LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
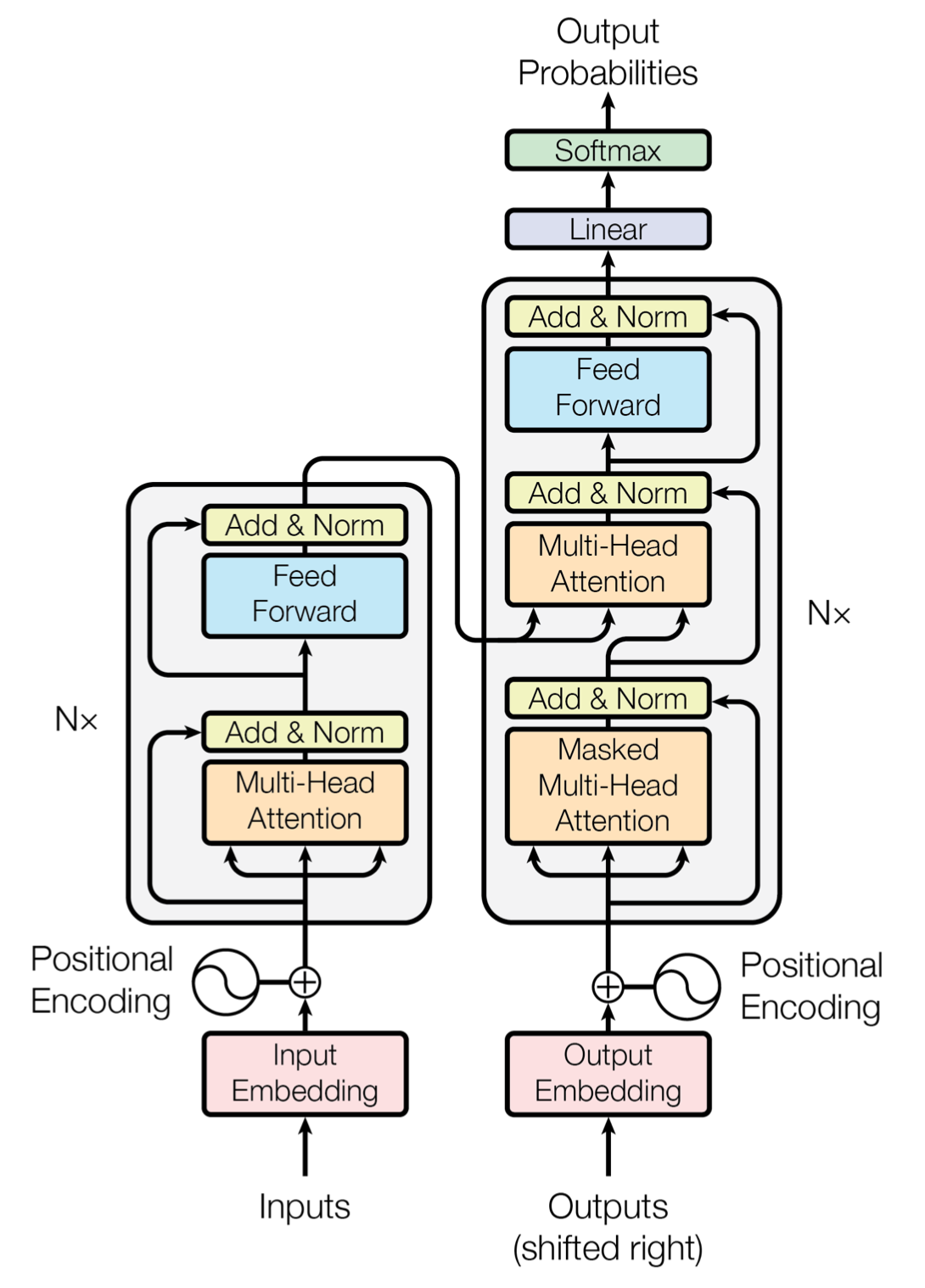
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Summary
디코더 전용 LLM을 텍스트 인코더로 변환하는 비지도 학습 방법 LLM2Vec
LLM2Vec;
a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder
three steps
1) Enabling Bidirectional Attention
2) Masked Next Token Prediction
3) Unsupervised Contrastive Learning
- word-level task에서 encoder-only model의 성능 능가
- MTEB(Massive Text Embeddings Benchmark)에서 비지도 학습 sota 달성
- supervised contrastive learning과 결합하면, publicly available data로 train시키는 모델들 중 MTEB sota
