1.1 Deterministic and Stochastic Models
모델링의 방법은 불확실성(uncertainty)의 여부에 따라 결정론적(deterministic) 방법, 확률론적(stochastic) 방법으로 나뉜다.
1. Deterministic Model
결정론적인 시스템에는 무작위성(randomness)이 없다. 즉, 입력(input)이 주어졌을 때 결과(output)은 반드시 동일하게 나온다. 함수나 미분 방정식은 특히 결정론적인 과정을 설명하기 위해 사용된다.
예를 들어, 박테리아의 수가 단위시간(1분)당 고정된 비율(20%)만큼 증가한다고 하자.
dtdy=(0.20)yy(t):# of bacteria present after t minutes
미분 방정식을 풀면, 다음과 같은 지수함수 형태의 해가 나온다.
y(t)=y0e(0.20)ty0=y(0):initial size of the population
- (참고) 도출 과정
dtdy=(0.20)y ⇒y1dy=0.20dt∫y1dy=∫0.20dt ⇒ln∣y∣=0.20t+Cy(t)=eC⋅e0.20t=y0e(0.20)t
→ t분 후의 박테리아의 수에 대해 명확하게 말할 수 있다.
2. Stochastic Model
확률론적인 시스템에는 무작위성(randomness)이 있다. 즉, 결과는 불확실하다. 확률 변수나 확률 분포 등의 개념이 활용된다.
예를 들어, 박테리아의 다음 번식까지의 시간이 rate parameter를 0.20으로 하는 지수 분포를 따른다고 하자. 다음과 같이 나타낼 수 있다.
y(t)=y0+N(t)N(t)∼Poisson(0.20⋅y0⋅t)
→ t분 후의 박테리아의 수에 대해 매번 다르게 말할 수 있다.
□ 만일 t 시점에서의 박테리아 수를 예측하는 것이 목표라면, 결정론적 모델이 더 효율적일 것이다. 그러나, 확률론적 모델은 각 개체에 대한 불확실성이 반영되어 있기 때문에 다음과 같은 다양한 질문에 대한 답을 내릴 수 있다.
- t 시점에서의 박테리아의 평균 수는?
- t분 후의 박테리아의 수가 특정 임계점을 넘을 확률은?
- 박테리아의 수가 2배가 되기까지의 시간의 확률 분포는?
3. SIR Model by Reed & Forest (Example 1.2)
SIR(Susceptible-Infected-Removed) 모델은 전염병이 사람 간 접촉을 통해 전파되고, 일정 시간이 지나면 회복 또는 면역력을 확보하여 전파에서 제외된다는 사실을 단순화된 형태로 나타낸다.
- S(Susceptible) : 전염 가능성이 있는 인구 수 → St : t 시점에 전염 가능성이 있는 인구 수
- I(Infected) : 전염된 상태의 인구 수 → It : t 시점에 전염된 상태의 인구 수
- R(Removed) : 회복한 상태(면역)의 인구 수 → Rt : t 시점에 회복한 상태(면역)의 인구 수
- z : S와 I인 사람이 만났을 때 전염이 될 확률(고정)
- p : S인 사람이 전염된 확률로, 1−(1−z)It
- 보충 설명 S인 사람이 I인 사람과 있을 때 전염될 확률은 z이고, 전염되지 않을 확률은 1−z이다. 만약 시점 t에 감염자가 It명 있다면? S인 사람이 모든 It명에게서 단 한 번도 전염되지 않을 확률은 (1−z)(1−z)⋯(1−z)=(1−z)It가 된다. 결국, S인 사람이 적어도 한 명으로부터 전염될 확률은 1−(1−z)It이다.
시점 t에서 S인 사람의 수가 St명일 때, 각 사람마다 감염될 확률 p는 동일하고, 독립적으로 일어난다. 이를 동전 던지기에 비유하면, St개의 동전을 동시에 던졌을 때, 앞면(=감염)이 나올 확률이 p인 상황과 동일하다. 따라서, 시점 t+1에 감염되는 사람의 수 It+1은 확률적으로 결정이 되며, 다음과 같이 이항 분포를 따른다.
It+1∼Binomial(St,p)
It+1은 위와 같은 분포에서 랜덤 샘플링하여 구할 수 있고, St+1=St−It+1로 구할 수 있다. St인 사람들은 그 다음 시점에서 계속 전염 가능성이 있는 상태(St+1)로 남아있거나, 전염(It+1)될 수 있다.
