객체지향언어와 절차적 언어와의 차이점을 보며 각각 어떻게 사용을 하는 것이 적합한지에 대해 살펴보도록 하겠다
절차적 vs 객체지향

- 절차적 언어 (Procedural Language)
- 순차적으로, 차례대로 기능들이 수행됨
- 데이터가 모두 공개되어있는 상태
- 객체지향 언어 (Object-oriented Language)
- public method만 가지고 대화하는 언어로, 움직임의 주체인 객체들끼리의 대화로 진행을 한다
- 객체가 움직임의 주체이기 때문에 동사로 이름이 작명되어야 하는 것!
- 이 객체가 다른 애들에게 서비스를 제공하는 형태이며, 나머지는 모두 private으로 처리해서 내부적인 것을 공개하지 않아야 서로 독립적으로 유지가 되면서 기능을 재사용할 수 있다
📌 Objects vs Data Structures
💭 왜 변수들을 private으로 만들어야 하는가? 왜 데이터를 노출하지 말아야 하는가?
- 그 이유는 다른 사람들이 이것에 의존하지 않기 바라기 때문이다
- 사용자가 타입이나 이행(implementation)을 바꿀 수 있는 자유를 주고 싶기 때문이다
- public으로 설정해놓으면 누구나 사용이 가능하다는 말이다. 즉, 누구나 수정이 가능하기 때문에 위험할 수 있다
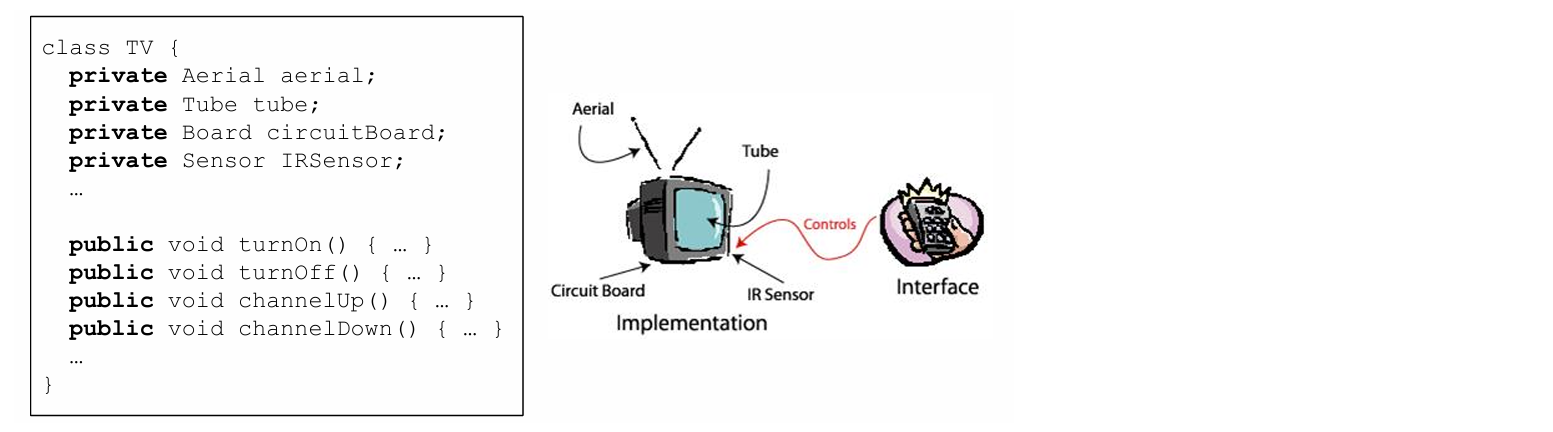
이 코드처럼 변수들을 private으로 설정해놓아야 dependency가 없어져 독립성이 높아질 수 있다.
🔻 함수의 interface
함수의 interface를 구성하는 세 가지 요소가 있다
- 함수의 이름
- 함수의 매개변수
- 함수의 return value
이 세 가지는 바뀌면 안되는 요소로 고정을 해놓는 것이다.
