Magma: A Foundation Model for Multimodal AI Agents
Magma: A Foundation Model for Multimodal AI Agents
- 2025.02.18
- CVPR 2025
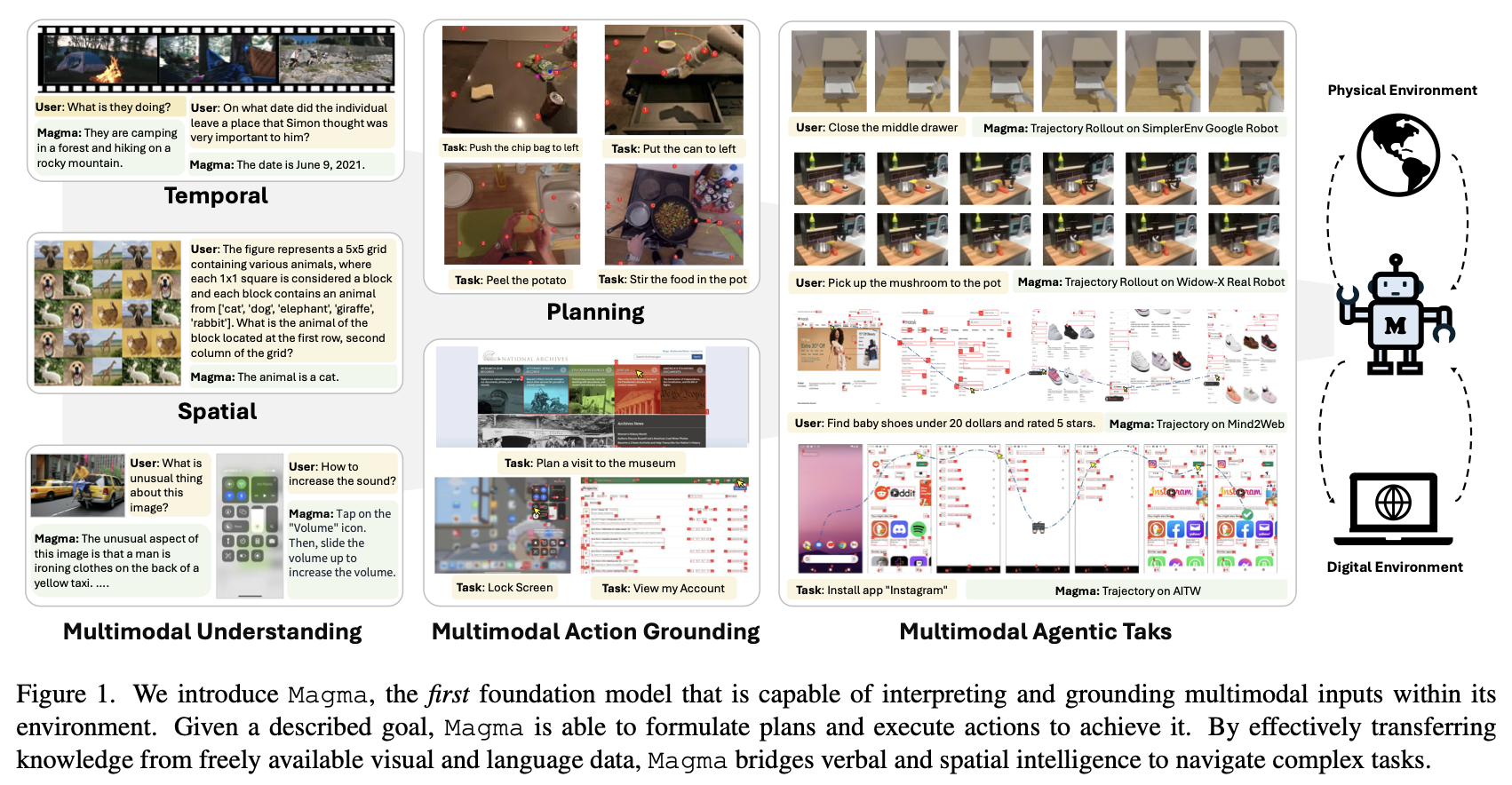
multimodal AI agent의 첫 foundation model이다.
디지털, 물리 세계의 다양한 작업을 수행하기 위한 언어적, 공간적, 시간적 지능을 연결한다.
abstract
- 디지털+물리 환경에서 ‘계획하고 행동할 수 있는’ 멀티모달 AI 모델
- verbal intelligence + spatial-temporal intelligence
- 기존 VL 모델의 이해 능력(언어적 지능)을 유지 + 시공간적 세계에서 계획을 세우고 행동할 수 있는 능력(공간-시간 지능)을 갖추고 있다!
- 사용자 인터페이스(UI) 탐색, 로봇 조작 등 다양한 에이전트 작업 수행 가능
- 이를 위해 이미지, 비디오, 로보틱스 데이터 등 다양한 '이질적인' 데이터셋으로 사전학습
- ⭐️ 이미지에 포함된 조작 가능한 시각 객체들(예: GUI 상의 클릭 가능한 버튼)은 Set-of-Mark (SoM) 으로 라벨링되어 행동 연결(action grounding)이 가능하고,
- ⭐️ 비디오 속 객체의 움직임(예: 사람 손이나 로봇 팔의 경로)은 Trace-of-Mark (ToM) 으로 라벨링되어 행동 계획(action planning)이 가능하다.
- 멀티모달 성능 좋다. 특히, UI 탐색 및 로봇 조작 작업에서 sota 달성
- 모델 및 코드 공개됨
introduction
Motivation
- 자율 에이전트(: 시각/언어/환경 데이터를 가지고 의미있는 실체적 행동을 구현하는)를 개발하는건 오랜 과제
- 최근 VLA(Vision-Language-Action) 모델 기반의 AI 에이전트가 대두
- 이러한 모델들은 일반적으로 대규모 비전-언어 데이터셋과, 이후에는 행동 궤적(action trajectory) 데이터로 사전학습
- 그러나 디지털(2D)과 물리(3D) 세계 간의 본질적인 차이로 인해 VLA 모델은 일반적으로 각각 따로 학습되며, 서로 다른 작업에 별도로 사용된다.
- 디지털 VLA 모델
- UI 네비게이션을 위한 Pix2ACT, WebGUM, Ferret-UI 등
- 물리 VLA 모델
- 로봇 조작을 위한 RT-2, OpenVLA 등
- 위의 모델들은 작업 특화된 행동 정책 학습을 우선시, 멀티모달 이해 능력은 낮다
논문의 핵심
➡️ 본 연구에서는 multimodal ai agent를 위한 foundation model을 개발하고자 한다.
이를 위해 다음 두 가지 능력이 동시에 필요하다.
1. Multimodal Understanding
디지털+물리 환경 모두에서 다양한 도메인의 멀티모달 입력을 의미론적, 공간적, 시간적으로 이해할 수 있는 능력
2. Multimodal Action Prediction
장기적인 작업을 정확한 행동 시퀀스로 분해하여, AI agent가 효과적으로 실행할 수 있는 능력

