Inference-Time Scaling for Generalist Reward Modeling
Inference-Time Scaling for Generalist Reward Modeling
2025.04.05
✅ Background
❓ 먼저, inference-time scalability란?
학습이 끝난 모델을 실제 사용할 때, / 더 많은 연산 자원을 쏟아서 / 성능을 더 끌어올릴 수 있는가한 번 예측하고 끝이 아니라, 이미 학습된 모델을 더 잘 쓰는 방법을 찾는 것이다.
- principle & critique?
- 강화학습에서 principle이란, 어떤 행동이 좋은지 나쁜지를 평가하는 기준. 예를 들어, 어떤 문장이 정중한가를 평가하려면 "정중함"이라는 원칙이 먼저 있어야 한다.
- critique란, 위의 principle을 기준으로 평가하는걸 말한다.
- online RL?
agent가 환경과 상호작용하면서 얻은 데이터로 즉시 학습을 진행하는 방식
이 논문에서는 GRM이 SPCT(Self-Principled Critique Tuning)을 통해 학습하는 <원칙을 스스로 생성하고, 그에 따라 생성된 문장을 평가하고, 보상 모델을 점진적으로 개선하는> 일련의 과정을 실시간으로 하는 것.
abstract
- RL은 LLM의 사후 학습, 즉 post-training 단계에서 널리 사용되고 있다.
- ⭐️ RL을 통해 LLM의 reasoning 능력을 유도할 수 있다.
- 적절한 학습 방법이 inference-time scalability 를 가능하게 할 수 있다!
- RL은 검증 가능한 질문이나 인위적인 규칙을 넘어, 다양한 도메인에서 정확한 보상 신호를 얻는 것이 주요 과제
⭐️ 본 연구에서는 다음 두 가지 방법을 탐구한다:
1. general queries(일반적인 질문)에 대해 inference compute(더 많은 추론 연산)을 활용하여 Reward Modeling(보상 모델링)을 개선할 수 있는 방법
- 보상 모델링 접근법: Pointwise Generative Reward Modeling(포인트 방식 생성형 보상 모델링, GRM)
- 다양한 입력 유형에 유연하게 대응, inference-time 확장 가능성을 확보
2. 적절한 학습 방식을 통해 performance-compute scaling(성능 대비 연산량의 효율)을 향상시키는 방법
- 학습 방법: Self-Principled Critique Tuning(SPCT)
- GRM이 online RL을 통해 principle(원칙)을 자가 생성하고, critique(피드백)을 정확하게 생성하도록 하여 보상의 확장성 있는 생성 행동을 유도한다.
- 이 방식으로 학습된 모델을 DeepSeek-GRM 이라고 명명
- inference-time scaling을 위해, parallel sampling(병렬 샘플링)을 사용하여 연산 자원을 확대 활용
- 투표 과정에서 더 나은 성능을 이끌어내기 위해 meta RM을 도입
실험 결과
- SPCT는 GRM의 품질과 확장성을 크게 향상시킴
- 학습단계에서의 확장보다도 더 뛰어난 성능
- DeepSeek-GRM은 여전히 일부 과제에서는 어려움을 겪고 있으나, 향후 generalist reward systems 개발을 통해 해결될 수 있을 것으로 보인다.
introduction
LLM의 사후 학습으로 강화학습이 채택되며 개선이 이루어지는 분야:
- human value alignment
- long-term reasoning
- environment adaptation
이러한 RL 과정에서 핵심적인 구성 요소는 Reward Modeling이며, 이는 LLM의 응답에 대해 정확한 보상 신호를 생성하는 데 필수적이다.
지금까지는 다음 두 가지 조건 아래에서만 고품질의 보상을 생성해왔다.
1. 조건이 명확한, 사람이 설계한 시뮬레이션 환경
2. verifiable question(ex. 코딩, 수학)을 위한 수작업 규칙
일반적인 도메인에서는 보상의 기준이 다양하고 복잡하며, 정답이 명시적으로 주어지지 않는 경우가 많아서 보상 생성이 어렵다. 그래서 사후학습의 측면(ex. RL at scale)에서도, 추론 측면(ex. RM-guided search)에서도, generalist RM이 LLM을 더 넓은 응용 분야에 활용하기 위한 핵심이 된다.
