✒️ Understanding RAG
📌 Overview of RAG
🔻Fundamental papers in RAG
✔️ 발전과정
KNN-LM(2019) → REALM(2020) → RAG(2020)
- KNN-LM
- inference시에 explicit memory 사용
- decoder-only Transformers
- REALM
- Retrieval-Augmented Pre-training
- BERT Based
- RAG
- Retrieval-Augmented Fine-tuning
- Fine-tuning only
- BERT encoder, BART generator
🔻기본적인 생성형 LM 파이프라인
- User input → Generation
인풋에서 아웃풋이 나오는 과정에서 무슨 일이 일어나는지 정확하게 알 수 없다. 단지 언어모델의 어딘가에는 학습과정 때 주어진 지식들이 저장되어 있을 것이라는 것을 실험적으로 도출할 수 있을 뿐이다. 이것을 Parametric Memory 라고 한다. 파라미터에 저장되어 있기 때문에 이런 이름이 붙은 것!
이러한 모델에서 학습을 시키는데 막대한 비용이 발생하기 때문에 Outdated 되기 쉽다.
또한, 정확히 결과가 어떻게 도출되는지 알 수 없기 때문에 과정의 일부를 고쳐 성능을 고치고 싶어도 그러기 어렵다는 문제점이 있다.
🔻RAG 파이프라인
- Indexing → User input → Retrieval → Generation
RAG에서는 외부 메모리를 활용한다는 점이 가장 큰 차이점이다! = Non-Parametric Memory (기존 모델의 생성 프로세스는 언어모델의 내제적 지식인 paremetric knowledge에만 의존했다)
Indexing : 외부에서 사용할만한 데이터를 모아서 사용하기 쉬운 형태로 가공하는 과정
Retrieval : 가공해두었던 외부의 메모리를 보면서 User input과 유사한 것을 골라내 전달하는 과정
이렇게 전달받은 지식과 user input은 결합되어 In-Context Learning(특정한 맥락 내에서 필요한 정보를 바탕으로 학습하는 방식)의 형식으로 Generator에 전해지게 된다.
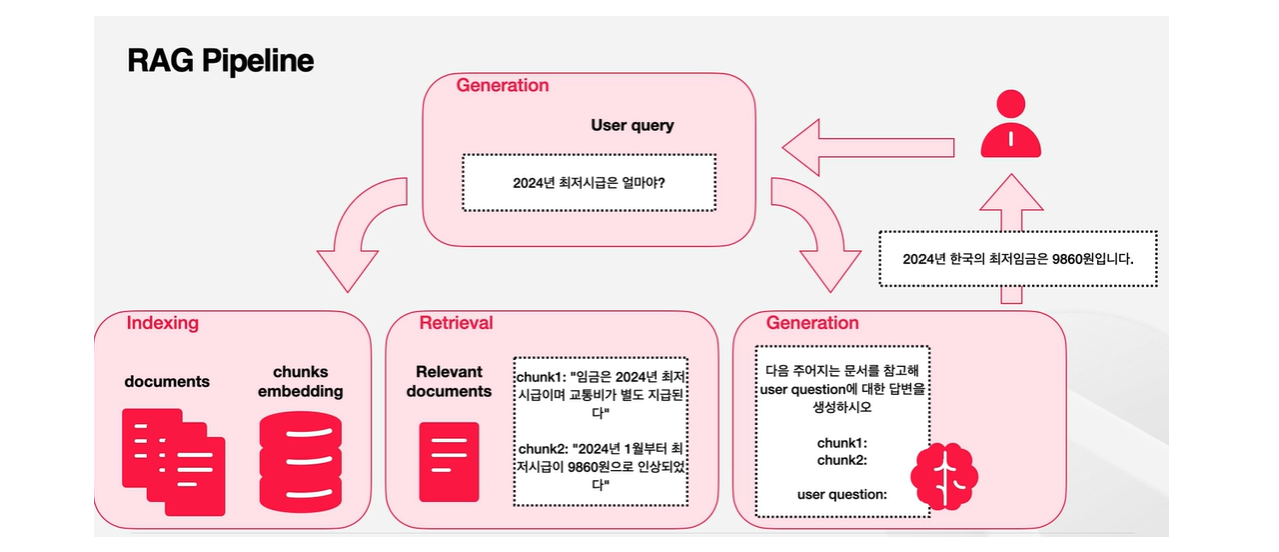
위 그림을 통해 과정을 더 자세하게 살펴보자.
처음 과정인 Indexing 과정에서는 각기 다른 문서의 길이를 다루기 쉬운 길이로 작게 나누는 과정인 'Chunking' 과정이 있다. 또한, Retrieval 과정에서 유사도를 알아내기 위해서 필요한 인베딩 유사도를 활용하기 위해 Indexing 과정에서 각 Chunk에 해당하는 인베딩을 미리 만들어 놓는다.
다음으로 Retrieval 과정에서의 목표는 Indexing 과정에서 잘 Chunking해 놓은 문서들 사이에서 사용자의 쿼리에 가장 도움이 될 수 있는 문서를 찾아내는 것이다. 가장 흔한 방식은 사용자의 쿼리와 가장 유사한 문서를 찾는 것인데, 꼭 유사도가 가장 높은 하나의 chunk를 찾는 것이 아니라 여러 개의 chunk를 활용할 수도 있다.
예를 들어, "변우석에 대해서 알려줘"라는 query가 있다고 해보자. chunk1에는 변우석의 나이와 키에 대한 정보가, chunk2에는 변우석의 출연작품에 대한 정보가 있을 수 있는데 이 경우 chunk1, chunk2를 모두 활용하여 답변을 할 수 있는 것이다.
마지막으로 Generation 과정에서는 유저의 query와 retrieval된 문서를 합쳐서 하나의 프롬프트를 합성하게 된다. 이 프롬프트는 LLM의 input으로 들어가 그에 따른 답변을 생성하게 된다. 외부 정보를 활용함으로써 더욱 사실 기반의 답변을 생성할 수 있게 된다.
🔻STATIC RAG
생각할 수 있는 가장 간단한 RAG 모델을 그려보면, TF-IDF와 BM-25가 있을 것이다.

-
TF-IDF (Term Frequency - Inverse Document Frequency): 문서에서 단어의 상대적 중요도를 평가하는데 사용
- 단어가 특정 문에서는 자주 등장하지만 다른 문서에서는 덜 등장하면 가중치를 부여한다.
