0. Recall
Stationary(정상성)
정상성이란 3가지 조건을 모두 만족하는 경우를 말한다.
(1) 평균이 each t에 대해 constant다.
(2) 분산이 each t에 대해 constant다.
(3) 공분산이 t에 대해 독립이다 →
왜 정상성을 만족해야하는가?
우리가 하고 싶은 것은 시계열을 예측하는 것이고, 그러기 위해서는 정제된 데이터가 필요함. 정제되지 않은 데이터로 예측하는 것은 신뢰성이 떨어지고, 잘 예측이 안될 가능성이 크다. 따라서 어떤 정제된 데이터 기준이 필요하고 그것이 바로 정상성이다.
Stationary 하지 않은 것은?
(1) trend가 있는 경우 → 평균이 상수이다라는 조건을 만족하지 않는다.
(2) 계절성이 있는 경우
Differencing
차분에는 두가지 종류가 있다.
(1) Differencing of order d (추세를 없애는데 사용) :
예시) 일 때, 이다.
(2) Differencing of lag k (Seasonal Differencing) :
예시) 일 때, 이다.
Tail off & Cut off
Tail off: 자기상관값들이 지수적으로 서서히 감소
Cut off: 어느 lag이후 막대가 모두 신뢰구간에 있는 경우
모델에 대한 복습
AR, MA, ARMA 모델에 대해 배웠고, 세션 자료 15p에 잘 정리되어 있으므로 생략한다.
1. Seasonal Differencing
Seasonality
: 특정한 달이나 계절의 데이터가 높아지거나 낮아지는 경우를 의미하며 계절성은 월이나 분기 등의 고정된 주기 를 가지는데, 계절성 패턴이 반복되는 시간 간격을 계절 주기라고 한다.
Seasonal Differencing
계절성이 있는 시계열은 비정상이므로, 계절 차분을 통해 정상 데이터로 만들 수 있다. 비정상 시계열 데이터 가 추세와 계절 주기가 인 계절성이 있다고 하자. 이때, 다음과 같이 계절 차분을 할 수 있다.
- : (ordinary) differencing of order
- : seasonal differencing of order
★ 대부분의 경우 이며, 차 일반 차분과 주기가 인 차 계절 차분을 진행하면 개의 데이터 손실이 발생한다.
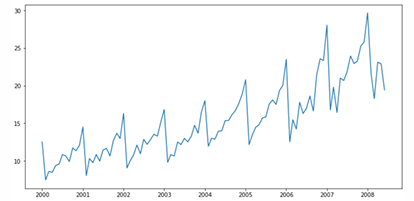
Example 5.1
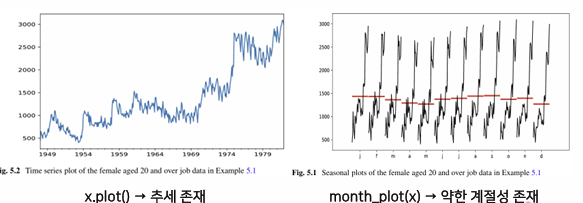
→ 플롯을 그려서 계절성 확인
→ seasonal_decompose 를 사용해 추가적으로 계절성을 판단해볼 수 있다.
⇒ 추세와 계절성이 모두 존재하는 경우에 대해서, 일반 차분과 계절 차분을 같이 진행해볼 수 있다.
⇒ statsmodels 라이브러리의 sm.tsa.statespace.tools.diff(x, k_diff, k_seasonal_diff, seasonal_periods) 함수를 이용하면 된다.
x: 데이터k_diff: 일반 차분의 차수k_seasonal_diff: 계절 차분의 차수seasonal_periods: 계절 주기
⇒ 최종적으로 kpss 를 활용해 kpss stationary test를 진행할 수 있다.
