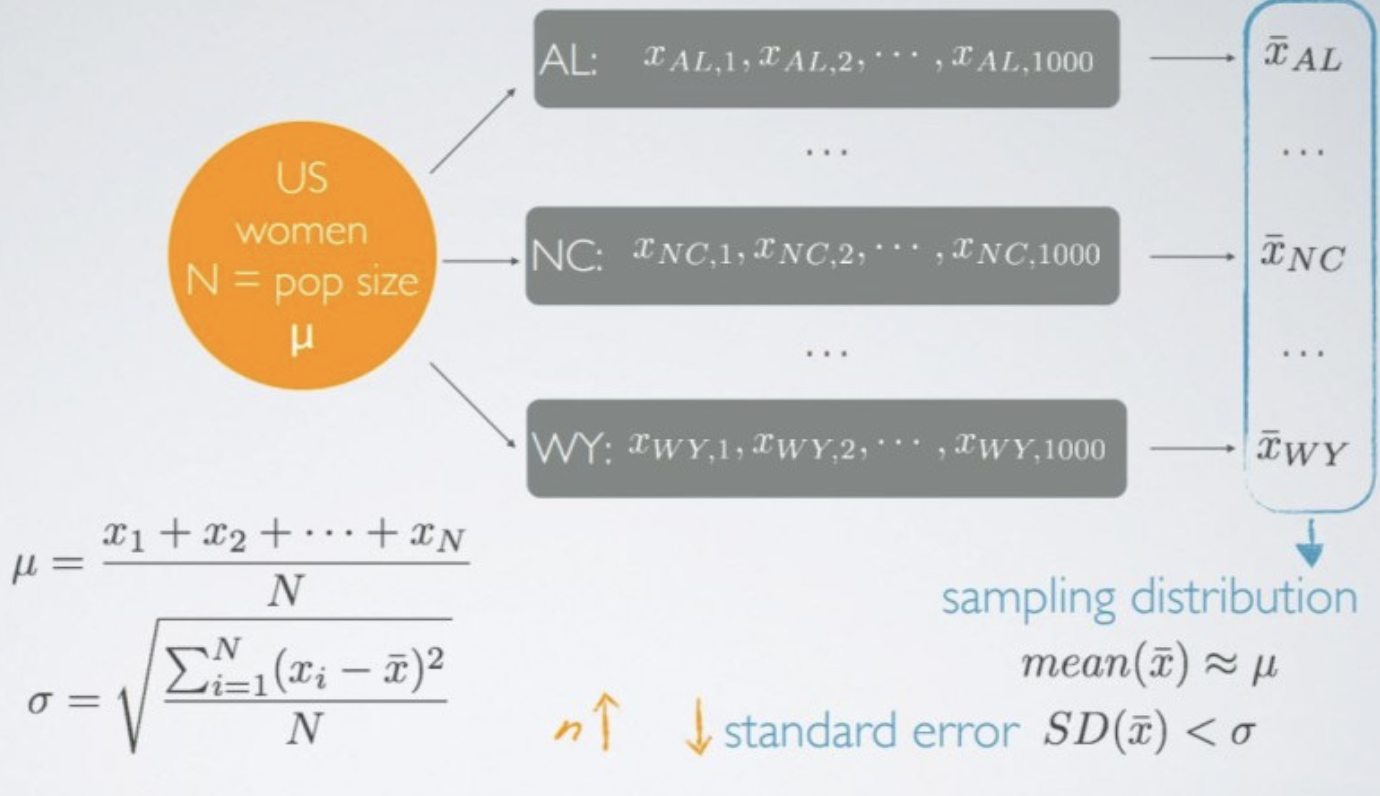
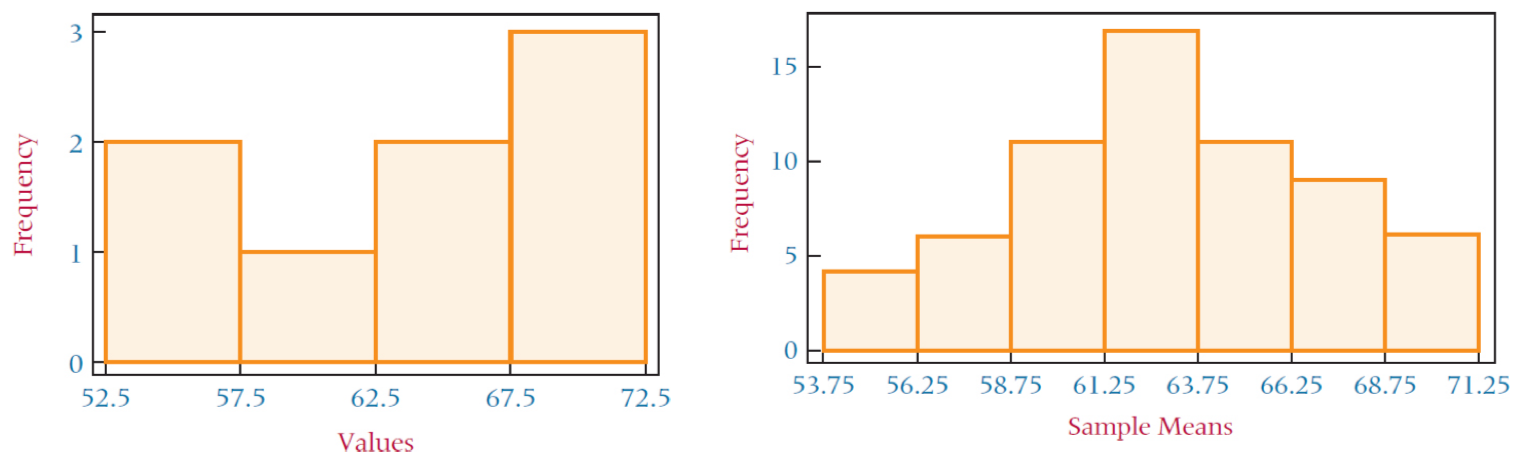
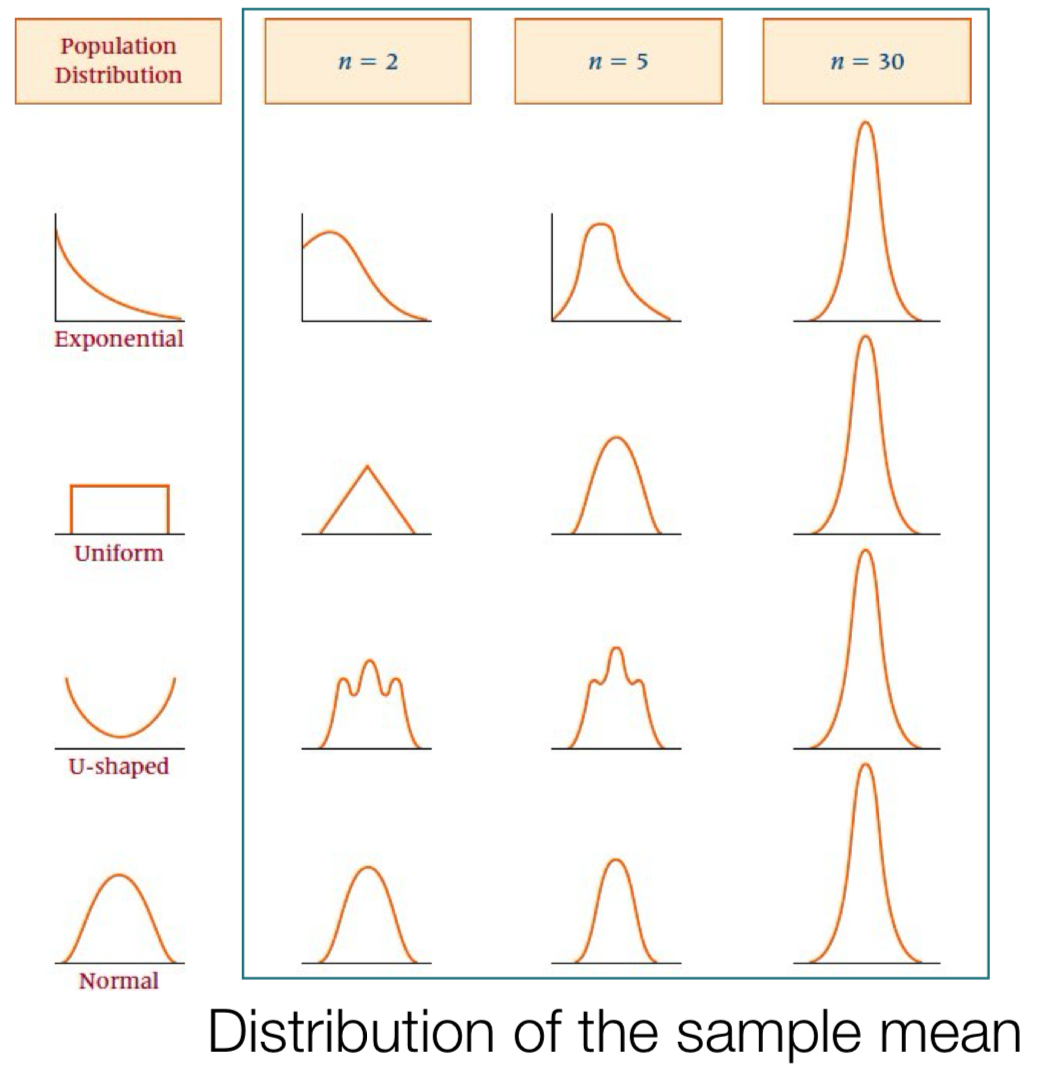
Population(모수): μ = parameter 모집단을 표현
Sample(표본): xˉ = statistic 표본을 표현
Random Sampling: every unit of the population has the same probability of being selected into the sample (지향)
Nonrandom Sampling: not every unit of the population ~ (지양. 통계방법론 적용에 부적절함)
Random Sampling Techniques
Simple Random Sampling
난수를 생성하여 임의로 뽑는다.
모수 N -> 표본 n
Stratified Sampling
Population is divided into non-overlapping subpopulations