- 예를 들어, 'RAG'라는 단어가 특정 강의에서 많이 등장하지만 다른 강의에서는 자주 등장하지 않아 가중치를 부여하고, '안녕하세요'라는 단어는 다른 문서들에서 모두 자주 등장하므로 가중치를 덜 부여하는 방식이다.
- 단어가 특정 문에서는 자주 등장하지만 다른 문서에서는 덜 등장하면 가중치를 부여한다.
-
BM-25 : TF-IDF와 유사하지만, 문서의 길이와 같은 다른 요소를 조금 더 섬사하게 고려하여 관련성을 측정
-
Generation은 추가적인 Fine Tuning없이 그냥 가져다 사용하는 경우를 생각해 볼 수 있다. 하지만 이렇게 되면 컴퓨팅 리소스가 많이 필요할 것!
이러한 모델을 보고 다양한 질문을 제기할 수 있을 것이다.
📍 What to retrieve
- granularity
- chunk 사이즈가 큰 경우 : chunk 사이즈가 더 커질수록 전달할 수 있는 정보의 양은 더 많아지지만 정보의 정확도는 떨어짐. 전달하는 내용이 많아진다면 사용자가 원하지 않는 내용도 포함될 가능성이 높아지기 때문
- chunk 사이즈가 작은 경우 : 정보의 정확도는 높아지지만 충분한 맥락을 반영하지 못할 수 있음
- source
- structrued
- Unstructured
- LLM generated
📍 When to retrieve
- single
- adpative : 유저의 input을 보고 retrieval이 필요한지 아닌지를 판단하여 선택적으로 retrieval를 하는 방법론
- 유저의 쿼리가 들어올 때마다 retrieve를 할 수 있겠지만, 대화형 쿼리라고 생각했을 때 모든 답변이 retrieve가 필요하다고 보기 어려울 수 있다. 이러한 경우 adapated 방법이 효과적일 수 있다.
- ex. '안녕'과 같이 의미없는 발화이거나, 내재적 정보로 충분히 추론할 수 있는 문제일 수도 있는 것! - multiple : iterative하거나 recursive한 retrieval를 활용하는 방법론으로, 한 번에 원하는 답변을 얻기 어려운 경우 사용
📍 How to use the retrieved information
- input
- intermediate layer
- output layer
⇒ 일반적으로 모델의 input에 retrieved된 정보와 user query를 결합해서 주지만, 중간/아웃풋 레이어의 정보를 제공하는 방식도 존재
📌 Overview of kNN-LM
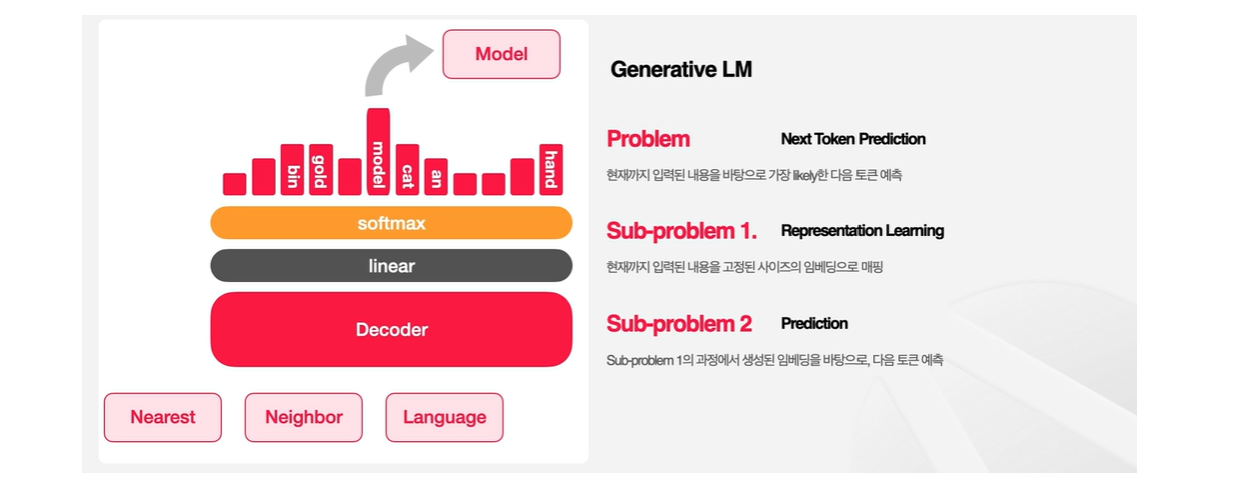
앞서 살펴보았던 Decoder-only Transformer 부분을 상기해보자.
📍 Transformer Decoder 블록
- 가장 하위 블록
- Masked Attention 블록으로, 입력된 토큰들 사이에 Self-Attention을 취해서 이 토큰들을 잘 재현할 수 있는 dense한 임베딩을 만드는 과정이다.
- Masked된 이유는 미래의 토큰은 참조할 수 없기 때문이다.
- 이로써 지금까지 들어온 토큰들의 의미를 나타내는 임베딩을 가지게 된다.
🔻 Self-Attention이란?
self-attention은 입력된 각 토큰이 다른 모든 토큰과 상호작용하며, 자신과 다른 토큰들 사이의 관계(유사도)를 계산하는 메커니즘이다.
동작 원리
- 각 토큰은 Query(Q), Key(K), Value(V)로 변환된다
- Query와 Key의 내적을 계산하여 각 토큰 간의 유사도를 구한다
- Softmax를 통해 유사도를 확률 값으로 정규화한다
- 이 확률 값을 Value에 가중 평균하여 출력 값을 생성한다
핵심은, 입력된 모든 토큰 간 상호작용을 고려하여 각 토큰의 임베딩을 업데이트한다.
🔻 Masked Attention이란?
Masked Attention은 Self-Attention의 변형으로, 미래의 토큰을 참조하지 않도록 제한을 둔 메커니즘이다.
이는 디코더에서 사용되고, 언어 모델이 순차적으로 예측하도록 한다.
동작 원리
- Self-Attention 계산 과정에서, Query와 Key의 유사도를 구할 때, 미래 토큰에 대한 유사도 값을 마스크(Mask) 처리하여 0으로 설정한다
- 이로 인해 현재 시점 이전의 정보만 사용하여 임베딩을 생겅하게 된다
핵심은, 마스크를 통해 순차적 정보 호름을 보장하고, 디코더가 아직 처리되지 않은 미래 정보를 보지 못하게 만든다.
📍 linear
- 앞서 만든 임베딩을 사용해서 다음 토큰을 예측해야 하는데, 이 임베딩의 차원은 우리가 사용하는 vocabulary의 차원보다 훨씬 작다.