2. SARIMA Models
Motivation
ARMA
- 단기적인 상관관계
- 최근 과거 데이터와 white noise 반영
- ordinary correlation 모델링
SARIMA
- 단기적인 상관관계 + 장기적인 상관관계
- 최근 과거 데이터와 white noise 반영 + 주기 내 같은 시기 데이터와 white noise 반영
- ordinary correlation + seasonal correlation 모델링
Definition of SARIMA(p,d,q)(P,D,Q)s
시계열 는 다음을 만족할 때 계절 주기 를 가지는 SARIMA(p,d,q)(P,D,Q)s 과정을 따른다.
만일 차분된 시계열 가 정상이고, 가 다음의 모델을 만족한다.
- AR 다항식 :
- MA 다항식 :
⇒ ordinary correlation을 모델링하는 구조
- 계절 AR 다항식 :
- 계절 MA 다항식 :
⇒ seasonal correlation을 모델링하는 구조
4 Remarks on Definition of SARIMA
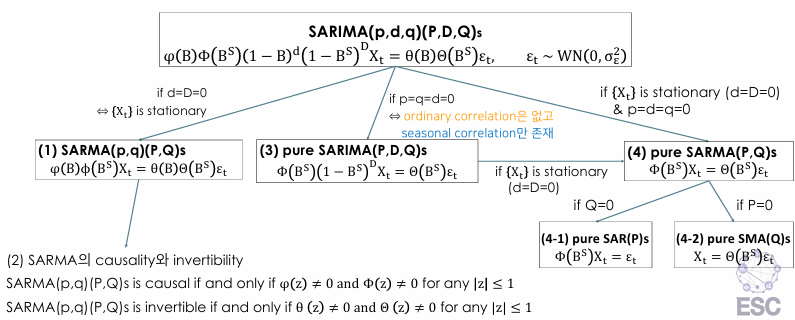
Summary
★ 이때, pure model은 현실적이지 않다. 대부분의 실제 시계열 데이터는 최근 데이터의 영향을 강하게 받으며, 이 모델은 급격한 변화(충격)에 대한 반응이 부족하기 때문이다.
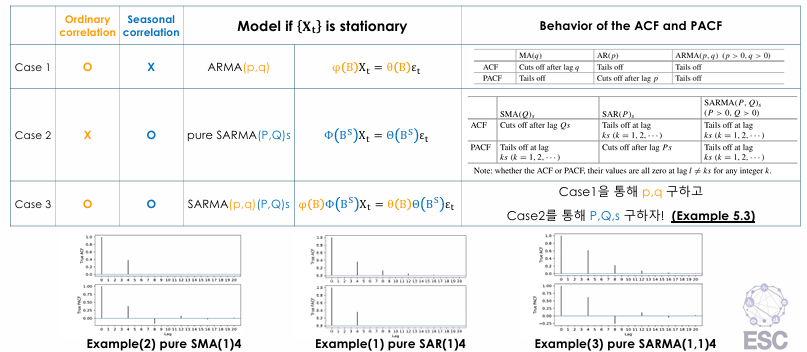
Example 5.2 (Case2)
Pure SARMA의 예시를 살펴보자. 는 정상이고, 계절 주기 4를 갖는다고 가정하자.
-
or
⇒ 위의 데이터는 계절 주기 4를 가지는 pure seasonal AR(1) 모델이라고 할 수 있다.
⇒ 즉, pure SAR(1)_4이다.
이 경우 ACF와 PACF를 살펴보면, ACF는 4를 주기로 점점 감소하며, PACF는 4 이후로 cut off 된다.
★ SAR → ACF tail off / PACF cut off
-
or
⇒ 위의 데이터는 계절 주기 4를 가지는 pure seasonal MA(1) 모델이라고 할 수 있다.
⇒ 즉, pure SMA(1)_4이다.
이 경우 ACF와 PACF를 살펴보면 ACF는 4 이후로 cut off 되며, PACF는 4를 주기로 점점 감소한다.