- LLM -> transform into universal text encoders in a parameter-efficient manner
- without the need for expensive adaptation or synthtic GPT-4 generated data
Background
Encoder & Decoder
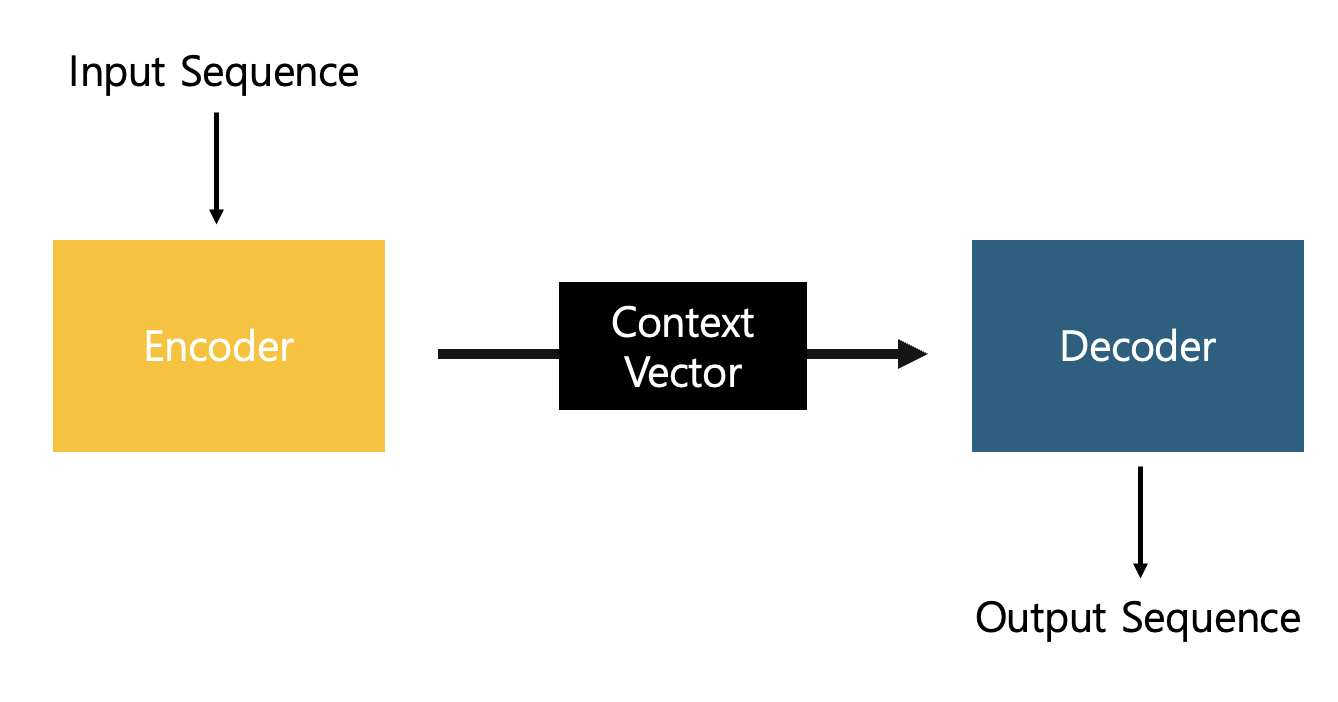
Encoder: Input sequence를 Vector로 압축[Embedding]하는 모듈 => Context Vector
Decoder: Context Vector로 Predction => Output Sequence
Traditional Language Model은 여러 단어가 입력으로 들어오면 다음 단어를 예측하도록 학습하는 단방향 모델이다. (left to right)
Bidirectional Language Model은 여러 단어가 입력으로 들어오고 그 중에 가려진 단어(masked token)를 예측하도록 학습하는 양방향 모델이다. 양방향으로 상관관계를 추출할 수 있어 문맥에 맞는 단어 예측이 가능하다.