RM 성능은 training compute과 inference compute 둘다 향상시키는 방향으로 개선되어야 한다.
그러면 RM의 성능을 높이기 위해서는?
1️⃣ 다양한 입력 타입에 대한 유연성
2️⃣ 다양한 도메인에서 정확한 보상 생성
3️⃣ 추론 연산량을 늘렸을 때 고품질 보상 생성 능력
4️⃣ 연산량 대비 성능 향상 효율
의 4가지 과제를 해결해야 한다.
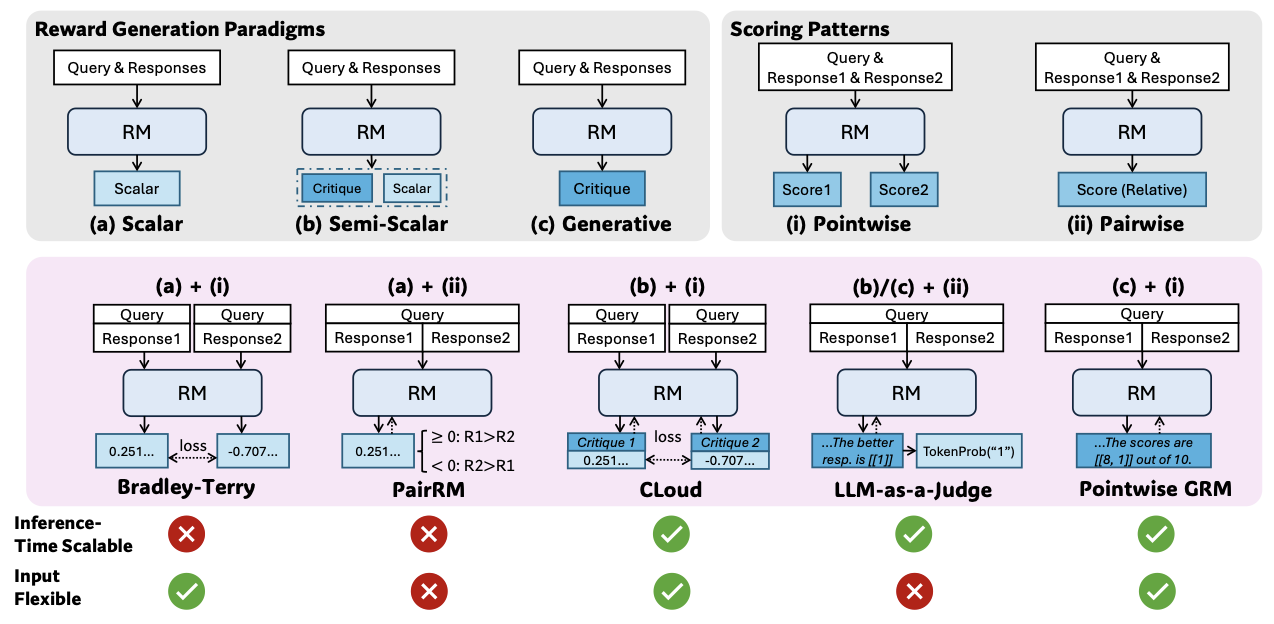
기존의 RM 연구는 다음과 같이 구분된다.
🎯 보상 출력 형태 기준
- scalar: 점수 하나
- semi-scalar: 점수+간단한 설명
- generative: 원칙+평가 등 자유 형태 문장 생성
🎯 입력 처리 방식 기준
- pointwise: 개별 응답에 대해 보상 판단
- pairwise: 응답 두 개를 비교해서 어느 쪽이 더 나은지 판단
👿 문제:
1. pairwise는 항상 비교할 응답 쌍이 필요해서 확장성이 떨어지고
2. scalar 방식은 같은 응답에 다양한 보상을 주기 힘들어서 다양성이 떨어짐
지금까지는 추론 시점의 확장성에 초점 x, 학습된 보상 생성 행동과 & RM의 추론 시 확장성 간의 연관성을 탐구하지 않아 성능 향상이 제한적이었음.
최근 DeepSeek-AI의 연구에서 적절한 학습 방법을 통해 효과적인 추론 시점 확장이 가능함을 알았고,
이 논문에서는
➡️ Can we design a learning method aiming to enable effective inference-time scaling for generalist reward modeling?