★ SMA → ACF cut off / PACF tail off
-
or
⇒ 위의 데이터는 계절 주기 4를 가지는 pure seasonal ARMA(1,1) 모델이라고 할 수 있다.
⇒ 즉, pure SARMA(1,1)_4이다.
이 경우 ACF와 PACF를 살펴보면, ACF를 4를 주기로 점점 감소하고, PACF도 4를 주기로 점점 감소한다.
★ SARMA → ACF tail off / PACF tail off
Example 5.3 : SARMA(0,1)(0,1)4를 따르는 가상 시계열 데이터를 생성하고, ACF/PACF를 통해 모델을 결정해보자.
-
라이브러리 불러오기
:
PythonTsa.plot_acf_pacf의acf_pacf_fig를 활용해 ACF/PACF를 그릴 수 있다. -
데이터 생성
:
sm.tsa.SARIMAX함수를 활용해 데이터를 생성할 수 있다. -
ACF와 PACF를 확인하여 모델 후보 결정
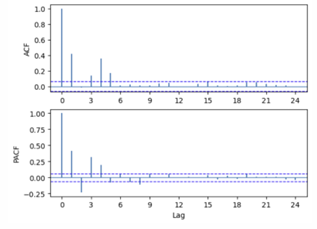
- non-seasonal
- ACF 1에서 절단, PACF 지수적 감소 → MA(1)
- ACF 5에서 절단, PACF 지수적 감소 → MA(5)
- seasonal
- ACF 4에서 절단, PACF 지수적 감소 → SMA(1)_4
⇒ 모델 후보 (1) SARMA(0,1)(0,1)_4 (2) SARMA(0,5)(0,1)_4
★ (2) 모델 적합 후 계수를 확인해보면, ma.L2, ma.L3, ma.L4, ma.L5 모두 유의하지 않다는 결과가 나오는데, 이 파라미터들을 제외하면 결국 SARMA(0,1)(0,1)_4 모델이 남게 된다. SARIMA 모델의 구성 요소
| Case | Ordinary Correlation (p,q) | Seasonal Correlation (P,Q) | Model | 설명 |
|---|---|---|---|---|
| 1 | O | X | ARMA(p,q) | 일반적인 ARMA 모형 |
| 2 | X | O | Pure SARMA(P,Q)s_ss | 현실적이지 않음 (계절성만 있고 최근 데이터 반영 안 됨) |
| 3 | O | O | SARMA(p,q)(P,Q)s_ss | 현실에서 가장 유용한 모델 (일반 + 계절 모두 반영) |
현실의 시계열은 대부분 최근 데이터 영향 + 계절성 반영 → 모델 사용
SAR, SMA, SARMA 순수 모델의 ACF/PACF 특징
- Pure SAR(1)4_44:
- ACF: s배수(lag 4, 8, 12...)에서만 tail off
- PACF: lag 4에서 cut off
- Pure SMA(1)4_44:
- ACF: lag 4에서 cut off
- PACF: s배수에서 tail off
- Pure SARMA(1,1)4_44:
- ACF/PACF: 모두 s배수에서 tail off
→ 이 패턴은 실제 시계열의 ACF/PACF를 해석할 때 모델 추정 힌트로 사용됨.