ex. age, gender, religion, etc.
집단을 구분하여 랜덤 샘플링
sample more closely match the population(error down)
집단 안에서는 동일하고 집단 밖에서는 배타적인 것이(겹치는게 없는) 이상적.
Proportionate stratified random sampling
occurs when: the percentage of the sample taken from each stratum is proportionate to the percentage that each stratum is within the whole population
각 표본의 비율이 모집단에서의 비율과 같을 때 !!
Disproportionate
different percentage
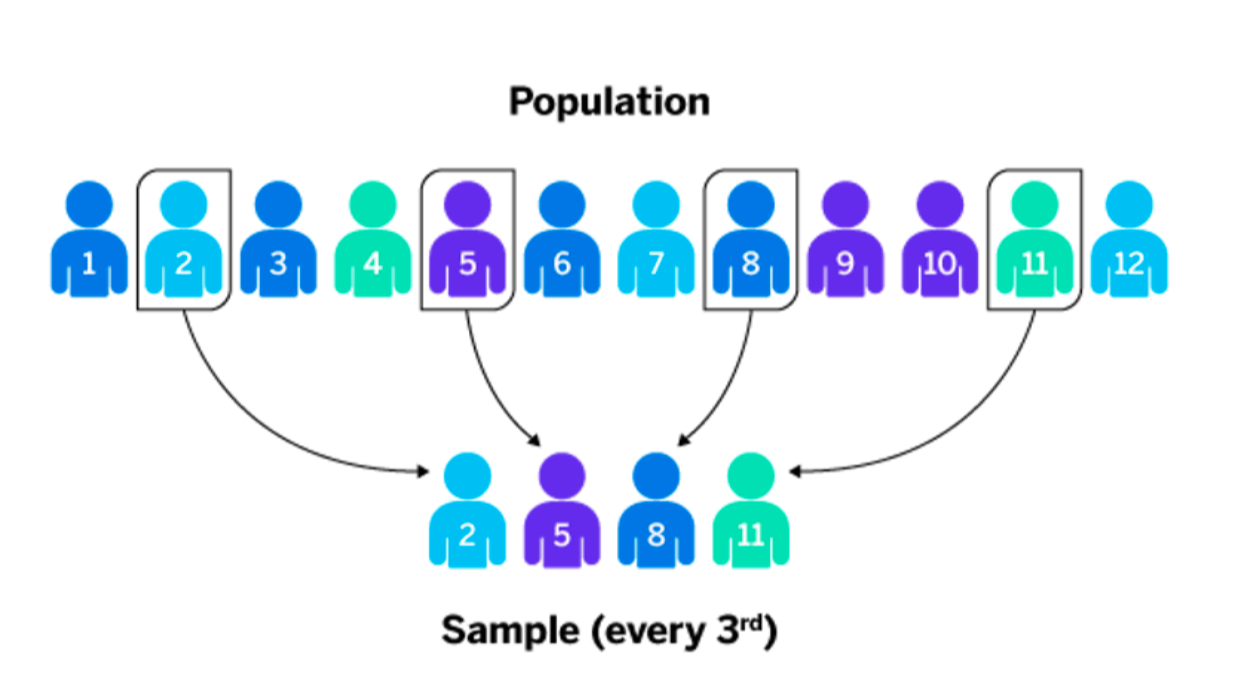
Systematic Sampling
Every kth item selected, sample size n, population size N, k=N/n