그 외에는 자유롭게 수정할 수 있게 private으로 설정하는 것이 바람직하다. 그렇지 않으면 각각의 기능이 tightly connected 되어 있는 것이기 때문!
자 이제 Object와 Data structure가 무엇인지 살펴보자
- Object : data + behaviors
-
객체 = 데이터 + 행동(method, 서비스)
-
[정보은닉] 데이터를 숨기고 행동, 즉 메소드를 드러내는 것이다
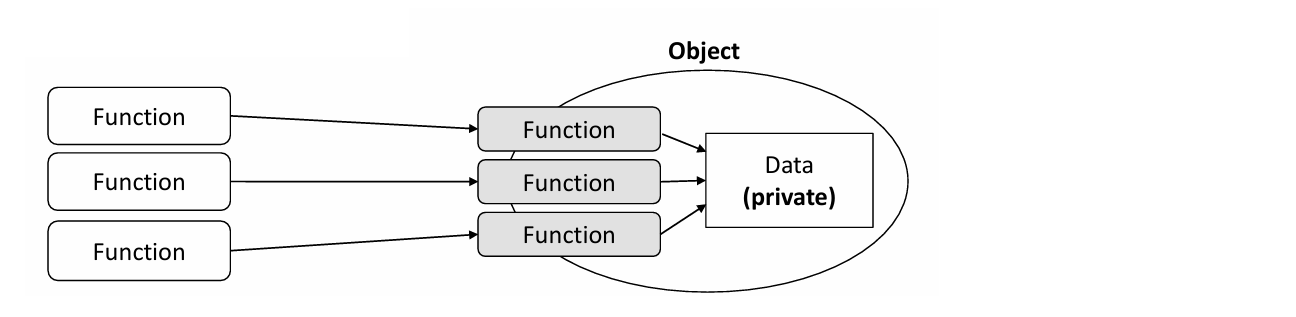
Function들은 public, Data는 private은 상태다.
new를 통해 새로운 객체를 만들어서 이런 function들을 사용하는 것이다. 사용하고 싶은 서비스를 받아서 사용하는 것이 객체지향 언어의 핵심이다!Data는 private이어야 서로 독립적으로 값들을 바꿔가며 사용을 할 수 있다!
따라서 객체를 만들 때 독립적으로 기능할 수 있을지, 재사용(reuse)가 가능할지를 고민하면서 만들어야 한다!
-
- Data structure : data
- 데이터를 드러내고, 특별한 행동이 없는 것
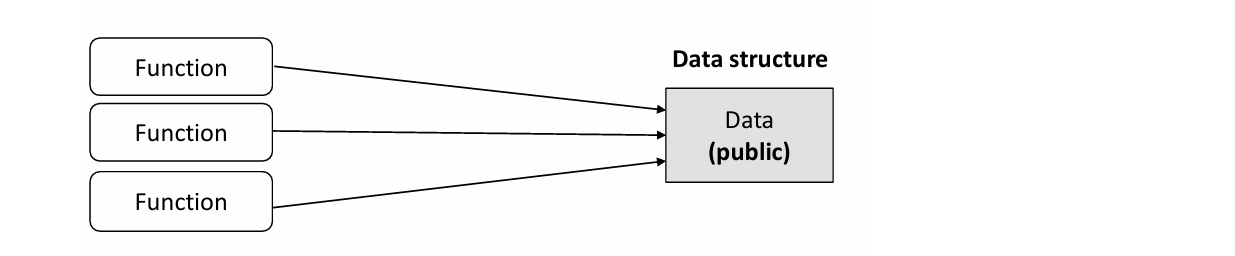
- 데이터를 드러내고, 특별한 행동이 없는 것
📌 Data Abstraction
두 가지 예시를 통해 한 번 이해를 해보도록 하자.
🔹 첫 번째 예시
아래 코드들의 차이점이 무엇일까?
- Point class
public class Point {
public double x;
public double y;
}- Point interface
public interface Point {
double getX();
double getY();
void setCartesian(double x, double y);
double getR();
double getTheta();
void setPolar(double r, double theta);
}interface는 클래스의 특수한 조율로, 본체는 전혀 없고 껍데기만 있는 형태이다.
