혹시 RabbitMQ와 pyodbc 라이브러리를 처음 접해보신다면 이전에 포스팅했던 글을 참고해주세요~~
pyodbc
RabbitMQ
RabbitMQ + pyodbc
구현 목적
pyodbc를 사용하여 RabbitMQ와 연동하여 데이터베이스에서 데이터를 읽어와 메세지 큐에 전송하는 코드를 작성. 이를 통해 RabbitMQ를 사용하여 데이터베이스와 애플리케이션 간의 데이터 송수신을 구현.
실행 프로세스
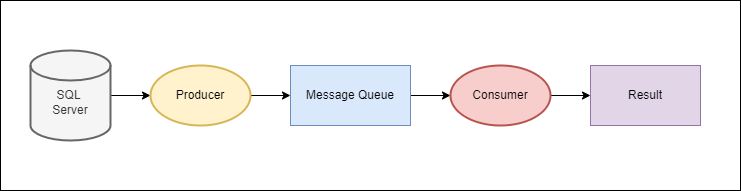
다음과 같이 SQL Server에서 값을 Load 하고, 그 값을 프로듀서를 통해 메시지 큐에 저장합니다.
그리고 컨슈머에서 해당 값을 통해 결과를 출력하는 함수를 추가하여서 사용자가 원하는 결과를 얻을 수 있도록 합니다.
Producer
import pika
import pandas as pd
import pyodbc
import time
server = ''
database = ''
username = ''
password = ''
driver = '{ODBC Driver 17 for SQL Server}' # 드라이버는 사용자의 환경에 맞게 설정
# Connection string 생성
connection_string = f"DRIVER={driver};SERVER={server};DATABASE={database};UID={username};PWD={password}"
# Connection 생성
connection_sql = pyodbc.connect(connection_string)
# Cursor 생성
cursor = connection_sql.cursor()
print("SQL 연결완료")
#==================================================================
#RabbitMQ 서버에 연결
#connection과 channel를 생성
connection_mq1 = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection_mq1.channel()
print("RabbitMQ 연결완료")
# 데이터 조회
cursor = connection_sql.cursor()
cursor.execute("SELECT TOP 1 * FROM test_table")
row = cursor.fetchone()
print(row) #( , , , ,) 튜플로 출력
# 프로듀서 설정
#channel.queue_declare(queue='test_queue')
channel.basic_publish(exchange='',
routing_key='test_queude',
body=str(row))
# RabbitMQ 연결 종료
connection_mq1.close()
connection_sql.close()저번보다 코드가 많이 늘어났는데 살펴보면 네 종류로 구분할 수 있습니다.
1. SQL Server 연결
2. RabbitMQ 연결
3. 데이터 조회
4. 프로듀서에 조회한 값 저장
쿼리문은 SELECT TOP 1 * FROM test_table 을 사용했고, test_table에서 첫 번째 행의 데이터를 가져옵니다.
basic_publish의 파라미터에 routing_key는 queue_declare에서 정의한 큐 이름을 입력하고, body에는 SQL Server에서 조회한 데이터를 문자열로 입력하면 됩니다.
꼭, RabbitMQ와 pyodbc 모두 사용이 끝난다면 close를 통해 연결을 종료해줍시다.
실행 결과

Consumer
import pika
import pandas as pd
import time
# 메시지 소비
def callback(ch, method, properties, body):
received_row = eval(body)
epoch = received_row[0]
lr = received_row[1]
window_size = received_row[2]
batch_size = received_row[3]
print(f"Received epoch: {epoch}")
print(f"Received lr: {lr}")
print(f"Received window_size: {window_size}")
print(f"Received batch_size: {batch_size}")
# ADD 함수 실행
result = ADD(epoch, batch_size, lr, window_size)
print("Result: ", result)
# 처리가 끝나면 RabbitMQ 연결 종료
channel.stop_consuming()
# ADD 함수 정의
def ADD(epoch, batch_size, lr, window_size):
return epoch + batch_size + lr + window_size
# RabbitMQ 컨슈머
connection_mq2 = pika.BlockingConnection(pika.ConnectionParameters(host="localhost"))
channel = connection_mq2.channel()
channel.basic_consume(queue='test_queue', on_message_callback=callback, auto_ack=True)
channel.start_consuming()
##연결 종료
connection_mq2.close()메시지 큐에 저장된 값을 사용자가 정의한 함수에 적용하여 소비하는 코드입니다.
우선 basic_consume에 사용할 함수인 callback함수를 정의합니다.
callback 함수의 파라미터는 총 4개지만, 이번 예시에서는 body하만 사용해도 실행이 됩니다.
body는 이전에 프로듀서에 저장된 문자열 값을 의미합니다.
eval을 사용하여 가져온 문자열을 튜플로 반환합니다.
eval은 취약점이 있기 때문에 사용을 지양해야합니다. 간단히 예시로 알아보기 위해 사용하였습니다.
네 컬럼을 반환하기 위해서 각 변수에 값을 저장해준 후, 사용자가 정의한 함수를 사용하여 결과를 출력합니다.
그리고 stop_consuming을 통해 소비를 종료합니다. 꼭 stop_consuming을 사용해줘야 메시지 큐에 저장된 1개의 작업만 실행됩니다. 이전 포스팅에선 사용하지 않았기 때문에 모든 메시지를 소비하고 무한루프문이 실행되는 것을 확인할 수 있었습니다.
예시로 저장된 모든 값을 더하는 ADD 함수를 정의해보았습니다.
callback에 ADD 함수를 적용하기 위해 RabbitMQ 서버에 BlockingConnection을 사용하여 연결합니다.
basic_consume메소드의 파라미터를 살펴보면, queue에는 사용할 큐이름을 입력하고, on_message_callback에 이전 정의했던 callback함수를 입력해주면 됩니다.
start_consuming을 통해 소비가 시작되고, 1개의 작업이 소비되었습니다.
실행결과
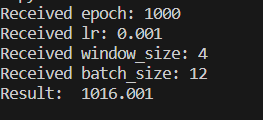
Comsumer 실행결과 SQL Server에 저장된 값과 함수를 실행한 결과를 모두 출력한 것을 확인할 수 있다.
RabbitMQ
활용 방안
함수를 ADD와 같은 간단한 함수 대신, 딥러닝 프로세스를 넣어보면 어떨까...
예를 들어 DB에 저장된 하이퍼파라미터를 모두 받아서 결과를 다시 SQL Server에 저장하는 과정도 만들 수 있을 듯 하다.
다음은 RabbitMQ와 Tensorflow 2.x를 활용해서 간단한 분류모델을 실행하는 과정을 구현해보겠습니다.
