: a statistic taken from a sample as a single value that is used to estimate a population parameter
추정은 점추정과 구간추정 두 가지로 구분되는데, 점추정은 모수를 어떤 하나의 값으로 추정(추정값이 하나의 값으로 나옴)하는 것이고 구간추정은 어떤 구간으로 추정하는 것이다.
Let {Xi}i=1n are i.i.d. random variables with Xi∼N(μ,σ2) μ의 점추정값: Xˉ=nX1+X2+⋯+Xn
좋은 추정량의 기준으로 비편향성, 효율성, 일치성이 있다.
여기서 우리가 추정하고 싶은 parameter θ는 모평균, θ의 점추정값 θ^는 표본평균으로 둔다.
Criteria for good point estimate
Unbiasedness : E[θ^]=θ
Efficiency : variance V(θ^)=E[(θ^−E[θ^])2] is small
Consistency : limn→∞Pr(∣θ^−θ∣>ε)=0 for all ε>0
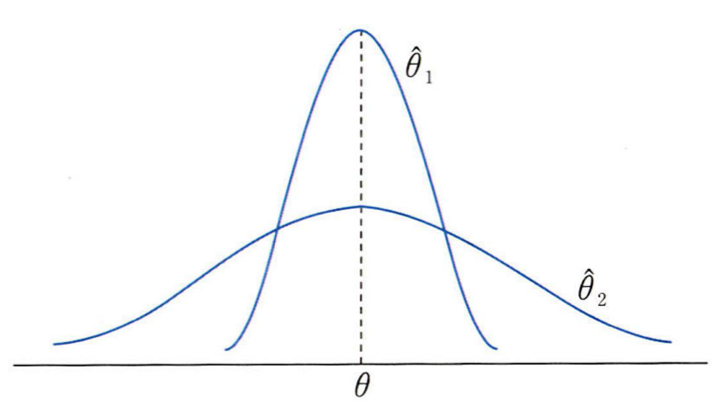
통계학에서 효율은 추정량의 작은 분산, 즉 작은 변동폭을 뜻한다. θ^1의 분산이 더 작으므로, 더 효율적이다.
통계학에서 일치성은 추정량의 모수로의 확률적 수렴성을 뜻한다. 좋은 추정량의 갖추어야 할 최소한의 조건으로 생각되기도 한다.
중심극한정리에 따라, 표본평균의 분산은 표본 크기가 늘어나면 0으로 수렴한다. 어느 추정량의 분산이 0으로 수렴한다는 것은 그 추정량의 표본추출로 인한 변동이 점차 줄어들고, 결국 그 추정량의 평균으로 수렴함을 의미한다. (통계학에서 수렴은 수학과 달리 0이 될 수 있다.)
모평균에서 아무리 작은 값 이상을 벗어날 확률은 표본크기가 커짐에 따라 0이 되게 되는데, 이 경우 표본평균은 모평균에 확률적으로 수렴한다고 한다.
n→∞limPr(∣θ^−θ∣>ε)=0
for all ε>0
(세타 값에서 아무리 작은 값이라도 벗어날 확률이 0이 된다)
Pr(θ^=θ)n→∞⟶1이 되는 θ^은 일치추정량이다.
example
E[Xˉ]=μV[Xˉ]=σ2/nPr(Xˉ=μ)→1 as n→∞
Interval Estimate (Confidence Interval)
: a range of values within which the analyst can declare, with some confidence, the population parameter is contained
구간추정은 모수를 하나의 값으로 추정하는 것이 아니라, 오차의 크기가 고려된 구간으로 나타내는 것. 표본통계량의 변동성 때문에, 보통 구간추정을 더 선호한다.