내용을 보면, 제공하고 싶은 서비스를 나열하기만 하였지 내부적으로 어떻게 데이터가 관리되고 있는지 알 수 없다.
예를 들어,

setCartiesan을 사용해서 기능을 하고 있는지, getTheta를 사용해서 기능을 하고 있는지 알 수 없는 것!
물론, setCartesian(double x, double y)에서처럼 매개변수값이 반드시 함께 전달되기 만들어, 내부에서 외부에서 접근하는 것을 제어할 수는 있다!
📍 Point 인터페이스 → 객체 (Object)
- 위에서 말했듯이, 구현이 직교 좌표계인지 극 좌표계인지 알 수 있는 방법이 없다
- 메소드가 접근 정책을 강제한다
- 개별 좌표는 읽을 수 있다
- 하지만 좌표를 반드시 함께 설정해야 함
- 구현(implementation)을 숨긴다
📍 Point 클래스 → 자료 구조 (Data Structure)
- 직교 좌표계로 명확하게 구현되었다
- 접근 정책이 없다
- 좌표를 완전히 자유롭게 조작할 수 있다
- 구현을 노출한다
- 내부 구조가 다 드러난 상태로, 마음껏 쓰라는 형태~
🔻 Object
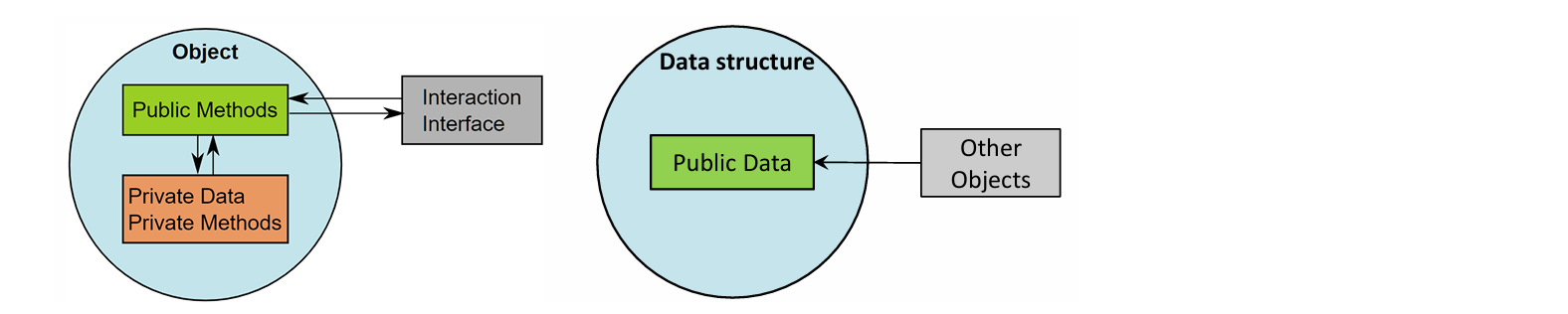
정리를 다시 해보자면, 객체는 사용자가 데이터의 구현을 알 필요없이 데이터를 조작할 수 있게 하는 추상 인터페이스를 노출하는 것이다
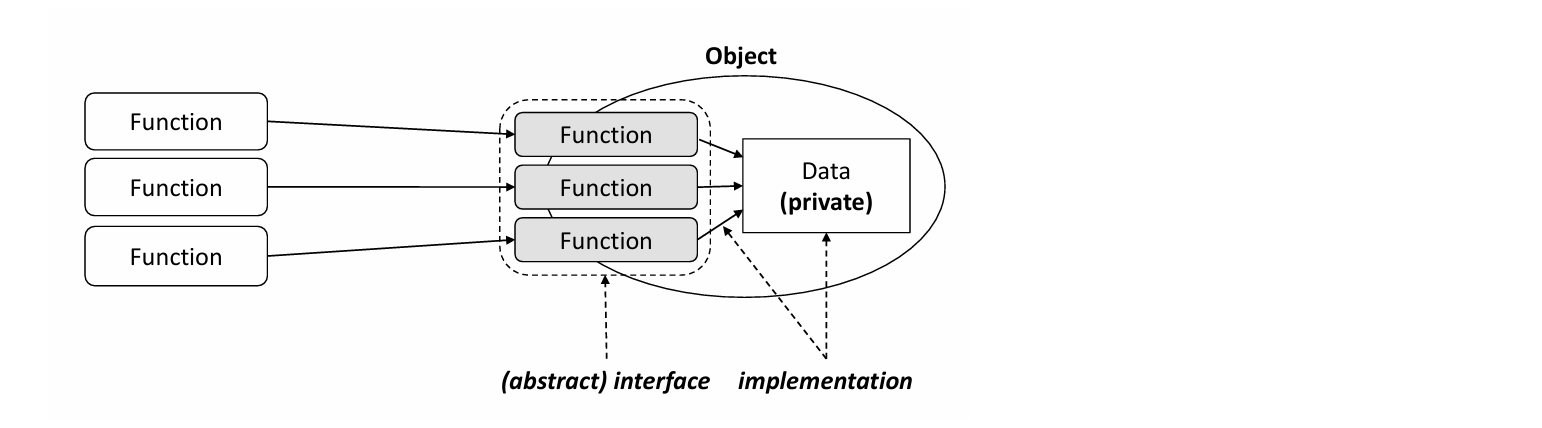
함수의 interface는 함수의 이름, 매개변수, return type이라고 했다. 이 세 개만 안 상태로 사용을 하는 것이고, 그 틀 안에서 각자 구현(implementation)을 하는 것!
🔹 두 번째 예시
아래 코드들의 차이점이 무엇일까?
- Vehicle interface
public interface Vehicle {
double getFuelTankCapacityInGallons();