Attention은 Decoder가 각 토큰을 예측할 때, 하나의 전체 context vector를 참고하던 기존과는 달리 각 토큰별로 어느 부분에 더 집중해야 하는지 알려주는 메커니즘이다. 단어의 대응관계를 나타내는 정보를 활용해서, 예를 들면 한국어로 '사과'라는 단어를 처리할때 'apple'이라는 단어에 더 집중할 수 있게 한다.
그중 Self-attention은 입력 시퀀스의 각 요소 간의 상대적인 중요성을 계산하여 요소 간의 관계를 모델링한다. 관계성 연산 결과를 바탕으로 연관성이 높은 단어들끼리 연결해주는 것이다.

Causal attention은 self-attention의 일종으로, 현재 위치의 이전 단어에만 유사도를 할당하며(이후의 단어는 보지 않는다) 이는 마스킹(masking)을 통해 구현될 수 있다. i번째 token은 0 ~ i-1 번째의 token에만 영향을 받도록 하는 것이다. 이를 통해 input sequence와 가장 관련있는 정보만 추출해내고자 한다.
그렇다면 decoder-only 모델에서는 왜 causal attention을 쓰는가?
auto-regressive모델은 현재 시점에서 이전 시점의 출력만을 활용해 다음 출력을 예측한다. 이는 과거 정보만을 활용하는 causal attention의 핵심 아이디어와 일치한다.
WHAT IS LLM
대형언어모델(LLM)은 NLP 작업을 수행하기 위한 딥러닝 알고리즘이다.
엄청난 수의 파라미터를 학습한다고 해서 'Large'라고 부르고, 기준은 없으나 일반적으로 GPT-3이 학습한 1,750억개의 파라미터 수 정도로 본다.
LLM 모델로는 GPT, BERT, LLaMA 등이 있다.
Encoder-only?
대표적인 encoder-only 모델로 BERT가 있다. 오직 임베딩만을 위한 모델인 것
따라서 직접적인 결과를 생성해내지는 않는다.
Decoder-only?
먼저 decoder의 중요한 특징 두 가지는, 한 번에 하나의 token을 예측한다는 점(문장 전체를 한 번에 예측하지 않는다.)과, 한 토큰의 예측 결과를 다시 다음 토큰을 예측하는 데에 input으로 사용한다는 점이다. 두 번째 특성을 auto-regressive이라고 한다. 출력되는 결과가 없는 encoder-only 모델과는 달리, decoder-only 모델은 생성에 있어 무한한 가능성이 있다.
encoder-decoder 모델이 하는 일을 생각해보면, Input sequence -> Output sequence 변환 작업이었다. 예를 들면 한국어 문장을 독일어 문장으로 번역하는 작업이 있다. 하지만 이런 문장-문장 변환이 아니라, 문장 생성 자체에만 관심이 있다면 Encoder에서 input sequence를 압축해서 만들어내는 context vector가 필요없다. 이 경우 Decoder-only model을 사용하게 되는데, 예를 들어 GPT를 보면 답안 전체가 바로 표시되는게 아니라 하나의 토큰이 순차적으로 표시되고(특성 1), 문장을 변환하는게 아닌(특성 2) 질문에 대한 답안을 제시한다.
모든 LLM 모델이 decoder-only 모델인 것은 아니지만, 최근 큰 관심을 받고 있는 GPT, LLama가 decoder-only 모델이다.
What is LoRA
사전 학습된 대규모 언어 모델의 가중치 행렬을 구성하는 모든 가중치를 미세 조정하는 대신, 이 큰 행렬을 근사화하는 두 개의 작은 행렬을 미세 조정하는 개선된 미세 조정 방식입니다. 이러한 행렬이 LoRA 어댑터를 구성합니다. 이렇게 미세 조정된 어댑터는 사전 학습된 모델에 로드되어 추론에 사용됩니다.
What is Contrastive Learning
Contrastive learning의 핵심 아이디어는 비슷한 샘플이 모델 내에서 서로 가깝게 임베딩되고, 다른 샘플과는 멀리 임베딩되도록 학습하는 것입니다. 이를 통해 모델은 데이터 포인트 간의 유사성을 파악하고, 이를 바탕으로 분류 또는 군집과 같은 작업을 수행할 수 있습니다.
