1. Time Series Review
Time Series
: Ordered Sequence of random variables
인 discrete stochastic process (확률과정)
Time Series value는 시계열 R.V의 Realization이다!
Stationarity
정상성 → 교재에서 사용하는 정상성은 거의 Weak Stationarity
- = Constant
정상성 : 평균과 분산이 시간에 따라 변하지 않음
- 평균이 시간에 의존하지 않음: (모든 t에 대해 동일한 상수).
- 분산이 시간에 의존하지 않음: (모든 t에 대해 동일한 상수).
- 자기공분산이 시간 차이(lag)에만 의존: 두 시점 와 의 공분산이 시점 자체가 아니라 시차 에만 의존함. 즉,
→ 시계열 과정의 평균이 상수, 제곱 평균이 유한, 공분산이 어디서든 시간 k만큼 차이나면, 그건 다른 기간의 시간 k 차이와 동일할 때? : 약한 정상성
White noise
Definition 1.8 : White Noise 정의
- : 평균이 상수
- : 분산이 상수
- for : 서로 다른 시점에서 상관관계가 없음
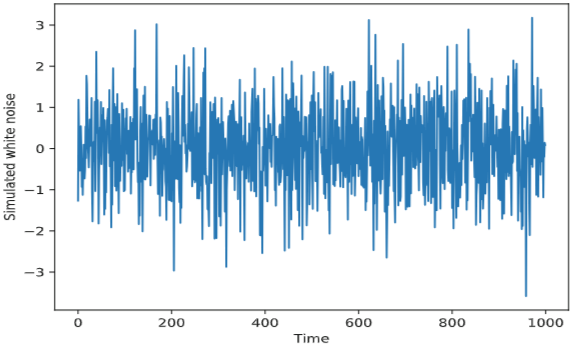
Definition 1.9 - Random Walk
는 이전 에 백색소음 를 더한 값
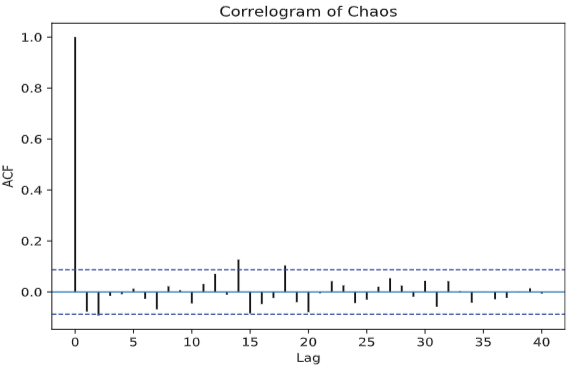
랜덤워크는 왜 자기상관계수가 모든 lag에서 높을까?
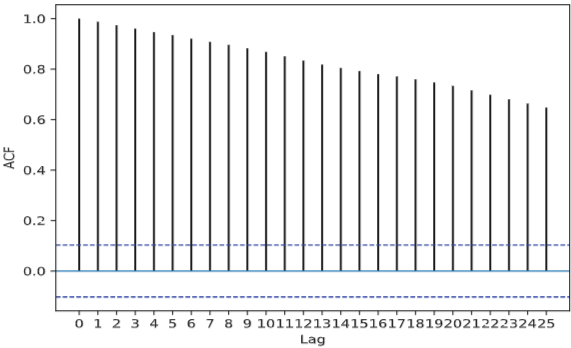
로그를 씌웠는데 여전히 비정상 → 차분도 적용
- Random walk 의 분산은 시간이 지남에 따라 커짐, 즉 Random Walk는 분산 정상성을 만족하지 않음.
Backshift Operator :
에서 로 one step 돌아가기 위한 operator
→ 행렬을 Time series 에 적용한 것.
→ B를 후방이동 Backshift 을 나타내기 위해 사용
- B를 한번 적용하면 시계열에서 한번 앞으로 간다.
- B를 n번 적용하면 시계열에서 n번 앞으로 간다.
- 0번 적용
→ 왜 쓰는건가?
- Backshift operator is widely used for model expression simplicity
- 모델 표현 단순화를 위해 씀
Differencing : 추세와 계절성을 제거
📌비정상 시계열에 대해 연속된 시계열 값 간의 차이를 계산하여 정적 시계열로 만듦
→ 그냥 원래 시계열 에 같은 차분 Operator를 적용하면
차분이 적용된, 즉 차분화가 진행되어서 계절성이나 추세가 제거된 시계열이 결과로 튀어나옴.