double getGallonsOfGasoline();
}- 차량의 연료량을 구체적인 단위인 Gallon으로 표현
- 변수의 단순 접근자(accessor) 역할을 할 가능성이 큼
inteface를 사용하고 있기는 하지만, 메소드명을 보면 모든 차량에 사용할 수 있는 것이 아니라 내연기관 차량에만 사용가능하기 때문에 내부구조를 다 드러낸 것과 같다.
이처럼 public method를 노출 시킬 때는 재사용이 가능한지를 생각해야 한다. 내부구조가 바뀌어도 메소드명에 걸맞는 기능을 하는 것인지를 생각해봐야 한다.
- Vehicle interface
public interface Vehicle {
double getPercentFuelRemaining();
}- 연료량을 퍼센트로 추상화함
- 데이터의 형태에 대해 전혀 알 수 없음
따라서 위 코드처럼 추상화 단계를 한 단계 높여 다른 종류의 차량들도 모두 사용이 가능하도록 만들어야 한다.
이처럼 interface를 활용할 때는...
- 데이터의 세부 사항을 노출시키지 않는다
- 데이터는 추상적인 용어로 표현해야 한다
- 이는 단순히 인터페이스나 getter/setter를 사용하는 것만으로 달성되지 않는다
요약을 해보자면

📍 객체
- 데이터를 추상화 뒤에 숨김
- method를 통해서만 data에 접근이 가능
- 그 데이터를 조작하는 메소드만 노출함
✔️ cf. 함수 호출 = 해당 함수에게 message를 보냈다
📍 자료 구조
- 데이터를 노출함
- 의미 있는 메소드가 없음
📌 Data/Object Anti-Symmetry
위 내용을 읽어보면 마치 객체지향 언어가 옳고 절차적 언어가 틀린 것처럼 보일 수 있다.
하지만 객체지향 언어의 핵심 개념을 설명하기 위한 내용이었음을 알고 가자.
두 언어 모두 장단점을 가지고 있고, 상황에 따라 필요에 맞게 언어를 사용해야 한다.
이제 각각의 언어를 더 살펴보도록 하자!