즉, 범용 보상 모델링[Generalist reward modeling]을 위해 효과적인 추론 시 확장을 가능하게 하는 학습 방법을 설계할 수 있을까?
라는 질문을 핵심으로 가져간다.
✅ 이 문제에 대해 논문에서 제안한 해결방법
1. pairwise는 항상 비교할 응답 쌍이 필요해서 확장성이 떨어지고:
Reward Model) Pointwise Generative Reward Modeling(GRM)
단일 응답, 다수 응답, 응답 쌍 등 다양한 입력을 모두 자연어 기반으로 처리한다.
principle과 critique를 모두 자연어로 생성함으로써 유연성과 품질을 확보한다.
: 과제 1️⃣ 해결
- scalar 방식은 같은 응답에 다양한 보상을 주기 힘들어서 다양성이 떨어짐:
보상 모델의 추론 시점 확장성은 같은 입력에 대해 여러 번 샘플링하여 다른 보상 결과를 얻을 수 있는지에 따라 결정된다. 예를 들어, scalar 방식을 사용하는 RM은 항상 같은 보상 값을 생성하기 때문에 확장성이 부족하다.
learning method) Self-Principled Critique Tuning(SPCT)
rule-based online RL을 활용하여 GRM이 스스로 principle을 생성하고, 응답에 대한 critique를 생성하여 보상 신호를 더 정교하게 생성할 수 있도록 학습시킨다.
: 과제 2️⃣ 해결
inference-time scaling) 다중 샘플링을 통해 연산량을 늘린다.
병렬로 샘플링하여 다양한 원칙과 이에 상응하는 비판을 생성하고, 최종 보상 결정을 위해 투표를 수행한다.
: 과제 3️⃣, 4️⃣ 해결
더 나은 scaling을 위해 투표 외에도 보상 모델 meta RM을 학습시킨다.
👾 이 논문에서 제안하는 모델: DeepSeek-GRM-27B
SPCT로 사후 학습된 모델이고, Gemma-2-27B를 기반으로 한다.
🏆 주요 기여:
- SPCT 접근법 제안, meta RM 도입 -> DeepSeek-GRM
- SPCT가 GRM의 inference-time scaling 유의미하게 향상시킴을 입증
- inference-time scaling이 training-time scaling보다 더 뛰어난 성능을 낼 수 있음을 발견