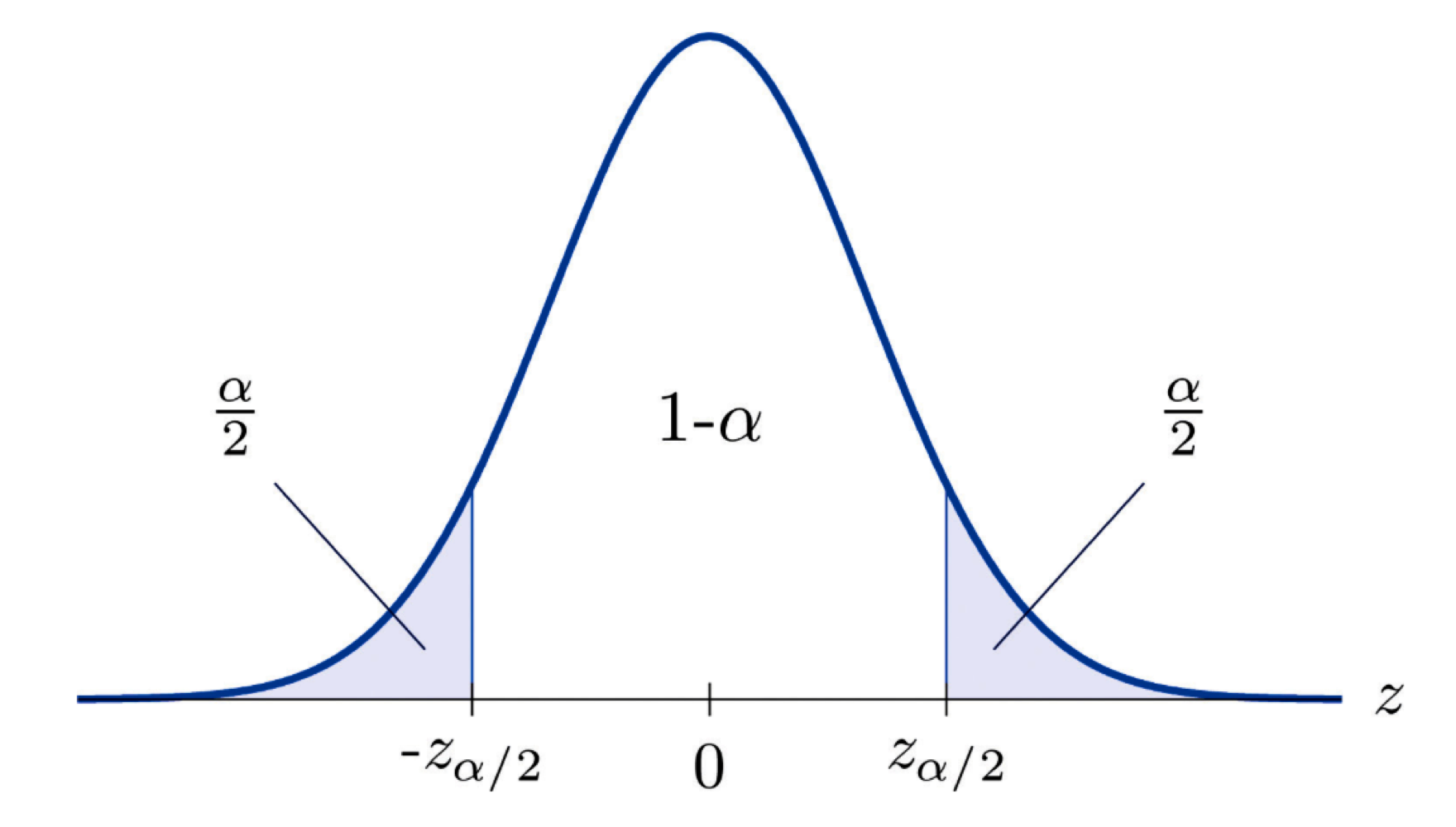
Level of confidence(신뢰수준) = 1−α
: 신뢰구간이 모수를 포함할 확률(비율)
여기서 α는 유의수준(Significance level)으로, 귀무가설이 참인데도 기각할 확률(잘못 추정할 확률).
표본을 100번 추출하여 신뢰구간을 구했다면 그 100개의 신뢰구간 중 95개가 모수를 포함했다: 신뢰수준은 95%이다.
alpha=0.05 alpha/2=0.025
0.5-0.025=0.475
z분포표에 따라 -> P(0<=Z<=1.96) = 0.4750 1600−1.9685160≤μ≤1600+1.9685160=1265.99≤μ≤1334.01
-> The telephone company can conclude with 95% confidence of number of texts is between 1265.99 texts and 1334.01 texts.
zα/2nσ는 margin of error(표본오차)라고 불린다.
신뢰수준 하에서 샘플에 의한 추정이 모집단의 측정치와 표본오차 범위만큼 차이가 날 수 있다
신뢰수준의 상한선, 하한선을 결정
Finite Correction Factor
모집단이 유한할 경우, 결과의 정확도를 높이기 위해 Finite Correction Factor를 사용할 수 있다.
xˉ−zα/2nσN−1N−n≤μ≤xˉ+zα/2nσN−1N−n
2. Estimating the Population Mean When σ Unknown
use the t statistic
모집단의 표준편차는 알려지지 않은 경우가 많다.
σ를 표본표준편차 s로 대체
z분포 대신 자유도가 n-1인 t분포를 따름
t=s/nxˉ−μ∼tn−1
카이제곱분포 카이제곱분포 설명
확률변수 Z1,Z2,...,Zn가 각각 표준정규분포를 따르고 서로 독립일 때, Z12+Z22+...+Zn2∼χ2(n)
n: 자유도
표본 크기가 커질수록 z분포와 유사해진다.