Definition 3.1 Backshift Operator
- (1) the differencing of order d - 차수에 따른 차분
- 1차 차분
- d차 차분 :
결과 예시*
1차 차분 (d=1):
- 원래 시계열:
- 1차 차분 후:
2차 차분 (d=2)
- 원래 시계열:
- 2차 차분 후
차수 차분의 관계 - 2차 차분은 1차 차분을 다시 차분한 것
- 만약 일정하게 증가하는 ‘추세’ 의 시계열이 있다면 1차차분하면 상승 추세 해결
- 만약 해결 안되면 다시 차분 (2차차분)으로 해결
- 미분 - 가속도 개념으로 이해하면 편함
→ 차수 차분의 직관 : 미분의 개념으로 이해하면 편함
📌차수 차분의 관계 - 2차 차분은 1차 차분을 다시 차분한 것
미분은 함수의 순간 변화율, 차분은 이산 시계열 데이터의 Step 별 변화량
→ 2차 차분을 2차 미분이라 생각하면 됨
→ 추세가 안죽으면 상수함수가 될 때까지 미분을 반복한다.
- (2) The differencing of lag k - 시차에 따른 차분
- 시차 k 차분
→ k기간 떨어진 관측값 사이의 차이를 계산 : 주로 계절성 Seasonality를 제거하는데 사용
→ 시차 k가 시계열 데이터 계절 주기와 일치할 때 계절 차분 Seasonal Differencing 이라고 함
- 시차 3 차분 (lag k=3):
원래 시계열:
시차 3 차분 후:
계절성 차분 먼저 하고, 필요하면 거기다 추세차분 하기도 함. 순서는 계절차분 먼저 주로 하는 것 같음.
AR : Auto Regressive Model
- 현재 값이 과거 값들의 Linear Combination 으로 표현된다는 아이디어
- 자기 상관성 (Auto Correlation) 을 포착
- : 모델의 차수, 현재 값 예측을 위해 사용하는 과거 시점의 수
t 이전 p개 값으로 시점 t 값을 예측하는 선형회귀
: i 번째 자기회귀 계수 - 시계열 과정에서 i 번째 전 데이터와의 PACF
AR 과 PACF 의 관계
p=2 짜리 AR 모델을 만듦
-
각 계수의 의미
- 0.6 : t-1 값과 t 값의 관련성 0.6 → 다른 변수의 영향이 제거된 lag 1 변수의 다음 변수에 대한 직접영향
-
두 시점간의 단순상관계수 : ACF
-
두 시점간의 직접 영향, 부분상관계수 : PACF
-
회귀 모델에서 각 변수들은 다중공선성이 높음 → 다른 변수의 매개효과를 제외한 직접 영향→ AR 모델의 회귀 계수이자 PACF 값
-
즉 AR 모델의 Coef는 모두 lag k PACF 값들
(100% 이해는 X → 직관만)
MA : Moving Average Model
- 현재 값이 과거의 오차항(White Noise)의 Linear Combination 으로 표현된다는 아이디어
- 예측 불가능한 외부 충격의 영향을 모델링
- : 특정 ‘충격’ 이 영향을 미치는 기간 - 이후에는 영향 X
ARMA 모델 - AR과 MA 장점 결합
-
과거 데이터(AR)와 과거 오차(MA)를 모델에 동시 결합
-
내부 역학(AR)와 외부 충격(MA)를 동시에 고려할 때 유용
-
ARMA(p,q) : AR의 영향과 MA의 영향을 동시에 고려할 수 있으며, p q 조절로 영향의 밸런스도 맞출 수 있음