- 따라서 차원을 맞춰줄 linear layer가 필요한 것!
📍 softmax
- linear layer의 결과가 softmax에 한 번 더 들어가서, 토큰별로 input으로 받은 맥락상에서 다음 토큰이 해당 토큰이 될 가능성을 나타내게 된다.
- 각 토큰들의 확률이 도출되는 것!
- 가장 확률이 높은 Likely한 토큰을 선택할 수 있게 된다.
👉 kNN-LM에서는 이전의 맥락에 비추어 다음 토큰을 예측해야하는 문제를 두 가지의 Sub-Problem으로 분해한다.
1. Representation Learning
이전의 맥락을 이해하는 부분으로, 현재까지 입력된 내용을 고정된 사이즈의 임베딩으로 매핑한다. 즉, 입력된 내용을 잘 나타낼 수 있는 벡터를 찾는 문제이다.
2. Prediction
맥락이 주어졌을 때 다음 토큰을 예측하는 문제다.
❗️ 여기서 Key Idea는 Representation Learning이 Prediction보다 더 쉽다는 것이다!
kNN-LM 구조의 핵심은 다음 토큰에 대한 예측을 만들기 위해 모델의 output distribution뿐 아니라 이전의 임베딩들에 대한 기억을 활용한다는 것이다!
학습 과정에서 등장했던 토큰들과 그에 해당하는 임베딩을 data store에 저장해놓고, inference 단계에서 다음 토큰을 예측할 때 비슷한 문맥에서 사용된 단어들을 data store에서 찾아서 확률에 참고할 수 있다. 이런 접근법은 드물게 등장하는 토큰들을 다룰 때 특히 효과적이라고 한다.
data store에는 토큰과 임베딩이 저장되어 있는데, key-value 페어(pair)로 이루어져 있다. value는 토큰, key는 임베딩이다. key를 통해 접근을 하기 때문에 임베딩 값을 통해 value인 토큰을 찾아가는 형식이다.
다음 토큰을 예측하는 과정에서 kNN-LM은 두 가지 방법을 결합한다.
1. 기존과 동일하게 문장을 Decoder에 넣고 output을 다시 Linear Layer와 softmax에 넣는 것이다.
이렇게 하면 일반적인 단어 모델처럼 다음 단어를 예측할 수 있다.
2. kNN-LM은 현재 inference 해야할 context가 가진 임베딩과 기존의 data store에서 가지고 있던 임베딩과 비교한다. 그리고 현재 가진 임베딩과 가장 거리가 가까운 K개의 key-value 상을 뽑아낸다. K-Nearest Label을 개선하는 것!
k개가 선택될 확률은마찬가지로 거리에 기반해 계산해서 기존에 계산해두었던 Next Token Prediction 확률과 Linear Interpolation(선형 보간법) 방식으로 결합한다.
cf. 선형 보간법은 끝점의 값이 주어졌을 때 그 사이에 위치한 값을 추정하기 위하여 직선 거리에 따라 선형적으로 계산하는 방법
🔻 Next Token Prediction
이렇게 해서 KNN 모델의 Next Token Prediction 방식에 대해서 간단히 더 살펴보자. Datastore를 구축하는 과정을 살펴보도록 하자.
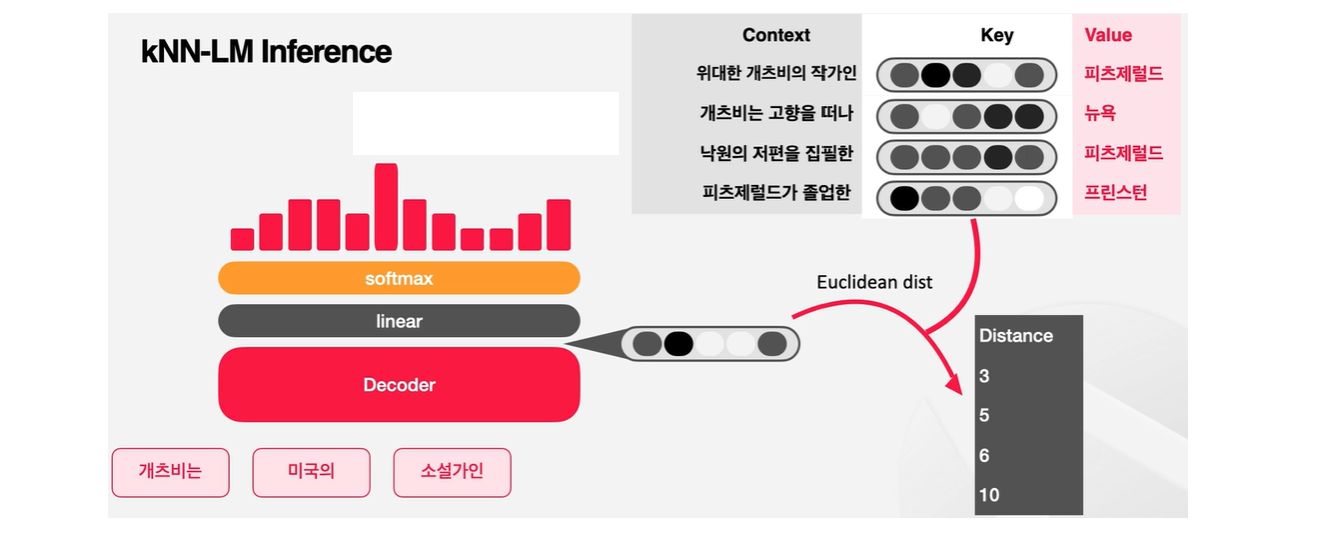
'게츠비는', '미국의', '소설가인' input을 보고 다음 토큰인 '피츠제럴드'를 예측하는 것이 목표이다.
다음 사진에서의 representation을 생성하는 함수를 f라고 해보면, kNN-LM에서는 이 타겟 토큰과 함수 f를 지난 임베딩을 가지고 key-value 데이터 스토어를 구축한다.
kNN-LM에서는 모든 학습 데이터의 토큰들에 대해 이 과정을 거쳐서 임베딩 data store를 생성하게 된다.
inference 과정에서 input인 세개 토큰이 들어왔을 때 모델은 다음 단어를 예측해야 하는데, 이때 data store를 참고하는 것이다. data store에 이미 기존의 모든 context embedding과 target 토큰을 가지고 있다.