ex. 순서대로 3의배수마다(?) 샘플 추출 (2,5,8..)
장점: convenient, 고르게(evenly) 분포된 샘플
단점: 데이터에 주기성이 있으면 bad
Cluster Sampling
Dividing populaiton into non-overlapping areas
아까랑 다르게, 하나의 집단 안에 다양한 사람들이 있고 그 집단이 다 비슷하게 생겨야 함.
cluster should be a miniature of the population
장점: cluster가 명확하면 비용 등 효율적
단점: cluster의 요소가 비슷하면, simple random sampling보다 덜 효율적일 수 있음
정리하자면,
pop mean : μ
pop var : σ2=E[(X−E(X))2]=E(X2)−E(X)2
sample mean : xˉ=n1∑i=1nxi
sample var : s2=n−11∑i=1n(xi−xˉ)2
표본평균의 평균 : E(Xˉ)=μ
표본평균의 분산: Var(Xˉ)=nσ2
모평균을 모르기 때문에 sample mean으로 추정한다.
기댓값의 정의인 ∑xf(x)는 분포 f(x)를 알 때의 얘기!
자유도
"계산의 자유도". 자유도 = 서로 독립적인 정보의 수. = 미지수(편의상!)-추정치
표본평균은 a+b+c/3으로 구한다. a,b,c 미지수 3개 = 자유도 3(n)
표본분산은 평균이 m일 때 (m-a)^2+(m-b)^2+(m-c)^2/2
a,b,c는 미지수, m은 a,b,c를 가지고 추정한 "추정치"
미지수에서 추정치 빼야 하기 때문에 3-1
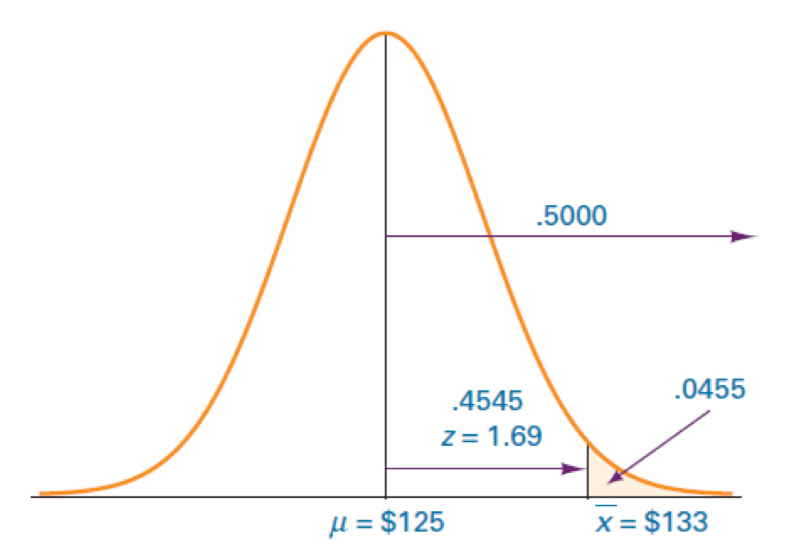
Suppose the population mean amount of money spent per customer at a store is $125 and the population standard deviation is $30. If a random sample of 40 customers is taken, what is the probability that the sample mean expenditure is more than $133?
