RTX 50환경에서 YOLOv12나 v13을 돌려보려하는데 기존 설치 명령어로 설치는 되지만, 학습 시 Flash Attention인식이 안되어서 기본 Attention이 사용된다라는 로그가 보여서 이를 해결해보려합니다.
우선 YOLOv12,13 깃허브에 사용되는 whl파일 다운로드 명령어 입니다.
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
컨테이너 환경
GPU : RTX50xx
OS : Ubuntu
CUDA : 12.8
Python : 3.11
Pytorch : 2.7.0
해결방법
https://github.com/Dao-AILab/flash-attention/releases
릴리즈 페이지 들어가보면 whl파일 이름엔 규칙이 있습니다.
cu11 : 쿠다 버전
torch2.2 : 토치 버전
cp311-cp311 : 파이썬 버전
linux_x86_64 : OS 종류
이렇게 구성되어 있습니다.
아직 v2.8.3에는 토치 2.7.0을 지원하는 파일이 없고, v2.8.2에 들어가면 아래처럼 있습니다.
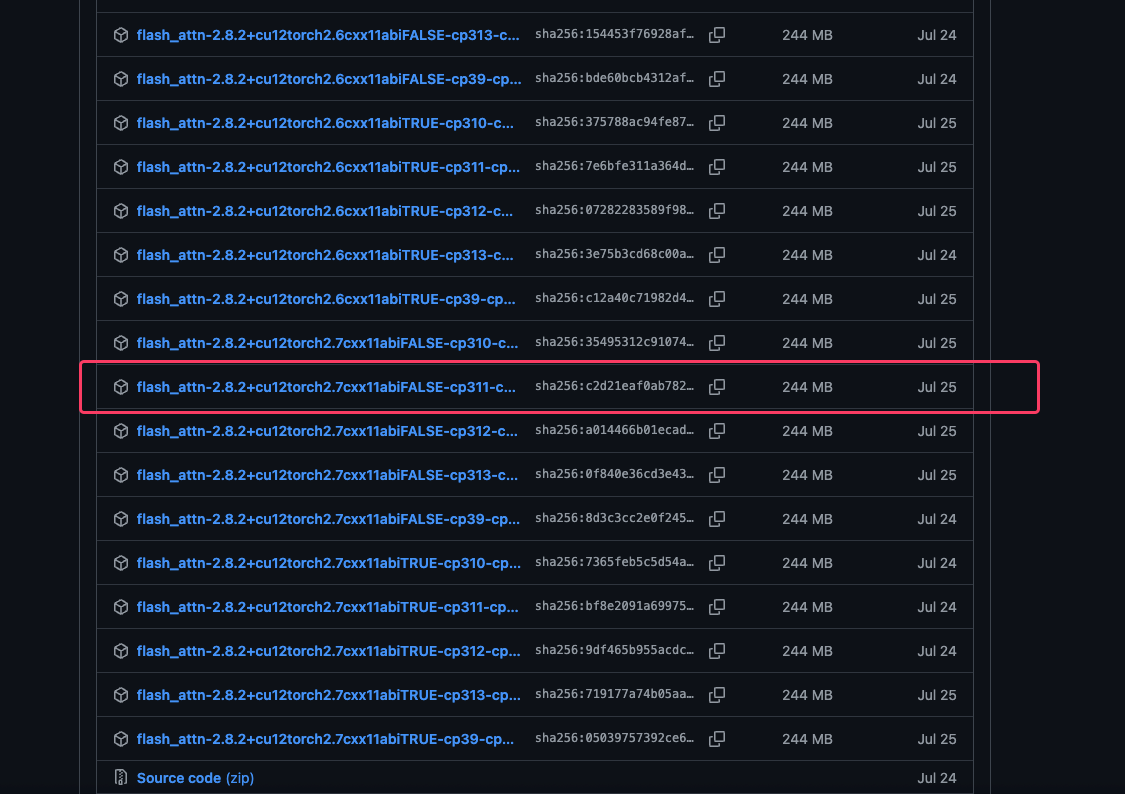
이제 pip install 로 설치해주면 Flash Attention이 적용됩니다.
pip install ~.whl동일한 환경이 아니더라도 CUDA,Torch,Python이 whl파일명과 일치하는 걸 찾아서 바꿔주면 문제는 해결됩니다.

Graduate student at Pusan National University, majoring in Artificial Intelligence