만약 현재 가지고 있는 context와 과거의 어떤 context가 의미상으로 매우 유사하다면 다음에 올 토큰이 유사할 가능성도 높을 것이라고 가정할 수 있다.
kNN-KM은 이런 아이디어를 가지고 현재 context에서 구해진 임베딩과 data store에 있는 임베딩과의 거리를 구한다. (ex. Euclidean Distance)
다음 스탭은 현재의 context와 가장 유사한 k개의 이웃 임베딩을 뽑는 것이다.
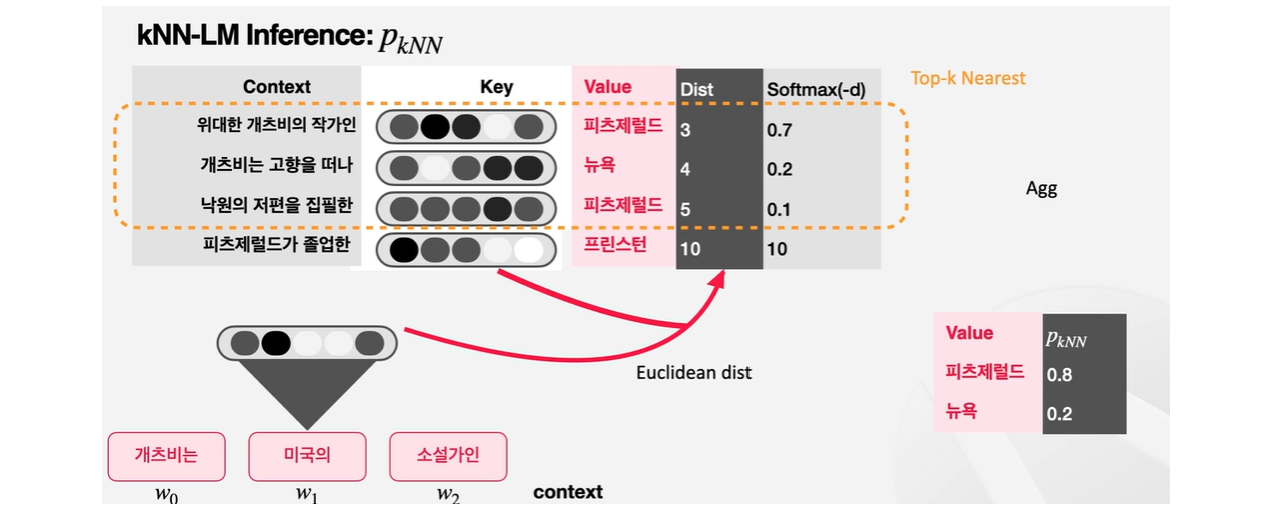
value별로 softmax를 거친 값을 더해주면 PkNN값이 도출되어 value별로 확률이 도출된다.
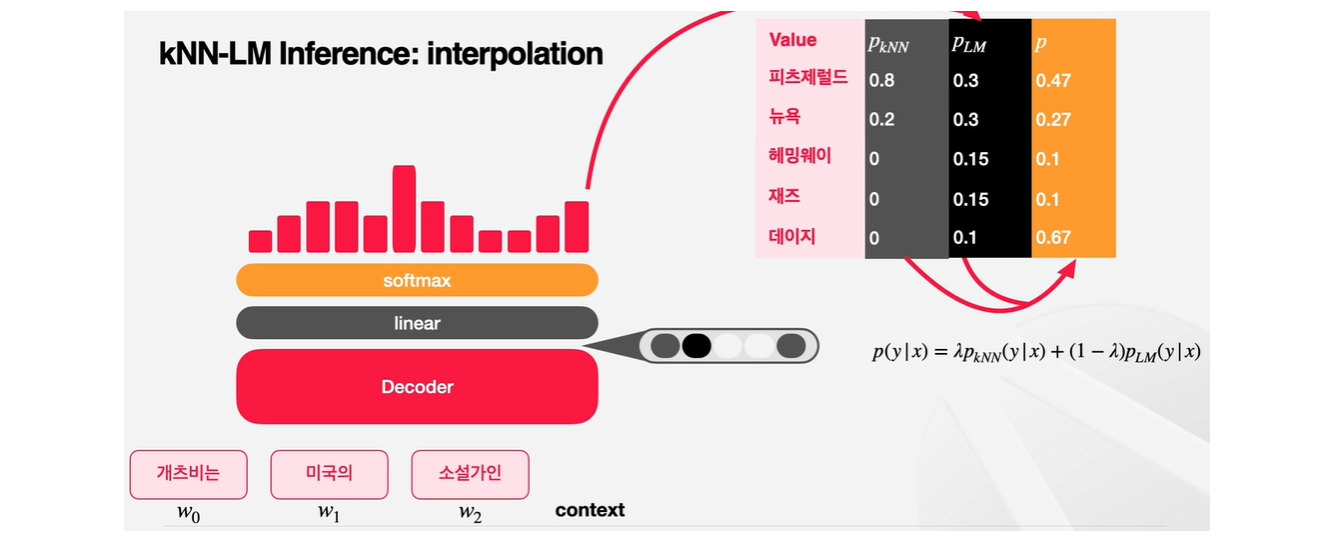
kNN-LM은 단순히 데이터스토어를 통해서만 다음 확률을 계산하는 것이 아니라, 기존의 언어모델식 접근법과 k-nearest layer 방법론을 모두 사용하고 있다. PLM에 해당하는 부분이다.
최종적으로 Linear Interploation 과정에서 PkNN과 PLM 둘 사이의 확률을 조정하여 p라는 최종 확률을 얻게 되는데 이때 람다를 활용한다.

끝으로, kNN-LM의 objective은 perplexity를 낮추는 것이다. perplexity는 언어모델이 다음 단어를 예측할 때 평균적으로 몇 개의 후보를 고려하는지를 나타내는 값으로, 생성 성능을 평가하는데 쓰이는 지표다.
이 지표를 기반으로 kNN-LM 모델을 평가해보았을 때 기존의 모델보다 훨씬 더 좋은 성능을 보여주고 있다.
📌 Overview of REALM
- REALM : Retrieval-Augmented Language Model Pre-Training의 약자
기존에는 retriever는 비지도학습으로 진행을 한 다음 document reader 부분에서 지도학습을 진행을 했는데, REALM은 retriever에서부터 지도 학습을 진행을 한다.