1.2 Stochastic Processes
1. Stochastic Processes
확률 과정은 확률 변수들의 모임으로, {Xt∣t∈I}이다. 이때, I는 지표 집합(index set)으로 주로 시간을 나타내는 경우가 많다. 그리고 S는 상태 공간(state space)으로, 각 확률 변수 Xt가 취할 수 있는 값들의 집합이다.
- 지표 집합 (Index set) : t가 가질 수 있는 값
- 이산형 : I={0,1,2,…}
- 연속형 : I=[0,∞)
- 상태 공간 (State space) : Xt가 가질 수 있는 값
- 이산형 지표 & 이산형 확률 변수의 예 : 모노폴리 → 턴의 수 & 모노폴리의 칸 번호 (1~40)
- 이산형 지표 & 연속형 확률 변수의 예 : 포화 산소량 → 매 시(hour) 단위 & 농도
- 연속형 지표 & 이산형 확률 변수의 예 : 도착 과정 → 연속적인 시간 & 메시지의 개수
- 연속형 지표 & 연속형 확률 변수의 예 : 브라운 운동 → 연속적인 시간 & 입자의 위치
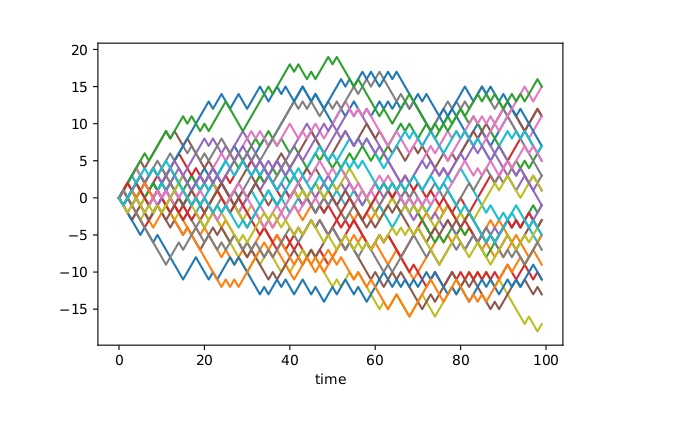
2. Random walk - Gambler’s Ruin
이산형 지표 & 이산형 확률 변수의 예로 “도박꾼의 파산”이 있다. 먼저 도박꾼이 초기 자산 k 달러로 도박을 했다고 가정하자. p의 확률(성공)로 +1이 되고, 1−p의 확률(실패)로 −1이 된다. 이때 n(n>k) 달러에 도달하거나 0 달러에 도달하면 도박을 종료한다.
- Xk=1 with probability p
- Xk=−1 with probability 1−p
- Sn=k+X1+X2+⋯+Xn for n≥1, S0=k
- S0,S1,S2,⋯는 상태 공간 Z를 가지는 이산 시간 확률 과정이다.
- Sm의 값이 n(n>k)에 도달하거나 0이 되면 종료한다.
2.1 Introduction:
💡 Markov Chain의 정의와 transition matrix에 대해 알아보자.
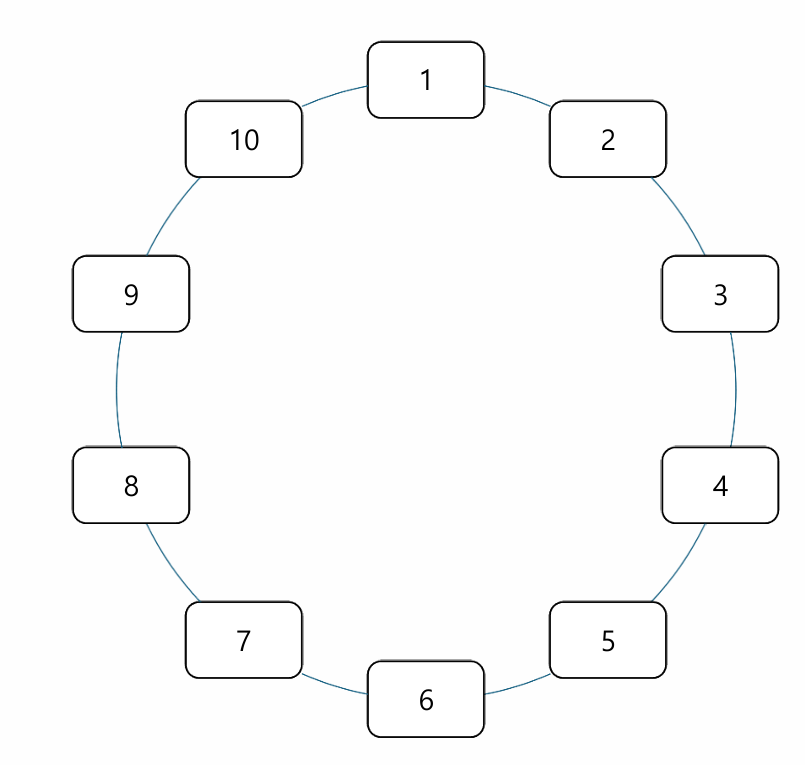
주사위 눈에 따라 현재 상태에서 눈의 수만큼 말이 이동하는 보드 게임(monopoly)을 생각해보자.