Contrastive learning의 목표는 유사한 샘플 간의 거리를 최소화하고, 다른 샘플 간의 거리를 최대화하는 임베딩 공간을 학습하는 것입니다. 이를 위해 일반적으로 모델은 유사도를 측정하는 함수를 사용하여 샘플 간의 거리를 정의하고, 이 거리를 최적화하는 방향으로 학습됩니다.
1. Introduction
- Text embedding model은 자연어의 의미적 content를 vector representation으로 encode한다. weakly/fully-supervised contrastive training(지도학습)으로 train되었다. BERT, T5와 같은 모델이 지배적
- 최근에서야 decoder-only 모델을 도입하기 시작했다. 도입이 느렸던 이유는 이것의 causal attention mechanism 때문일 것으로 추정. causal attention은 token interaction을 제한해 풍부한 맥락에서의 representation이 어렵다. 이는 생성 기능에 필요한 제한이지만, 전체 input sequence에서 정보를 얻기는 어려워 text embedding에는 적합하지 않다.
Decoder-only model의 장점
- pre-training에서 일부가 아닌 모든 input token을 학습한다.
- 이는 encoder-only model보다 sample-efficient하게 함
- rich ecosystem
- extensive tooling & well tested recipes - continuous improvement by the community
- instuction fine-tuning and learning 에 탁월한 decoder-only LLM 개발됨
- universal text embedding models에 적합
- instruction을 사용하는 다양한 task에 general하게 쓰임
We provide a simple unsupervised approach, termed LLM2Vec, which can be used to transform any pre-trained decoder-only LLM into a (universal) text encoder.
2. LLM2Vec
2.1 Three simple ingredients
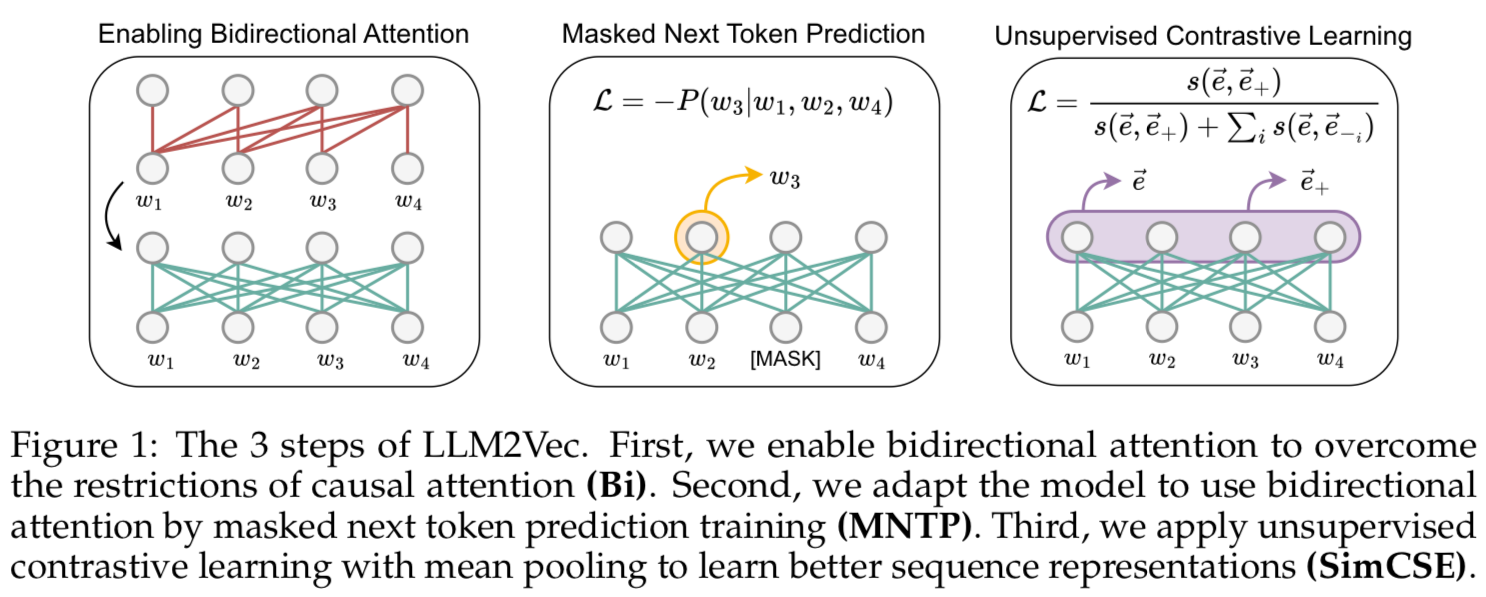
1. Enabling Bidirectional Attention (Bi)
- replace the causal attention mask of decoder-only LLMs by an all-ones matrix
- This gives each token access to every other token in the sequence, converting it into a bidirectional LLM
However, it is not a priori clear why this should lead to better sequence representations.