🔻Overview
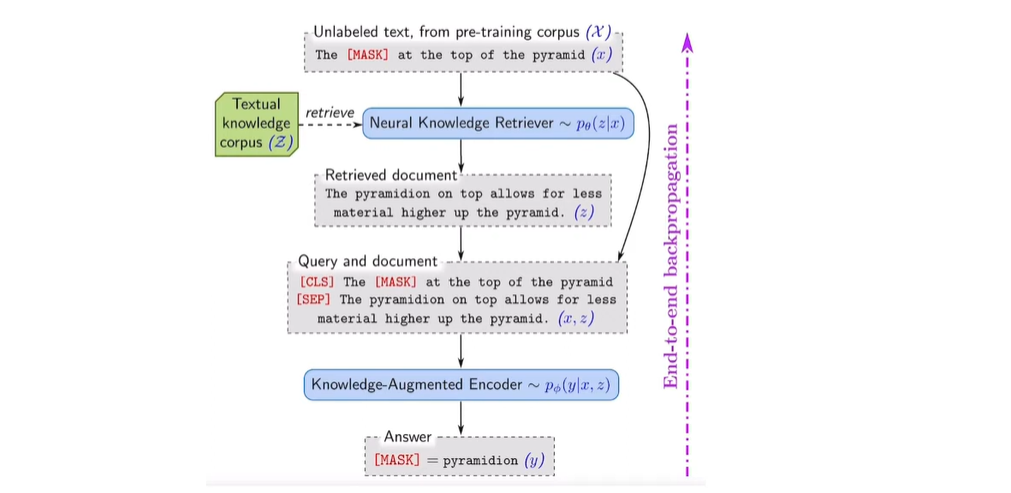
다음 그림은 REALM의 개요를 한 눈에 보여주며, 크게 두 가지를 시사하고 있다.
-
Retriever에서부터 학습을 하면 QA의 성능이 매우 향상될 수 있다.
-
한 번에 학습하는 Joint Training을 진행할 경우 매우 좋은 성능을 보일 수 있다.
- Joint Training을 하기 위해 좋은 수단으로서 Pre-training을 수행함
따라서 Retriever를 잘 학습할 수 있는 방법 뿐만 아니라 Retriever와 Reader를 한 번에 통합하여 사용할 수 있는 프레임워크를 제시했다고 볼 수 있다.
🪄 REALM의 내용을 간략하게 정리를 해보자면...
-
TD;DR
- Retriever도 학습하면 QA 성능이 매우 높아짐
- Retriever와 Reader를 한 번에 학습(Joint training)할 수 있음
- Retreiver와 Pretraining에서 수행하는 모델 제안
-
Main Contribution
- Retriever와 Reader를 한 번에 학습하는 End-End 모델
- Query를 넣어(input), 답(output)을 찾는 과정을 두 단계로 분리
- Neural Knowledge Retriever
- Query → Query의 답이 될만한 document를 찾음 - Knowledge-Augmented Encoder
- Retrieved Document → Answer
- Neural Knowledge Retriever
- Pretraining과 Fine Tuning(ODQA)을 모두 진행함
이처럼 REALM은 사용자의 질문에 해당하는 query, 즉 input에서부터 output인 answer를 도출을 하는 과정을 두 가지로 분리한다. 이 두 가지 과정이 완전히 독립적인 모델을 만드는 것이 아닌, 과정만 분리한 것임을 유의하자!
첫 번째 과정인 Neural Knowledge Retriever에서 답이 될만한 document를 찾는 과정 자체가 retriever를 의미하고, 이때 retriever를 학습한다는 것이 중점적인 부분이다.
두 번째 과정인 Knowledge-Augmented Encoder는 Reader 파트를 진행을 한다.
🪄 다시 위 그림으로 돌아가 위에서부터 과정을 차근차근 살펴보자.
Unlabeled text, from pre-training corpus
-
pre-training을 한다는 의미는 기존에 있는 Mask Language Modeling을 적극적으로 활용을 하되, 이 Mask Language Modeling으로 학습을 시키는 것이 아닌, 이 자체가 output을 도출하는데 도움이 될 수 있는 방향으로 진행된다는 의미다.
-
unlabeled text는 label 되지 않은 토큰과 mask 되어있지 않은 토큰이 들어오게 되는 것인데, pre-training을 할 수 있는 형태가 되기 위해 mask라는 토큰으로 특정 토큰이 변환되는 과정이 있게 된다.
-
또한 [MASK] 토큰에 오게 될 토큰을 예측하는 LLM 과정에, MASK 토큰이 question에 대한 답변을 할 수 있는 형태로 만들어주는 과정이 있다.
-
이처럼 동일한 Mask Language Modeling이라고 하더라도 목적을 다르게 하고 있고, 여기서의 목적은 question-answering을 잘 푸는 모델을 만드는 데에 있다.
그렇다면 어떤 토큰에 Mask를 진행하는 것이 가장 좋을까?
Mask를 부착하는 방법론 자체가 중요하게 됨!!
Mask라는 토큰에 answer가 오는 과정을 찾아내기 위해서 retriever 부분을 학습을 하게 된다고 이해하면 된다.
그림에서 표현된 수식을 살펴보면, x가 조건(condition)이 되고 그 조건 안에서 z 값을 찾아가는 과정이다. z는 Textual knowledge corpus라는 Z라는 값에서부터 retrieve를 진행하여 retrieved document로 얻을 수 있다.
z로부터 Query와 document를 input으로 받게 되는데, 해당 과정에서 CLS와 SEP 토큰이 붙여져 모델이 이해할 수 있는 형태로 바꿔주는 과정을 거치게 된다.
y라는 값을 학습할 때는 x,z 모두를 condition으로 걸어서 학습하게 된다. 즉, y라는 값을 도출하기 위해 unlabeled text에 해당하는 x와, retrieved하여 얻은 결과 값인 retrieved document, 즉 z가 필요하다.
이 과정을 한꺼번에 진행하고 End-to-end backpropagation을 통해 answering을 도출하고자 하는 것이 이 모델의 주안점이다.
🔻Method
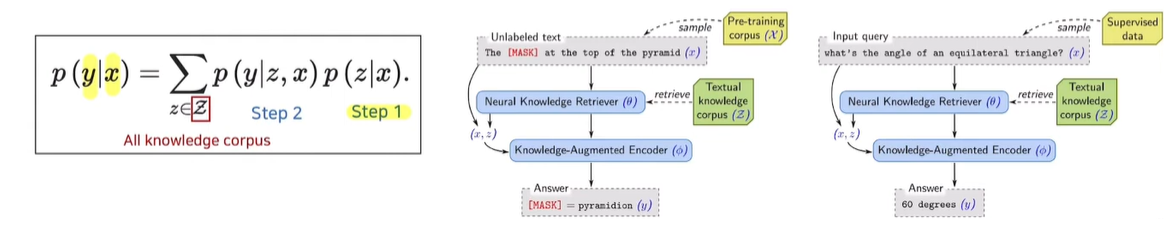
📍 Main Idea
- Original QA : Query(x)를 넣어 Answer(y)를 찾겠어
- REALM
- Step 1 : Query(x)를 넣어 Retrieved document(z)를 찾고
- Step 2 : Query(x)와 Retrieved document(z)를 넣어 Answer(y)를 찾겠어
z는 all knowledge corpus에 포함된 값이다.