Xn=n번 주사위를 굴린 후 말의 위치
랜덤 변수 Xn을 위와 같이 정의하자.
상황: X0=1,X1=2,X2=4,X3=8
위와 같은 상황에서 X4=10일 확률은
P(X4=10∣X0=1,X1=2,X2=4,X3=8)=P(X4=10∣X3=8)=61
즉 미래의 상태가 오직 직전의 상태와 관련이 있다는 것을 알 수 있다.
위 보드 게임에서 말의 위치 집합은 랜덤 변수의 집합이므로 확률 과정 중 monopoly이다.
그 중 다음 단계가 오직 현재의 상태와 관련이 있는 성질에 의해 Markov Chian이라 불린다.
Markov Chain
집합 S를 상태 공간(state space)이라고 하자. 확률 변수들의 열 X0,X1,X2,…가 S의 원소를 값으로 가지며, 다음과 같은 성질을 만족하면 이를 마코프 체인(Markov chain) 이라고 한다. P(Xn+1=j∣X0=x0,X1,…,Xn−1,Xn=i)=P(Xn+1=j∣Xn=i)
모든 x0,x1,…,xn−1,i,j∈S 및 n≥0 에 대하여 성립한다.
이 성질을 마코프 성질(Markov property) 이라고 한다.
여기서 Markov Chain은 time-homogeneous 성질을 가진다
Markov Chain is called time-homogeneous if
P(Xn=j∣Xn−1=i)=P(X1=j∣X0=i)∀n∈N
Markov Chain은 monopoly이므로 state space는 finite개(let k)의 원소를 가진다.
이때 현 상태에서 다음 상태로 가는 경우의 수는 K*K개이고 각 경우의 수의 확률을 행렬로 나타낸 것을 transition-matrix라 한다
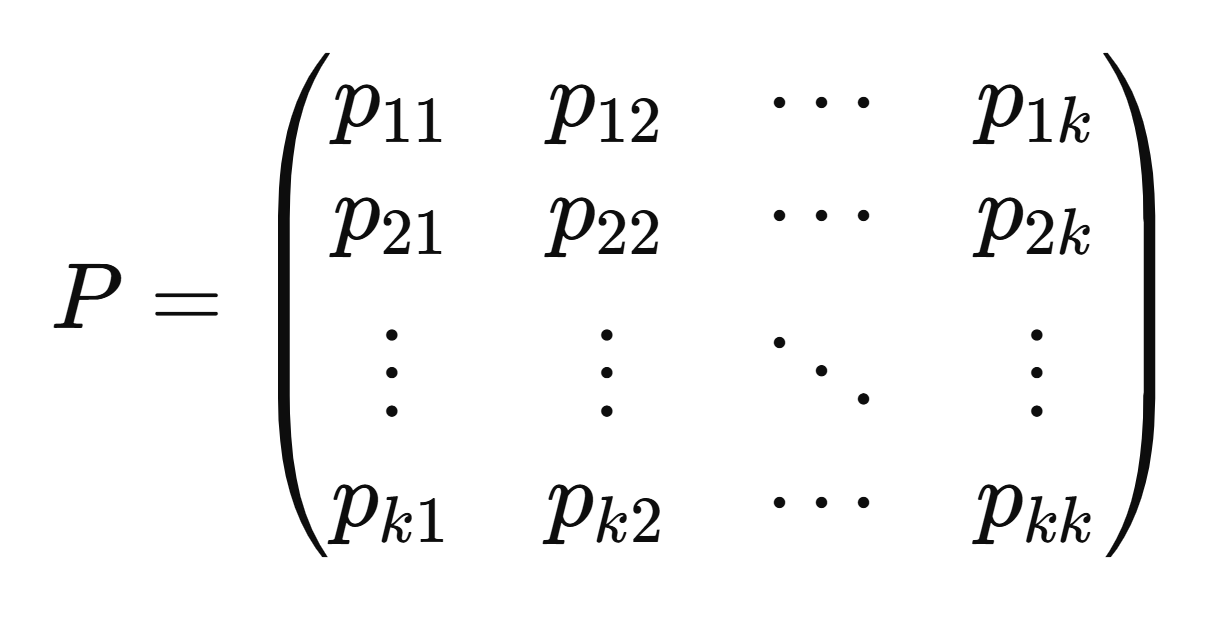
j=1∑nPij=1for all i=1,2,…,k
각 행은 현 상태 i에서 다음 상태 j=1,…..,k로 갈 때의 확률이므로 P_i1+,,,,+P_ik=1이다.
