Understanding and Mitigating Language Confusion in LLMs
Understanding and Mitigating Language Confusion in LLMs
2025.04
abstract
language confusion 문제 > Language Confusion Benchmark 생성
- 베이스 모델, 영어 중심 instruct 모델이 특히 언어 혼동에 취약
- 프롬프트가 복잡할수록, 샘플링 temperature가 높을수록 악화
few-shot prompting, multilingual SFT(supervised Fine-Tuning), preference tuning을 통해 해소 가능.
contribution: efficient, scalable multilingual evaluation
introduction
혼동 종류
- full-response confusion / line-;eve; confusion / word-level confusion
- 이질적이고 불쾌한 경험
아래 두 가지 상황에서 조사
- 단일언어 생성(monolingual generation): 사용자가 특정 언어로 질문하고, 같은 언어로 답변을 기대하는 경우
- 교차언어 생성(cross-lingual generation): 사용자가 명시적으로 "이 언어로 답해줘"라고 지시하는 경우
- 15개 유형적으로 다양한 언어를 다루는 language confusion 벤치마크
- llama instruct & mistral 심각한 언어 혼동 > command R과 openai 모델: 더 나은 성능 but 교차언어 생성에서는 가장 강력한 모델조차 일관된 언어로 응답하지 못함
주요 contribution
- llm language confusion 문제를 식별하고 설명
- language confusion 측정하는 새로운 벤치마크와 metrics 도입
- 다양한 llm 의 language confusion 평가
- llm language confusion 개선 방법 제안
2. Language Confusion Benchmark
llm language confusion 측정을 위한 데이터셋은 존재하지 않음
다양한 언어 유형을 포괄하면서 현실적인 사용 사례를 반영한 프롬프트를 수집하여 Language Confusion Benchmark(LCB)를 새로 만들었다.
extensible, cheap, efficient
1. generation settings
- monolingual generation
- 가장 일반적인 사용 상황
- cross-lingual generation
- 입력 언어마다 별도로 프롬프트를 최적화하는 것이 비효율적이거나, 사용자가 자신이 모르는언어로 생성된 응답이 필요한 경우
- 지시 언어: 영어
- language confusion metrics
fastText 채택
- line-level detection
응답을 \n 기준으로 나누고, 각 줄이 사용자가 원하는 언어로 되어 있는지 fastText로 확인한다. - word-level detection
시중에 있는 LID 도구들은 단어 수준까지는 지원하지 않음.
LLM 기반으로 코드스위칭을 탐지해도 F1 점수가 79-86밖에 안 돼서, 자동 평가자로 쓰기에 부족하다.
➡️ 두 가지 기준을 사용한 휴리스틱 방식
- non-Latin script 비라틴 문자 언어 (아랍어, 일본어, 한국어, 중국어 등)
영어 단어가 끼어 있는지만 확인함
→ 영어 단어가 갑자기 섞이면 확실한 오류
→ 일본어 & 중국어 섞이는 경우도 있을텐데 왜 이렇게 했을까..? binary evaluation에서 걸리는건가? 아닌거같은데 ㅇㅅㅇ - Latin script 라틴 문자 언어 (독일어, 프랑스어, 스페인어 등)
해당 언어 유니코드 범위를 벗어난 문자가 있는지 확인함 (더 정밀하게)
- binary evaluation
하나라도 잘못된 줄이나 단어가 있으면 오류로 간주
METRICS
Line-level pass rate(LPR)
percentage of model responses that pass our line-level language confusion detector without error. A response is “correct” if all lines match the user’s desired language.
Word-level pass rate(WPR)
Word-level pass rate(WPR)
percentage of responses where all words are in the desired language.
exclude responses with line-level errors
For languages that use a Latin script, we detect erroneous English words while for Latin script languages, we identify characters outside of the script’s Unicode range.
Language confusion pass rate(LCPR)
LPR, WPR 산술평균
Data Sources
- Aya: 7개 언어 / 각 250개 / 사람이 직접 작성한 프롬프트
- Dolly: 기계 번역된 프롬프트를 유창한 원어민들이 수정한 버전 / 6개 언어 / 200개
- Okapi: 영어 지시문 52k개를 26개 언어로 ChatGPT가 번역한 데이터
- ShareGPT: ShareGPT api로 수집 대부분 영어 / 9만개의 대화의 첫 번째 턴 프롬프트
- Native prompts: 직접 수집 / 일어, 한국어, 스페인어, 프랑스어는 기존 데이터셋이 부족했기 때문에 native annotators에게 요청해서 새롭게 프롬프트 수집
- Complex prompts: 직접 수집 / 사람이 직접 작성한 복잡한 영어 프롬프트
Data Filtering and Processing
LID 도구는 짧은 문장이나 비표준 텍스트에 대해 성능이 떨어진다.
