StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
논문 1~2번 정리
Abstract
Image-to-Image Translation
existing approaches
- different models should be built independently for every pair of image domains
- -> limited scalability and robustness in handling more than two domains
StarGAN: a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model
- allows simultaneous training of multiple datasets with different domains within a single network
- superior quality of translated images compared to existing models
- novel capability of flexibly translating an input image to any desired target domain
- facial attribute transfer and a facial expression synthesis tasks
정리하자면, 이 논문에서는 image-to-imgae translation task를 다루고 있다. 원래는 두 개 이상의 도메인에서 이 태스크를 수행하려면 독립적인 모델을 도메인별로 각각 돌려야 해서 확장성과 안정성이 떨어졌다. 이를 해결하기 위해 StarGAN이 제안되었고, 이는 여러 도메인에서도 하나의 모델로 태스크를 수행할 수 있으며 퀄리티도 좋다.
1. Introduction
1. image-to-image translation이란?

The task of image-to-image translation is to change a particular aspect of a given image to another, e.g., changing the facial expression of a person from smiling to frowning
위의 그림을 보면, input 이미지에 있는 인물은 동일하지만 헤어스타일, 성별 또는 표정(감정) 등이 다르게 표현되고 있다. 논문에서는 이 태스크를 이미지의 특정한 feature(: attribute)를 바꾸는 작업으로 설명한다.
-
GAN이 이 태스크를 엄청나게 발전시킴(헤어스타일, 배경의 계절 등)
-
attribute: meaningful feature inherent in an image
- ex. hair color, gender or age
-
attribute value: particular value of an attribute
- ex. black/blond/brown for hair color
2. domain이란?
We further denote domain as a set of images sharing the same attribute value. For example, images of women can represent one domain while those of men represent another.
다양한 labeled attributes를 가진 이미지셋
- TASK: multi-domain image-to-image translation, where we change images according to attributes from multiple domains
- 같은 attribute를 공유하는 이미지셋을 도메인이라고 한다. 따라서 여러 도메인의 이미지라는 것은 위의 그림에서 각 열의 이미지셋을 의미할 것이다.
- blond hair/gender/aged/pale skin 4개의 도메인으로 이미지가 translate되는 것을 확인할 수 있다.
- 다른 데이터셋의 여러 도메인을 학습하는 것으로 확장시킬 수 있다.
- A 데이터셋을 훈련시킨 모델로 B 데이터셋의 이미지의 표정을 바꿀 수 있음
3. 기존의 문제점은?
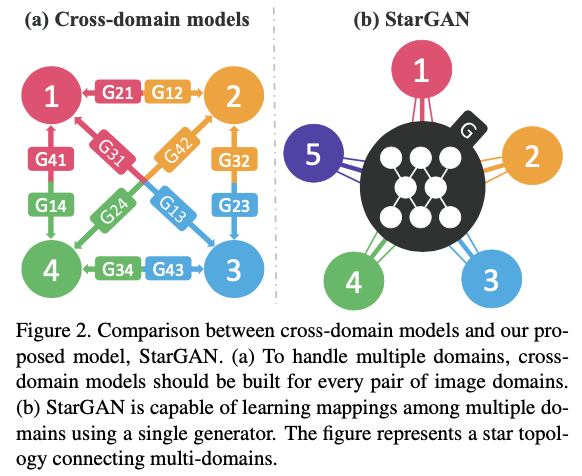
- However, existing models are both inefficient and ineffective in such multi-domain image translation tasks.
- in order to learn all mappings among k domains, k(k−1) generators have to be trained.
- global features가 있는데도 불구하고, 전체 학습데이터를 충분히 활용하지 못함.
- k개의 도메인이 있으면 그중 두 개씩 학습해야 하는 비효율성
- limit the quality of generated images
- 또한 각 데이터셋이 partially label되어있기 때문에, 결합적으로(jointly) 학습하는 것이 불가능. >> Section 3.2.
-> Solution: StarGAN
여러 도메인의 데이터를 하나의 generator만으로 학습가능하다.
- 기존과 달리, fixed translation(e.g., black-to-blond hair)으로 학습하지 않는다.
- input으로 image and domain information를 동시에 받음으로써 도메인을 유연하게 변경할 수 있도록 한다.
- domain information으로는 label(e.g., binary or one-hot vector)을 사용한다.
- target domain label을 random하게 생성해서 input -> target domain translation을 훈련시킨다.
- 어떤 도메인이든 자유롭게 바꿀 수 있게 함
- joint training between domains of different datasets by adding a mask vector to the domain label.
- the model can ignore unknown labels and focus on the label provided by a particular dataset.
Overall, our contributions are as follows:
• We propose StarGAN, a novel generative adversarial network that learns the mappings among multiple do- mains using only a single generator and a discriminator, training effectively from images of all domains.
• We demonstrate how we can successfully learn multidomain image translation between multiple datasets by utilizing a mask vector method that enables StarGAN to control all available domain labels.
• We provide both qualitative and quantitative results on facial attribute transfer and facial expression synthesis tasks using StarGAN, showing its superiority over baseline models.
2. Related Work
Generative Adversarial Networks
- GAN과 유사하게 adversarial loss 활용.
- 이미지 생성을 더 현실적으로 하기 위함
Conditional GANs
- conditional domain information 제공해서 조건부로 학습시킴
Image-to-Image Translation
StarGAN까지의 발전 과정이라고 생각하면 될듯
- pix2pix
- 어떤 이미지를 condition으로 주고 그에 따른 translation - cGAN
- adversarial loss + L1 loss
- thus requires paired data samples [지도학습]
=> unpaired image-to-image translation frameworks
- CycleGAN
- UNIT combines variational autoencoders (VAEs) with CoGAN
- two generators share weights to learn the joint distribution of images in cross domains.
- CycleGAN and DiscoGAN preserve key attributes between the input and the translated image by utilizing a cycle consistency loss
CycleGAN: 변환된 이미지가 원래의 이미지로 돌아올 수 있도록 제한을 준다. 두개의 generator
한 번에 도메인 두 개씩 학습 가능. 멀티도메인에 확장성이 낮다.(너무 많은 쌍의 도메인이 학습되어야 함)
=> StarGAN: 하나의 모델로 여러 도메인 간의 관계를 학습한다.