μ=125,σ=30,n=40 P(Xˉ>=133)?
풀이 P(Xˉ≥133)=P(z≥30/40133−125)≈1.69
z분포표에 따르면, z=1.69의 확률은 0.4545
z가 1.69보다 클 확률이기 때문에 (위의 그림 참고) 0.5-0.4545 = 0.0455
Finite Population Correction (FPC)
지금까지는 모집단이 무한대이거나 충분히 클 때를 가정했음.
모집단이 유한하고 표본을 비복원추출할 경우,
z=nσN−1N−nxˉ−μ
N은 모집단의 크기, n은 표본의 크기
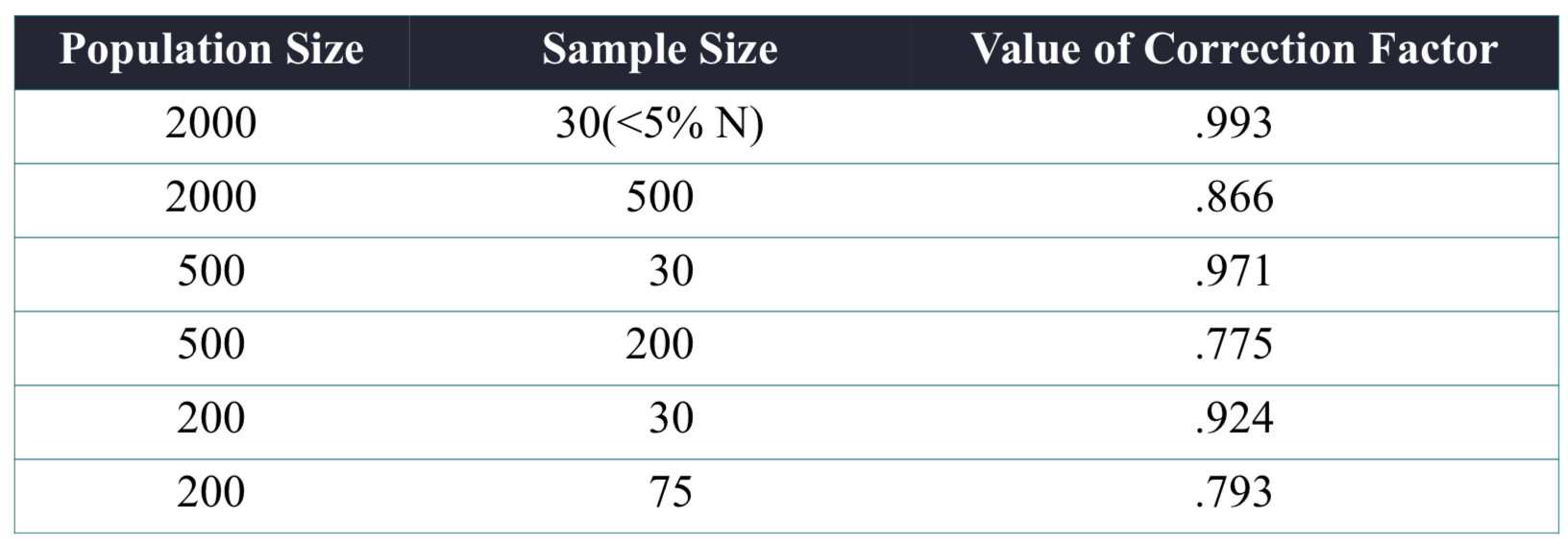
n/N≥0.05 일 때 FPC 적용.