- 범용 능력의 학습을 위해 UI 데이터셋(SeekClick), 로봇 조작 데이터셋(OXE), 인간 행동 비디오(Ego-4d), 그리고 이미지-텍스트 쌍 데이터셋(LMMs; 대규모 멀티모달 모델)를 사용
- 기존처럼 한 도메인에서 학습하고 다른 도메인으로 전이하는 방식이 아니라, 하나의 통합 파운데이션 모델을 훈련시켜 제로샷 방식으로 다양한 다운스트림 작업에 적용할 수 있도록 함
- 데이터셋을 단순히 결합하는 걸로는 효과가 없다.
- 데이터셋 간의 본질적인 차이가 있기 때문(텍스트/공간적 좌표 기반 등)
➡️ 이 차이를 연결하기 위해, 모델 학습을 위한 두 가지 surrogate task(대체 과제)를 제안한다.
1. 행동 연결(Action grounding)
이미지에서는 조작 가능한 시각 객체를 Set-of-Mark(SoM)으로 라벨링(ex. 클릭 가능한 버튼)
2. 행동 계획(Action planning)
비디오에서는 객체의 움직임을 Trace-of-Mark(ToM)으로 라벨링(ex. 사람 손의 이동 경로)
이를 통해 원래 행동 라벨이 없는 이미지와 비디오 데이터를 VLA 데이터로 변환, 다양한 작업 간의 격차를 줄일 수 있다. SoM과 ToM은 환경에 독립적이며 새로운 에이전트 작업으로 일반화되기 쉬워서, 학습 확장에 효과적임을 입증했다.