📍 절차적 코드
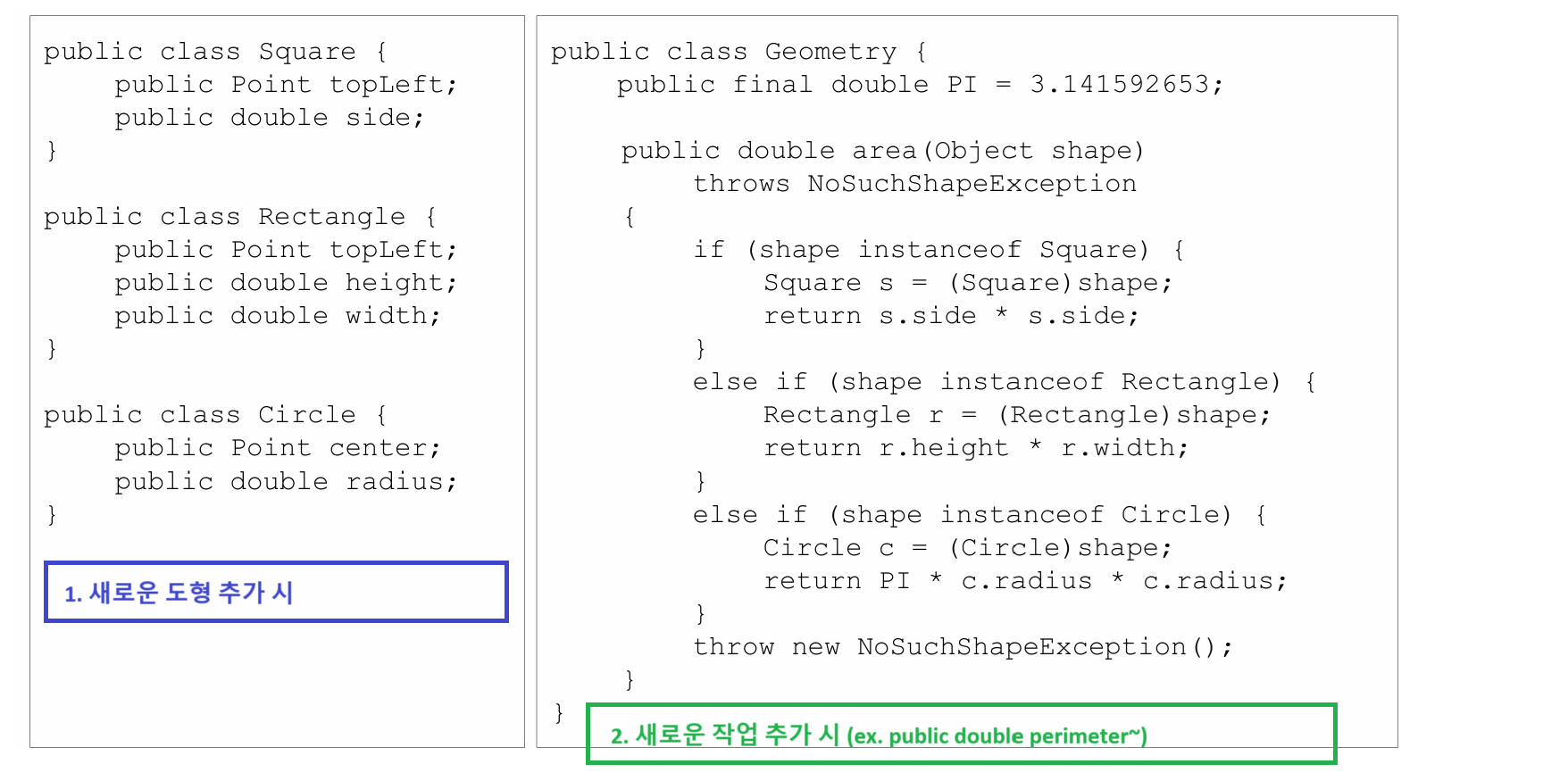
Square, Rectangle, Circle 클래스를 보면 사용할 변수만 선언을 해놓고 있고, area를 구하는 것은 나의 몫으로 되어있다.