Self-Principled Critique Tuning
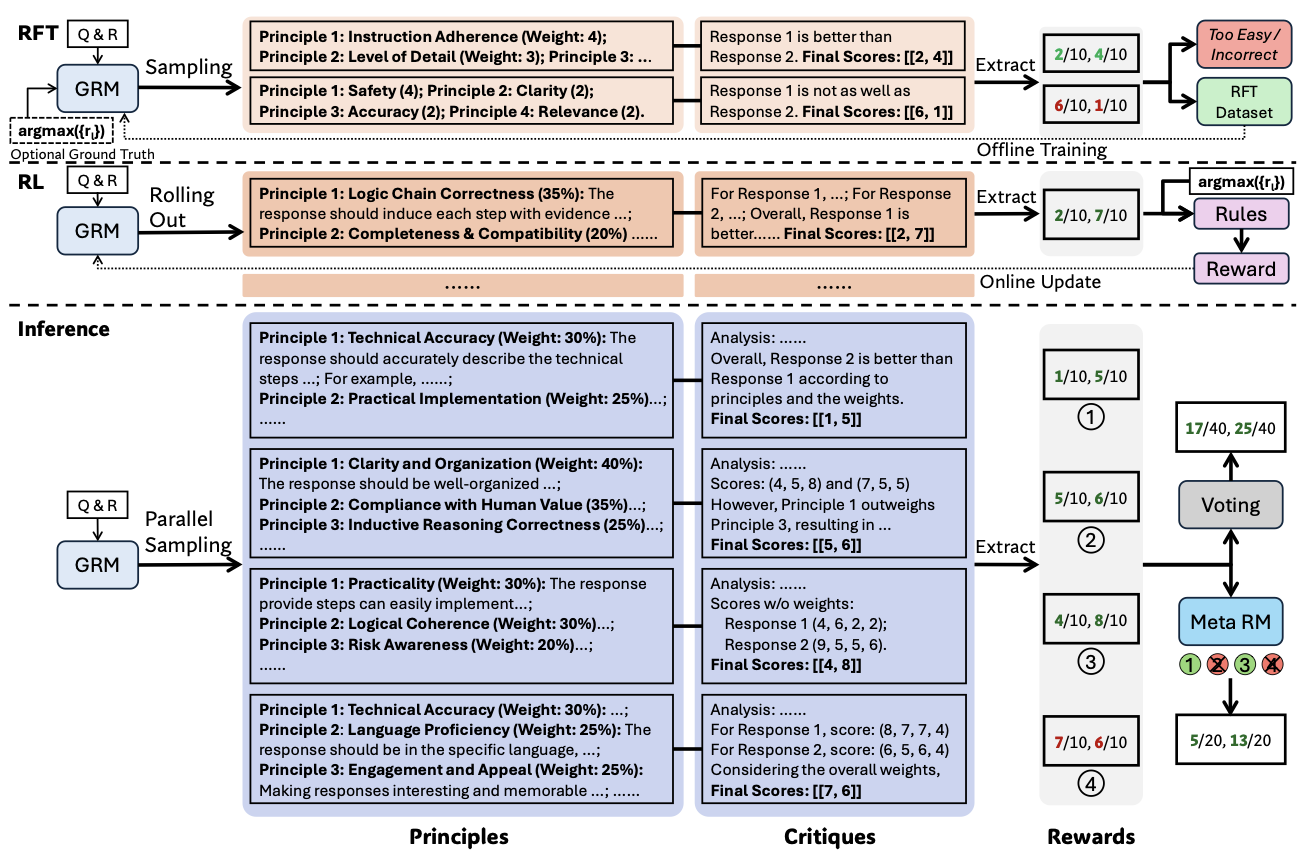
기존처럼 principle을 사전 정의하는게 아니라, 보상 생성의 일부로 포함시켜 직접 생성하는 방식을 제안한다. [원칙을 모델이 직접 생성]
원칙이 사전에 정의되어 있는 경우, 원칙은 보상 생성 과정을 다음 식처럼 유도한다.
흐름
1. 질의 x와 여러 개의 응답 가 주어짐
: 지도학습용 학습 데이터셋이 필요함
2. 원칙 생성: 모델 는 와 를 입력으로 받아 m개의 원칙 를 생성
3. 비판 및 보상 생성: 보상 모델 는 위에서 생성한 원칙들과 응답을 받아 critique C를 생성하고, 이를 통해 보상 R을 도출
: Query, : Principle Generator, : Reward Generator(GRM)
: Critique, : Reward
: n개의 responses, : m개의 principles(질의와 응답들을 기반으로 생성됨)
- 질의와 응답에 기반하여 원칙을 자동으로 생성하고, 이 원칙이 보상 생성 과정에서 adaptive align 되게 한다.
- adaptive alignment(적응적 정렬)이란 모델이 상황에 맞는 원칙을 만들어서, 그 기준으로 critique와 reward를 일관되게 만든다는 것이다.
- 원칙 생성 함수와 보상 생성 함수는 동일한 모델 구조를 공유한다.
- 같은 LLM 기반 구조를 사용한다는 뜻이다.
- 원칙 생성 함수는 x, y를 넣어서 원칙 p 생성 / 보상 생성 함수는 x, y, p 넣어서 r 생성
- 이를 통해 대규모로 원칙이 생성되어, 더 합리적인 기준과 세밀한 단위로 보상을 산출할 수 있게 된다.
SPCT는 두 단계로 구성된다.
1. Rejective Fine-Tuning => 거절 기반 파인튜닝
🧊 cold-start 방식(아무것도 학습되지 않은 상태에서 시작)
GRM이 다양한 입력 유형에 대해 올바른 형식의 원칙과 비판을 생성하도록 적응시키는 것이다. 기존 연구는 단일 응답/쌍/복수 응답을 서로 다른 형식으로 혼합하여 사용했지만, 본 논문에서는 pointwise GRM을 채택해 어떤 수의 응답이든 동일한 형식으로 보상을 유연하게 생성할 수 있도록 한다.