ACF/PACF를 통한 모델 결정 전략
- Case 1 (Ordinary만 있는 경우) → ARMA(p,q) → 일반적인 lag 사용
- Case 2 (Seasonal만 있는 경우) → SARMA(P,Q)s_ss → s배수 lag 사용
- Case 3 (둘 다 있는 경우) → SARIMA(p,d,q)(P,D,Q)s_ss
→ Ex. ACF가 lag 1에서 cut, PACF는 지수적 감소 → MA(1) 가능성 → p=0, q=1
예제 5.3: 모델 결정 과정
sm.tsa.SARIMAX함수로 데이터 생성- Step 2: 시계열 확인 (추세 없음, 일정 분산 → 정규성 만족)
- Step 3: ACF/PACF 분석 → 모델 후보:
- Step 4:
SARIMAX(...).fit()결과 분석 → 유의하지 않은 계수 제거 → 최종 적합 모델: ⚠️오류 주의q=5와Q=1, s=4는 lag 4 중복됨 → 모형 설정 오류 발생 (동일한 lag이 MA와 SMA에 겹침)
SARIMA 모델 일반 구축 절차
1. 정상화
- 시계열의 추세와 계절성 확인
- 둘 다 존재하면 계절 차분 먼저, 그 후 필요시 일반 차분
2. 모형 선택
- ACF/PACF로 p,q,P,Qp, q, P, Qp,q,P,Q 식별
- AIC, BIC 등 criterion으로 모델 비교
3. 모수 추정
- SARIMA 모델 수식에 따라 추정
4. 모형 진단
- 파라미터 유의성 검정
- ACF/Ljung-Box/QQ plot 등으로 잔차 진단
5. 예측
- in-sample / out-of-sample forecasting
Case Study #1: Chinese Quarterly GDP
- 데이터 특징: 계절성 있고 추세 존재 → 로그 변환 후 차분
- 차분 순서: ① 로그 변환 → ② 계절 차분 (lag=4) → ③ 1차 차분
- 차분 결과: 정상성 확보
Case Study #2: Corticosteroid Drug Sales in Australia
- 데이터: 월별 데이터, 계절성 뚜렷
- 차분: 계절 차분 (lag = 12)
- KPSS test로 정상성 확인
03 SARIMA Model Building(Case Study #1)
Step 1. 시도표 확인 후 , 필요시 변환 및 차분을 진행하여 정상시계열로 바꿔줌
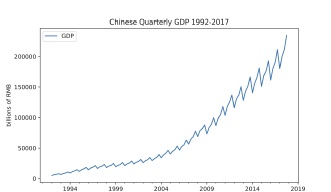
분산안정화, 평균안정화가 모두 필요한 상황으로 파악된다.
- 로그 변환
분산안정화를 위해, 로그변환을 진행함.
lx=np..log(x)의 코드 이용
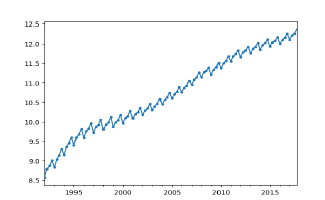
- 차분
추세와 계절성이 모두 파악되므로 일반차분과 계절차분을 모두 진행해야하는데, 이 경우 계절차분을 먼저 진행한다.
lag=4의 계절차분을 하는 코드는 dlx=lx.diff(4) 가 된다.
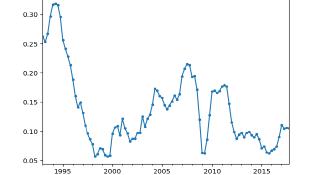
이후, 1차차분을 하는 코드는 dlx=dlx.diff(1)이다.
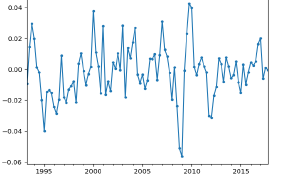
이후 KPSS TEST를 통해 이렇게 변환, 차분한 데이터가 stationary인지, non-stationary인지 파악할 수 있다.
Step 2. 모형 선별
ACF와 PACF를 보고 lag ~ 이후 절단, 지수적 감소를 바탕으로 시각적으로 파악해도 되고, Atuomatic Order Determination 방식을 사용해도 된다.
이때, SARIMA에서는 pm.auto_arima함수를 사용한다.

가능한 (p, q) 및 (P, Q) 조합 중 AIC가 최소화되는 모델을 찾아준다.
Step 3. 모수 추정
결정된 모형을 바탕으로 모수를 추정하는데, 이때 모수는 여러방법으로 추정할 수 있지만 주로 Maximum Likelihood 방법을 사용한다.