즉, 내부구조를 다 알고 있기에 서비스를 본인이 다 짜야하는 상태이다.
이러한 코드의 장점과 단점은 무엇일까?
✔️ 장점
- 새로운 기능이 추가하기 쉽다
예를 들어, perimeter를 구하는 작업을 추가한다고 했을 때, 기존의 코드에서 수정할 것 하나 없이 area 메소드 아래 perimeter 메소드를 추가만 해주면 된다
✔️ 단점
- 새로운 도형을 추가하기 어렵다
만약 Triangle 도형을 추가하고 싶다고 한다면, area에서 else if (shape instanceof Triangle)~ 하며 계산 코드를 다 적어줘야 한다. 이렇게 도형을 추가할 때마다 다 커버를 해야하기 때문에 overhead가 큰 작업이 된다
📍 객체지향적 코드

Shape라는 interface를 만들어 area 메소드를 정의해놓았다. 새로운 객체(도형)마다 area를 제공했으면 좋겠다고 할 때 interface를 사용하는 것이다. 그래서 Shape을 implement한 클래스들은 모두 area를 구현해야하는 형태인 것!
implement를 한다는 것은 인터페이스에서 정의된 것을 다 받아서 구현을 다 한다는 것이며, 구현을 한다는 것은 내용을 채워넣는 것을 의미한다.
각자의 객체는 내부 데이터를 private으로 선언하여 숨긴 상태이다. 단 PI는 public으로 선언했는데 이는 상수이기 때문에 누구나 사용해도 되기에 public으로 선언한 것이다.
여기서 만약 Shape s = new Shape();라고 작성하면 어떻게 될까? 에러가 날 것이다. 왜냐하면 지금 interface는 본체가 없고 껍데기만 있는 상태이기 대문에 컴파일이 불가하다.
그렇다면 Shape s = new Square();라고 하면 어떨까? 컴파일이 될 것이다. 그리고 a = s.area();라고 한다면 s.area()는 Square 클래스의 area가 호출되어 side * side 가 계산될 것이다.
이처럼 "new ~~" 부분만 바꾸면 각 도형의 면적을 구할 수 있게 되는 것이다! 이것이 객체 지향의 하이라이트~!!
✔️ 다형성
- area() 메소드는 다형성을 가지기 대문에 절차적 언어처럼 Geometry라는 클래스가 필요가 없다
✔️ 장점
- 새로운 도형을 추가하기 쉽다
- 즉, 새로운 객체를 생성하는 것이 쉽다는 것
새로운 도형을 추가해도 기존 코드에서 수정해야 하는 것이 없음!
✔️ 단점
- 새로운 기능을 추가하기 어렵다
- 새로운 기능 필요시 객체마다 다 넣어줘야 한다
예를 들어, perimeter를 구하는 기능을 추가하고 싶다면 객체마다 기능을 다 구현해주어야 한다.
우리는 두 정의의 상호보완적인 성격을 볼 수 있다.
절차적 코드는 기본 데이터 구조를 변경하지 않고 새로운 함수를 추가하기 쉽게 만든다. 반면에 객체 지향 코드는 기존 함수들을 변경하지 않고 새로운 클래스를 추가하기 쉽게 만든다.
반대도 사실이다. 절차적 코드는 새로운 데이터 구조를 추가하기 어렵게 만든다. 모든 함수들이 변경되어야 하기 때문이다. 객체지향 코드는 새로운 함수를 추가하기 어렵게 만든다. 모든 클래스들이 변경되어야 하기 때문이다.
모든 것이 객체여야 한다는 생각은 신화이다. 즉, 객체지향 프로그래밍이 만능이 아니며, 모든 문제에 적합한 해결책이 될 수 없다는 것이다. 객체지향 프로그래밍(OOP)가 강력한 도구인 것은 맞지만, 때때로 더 간단한 절차적 프로그래밍이나 데이터 구조 중심의 접근 방식이 더 적합한 상황이 있다.