데이터
- 일반적인 instruction 데이터 외에도,
- 다양한 응답 개수를 가진 RM 데이터에서 질의와 응답을 주고, 사전학습된 GRM으로부터 trajectory를 샘플링
- 각 쿼리-응답 세트에 대해 횟수만큼 샘플링을 수행
거부 전략
- 예측된 보상이 ground truth 보상과 일치하지 않으면 trajectory를 거부
- 반대로 번의 샘플링에서 모두 정답일 경우에도 너무 쉬운 문제로 간주해 거부한다.
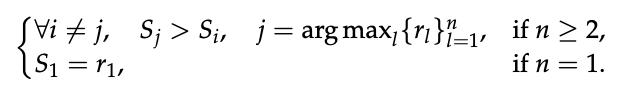
예측한 보상이 실제 정답 순위와 일치해야 "정답"으로 간주함.
- n>=2인 경우: 가장 높은 실제 보상을 가진 응답 j가 예측된 보상 에서도 가장 높아야 함
- n=1인 경우: 예측된 보상 이 실제 보상 과 일치해야 함
👿 문제점
기존 연구와 마찬가지로, 사전학습된 GRM이 제한된 샘플링 횟수 내에서 정확한 보상 예측을 어려워하는 경우가 많다는 것을 발견
✅ 보완
힌트를 포함한 샘플링(Hinted Sampling)을 제안
- SPCT의 cold start, 첫 번째 단계에서 사용된다. 힌트가 있는 샘플링과 없는 샘플링을 각각 따로 수행함.
- 쿼리-응답 세트에 대해 argmax(가장 높은 실제 보상)의 인덱스를 프롬프트에 추가
- 이 프롬프트를 기반으로 GRM이 올바른 보상을 예측하도록 유도
- 이때는 샘플 1회만 수행, 예측이 틀렸을 경우에만 trajectory를 거부
👿 힌트 포함 샘플링은 특히 reasoning 과제에서 critique를 단축/생략하는 경향이 있었고 이는 GRM에 대해 online RL이 필요함을 시사한다.
- 힌트를 줘서 원칙을 알려줘도 제대로 된 critique를 생성하지 못하고 간단한 문장으로 critique를 때우는 경향이 있기 때문(정답에만 맞추려고)
- 1번이라는 정답을 주면 제대로 된 추론을 안하고 1번이라서 좋다~ 이런 느낌
2. Rule-Based Online RL => 보상 생성 능력 강화
추가 파인튜닝 단계
GRPO(Generative Reward Policy Optimization) 설정을 그대로 따르며, rule-based outcome rewards를 사용한다.
rollout(수집) 단계에서 principle, critique를 생성했음
critique에서 예측된 보상 값을 추출하고, 이 보상을 ground truth reward와 accuracy rules를 통해 비교한다.
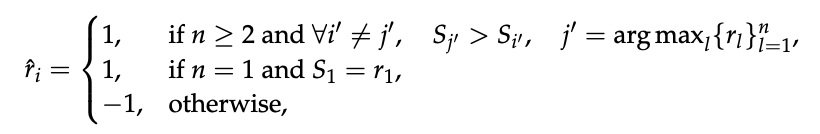
예측한 보상 분포가 정답과 일치하면 +1 보상, 아니면 -1 패널티를 준다는 뜻
GRM이 principle과 critique를 실시간으로 최적화하면서 가장 우수한 응답을 잘 구분하도록 학습시킨다. 이 reward signal은 어떤 preference dataset이든지, 또는 LLM이 라벨링한 응답 데이터로부터도 얻을 수 있다는게 장점이다.
Inference-Time Scaling with SPCT
1. Voting with Generated Rewards
각 응답에 대해 여러 개의 보상을 생성하고 이를 합산하여 최종 보상을 결정하는 형태.
보상을 여러 개 샘플링해서 합치면 보상 공간이 k배로 확장된다.
다양한 원칙을 생성할 수 있어 보상의 정밀도와 품질 향상에 도움이 된다.
응답 순서를 섞어서(shuffle) 위치 편향을 막고 다양성을 확보한다.
2. Meta Reward Modeling Guided Voting
샘플링된 보상 일부는 편향/저품질일 수 있다.