1.Pij≥0∀i,j
2.j=1∑nPij=1∀i
즉 (one-step)transition matrix면 stochastic matrix이다.
2.2 Markov Chain Cornucopia - examples
💡Markov Chain이 적용되는 상황들을 알아보자.
1. weather
어느 지역의 날씨가 비(r),눈(s),맑음(c) 이 세가지만 있다고 가정했을 때의 transition matrix
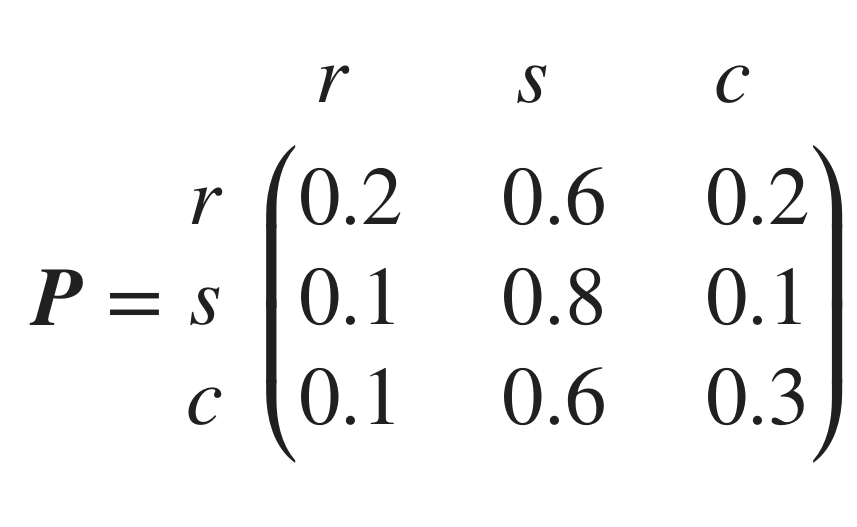
Q: 다음날 눈이 올 확률은?
P(Xn+!=s∣Xn=s)P(Xn+!=c∣Xn=s)P(Xn+!=r∣Xn=s)
: 적어도 60% 이상
2. i.i.d sequence
Sequence of iid random variables > Markov chain
state space={1,…k}
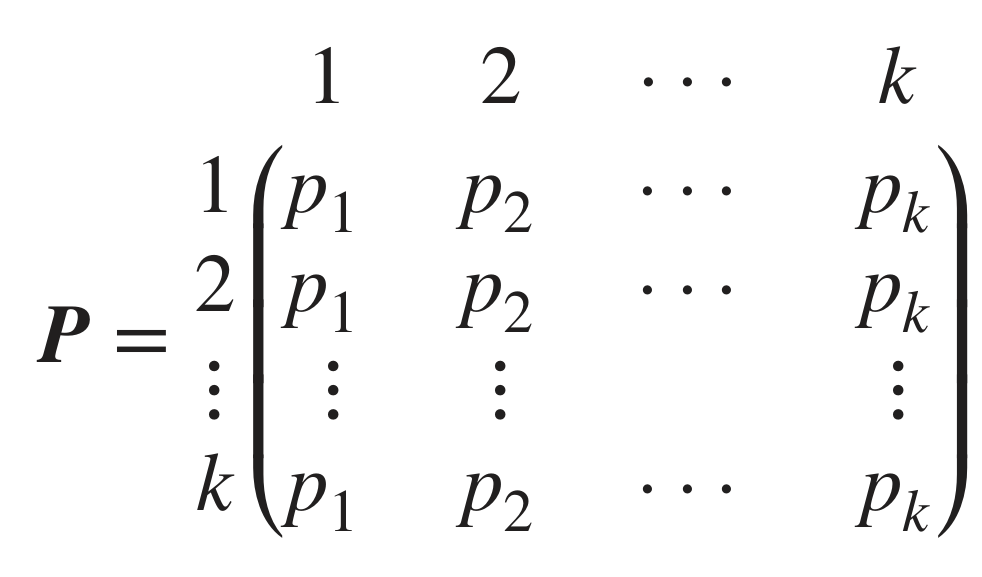
각 랜덤 변수들은 독립이기 때문에
P(X1=j∣X0=i)=P(X1=j)
따라서 모든 현재 상태에 대해서 X_i로 갈 확률이 p_i로 나타나기 때문에 transition matrix를 위와 같이 나타낼 수 있다.