따라서 상황에 맞게 적합한 접근 방식을 생각해 언어를 고르는 것이 중요하다.
📌 The Law of Demeter (LoD)
- 객체가 드러나는 순간 다 tightly connected 해지고, dependency가 올라가게 된다
- [P] 이렇게 되면, 뭐하나 수정하면 연쇄적으로 수정해야 하므로 문제가 된다
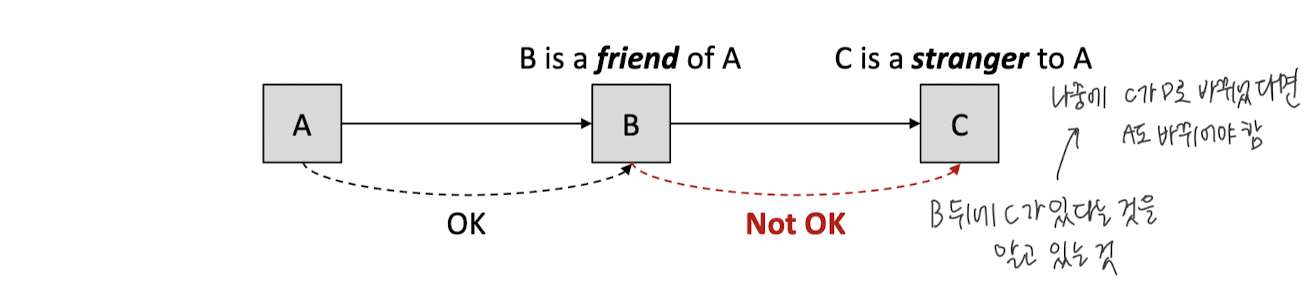
객체지향 프로그램의 디자인 가이드라인
- 각 객체는 자신의 절친하고만 대화해야 한다.
- stranger와 대화하면 안된다
여기서 절친은 바로 호출 가능한 메소드를 의미한다
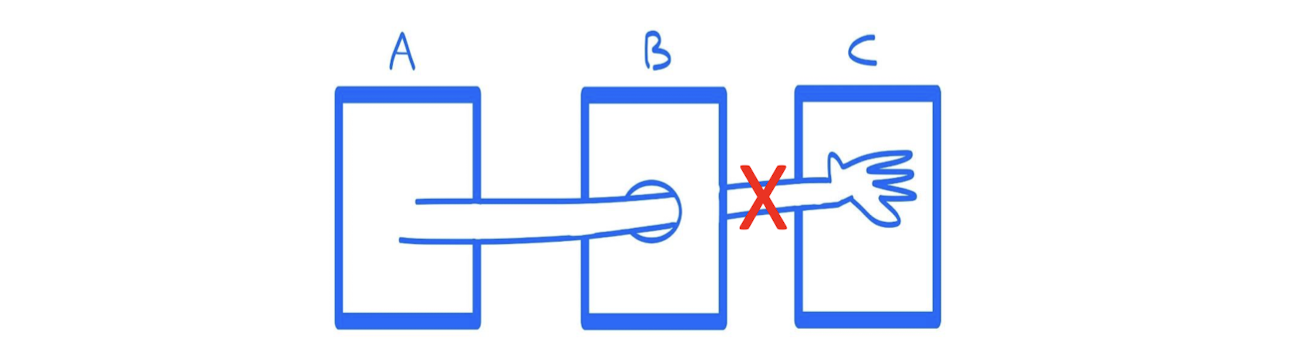
이 말은 객체 A는 객체 B를 호출할 수 있지만, 객체 A가 객체 C에 접근하기 위해서 객체 B를 거쳐가면 안된다는 것이다!