-
Weak Stationarity 가정아래 확률과정을 설명
Cut off와 Tail off
AR은 p개 시점 전까지만 t 시점 예측에 고려 → 계수가 t-p 까지만 존재
→ 그 이전은 PACF가 0이됨 (lag가 p보다 큰 PACF 0)
but MA 모델 영향으로 PACF가 이후에도 0이 아님
- ARMA의 tail-off는 AR과 MA 성분의 상호작용으로 인해 발생
- AR(p)의 PACF 절단을 MA(q)가 훼손시키고, MA(q)의 ACF 절단을 AR(p)이 훼손
| 특성 | AR(p) 모델 | MA(q) 모델 |
|---|---|---|
| 의존성 | 과거 관측치에 의존 | 과거 충격에 의존 |
| ACF 패턴 | 지수감소 (Tail-off) | q 이후 절단 (Cut-off) |
| PACF 패턴 | p 이후 절단 (Cut-off) | 지수감소 (Tail-off) |
| 메모리 | 장기 메모리 | 단기 메모리 |
- Example
- MA(3) 모델 → lag 3이후 ACF 가 Cut off → lag 3 이전 시점들과는 공분산이 0이다
이후 존재하는 값들은 신뢰구간 내 → White noise로 간주
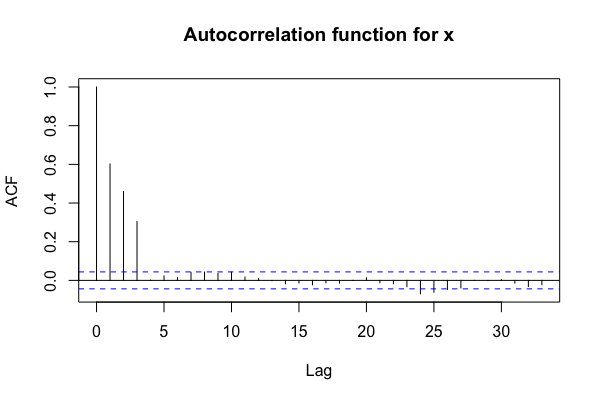
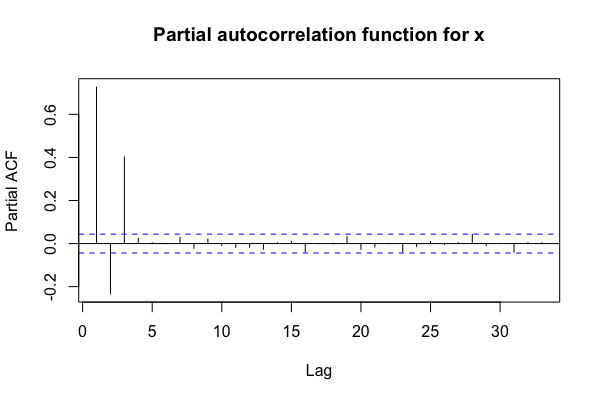
- AR(3) 모델 → lag 3 이후 PACF 는 조건부 회귀계수가 0이다
2. Model Building Problems & Estimation Methods
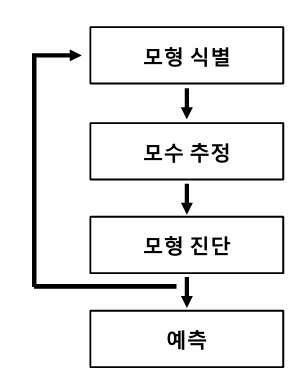
- 모형식별 : 전문가가 ACF와 PACF 그래프의 패턴을 시각적으로 검토
:
- PACF가 특정 시차(lag) p에서 절단(cut-off)되면 AR(p) 모델을 고려
- ACF가 특정 시차 q에서 절단되면 MA(q) 모델을 고려
- 둘 다 점진적으로 감소하면 ARMA 모델을 고려
-
모수추정 : MLE 등 계수 추정
-
모형 진단 (Model Diagnostics)
- 잔차의 WHite noise 여부 확인 → 아니라면 p,q 등 차수를 높여 다시 시행
- 그 외에도 이것저것 더 있음
- 예측 (Forecasting)
ARIMA : Auto Regressive Integrated Moving Average
- ARMA 모델은 weak 정상성 가정이 필수
- but 아닌 경우는 ?
ARIMA(p,d,q) →
- : AR 의 차수 - 회귀에서 고려하는 전 데이터 수
- : MA의 차수 - MA에서 고려하는 전 데이터 수
- d : 추세 차분 수 - d차 차분
- ARMA 식
- AR 파트 다 이항
: MA 에서의 오차
즉 AR 모델의 회귀 잔차 = MA 에서 모델링한 잔차 가중합
→ AR 모델의 가정
- 만 넘기고 좌변 우변 정리
where
- 여기다 대신 차분 적용한 넣으면 ARIMA 가 됨
Definition 4.1 ARIMA
위 4. 의 식 → 단 가 stationary 해야 함.
AR Estimations
innovations, mle, moment 여러 AR 계수 추정방식이 있음.