생각을 해보면 모든 knowledge를 가지고 있는 것을 retrieve를 사실상 할 수 없기 때문에 어떤 방식으로 전체 corpus를 대응할 수 있는 값을 찾아내는 과정이 중요한데 뒤에서 더 살펴보겠다.
📍 Model Architecture
- Neural knowledge retriever (Step 1)
- Retriever는 dense inner product model로 정의됨 == "Query와 relevance scrore가 가장 높은 document를 찾겠다"는 의미

보통 유사도가 높은 Top k개 문서를 추출할 때 distance를 계산하여 유사도를 계산하는데, 여기서는 'relevance score'를 따로 정의하여 이를 기반으로 Top k개 문서를 뽑아낸다.
모든 corpus를 돌아다니며 계산을 할 수 없기 때문에 relevance score가 높은 Top k개 문서로부터 x에 대한 y값을 계산하겠다는 의미가 된다.
Top K를 approximate 하는 과정에서 Maximum inner Product Search라는 방법론을 논문에서 자세히 설명하고 있는데, Top k개를 가져오는 방식이 전체 corpus를 활용했을 때와 비슷한 결과값을 도출한다, 즉 대표성을 띈다는 내용을 담고 있다.
🪄 이제 수식 아래 내용을 살펴보자.
① Distribution, relevance score
-
x를 통해서 z를 어떻게 찾아낼 것인가에 대한 distribution을 구성
-
f라는 function을 통해서 relevance score를 정의하고 있는데, 임베딩 값인 input값과 document값인 z값의 임베딩을 구한 다음 이 임베딩을 닷-프로덕트라는 과정을 통해 relevance score를 도출
-
similarity를 찾는 것과 매우 유사!
② BERT style transformer
- encoder는 BERT 스타일 transformer
- 문장이 들어왔을 때 CLS와 SEP를 붙여서 어떻게 문장과 쿼리를 구분하는지에 대한 내용
③ Embeddings
- : x값이 들어왔을 때 BERT를 통과하여 CLS값이 input에 있는 matrix multiplication을 통해 임베딩을 진행
- : 타이틀과 해당 context를 모두 사용하여 를 거친 후에, 이 BERT의 CLS 토큰과 기존 matrix를 모두 multiplication 하는 과정을 통해서 embedding을 뽑아내고 있음
- Knowledge-Augmented Encoder (Step 2)
- Retrieved documents와 query를 함께 사용하여 정답을 찾아내며, pre-training과 fine tuning 과정이 살짝 다름

🪄 이제 수식 아래 내용을 살펴보자.
① Pretraining (MLM)
- x 토큰이 noise가 들어가 mask 토큰으로 대체되었을 때, 이 mask가 무엇인지 찾아내는 방식으로 예측을 수행
- 이 방식은 기존과 차이점을 가짐 (뒤에 설명)
② Open QA Finetuning
- supervised learning
- Span 예측을 통해서 query가 들어왔을 때 query에 알맞는 document로부터 답이 될 수 있는 부분의 START 토큰과 END 토큰의 자리를 예측한 다음, span 예측을 하여 얻고자 하는 답변의 위치를 알아내는 것
- Sailent span masking
- Named entity를 사용하여 sailent spans 생성 (ex. "United Kingdom", or "July 1969")
- 해당 masking strategy의 목적은 정답일 가능성이 높은 Entity들을 Query이 Answer로 간주하는 것!
- Pretraining REALM 과정에서 [MASK] 자리에 들어올 값을 Top K Retriever 과정을 통해 찾아내는 것이 포인트
📍 Training Process
- Unsupervised (Pretraining)
- Supervised Training (Fine Tuning)
- QA Task
- Fine Tuning은 QA Task의 직접적인 답변이 될 수 있는 값을 가져옴
🔻 Performance / Result
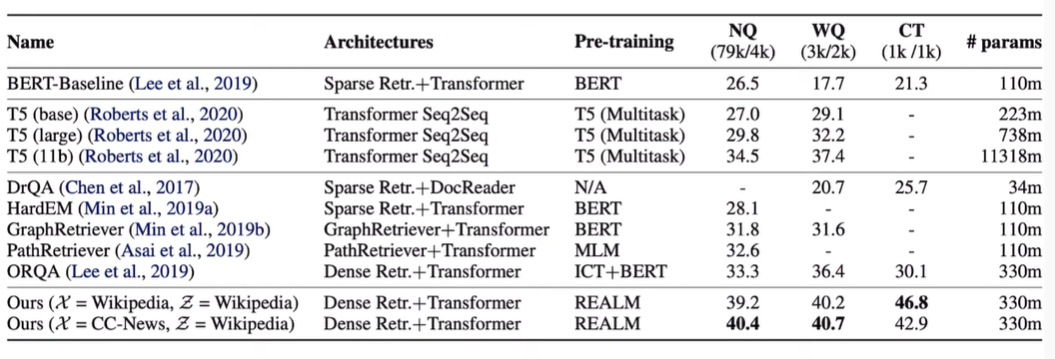
다른 각종 방법론보다 성능이 좋음을 확인할 수 있다.
또한, 파라미터 사이즈가 BERT에 비해 증가하긴 하였지만, 증가한 파라미터 사이즈 대비 성능이 매우 높아졌기 때문에 좋은 성능을 보이는 강건한 모델임을 알 수 있다.
📌 RAG
우선 RAG는 REALM과 매우 비슷한 모델이지만, pre-training을 진행하지 않고 Fine Tuning만 진행한다는 차이가 있다.
또한, REALM의 encoder 자리에 generator를 사용한 Generative Model이라는 점에서도 차이가 있다.
전체적인 구조는 REALM과 매우 유사하여, query가 들어오면 가지고 있는 지식 데이터 중에서 쿼리와 유사한 것을 찾는다. 다만 넘겨주는 대상은 이번에 Reader 아닌 Generator이다!
Generator는 input query와 retriever가 전달한 document를 받고 적절한 대답을 생성한다. 이전의 릴룸(REALM) 모델에서는 다큐멘트 안에서 정답 부분을 추출했지만, Generator는 직접 정답을 생성한다는 차이가 있다.