→ 수작업으로 한 단어/구절로 답변이 가능한 예시, 객관식 문제나 목록 나열형 프롬프트, 코드 생성, 수학식, HTML 같은 특정 데이터 형식을 요구하는 프롬프트를 걸러냈다.
→ 응답이 제공되는 데이터셋에서는 완성된 답변이 5단어 미만인 경우도 필터링했다.
→ 서구 중심 질문: 특히 미국 중심 개념(미국 대통령, 미국 국립공원, 미국 브랜드)에 대한 질문이 많다. 이는 잘못된 오류를 낼 수 있어 걸러냄
cross-lingual generation을 위해 타겟 언어로 응답하도록 지시하는 문구를 프롬프트에 추가
monolingual은 원본 그대로 사용
Experiment
models
- Llama 계열
- llama2 70B Instruct, llama3 70B Instruct, llama 3.1 70B Instruct
- Command R 계열
- Command R, Command R+, Command R Refresh, Command R+ Refresh
- Mistral
- Mixtral 8x7B, Mistral Large
- OpenAI
- GPT-3.5 Turbo, GPT-4 Turbo, GPT-4o
llama와 command 모델에 대해서는 instruct & base 버전도 함께 평가함
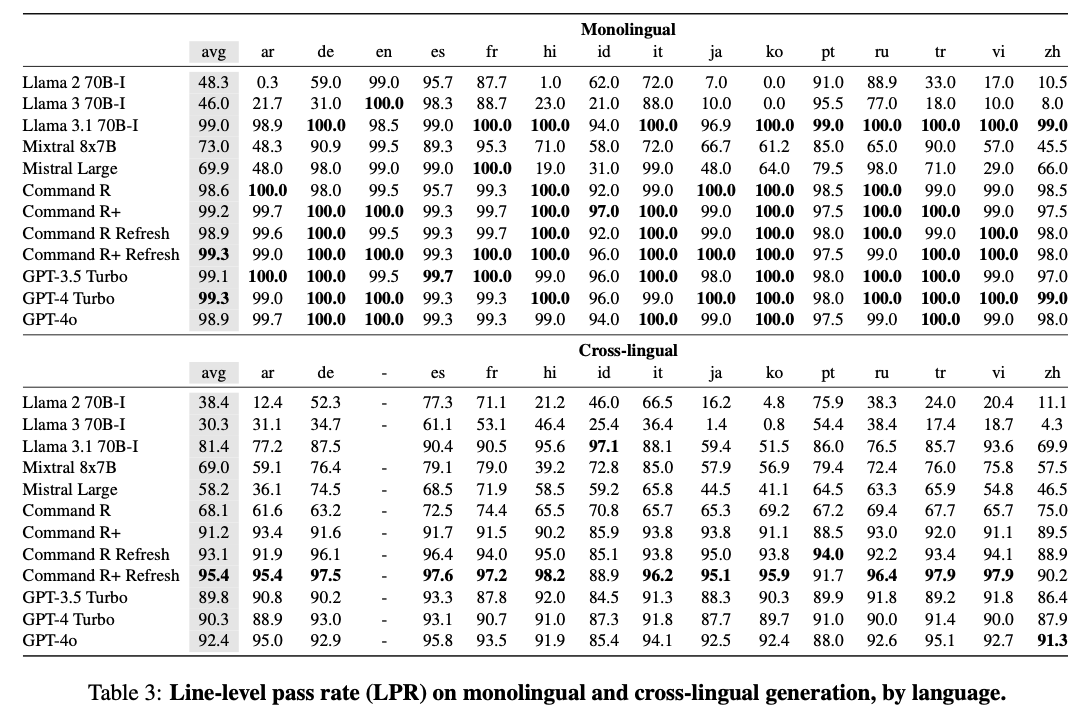
LPR experiment
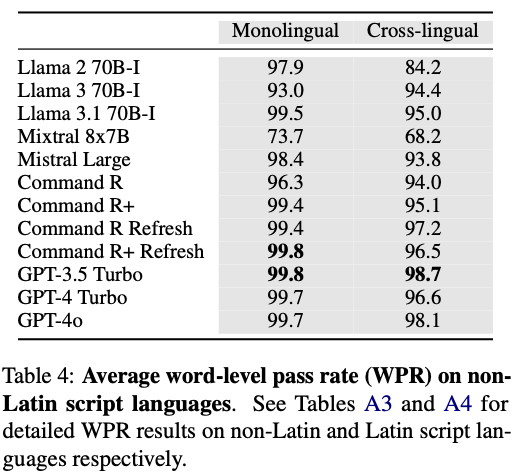
WPR experiment
Impact of dataset
monolingual : 데이터셋 간 차이가 거의 없다
cross-lingual : 데이터셋 간 차이가 더 뚜렷하게 나타났다.