더 안 좋은 결과를 낼 수도 있지만 어쨌든 모델이 bidirectional attention을 사용할 수 있도록 바꾸는 방법은 간단하다는 취지의 말
2. Masked Next Token Prediction (MNTP)
- bidirectional attention을 사용하도록 바꿨다는걸 모델이 인지할 수 있도록, masked next token prediction(MNTP)을 통해 적응시킨다.
- MNTP란, next token prediction과 masked language modeling을 결합한 기술이다.
- Masked Language Modeling(MLM)은, 먼저 주어진 문장에서 특정 단어/토큰을 가린 후 전후 맥락에 맞게 가려진 단어/토큰을 예측할 수 있도록 학습시킨다. MNTP는 그 중에서도 다음 토큰을 예측하는 기술이다.
- 위치 i에 있는 masked token을 예측할 때에는 그 토큰 자체의 위치가 아니라 i-1번째 토큰에서 얻은 logit을 바탕으로 loss를 계산한다.
3. Unsupervised Contrastive Learning (SimCSE)
-
위의 두 방법은 word-level task를 위한 encoder로 변환시킬 수는 있지만, sequence representation에는 충분하지 않을 수 있다.
-
context of entire sequence를 capture할 수 있게 훈련되지 않았다.
-
To fill this gap, we apply unsupervised contrastive learning via SimCSE.
-
입력 시퀀스가 주어지면 독립적으로 샘플링된 dropout mask를 사용하여 모델을 두 번 통과시켜 동일한 시퀀스에 대해 두 가지 다른 표현을 생성한다.
-
모델은 이 두 표현 간의 유사성을 최대화하는 동시에 배치의 다른 시퀀스 표현과의 유사성을 최소화하도록 훈련된다.
-
이 단계에는 paired 데이터가 필요하지 않으며 어떤 시퀀스 콜렉션이면 다 적용 가능하다.
-
token representation에 pooling작업을 사용하여 sequence representation을 얻는다.
=> Bi + MNTP + SimCSE 결합해서 LLM2Vec recipe 구성
2.2 Transforming decoder-only LLMs with LLM2Vec
Models (1.3B-7B parameters)
Sheared-LLaMA-1.3B, Llama-2-7B-chat, Mistral-7B-Instruct-v0.2
Training data
MNTP와 SimCSE를 모두 English Wikipedia로 학습.
- 실험하는 모든 모델의 사전 학습물에 포함되어 있었음
- 따라서 이 두 단계에서는, 미래의 token에 주목하는 방법과 sequence representation을 구성하는 방법 외에 새로운 지식을 모델에 가르치지 않는다고 가정할 수 있다.