Z가 표준정규분포의 확률변수, Y가 자유도 n인 카이제곱분포의 확률변수이며 Z와 Y가 독립일 때, X=ZYn는 자유도가 n인 t분포를 따른다.
xˉ−tα/2,n−1ns≤μ≤xˉ+tα/2,n−1ns,df=n−1
원하는 자유도가 t분포표에 없을 수도 있는데, 그때는 원하는 자유도보다 작은 수 중 가장 가까운 수를 사용한다.
더 작은 값을 사용하는 이유는, 더 보수적으로 결과 구하기
3. Estimating the Population Proportion
use the z statistic
표본비율 p를 추정한다.
ex. 생산품 중 불량품의 비율을 추정
p^=nX∼N(p,npq)
CLT에 따라 z값을 다음과 같이 구할 수 있다.
z=pq/np^−p,q=1−p
표본평균 추정 xˉ∼N(μ,nσ2) Z=σ/nxˉ−μ
표본비율 추정 p^∼N(p,npq) Z=pq/np^−p
두 추정 모두 N(0,1)의 표준정규분포를 따르는 Z값으로 추정한다
p를 알기가 어렵기 때문에 p를 p^로 대체하고, 표본 크기가 클 경우와 신뢰구간 추정의 경우만 추정이 가능하다.
보통 문제에서 p^가 주어짐
p^−zα/2np^q^≤p≤p^+zα/2np^q^,q^=1−p^
4. Estimating the Population Variance
given sample variance s2
use the chi-square statistic
모분산의 점추정값은 표본분산 s^2이다.
s2=n−11i=1∑n(xi−xˉ)2
모분산에 대한 구간추정에는 (n−1)s2/σ2의 분포가 유용한데, 이 분포는 자유도가 n-1인 카이제곱분포를 따른다.
χ2=σ2(n−1)s2∼χn−12
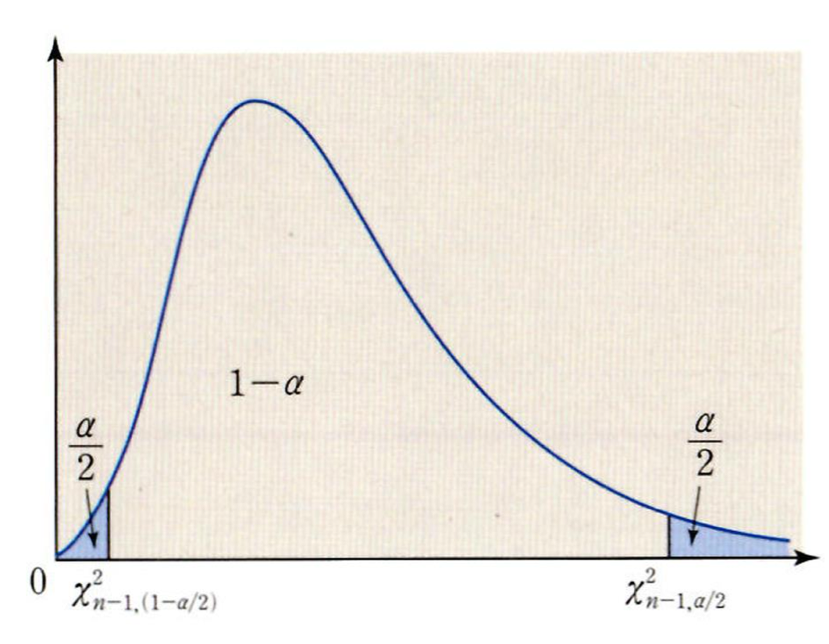
카이제곱분포의 신뢰구간은 다음과 같다.
χα/22(n−1)s2≤σ2≤χ1−α/22(n−1)s2
카이제곱분포는 대칭이 아님에 유의한다.
5. Estimating Sample Size
표본수 n을 추정한다.
표본오차를 E=xˉ−μ라고 하자.
z=nσxˉ−μ=nσE∼N(0,1)
5-1. given σ
n=(Ezα/2σ)2
5-2. population proportion
p가 주어지지 않았다면, 보통 0.5로 생각한다.
n=E2zα/22pq
ex. Suppose a business analyst wants to estimate what proportion of IT workers are self-employed. The analyst wants to be 99 % confident of the result and be within 0.05 of the actual proportion. How large sample size should be taken?
풀이
p=0.5, E=0.05
n=E2z0.0052pq=0.0522.5752×0.52=663.1
-> The analyst would have to sample at least 664 workers to attain a 99% level of confidence and produce an error no bigger than 0.05.