Innovations
2차 모멘트 유한(weak stationarity 전제임) → 분산과 평균이 유한함 → 그냥 약정상시계열의 다른 말
1~n-1 개의 과거 데이터로 n 시점 데이터를 예측 → 예측 잔차
이 예측 잔차 innovation이 과거 데이터와 상관 없다면 새로운 정보
Innovation 알고리즘의 핵심 아이디어
-
시계열 데이터는 자기상관 구조를 가지므로, 이전 관측치로 현재 값을 선형적으로 예측
-
→완벽한 예측은 불가능하므로 항상 예측 오차(innovation) 발생
-
Innovation 알고리즘은 이 오차를 최소화하기 위해 계수 와 분산 을 재귀적으로 계산
-
Innovation 알고리즘은 각 시점에서 발생하는 예측 오차의 분산 을 통해 모델이 얼마나 데이터를 잘 설명하는지 평가
-
값이 작을수록 모델이 데이터를 잘 설명하고 있음을 의미
3. Order Determination (모형 차수 결정)
Order Determination의 필요성
- ACF/PACF 보고 AR/MA 차수 추정하지만 애매할 때가 많음
- 따라서 Information Criterion (정보 기준)(추가적인 정보)으로 결정
- 대표적인 정보 기준:
- AIC (Akaike Information Criterion)
- BIC (Bayesian Information Criterion)
- HQIC (Hannan-Quinn Information Criterion)
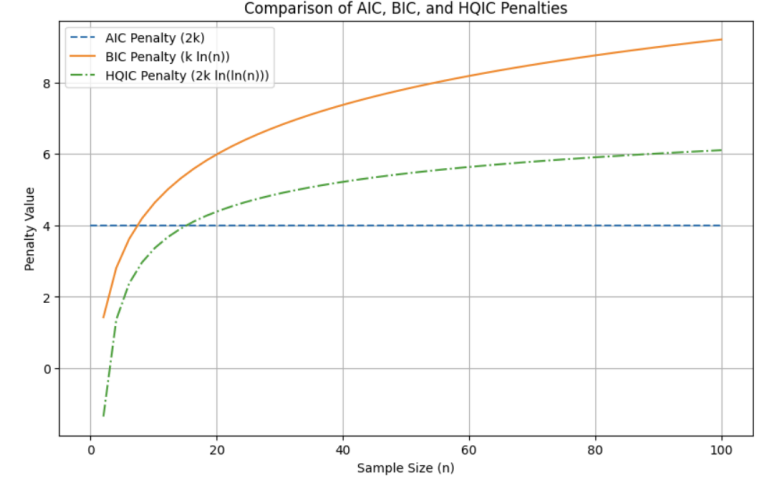
1. AIC (Akaike Information Criterion)
- 공식: AIC = -2ln(L) + 2K
- L: 최대 우도 → -2ln(L): 모델 적합도
- K: 추정된 파라미터 개수 → 2k: 파라미터 클수록 페널티를 주기 위함
- 값이 작을수록 모델이 적합
- 복잡한 모델에 페널티 부여, 간단한 모델 선호
2. BIC (Bayesian Information Criterion)
- 공식: BIC = -2ln(L) + Kln(N)
- N: 샘플 사이즈
- N이 커질수록 페널티 커짐
- AIC보다 더 보수적 (복잡한 모델에 더 큰 페널티)
3. HQIC (Hannan-Quinn Information Criterion)
- 공식: HQIC = -2ln(L) + 2Kln(ln(N))
- AIC와 BIC의 중간 정도로 모델 크기에 따른 페널티 부여
예시 1: AR(1) 모델 - Information Criterion 적용
Step 1. AR(1) 데이터 생성
- 생성 모델(AR(1) Model):
- : white noise
- → 정상성 확보
- 초기분포 계산:
Step 2. Likelihood 계산
- AR(1) 모델은 조건부로 정규분포 따름
- 전체 Likelihood는 다음과 같이 계산:
- 초기값 분포와 조건부 분포를 곱함
- Log-Likelihood를 Python으로 구현 후 계산
- 계산과정
Step 3. AIC, BIC, HQIC 계산
- 각각의 모델에서 log-likelihood(Python) 값을 이용해 지표 계산
- 결과적으로 가장 낮은 값을 가지는 모델 선택
sm.tsa.arma_order_select_ic(data, max_ar, max_ma, ic, trend)- max_ar, max_ma: AR, MA의 최대 차수를 지정해줌
- trend=’c’(상수항 포함)/’n’(미포함)
예시 2: Automatic Order Determination - ARMA(2,2) 데이터
ARMA(2,2) 데이터 생성
ACF/PACF 확인
- ACF: 지수 감소 or lag 1 이후 절단?