왼쪽: 다양한 멀티모달 입력을 이해
가운데: 향후 행동 계획 및 연결을 수행
오른쪽: 디지털+물리 환경의 (unseen) 에이전트 작업에 적응할 수 있다.
평가
세 가지 작업 카테고리에서 평가했다.
- UI navigation (Mind2Web, AITW)
- UI 행동; reason and act in evolving digital environments
- vision-language understanding (GQA, VideoMME)
- 언어적 이해; grounds language in visual objects and events
- robotic manipulation (Bridge, LIBERO)
- 물리적 상호작용; tests its 3D spatial intelligence for physical interaction
➡️ UI navigation, robotic manipulation에서 sota, VL 작업에서도 기존 LMM들과 유사한 성능
method
Set-of-Mark for Action Grounding

- SoM prompting은 GPT-4V에서 처음 제안되었음
- 기존처럼 prompt로 쓰는게 아니라 train에 사용한다.
locating actionable points, regions for a specific task, further predict atomic actions(if needed)
단순하게 표현하면
여기서 은 timestep마다 atomic 행동
ex. : "click" (verbal)
: (x,y)로 이동 (spatial)
: "type" (verbal)
: "1234" (verbal)
...
단계
1. 3가지 input
- 시각 입력 와 작업 지시 , 문맥 를 입력으로 받음
- 이때 입력은
- 높이 H, 너비 W, 3채널(RGB)
- 먼저 2가지를 추출
- 후보 영역(candidate regions) , 조작 가능한 위치(actionable points)
- 는 4차원 박스 좌표 또는 2차원 점 좌표
- 위치마다 숫자 마크 부여:
- 새로운 마크가 덧입혀진 이미지 를 생성한다.
- 마크가 포함된 이미지 을 모델에 입력 -> 해당 마크 선택 및 행동 예측
이를 통해 행동 연결이 단순화되며, UI든 로봇이든 공통된 포맷으로 표현 가능하다는 장점이 있다.
수식은 다음과 같이 재구성될 수 있다.
는 마크 의 subset이다.
🚨 기존 방식과 다른 점
기존 모델은 이 개념을 암묵적으로 사용하거나 도메인별로 따로 처리함.
Magma는 이를 명시적으로 일반화하고 모든 멀티모달 작업에 통합해서 학습이 가능하도록 함.
Trace-of-Mark for Action Planning
비디오 데이터는 많은 정보를 담고 있지만 행동 라벨(action label)이 존재하지 않기 때문에, 이전 연구들은 이 방향을 거의 탐색하지 않았다.

- "overlaying marks" 전략, 즉 마크를 덧씌우는(위의 같이) 전략을, ToM을 통해 정적인 이미지에서 동적인 비디오로 확장한다.
⭐️ 자동추적: 원래 있는 기능이었는데 magma에서 처음으로 ai agent에 도입
- 비디오에서 visual observation sequence 가 주어졌을 때, 연구진은 시간 축을 따라 미래 개의 프레임, 으로 확장한다.
- 현재 시점 의 프레임 에서 개의 마크가 주어졌다고 할 때, 미래 프레임들에서 해당 마크들의 위치를 추적해서 얻는 경로를 로 나타낸다.
- remind:
- SoM에서 행동 유형()과 유효한 마크()를 예측한 것에서 나아가, 해당 마크의 미래 이동 경로()까지 예측해야 한다.
여기서 는 해당 마크()의 유효한 움직임 경로이며, 에서 선택된 하위 집합이다.
이를 통해 모델이 시간적인 흐름을 이해하고, 다음 행동을 취하기 전에 앞을 내다볼 수 있도록 강제한다. 또, 프레임을 직접 예측하는 방식과 달리, trace를 예측하면 훨씬 적은 토큰만으로 더 긴 시간축과 관련된 객체의 움직임을 효율적으로 표현할 수 있다.
- ToM을 추출하기 위해 논문은 CoTracker와 같은 포인트 추적 모델을 사용한다.
추적 과정
1. 비디오 프레임 인풋
프레임 시퀀스
높이 H, 너비 W, RGB 3채널 프레임이 개 있는 것.
2. 격자 점들을 찍는다. 총 개의 점을 찍는 것
그 점을 기반으로 움직이는 애들이 어디있는지 본다
3. dense tracking
각 점에 dense tracking을 적용하여 각 점이 프레임 간 어떻게 이동하는 추적한다.
예를 들어 첫 번째 점이 이렇게 움직이는 걸 하나하나 따라가다 보면 하나의 trace가 완성된다.
trace:
4. 각 점마다 trace 하나씩 생성하니 길이가 인 개의 trace를 추출한다.
5. filtering
이후, 인접 프레임 사이에서 평균 이동 거리가 특정 임계값 보다 작은 trace들은 제거한다.
즉 벽, 책상 등 정지된 배경으로 간주한다.
6. 남은 trace들은 작업에 의해 유도된 foreground 동작!
얘를 ToM으로 써서, 모델에게 "행동의 결과"로서 훈련시킨다.
pre-training

video data 엄청 많음
data source: instructional videos, robotics manipulation, UI navigation, and multimodal understanding
- SoM: 모든 모달에 적용
- ToM: video, robotics에만 적용