전체적인 식 또한 REALM과 유사하지만, Generator는 각 토큰을 예측할 때 input query 뿐만 아니라 자신이 직전에 예측한 토큰까지 함께 받아들인다는 점에서 차이를 보인다.
-
Retriever:
- query와 document에 대한 encoder 역할을 각각하는 BERT 모델을 가지고 있고
- 이렇게 나온 결과 사이에 inner product를 취해서 유사도를 선별한다.
-
Generator:
- BART 모델(BERT아님!)을 기반으로 한다.
- BART 모델은 Encoder-to-Decoder 구조로 denoising 방식으로 학습된 생성형 모델이다.
- input이 들어오면 인코딩을 한번 거치고, 인코딩된 결과와 직전까지 생성된 토큰을 통해 디코딩하는 모델이다.
- RAG에서는 input query와 retriever에 대한 document z를 concat해서 BART에 넘겨주게 된다.
- BART 모델(BERT아님!)을 기반으로 한다.
🪄 RAG의 Generator는 두 가지 옵션이 주어진다!
- RAG-Sequence Model
- 모델이 하나의 시퀀스를 생성하는 동안 쭉 하나의 다큐먼트를 참조하는 방식
- 문서를 고정하고 시퀀스를 쭉 생성하는 과정으로, document1을 보고 쭉 생성하고, document2를 보고 쭉 생성하는 과정을 Top K개 동안 반복한다
- 그리고 모든 시퀀스에 대한 확률 분포를 고려한다

식에서도 볼 수 있듯이 Top K가 아닌 문서의 확률이 거의 0이라고 가정하고 Top K개 문서에 대해서 마지널라이즈를 한다.
각 문서가 retriever에 대한 확률에 해당 문서를 가지고 시퀀스를 생성할 확률이고, 만값이 PYX가 되겠죠!
- RAG-Token Model
- 모델이 하나의 시퀀스를 생성하는 동안 쭉 하나의 다큐먼트를 참조하는 방식
- 위 방법과 반대로 개별 토큰을 생성할 때 모든 문서를 고려하고, 또 다음 토큰을 생성할 때 이전에 생성한 토큰과 또 모든 문서를 조회한다

이전과는 마지널라이즈 시점이 다르다고 볼 수 있다! 따라서 이전과는 시그마와 PY의 순서가 반대인 것이다.
🔻 Method
RAG의 트레이닝 방식은 REALM과 같이 Joint Training이다. 다만 쿼리 인코더와 generator만 학습하고, document encoder는 학습하지 않는다. document encoder를 학습하는 과정에서 파라미터가 계속 변하는만큼 결과가 되는 임베딩 값도 계속 변하기 때문이다. 임베딩이 계속 바뀌니 모든 다큐먼트에 대해 임베딩을 주기적으로 업데이트 해야되는데, 이 과정이 불필요하게 computational cost를 사용한다고 판단한 것이다.
✔️ Training loss
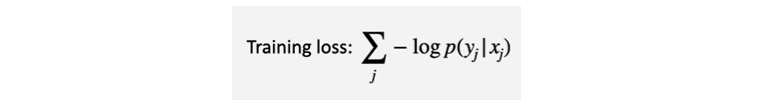
- j : 학습 데이터에 있는 input, output pair
- : i번째 input
- : i번째 정답 (output)
✔️ Decoding: RAG-Token Model
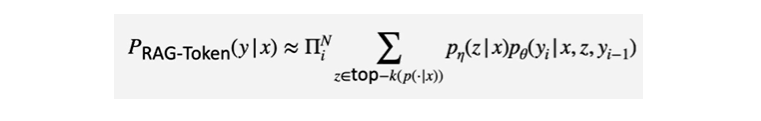
RAG-Token Model는 리마인드를 해보자면 토큰을 하나씩 생성하고 생성할 때마다 Top-K document들을 모두 참조하는 식의 모델이었다.
그럼 모델이 내뱉는 확률값은 어떻게 해석해서 결과 시퀀스를 만들 수 있을까?
앞서 REALM 모델에서는 이 과정이 수월했다. 결과 값이 하나의 토큰 혹은 Span으로 단순하게 나왔기 때문이다.
하지만 generative model은 생성된 이전 토큰이 다음 토큰의 생성에도 영향을 주는 좀 더 어려운 구조를 가지고 있다.
📍 Greedy
가장 직관적으로 생각나는 알고리즘은 Greedy Algorithm일 것이다. 각 시점에서 가장 확률이 높은 토큰을 찾아가는 방식이다.
예를 들어, 'open'이라는 토큰 뒤에 'domain','engine','sentence','world'라는 후보가 있을 때 'world'가 가장 높은 확률을 보인다면 world를 선택하고, 이후에 open world를 prefix 삼았을 때 가장 확률이 높은 것이 application이라면 또 그것을 선택하고 하면서 end of sentence를 만날 때까지 과정을 이어간다.
그런데 이런 식으로 움직인다면 한 번이라도 잘못된 선택을 하느 순간 바로 결과가 겉잡을 수 없이 틀어지게 될 것이다! 정답 시퀀스가 매 토큰마다 가장 높은 확률을 가진다는 보장이 없다. 특정 순간순간마다 가지는 확률이 다른 모델과 비슷하거나 조금 떨어져도 최종 완성되는 시퀀스는 높은 확률을 가질 가능성도 당연히 존재할 것이기 때문이다.
📍 Exhaustive
Exhaustive Search는 가능한 모든 값에 대해서 검증해보는 방식이다.
예를 들어, 'open' 다음에 올 수 있는 토큰 후보들을 모두 늘어놓고, 또 그 토큰에서 파생될 수 있는 후보들을 모두 모아놓고 마지막까지 계속 이런식으로 늘어놓은 다음 가장 높은 시퀀스를 찾는다.
이런식으로 진행을 한다면 중간중간 과정에서는 다른 토큰들에 비해 조금 낮은 확률을 가졌지만, 결과적으로 가장 높은 확률을 가지는 시퀀스를 놓칠 일이 없어지게 된다.
하지만 이런 식의 방식은 모든 간으한 토큰들에 대해서 계산하는 것이기 때문에 computing cost가 너무 크다는 단점이 있다.
좀 더 합리적인 방식이 필요한데 그것은....
📍 Beam Search
바로 Beam Search로, Greedy Search와 유사하지만 매번 제일 확률이 큰 하나만 선택하고 나머지를 버리는 대신에 매번 N개의 선택지를 고려한다.