N >> n (훨씬 크다) 일수록 N−1N−n는 1로 수렴. FPC 참고자료
n=1일 때 FPC=1. 0≤FPC≤1
Distribution of Sample Proportion
Sample Proportion
표본비율(p^): 모집단에서 추출한 표본들이 어떤 특징을 가지는 것들의 비율
computed by dividing the frequency with which a given characteristic occurs in the sample by the number of items in the sample
n이 충분히 클 때(np≥5,nq≥5 where q=1-p) CLT에 따라 p^는 정규분포를 따른다.
표본비율의 평균은 p, 표본비율의 분산은 pq/n, 표본비율의 표준편차는 sqrt(pq/n)
정리하자면,
X∼Binom(n,p)≈N(np,npq)p^=nX∼N(p,npq)
표본비율이 X/n으로 구해지는데, X가 N(np,npq)를 따르고, 표본비율 p hat은 근사적으로 N(p, pq/n)을 따르게 되는 것이다.
예시
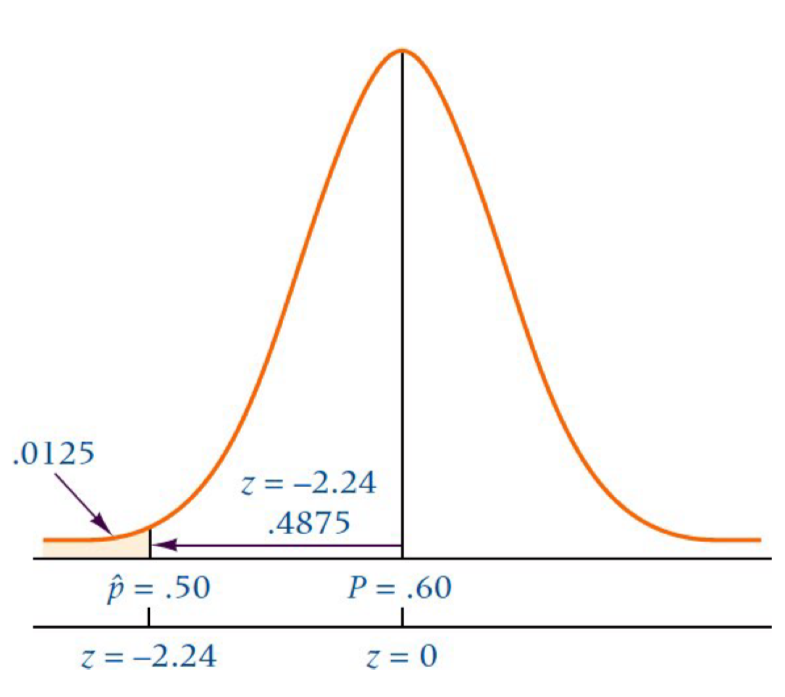
Suppose 60% of the electrical contractors in a region use a particular brand of wire. What is the probability of taking a random sample of size 120 from these electrical contractors and finding that 50% or less use that brand of wire?
p=0.6
n=120 P(p^≤0.5)?
풀이 np>5, nq>5 -> We can have CLT
z=pq/np^−p z=(0.6×0.4)/1200.5−0.6≈−2.24
0.5-0.4875=0.0125
어디서 배웠는지 기억해낼 수 없어 따로 적는 내용..
선형결합에서의 평균과 분산
X=∑i=1naiXi
E[X]=i=1∑naiμiV[X]=i=1∑nai2σi2
참고: 연세대학교 손지용 교수님 통계방법론 강의안 <Excel, SPSS, R로 배우는 통계학 입문>