- PACF: lag 3 이후 절단?
Python에서 자동 차수 선택
sm.tsa.arma_order_select_ic(data, max_ar=6, max_ma=7, ic=['aic', 'bic', 'hqic'])
- choose_arma 함수로 (0,0) ~ (6,7) 사이 AIC/BIC/HQIC 모두 계산
- AIC 기준으로 ARMA(2,2) 선택됨
- BIC는 더 보수적이라 차수가 낮을 수도 있음
!!참고: choose_arma 함수가 불안정할 수 있어서 choose_arma2 권장!
예시 3: Order Determination - NAO Index (북대서양 진동 지수) - 실제 데이터
- ACF/PACF 보면:
- 둘 다 lag 1에서 절단 → AR(1) 또는 MA(1) 후보
- Information Criterion 적용
- AR(1)과 MA(1) 모델 비교
- 결과:
- AIC, BIC, HQIC 모두 AR(1)이 더 낮음
- 최종 모델: AR(1) 선택
예시 4: Order Determination - GMSATC (연간 평균 지표면 기온 변화)
정상성 검정 (KPSS Test)
- KPSS 통계량 0.0826 (p-value > 0.1)
- 결과: 정상성을 만족함
ACF/PACF 살펴봐도 명확하지 않음
- ACF: lag1에서 절단?
- PACF: 지수적 감소?
IC로 모델 선택
- AIC/HQIC → ARIMA(1,1,3)
- BIC → ARIMA(1,1,1) (BIC는 복잡도에 큰 페널티)
- 결국 교재에서는 ARIMA(1,1,1) 채택해 진단 및 예측 진행
정리 포인트
| 예시 | 분석 포인트 | 최종 선택 |
|---|---|---|
| AR(1) 시뮬 | Likelihood 계산 후 IC | AR(1) 유지 |
| ARMA(2,2) 시뮬 | choose_arma로 AIC/BIC 비교 | ARMA(2,2) |
| NAO Index | ACF/PACF 후 IC로 검증 | AR(1) |
| GMSATC | KPSS 정상성 → IC 비교 | ARIMA(1,1,1) |
4.
4.3 Order Determination
Order Determination?
| MA(q) | AR(p) | ARMA(p, q) (p > 0, q > 0) |
|
|---|---|---|---|
| ACF | Cuts off after lag q | Tails off | Tails off |
| PACF | Tails off | Cuts off after lag p | Tails off |
ACF에서 lag q 이후에 cut off 되면 순서를 (0, q), PACF에서 lag p 이후에 cut off되면 (0, p)로 설정
하지만 동시에 감소하면 순서를 결정할 수 없음
- AIC(Akaike Information Criterion)
AIC = -2ln(L) + 2K
L: Maximum Liklihood K: Number of Estimated Parameters
값이 작을수록 모델이 더 적합
-2ln(L)는 모형의 적합도를, 2K는 파라미터가 클수록 패널티를 줌
Likelihood를 최대화하는 동시에 모형은 간단
- BIC(Bayesian Information Criterion)
BIC =-2ln(L) + Kln(N)