투표 과정을 더 잘 가이드하기 위해 별도의 보상모델: meta RM을 훈련한다.
meta RM은 pointwise scalar RM으로서, 각 principle과 critique의 정확성 여부를 판별하는 역할을 한다.
inference-time에서 GRM이 샘플링한 보상 중 k개가 있을 때, meta RM은 이 k개의 샘플 보상 각각에 대해 meta reward를 출력하고, 그 중 상위 k_meta개의 보상만 선택해서 최종 투표에 반영한다.
이를 통해 저품질 샘플을 필터링하는 효과가 있다.
result
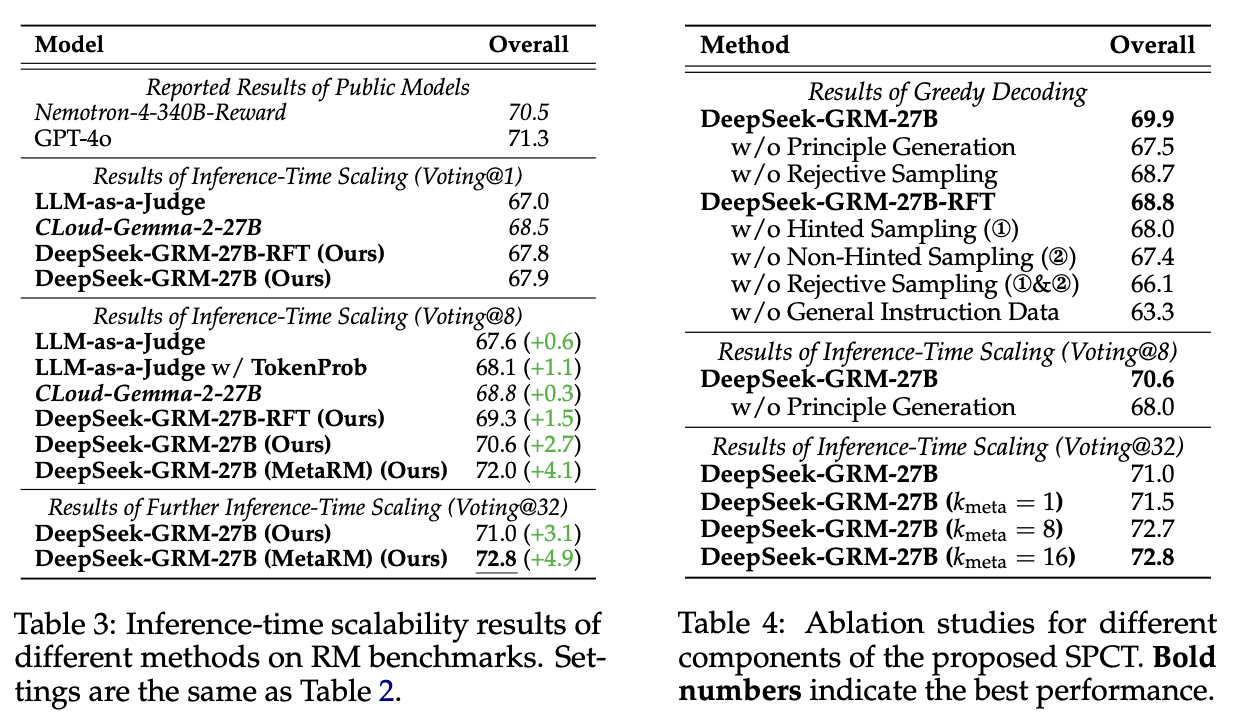
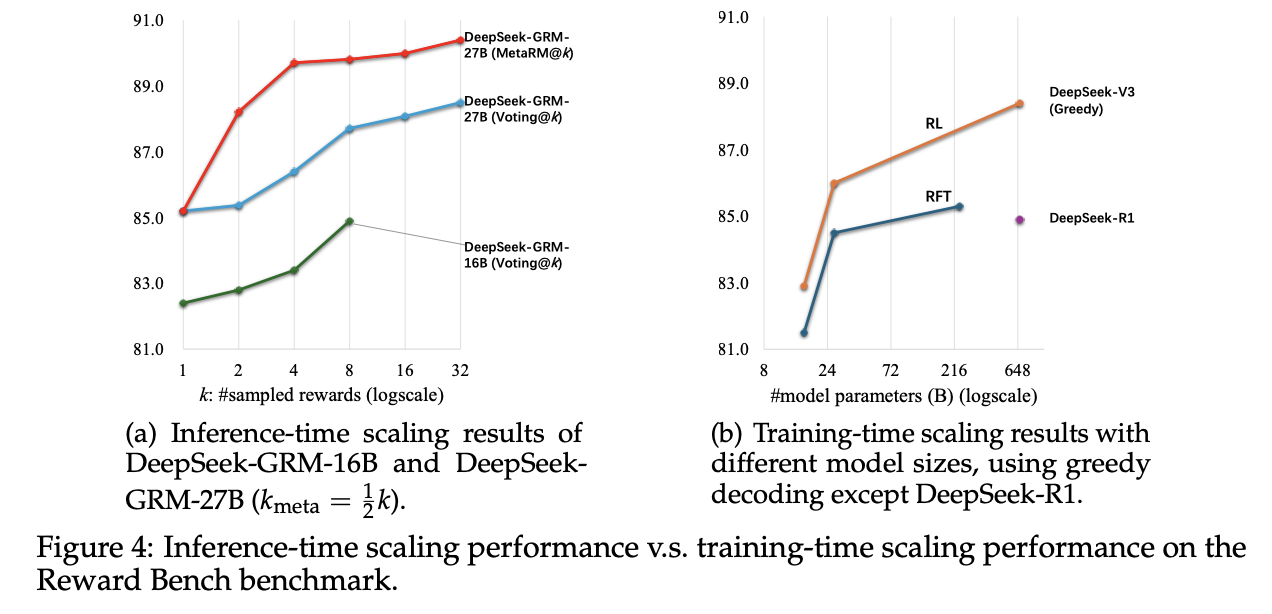
요약
논문 제목: Inference-Time Scaling for Generalist Reward Modeling
motivation: RL을 통해 LLM의 reasoning 능력을 유도: 적절한 학습 방법이 Inference-time scalability를 가능하게 할 수 있다!
메인 연구 질문: Generalist reward modeling을 위해 효과적인 추론 시 확장을 가능하게 하는 학습 방법을 설계할 수 있을까?
과제1. how to improve reward modeling (RM) with more inference compute for general queries
제안:
- 보상 모델링 접근법: Pointwise Generative Reward Modeling(포인트 방식 생성형 보상 모델링, GRM)
- 다양한 입력 유형에 유연하게 대응, inference-time 확장 가능성을 확보
과제2. how to improve the effectiveness of performance-compute scaling with proper learning methods.
제안: - 학습 방법: Self-Principled Critique Tuning(SPCT)