- A.methodOfB() (O)
- A.getObjectC().methodOfC() (X)
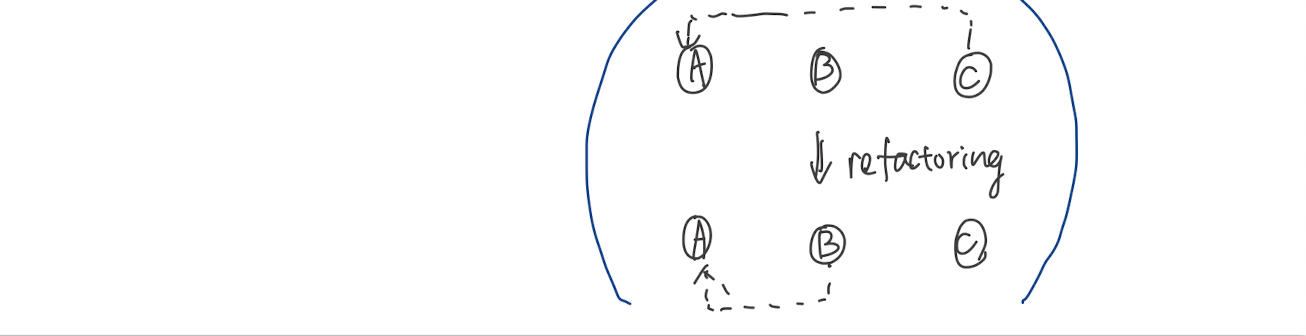
예시
class C {
void f() {
A a = new A(); //A안에 숨겨진 메소드 h()가 있자고 하자
a.h(); //ok
}
}
void g() {
D d;
void f(B b){
b.h(); //ok
d.h(); //ok
}
}
클래스 C의 메서드 f는 아래의 경우에만 메서드를 호출할 수 있다
- C (자기 자신)
- f에 의해 생성된 객체
- f에 인수로 전달된 객체 (파라미터 변수)
- C의 인스턴스 변수로 보유된 객체
이 네 가지는 허용되지만, 이 객체들을 통해 다른 객체를 생성하는 것은 허용되지 않는다! 즉, 메서드는 허용된 함수들로 반환된 객체에서 메서드를 호출하면 안된다
ex. java
String outputDir = ctxt.getOptions().getScratchDir().getAbsolutePath();
Data Transfer Objects
- Data Transfer Object (DTO)
- 데이터 구조의 본질적인 형태
- public 변수만 있고, 함수가 없는 클래스 형태로 구성
- 데이터베이스에서 데이터를 다른 시스템으로 전달하거나 변환할 때 주로 사용
- 다른 시스템과 통신할 때 특히 유용
- 데이터베이스의 원시 데이터를 응용 프로그램 코드에서 사용할 객체로 변환
- 예시
- 데이터베이스 -> Name, Age, City, Zip 필드를 포함한 행이 존재
- DTO -> 해당 데이터를 객체의 속성 (Name = "lee", Age = 25)으로 변환하여 다른 시스템으로 전다
public class Address {
private String street;
private String streetExtra;
private String city;
private String state;
private String zip;
public Address(String street, String streetExtra, String city, String state, String zip) {
this.street = street;
this.streetExtra = streetExtra;
this.city = city;
this.state = state;
this.zip = zip;
}
public String getStreet() {
return street;
}
public String getStreetExtra() {
return streetExtra;
}
....
}- 내부는 private으로 만들고
- 메소드는 public으로 만들고, 객체를 생성하여 사용한다
Conclusion
Objects vs. Data Structures
📍 객체 (Objects):
- 행동(메서드)**을 노출하고 데이터를 숨김.
- 새로운 클래스를 추가하기 쉬움.
- 기존 클래스에 새로운 행동(메서드)을 추가하기 어려움.
📍 데이터 구조 (Data Structures):
- 데이터를 노출하고 주요 행동이 없음.
기존 데이터 구조에 새로운 행동(함수)을 추가하기 쉬움. - 새로운 데이터 구조를 기존 함수에 추가하기 어려움.
📍 좋은 개발자는 상황에 맞는 최적의 접근법을 선택:
- 새로운 데이터 타입을 추가하려면 객체 사용.
- 새로운 행동(함수)을 추가하려면 데이터 구조와 프로시저 사용.
결론: 재사용성과 유연성을 극대화하기 위해 객체와 데이터 구조를 상황에 따라 적절히 활용해야 함.