N: Sample Size
AIC에서의 패널티가 ln(N)으로 바뀜
이면 AIC보다 높은 패널티
| AIC | BIC | |
|---|---|---|
| 공식 | −2ln(L)+2K | −2ln(L)+KlnN |
| 패널티 크기 | 비교적 작음 (2) | 데이터 크기에 따라 증가 (lnN) |
| 샘플 크기 n이 클 때 | 복잡한 모델을 허용 | ln(N)이 크므로 더 단순한 모델을 선택 |
| 과적합가능성 | AIC에서 더 높음 |
- HQIC(Hannan-Quinn Information Criterion)
HQIC = -2ln(L) + 2Kln(ln(N))
penalty가 AIC보다 크고 BIC보다는 작음
Example : Information Criterion for AR(1) Model
- AR(1)을 따르는 시계열 모델 생성
np.random.seed(42)
n = 100 # 샘플 크기
phi_true = 0.7 # 가정한 AR(1) 계수
sigma_true = np.sqrt(0.5) # 가정한 표준편차 (sqrt(0.5))
X = np.zeros(n)
epsilon = np.random.normal(0, sigma_true, n)
for t in range(1, n):
X[t] = phi_true * X[t-1] + epsilon[t]X = pd.Series(X)
X.plot(); plt.show()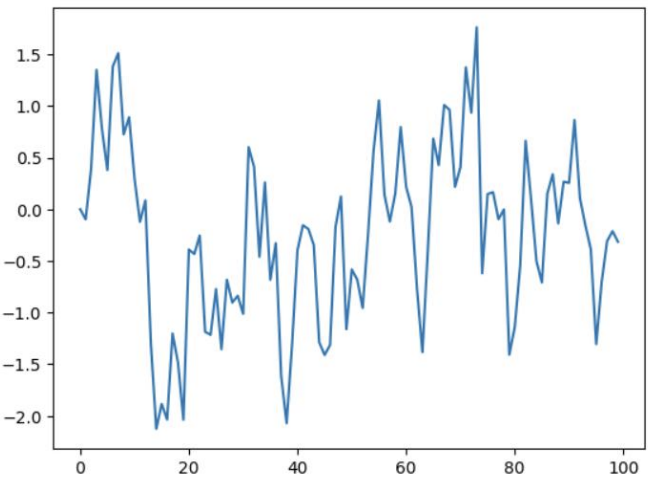
acf_pacf_fig(X, both = True, lag = 20)
plt.show()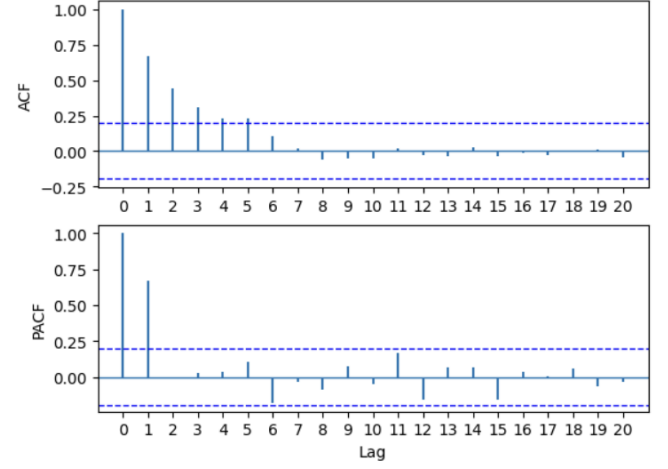
- AR(1) Model의 Likelihood 구하기
AR(1) Model:
- Log-Likelihood Function Python으로 구현
# AR(1) 모델의 로그 우도 함수 도출
def log_likelihood_ar1(X, phi, sigma2):
n = len(X)
# 초기 분포의 로그 우도 (정상성을 가정한 경우)
log_L1 = -0.5 * np.log(2 * np.pi * sigma2 / (1 - phi**2)) - (X[0]**2 / (2 * sigma2 / (1 - phi**2)))
# 조건부 분포의 로그 우도 합산
residuals = X[1:] - phi * X[:-1] # Xt - phi * Xt-1
SSE = np.sum(residuals**2) # 잔차 제곱합
log_L2 = - (n-1)/2 * np.log(2 * np.pi * sigma2) - (1 / (2 * sigma2)) * SSE
# 총 로그 우도 값
log_L = log_L1 + log_L2
return log_L
# MLE로 추정한 파라미터 (phi_hat, sigma2_hat) 사용
phi_hat = np.sum(X[1:] * X[:-1]) / np.sum(X[:-1]**2) # phi 추정
sigma2_hat = np.var(X[1:] - phi_hat * X[:-1], ddof=1) # sigma^2 추정 (불편분산 사용)
# 로그 우도 계산
log_L = log_likelihood_ar1(X, phi_hat, sigma2_hat)
비효울적임!!
