
('는', 'ETM'),
('우리', 'NP'),
('대하', 'VV'),
('ㄴ', 'ETM'),
('국민', 'NNP'),
('은', 'JX'),
('3', 'SN'),
('·', 'SP'),
('1', 'SN'),
('운동', 'NNP'),
('으로', 'JKB')]okt.pos(c[:40])[('대한민국', 'Noun'),
('헌법', 'Noun'),
('\n\n', 'Foreign'),
('유구', 'Noun'),
('한', 'Josa'),
('역사', 'Noun'),
('와', 'Josa'),
('전통', 'Noun'),
('에', 'Josa'),
('빛나는', 'Verb'),
('우리', 'Noun'),
('대', 'Modifier'),
('한', 'Modifier'),
('국민', 'Noun'),
('은', 'Josa'),
('3', 'Number'),
('·', 'Punctuation'),
('1', 'Number'),
('운동', 'Noun'),
('으로', 'Josa')]okt.tagset{'Adjective': '형용사',
'Adverb': '부사',
'Alpha': '알파벳',
'Conjunction': '접속사',
'Determiner': '관형사',
'Eomi': '어미',
'Exclamation': '감탄사',
'Foreign': '외국어, 한자 및 기타기호',
'Hashtag': '트위터 해쉬태그',
'Josa': '조사',
'KoreanParticle': '(ex: ㅋㅋ)',
'Noun': '명사',
'Number': '숫자',
'PreEomi': '선어말어미',
'Punctuation': '구두점',
'ScreenName': '트위터 아이디',
'Suffix': '접미사',
'Unknown': '미등록어',
'Verb': '동사'}빈도수 활용하여 워드클라우드 그리기
kolaw = Text(okt.nouns(c), name = 'kolaw')
kolaw.plot(30)
from wordcloud import WordCloud
# 자신의 컴퓨터 환경에 맞는 한글 폰트 경로를 설정
font_path = '/content/sample_data/NanumGothic-Regular.ttf'
wc = WordCloud(width = 1000, height = 600, background_color="white", font_path=font_path)
plt.imshow(wc.generate_from_frequencies(kolaw.vocab()))
plt.axis("off")
plt.show()

Deep Learning, Multi-Agent RL, Large Language Model, Statistics