Masked next token prediction
: masked tokens의 percentage 실험: 20%, 40%, 60%, 80%, 90% - 이중 best setup
S-LLaMA-1.3B, LLaMA-2-7B : 20%, Mistral-7B : 80%
1000 steps with LoRA (r=16, α =32), batch size 32
brain floating point(bfloat16) quantization
FlashAttention-2
gradient checkpointing
80GB A100 GPU 하나로 학습 : 90분
Unsupervised contrastive learning
동일 input sequence에 dropout(0.3) 2번 적용해서 positive example, 같은 배치의 다른 시퀀스들은 negative
LoRA로 fine-tuning: 2.5 hours with batch size of 128
Evaluation
word-level tasks
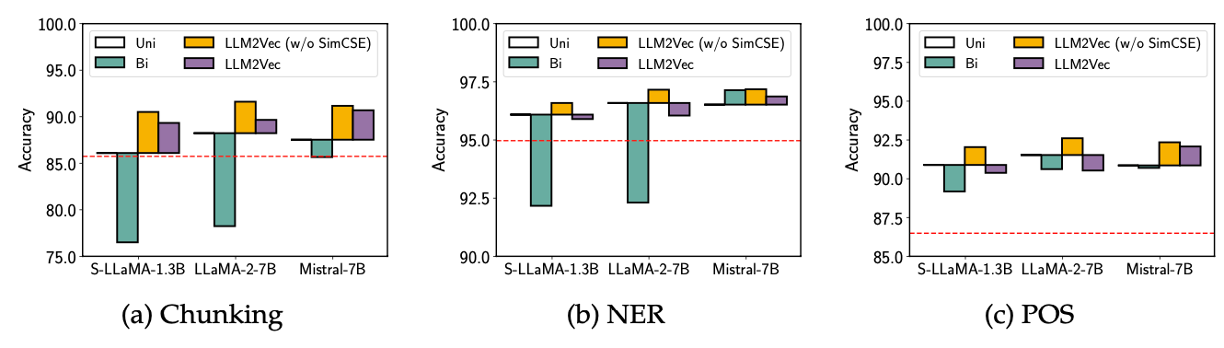
Causal Attention으로도 이미 성능이 encoder-only 모델보다 높다
학습데이터가 더 많기 때문
Bi 만 적용했을 경우 대부분의 경우 성능이 크게 저하
Mistral-7B만 훨씬 덜 저하된다.
Mistral 모델은 사전 학습 과정에서 일부 Bidirectional attention과 관련된 기법을 사용했기 때문
sequence-level tasks
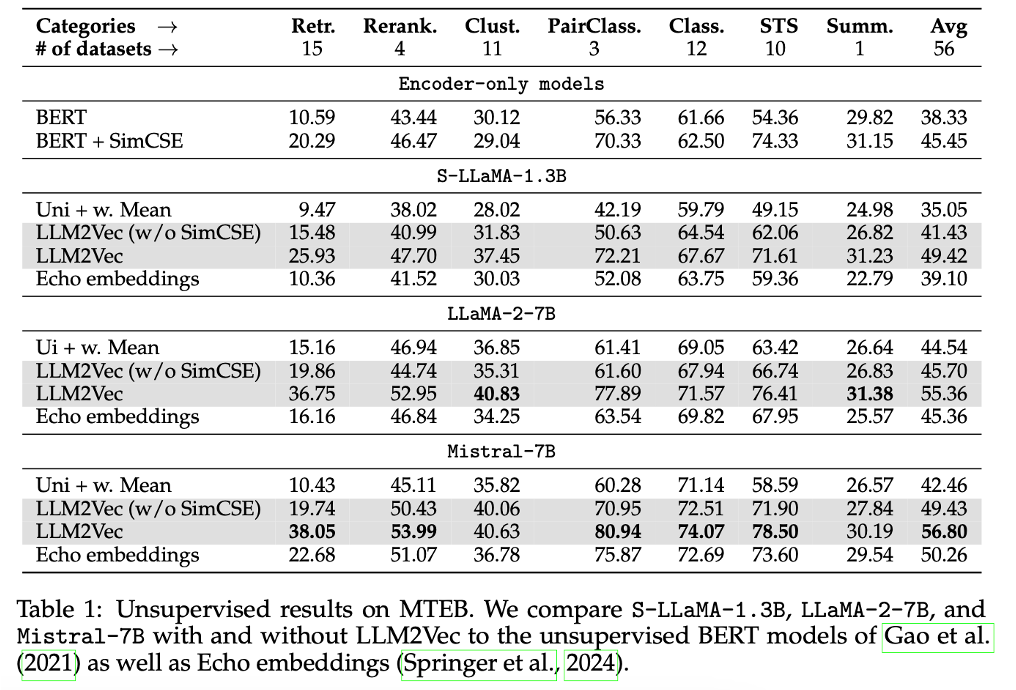
MTEB (Massive Text Embedding Benchmark)
• LLM 자체는 낮은 성능
• Bi -> Mistral-7B 만 향상
• SimCSE -> 49.8%, 23.2%, 37.5% 향상
• Mistral-7B : 최고점 : 56.8
Conclusion
a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder
- Enabling Bidirectional Attention (Bi)
- Masked Next Token Prediction (MNTP)
- Unsupervised Contrastive Learning (SimCSE)
Mistral-7B 모델이 MTEB 벤치마크에서 9위 (비지도학습 기준 sota)
simple + computational efficiency