3. Gambler’s ruin
도박꾼이 초기 자산 k달러에서 도박 (p의 확률로 +1, 1-p의 확률로 -1)
n달러 또는 0달러에 도달할 시 게임이 끝남
Xn:=n번째 게임의 결과로 얻은 돈
Sn=k+X1+⋯+Xn,for n≥1,S0=k
Sm=0orn이 되면 게임 종료
S0,…,Sn은 확률 과정(중 Markov Chain)
ex) n=6이고 p=1/3인 경우

4.Random walk on a graph
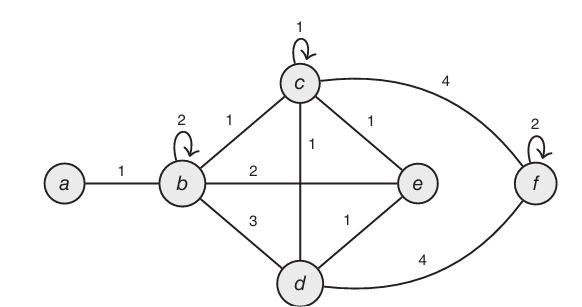
Def:
Degree of vertex v, denoted deg(v), is the number of neighbors of v.
deg(a)=1,deg(b)=deg(c)=deg(d)=4,deg(e)=3,deg(f)=2.
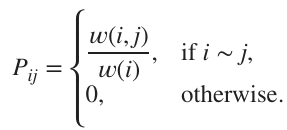

위 행렬은 위 상황에서의 transition matrix이다.
5.Lazy librarian-최적의 책 나열 알고리즘
책의 인기 정도를 대출될 확률로 생각하자. k권의 책에 대해
p1+,...,+pk=1
초기에 책이 왼쪽부터 index순으로 나열되어 있다. 사서는 반납된 도서를 왼쪽에 계속 넣는다.
이때 시간이 지날수록 동선이 최소화되는 나열에 수렴하게 된다.
2.3 Basic Computations
1. Markov chain에서의 probability distribution
probability distribution은 확률 벡터의 형태로 나타내고 α,λ,π 등으로 표기한다.
α=(α1,α2,…,αk)가 Xi의 분포 → P(Xi=j)=αj for all j
cf) probability vector란? 더해서 1인 음이 아닌 수들로 구성된 행백터
초깃값(X0=j)과 Markov chain의 transition matrix가 주어진 경우
초기 분포는 j번째 원소만 1인 (0, … , 0, 1, 0, … , 0)으로 볼 수 있고, transition matrix를 적용하여 n step 이후의 값 Xn의 확률 분포를 구할 수 있다(정확한 값을 구할 수는 없음)
2. n-step Transition Matrix
X0,X1,… 가 transition matrix P를 가지는 Markov chain이라고 할 때, Pn은 n-step transition matrix가 된다.
For n≥0,Pijn=P(Xn=j∣X0=i) for all i,j
즉, transition matrix P를 n번 거듭제곱하면 n-step 후로 전이시키는 transition matrix를 구할 수 있다.