- GRM이 online RL을 통해 principle(원칙)을 자가 생성하고, critique(피드백)을 정확하게 생성하도록 하여 보상의 확장성 있는 생성 행동을 유도한다.
- 이 방식으로 학습된 모델을 DeepSeek-GRM 이라고 명명
Self-Principled Critique Tuning(SPCT)
1단계: Rejective Fine-Tuning
기존처럼 principle을 사전 정의하는게 아니라, 보상 생성의 일부로 포함시켜 직접 생성하는 방식을 제안한다.
사전학습된 GRM에게 principle과 critique를 생성하게 하고, 이로부터 예측 보상을 뽑는다.
2단계: Rule-Based Online RL
강화학습 기반 추가 파인튜닝 단계
모델이 스스로 정제된 원칙을 만들고, 그에 따라 평가 능력을 학습한다.
GRPO 방식 사용
- GRM이 직접 principles + critiques → reward를 생성
- 생성한 보상을 ground truth와 비교해 rule-based reward 제공
- 형식 보상은 제거, 대신 KL penalty로 형식 유지
- 추가로, Inference-Time Scaling 방법
- 1) 다중 + 병렬 샘플링으로 연산량을 늘리고, voting으로 성능 향상. 2) 별도의 meta RM이라는 pointwise scalar 보상모델을 학습시켜 low-quality trajectory 걸러줌
의의 및 기존 연구와의 차별점:
기존 RM 방식: 보상 함수가 정적이거나, human preference dataset에 의존 → 확장성과 일반화에 한계. inference-time compute 증가가 보상 모델에 직접적인 영향을 주지 않음.
본 연구: 모델이 principle & critique를 생성하고, 이를 통한 동적 보상 평가를 수행 + SPCT라는 2단계 구조를 통해 자율성과 평가 일관성을 강화. inference-time scaling을 구조적으로 통합.