우리가 만든 complex 프롬프트에 대해서는 성능이 떨어졌다.
Impact of prompt length
명확한 패턴 없는걸로 결론. 프롬프트의 복잡성 때문
Impact of instruction position
지시문이 프롬프트 안에 자연스럽게 섞여 있으면 모델들이 언어 혼동을 더 많이 하고, 따로 분리된 지시문일 때 성능이 훨씬 좋다.
시작/끝 위치는 거의 차이가 없음
Impact of quantization
양자화? ??? ? ?
Impact of instruction tuning
instruction model vs base model 비교
Command R: instruction 튜닝하면 언어 혼동이 더 적어진다.
Llama: instruction 튜닝이 영어 중심으로 진행되어서, 오히려 언어 혼동이 심해진다.
When does language confusion occur?
만약 원하지 않는 언어 토큰이 충분히 높은 확률을 부여받으면, 그것이 샘플링된다.
각 샘플링 지점마다 shannon entropy와 nucleus size를 계산했다.
관찰 결과, 언어 혼동은 주로
- 다음 토큰 후보들의 distribution이 flat 하고
- nucleus 가 큰 경우에 발생
언어 혼동은 모델이 다음 토큰을 고를 때 확률이 널리 퍼져 있을 때 주로 발생한다.
6. Mitigating Language Confusion
6.1 Reducing temperature and nucleus size
- temperature를 낮추면 언어 혼동을 줄일 수 있다.
- nucleus size를 줄이는 것도 도움은 되는데 효과는 덜함
6.2 Beam search decoding
beam search: 언어 혼동을 줄이는 데 효과적이다. 특히 cross-lingual 성능 개선이 두드러진다. 계산 비용은 더 많이 든다.
다만 beam size는 키울수록 오히려 성능이 나빠졌다.
6.3 Few-shot prompting
instruction tuning이 안 된 LLM들(ex. Command R)은 그 지시를 답변하는 대신 그냥 번역만 해버리는 경우가 많았다.
→ cherry pick examples
→ few-shot prompting: command R base 언어 혼동이 크게 줄어들었고, monolingual 상황에서는 거의 완전히 문제를 없앴다.
→ one-shot prompting: 단일 언어에서는 오히려 성능이 나빠졌지만 교차 언어에서는 모델이 지시를 더 잘 따르게 만들었다.
Limitations
conversations
단일 턴 입력만 다루고, 여러 턴 대화나 턴마다 다른 언어를 사용하는 상황은 고려하지 않았다.
code-switched input
프롬프트가 하나의 언어로 되어 있는 경우만 다루었다.
한 문장 안에 여러 언어가 있는 입력은 고려하지 않았다.
cross-lingual context
교차언어 맥락이 포함된 입력…?? ?? ? ?
language varieties
표준어에 대해서만 평가. 방언/문체/다양한 스타일 확장 가능
metrics
모델 출력에 대해 최대 100 토큰까지만 평가했다.
- 더 짧게 쪼개는 토크나이징 방식을 쓰는 모델은 LPR, WPR 같은 이진 지표에서 유리할 수 있다
- 덜 장황한(less verbose) 모델이 평가상 유리했을 가능성이 있다
현재 LID 도구는 word-level 언어 식별을 제대로 지원x
WPR 지표는 비라틴 문자 언어 등에서 영어 혼동만 평가할 수 있다.
appendix - preference tuning
DPO(Direct Preference Optimization) 학습이 진행될수록 선호 데이터와 비선호 데이터 모두에 대해 생성 확률이 감소하는 현상
"DPO is prone to generating a biased policy that favors out-of-distribution responses, leading to unpredictable behaviors."
preference learning이 학습 과정에서 자주 등장한 예시의 토큰 생성 확률을 감소시킨다면, 반대로 보지 못했거나 희귀한 토큰들의 상대적 생성 확률이 높아지는 것.
English SFT, English preference tuning 조건에서 관찰한 WPR(Word Prediction Rate) 감소

preference learning이 language confusion과 같이, 바람직하지 않은 행동을 촉진할 수 있다는 가설은 추가연구가 필요하다.
오히려 강화학습이 성능을 낮춘다?