Step 4. 모형 진단
- 유의성 검정
-모수가 통계적으로 유의한지 검정하는 것으로, 모든 계수의 p-value가 0.05보다 작다면 해당 모수가 통계적으로 유의하지 않다는 귀무가설 H0을 기각한다.
- 잔차 분석
-residual이 white noise 가정, 즉 정규성을 따르며 잔차 간 자기상관이 없는지를 확인한다.
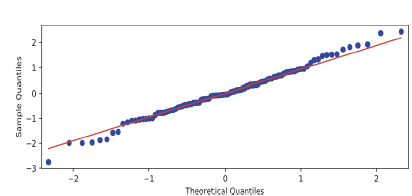
-잔차의 정규성을 파악하는 QQ-Plot은, 잔차의 분포가 대각선과 일치하면 정규성을 따른다고 판단하게 된다.
-잔차 간 자기상관을 파악하는 방법으로는, 우선 잔차의 ACF를 구하는 방법이 있다.
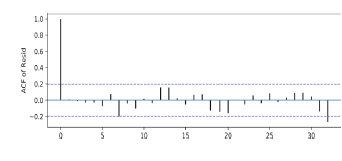
ACF가 대부분의 Lag에서 0에 가깝다면 잔차 간 자기상관이 없다고 생각하게 된다.
-또다른 방법으로는 Ljung-Box 검정이 있는데, 이것은 잔차에 자기상관이 존재하는지를 검정하는 통계적 방법이다.
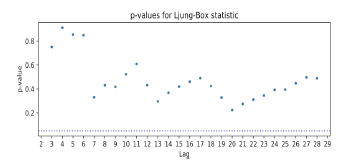
대부분의 p-value가 0.05보다 크다면 잔차 간 자기상관이 없다고 확인한다.
Step 5. 모형 예측
- In-sample prediction
알고 있는 정답 데이터를 바탕으로 예측을 수행함으로써 모델이 얼마나 잘 적합되었는지 확인함.
- Out of sample forecasting
훈련되지 않은 미래 데이터에 대한 예측을 수행하는 것으로, 실질적으로 ‘예측’을 수행하는 과정이다.
Case Study #2: Corticosteroid Drug Sales in Australia
- 정상화
- 월간 데이터 → 계절 차분 lag=12
- KPSS Test 결과: p-value > 0.1 → 정상성 만족
- 모델 식별
- 일반 ACF/PACF: ACF lag 5, PACF lag 3에서 절단
- 계절 ACF/PACF: ACF lag 12, PACF lag 24에서 절단
- 후보 모델:
- SARIMA(3,0,0)(2,1,0)[12]
- SARIMA(3,0,0)(0,1,1)[12]
- SARIMA(0,0,5)(0,1,1)[12]
- SARIMA(0,0,5)(2,1,0)[12]
- 모수 추정
- 선택된 모델:
- *ma.L4 (B^4)**의 계수 p-value > 0.05 → 유의하지 않음 ⇒ 모델을 재설정해 θ₄ = 0으로 리빌드
- 모형 진단
- 모든 계수 유의
- 잔차 분석:
- Ljung-Box Test: 대부분 lag에서 p > 0.05
- QQ Plot: 정규성 만족
- ACF of Residuals: white noise
- ACF of Squared Residuals: ARCH 효과 없음
3.4 REGARMA (ARMAX)
정의
Regression + ARMA error
외생변수 와 내생변수 , 그리고 오차항 를 포함한 회귀 모델
모델 수식
- ARMA 구조의 오차항 포함
- 주기적인 성분이 있는 경우 , 로 seasonality 표현 가능
특징 및 장점
- SARIMA는 계절 차분 후 모델링, REGARMA는 계절성을 회귀식 내에서 직접 모델링
- 복잡한 주기 구조를 더 유연하게 표현 가능
- 외생 변수 활용 가능 → 예측력 향상 가능