AIC,BIC,HQIC를 종합해서 ARMA Model의 최적차수(p,q)를 찾아주는 함수
- sm.tsa.arma_order_select_ic(data,max_ar,max_ma,ic,trend)
max_ar,max_ma는 AR,MA의 최대 차수 지정(기본값:4)
ic는 퇴적차수를 찾을 때 사용
trend는 상수항 포함 여부
- choose_arma(data,max_p,max_q,ctrl)
max_p,max_q는 최대 차수(기본값:p=6,q=7)
ctrls는 제어 계수(1.0에서 1.1 사이, 보통 1.05 이내)
Example 4.2 (Auotomatic Oreder Determination)
ARMA(2,2) Model 을 따르는 가상 시계열데이터를 생성, 최적의 ARMA를 선택
# Step 1: 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.arima_process import arma_generate_sample
from PythonTsa.plot_acf_pacf import acf_pacf_fig
from PythonTsa.Selecting_arma import choose_arma
from statsmodels.tsa.arima.model import ARIMA
from PythonTsa.LjungBoxtest import plot_LB_pvalue
from scipy import statsSimulating and Building ARMA(2,2) Model
# Step 2: ARMA(2, 2) 데이터 생성
# AR, MA 계수 정의
ar = np.array([1, -0.8, 0.6]) # AR(2) 부분
ma = np.array([1, 0.7, 0.4]) # MA(2) 부분
# 랜덤 시드 고정
np.random.seed(12357)
# 500개의 샘플 데이터 생성
y = arma_generate_sample(ar=ar, ma=ma, nsample=500)
y = pd.Series(y, name="y")# 시계열 데이터 플롯
y.plot(); plt.show()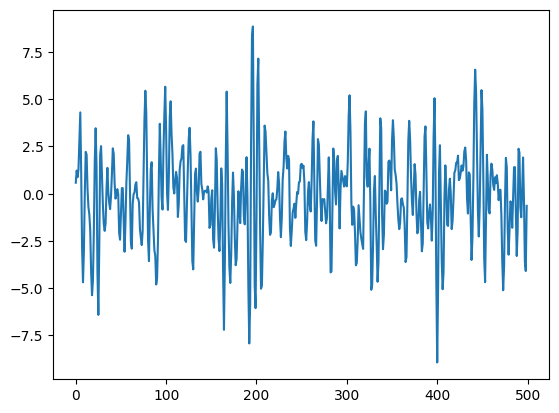
# Step 4: Order Determination by sm.tsa.arma_order_select_ic
inf = sm.tsa.arma_order_select_ic(y, max_ar=6, max_ma=7, ic=['aic', 'bic', 'hqic'], trend='n')
print("AIC 기준 최적 차수:", inf.aic_min_order)
print("BIC 기준 최적 차수:", inf.bic_min_order)
print("HQIC 기준 최적 차수:", inf.hqic_min_order)
AIC 기준 최적 차수: (4, 5)
BIC 기준 최적 차수: (2, 2)
HQIC 기준 최적 차수: (2, 2)
# Step 5: Order Determination by choose_arma
from PythonTsa.Selecting_arma2 import choose_arma2
choose_arma2(y, max_p=6, max_q=7, ctrl=1.02)
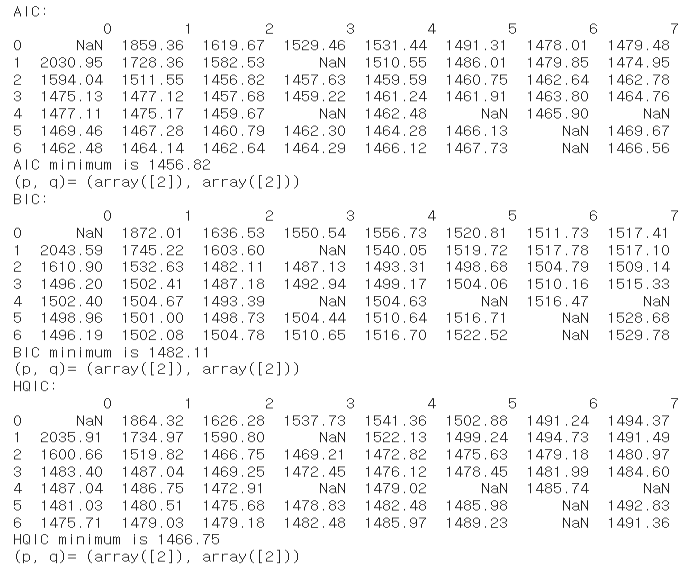
확인하면 ARMA(2,2) 선택!
Reference
Shumway, R. H., & Stoffer, D. S. (2017). Time Series Analysis and Its Applications: With R Examples. Springer.