Ex) 6-step transition matrix
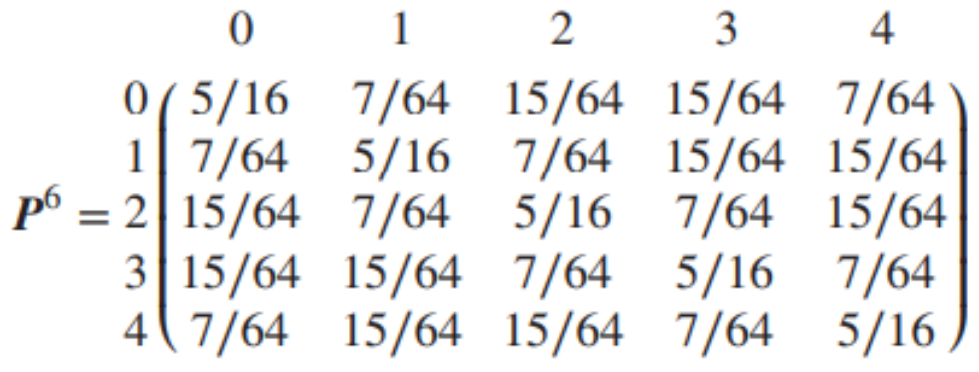
Q : 각 원소가 가지는 의미는?
A : P6의 i행 j열 원소를 Pij6라고 하면, Pij6는 X0=i에서 6번의 step을 거쳐 X6=j가 될 확률을 의미한다.
3. Chapman-Kolmogorov Relationship
For m,n≥0, Pijm+n=ΣkPikmPkjn
위 식을 정리해보면
⇒Pijm+n=P(Xm+n=j∣X0=i)
=k∑PikmPkjn
=k∑P(Xm=k∣X0=i)P(Xn=j∣X0=k)
=k∑P(Xm=k∣X0=i)P(Xm+n=j∣Xm=k)
와 같다.
이는, m+n번의 step을 거쳐 확률변수가 i에서 j로 전이할 확률이 모든 k에 대해 (m번의 step을 거쳐 확률변수가 i에서 k로 전이할 확률)*(n번의 step을 거쳐 확률변수가 k에서 j로 전이할 확률)을 합한 것과 같음을 의미한다. 여기서 k는 확률변수 X가 가질 수 있는 값을 나타낸다.
4. Distribution of Xn
초기 분포(X0의 분포)를 α로 두자. 이때, Xn의 분포는 아래와 같이 구할 수 있다.
P(Xn=j)=i∑P(Xn=j,X0=i)
=i∑P(Xn=j∣X0=i)P(X0=i)
=i∑Pijnαi
=(αPn)j
즉, Xn이 상태 j를 가질 확률이 αPn의 j번째 열에 나타나므로 Xn의 분포 = αPn이다.
ex) weather
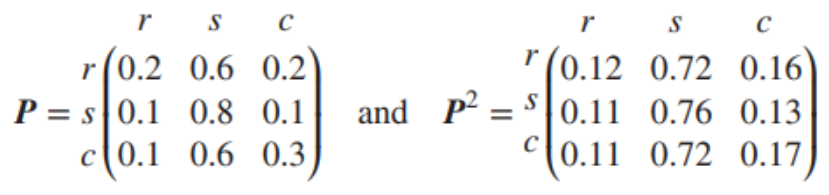
Q : 오늘 비가 왔을 때 이틀 뒤의 날씨 분포
A: 오늘 비가 왔으므로 X0=r이라고 둘 수 있다. 이틀 뒤의 날씨는 P2의 1번째 행(r)을 통해 확인할 수 있다. 오늘 비가 왔을 때 이틀 뒤 비(r)가 올 확률은 0.12, 눈(s)이 올 확률은 0.72, 구름(c)이 낄 확률은 0.16이다.
5. Markov Property
Markov chain의 기본 성질인 이전 시점에만 영향을 받고, 그 전과는 독립이라는 성질을 확장하면 다음과 같이 나타낼 수 있다.
Let X0,X1,… be a Markov chain. Then for all m<n,
P(Xn+1=j∣X0=i0,…,Xn−m−1=in−m−1,Xn−m=i)
=P(Xn+1=j∣Xn−m=i)
=P(Xm+1=j∣X0=i)
=Pijm+1
Xn+1을 예측할 때, 값을 알고 있는 가장 최근의 과거가 n−m번째 전이가 일어난 상황이라면 (즉, Xn−m=i 임을 알고 있음) Xn+1=j일 확률은 n-m 이전의 상황은 고려하지 않고, Xn−m에만 의존하여 Pijm+1이 전이행렬이 된다.
Reference
Dobrow, Robert P. Introduction to Stochastic Processes with R. 1st ed. Wiley, 2016.
이미지 출처: University of Oxford, Mathematical Institute. 사용 목적: 비영리·교육적 목적