N=2일 때 Beam Search 과정을 따라가보자.
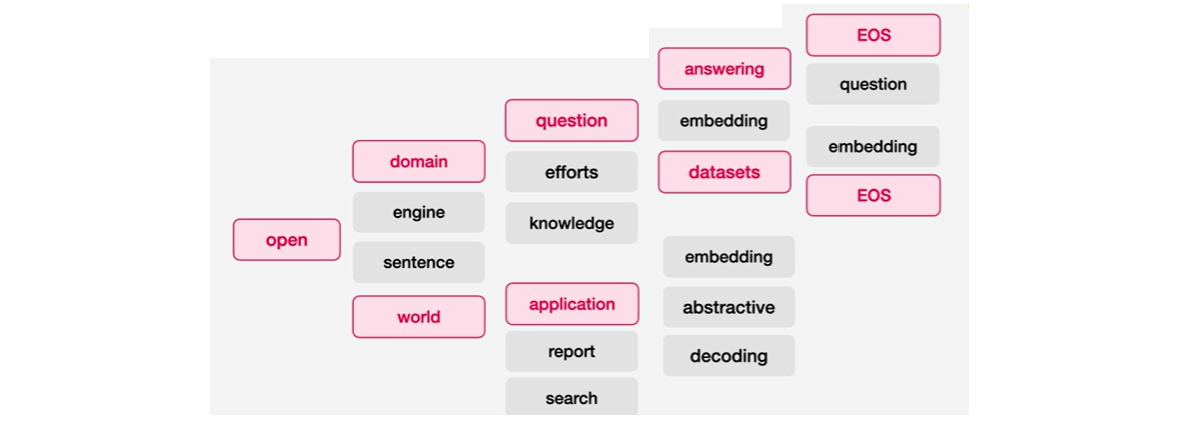
예를 들어, 'open' 뒤에 4개의 토큰이 있다면 확률이 높은 두 개의 토큰을 후보로 두고 이 두 개의 토큰에서 다음 토큰으로 뻗어나간다.
✔️ Decoding: RAG-Token Model
이제 RAG-Sequence Model에 대해 알아보자.
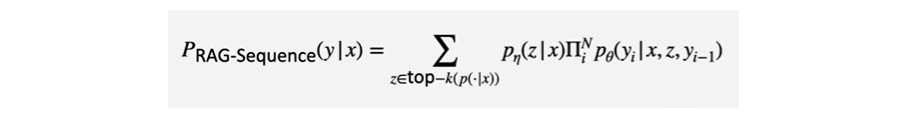
RAG-Sequence 모델은 Top-K개의 각각의 문서에 대해 시퀀스를 생성하는 모델이었다. 그러면 이 결과 값을 어떻게 디코딩 할 수 있을까?
document가 2개인 예제를 통해 살펴보자.

1. z1, z2의 document가 있을 때 각각 시퀀스가 생성된다.
- 각각 시퀀스 후보가 있을텐데 눈문에서는 이를 hypothesis라고 한다
- 어떤 시퀀스는 여러 document에서 중복이 될 수 있고, 어떤 시퀀스는 특정 document에서만 나타날 수 있는데 어떤 document에 속해있는지는 중요하지 않고 내용에 따라 hypothesis를 넘버링한다
- 예를 들어, 'BART is seq2seq model'라는 모든 시퀀스는 hypothesis y2이고 'attention is all you need'라는 시퀀스는 hypothesis y4이다.
2. 문서가 주어졌을 때 각 hypothesis가 생성될 확률을 구한다.
- 하지만 이 과정이 쉽지 않은 이유는 후보에 나오지 않은 선지에 대한 확률을 알지 못하기 때문이다.
- 예를 들어, document z3에 y2가 등장하지 않았다면 확률을 구할 때 그 값이 필요하지만 계산하지 못하게 됨!
🪄 논문에서는 이 문제에 대해 **2가지 해결책**을 제시한다.
1) Solo Decoding
- hypothesis y가 등장하지 않은 z들을 추가로 모델에 넣어서 다시 확률을 계산
하지만 이러한 방식도 후보가 많아질수록 computing cost가 높아지게 될 것이다.
2) Fast Decoding
위 문제를 해결하기 위해 추가적으로 도입된 방식!
- 등장하지 않은 y,z 상일 경우에 모두 확률이 0이라고 보는 방식
이렇게 하면 추가적인 계산 필요 x - 빠르게 디코딩 가능!
🔻 Performance / Result
- Open-Domain QA Test Scores
- REALM보다도 잘 작동
- REALM보다도 잘 작동
- Extractive QA
- 단순히 지문에 있는 정답을 추출하는 능력 뿐만 아니라 여러 지문을 이해하고 대답을 합성할 수 있는 능력을 평가하는 과제
- Jeopardy는 entity에 대한 사실을 통해서 entity를 예측하는 질문!
- RAG-Token 방식에서는 토큰마다 다른 문서를 참고할 수 있기 때문에 성능이 높게 나옴
논문에서 Test한 결과에 대한 내용을 살펴보면, 문서에 대한 참조의 정도가 새로운 정보 조각의 맨 첫 토큰에 몰려있다는 점이 나와있다!
여기서 알 수 있는 점은 문서가 생성의 길잡이를 하고, 이후의 생성은 parametric memory에 좀 더 의존한다는 것이다. 즉, parametric memory와 non-parametric memory가 같이 일하게 되는 것이다.
- Jeopardy QA
- Human evaluation도 진행됨
- 사실에 기반했는지와 구체적인지 모두에 대해서 RAG와 BERT 중 RAG가 낫다는 응답이 가장 높았다
- Index hot-swapping
- 2016년 12월 데이터와 2018년 12월 데이터를 리트리벌 소스삼아 평가를 진행 : "Who is {position}?" 질문으로 평가
- 평가 대상 : 2년 동안 교체된 각국의 지도자 리스트
- 동년의 데이터를 가지고 실험을 했을 때는 괜찮은 성능을 보이지만, 서로 index를 바꾸었을 때는 정확도가 형편 없어짐
- 잘못된 소스를 전달했으니 당연한 결과이지만, RAG 스타일 시스템에 있어서 정확한 retrieval 중요도를 보여준다고 할 수 있다.
✒️ 최종정리
| kNN-LM | REALM | RAG | |
|---|---|---|---|
| retrieval | inference | Pre-train+Fine-tuning | Fine-tuning |
| retrieval object | token | document | document |
| type | generative | extractive | generative |
| evaluation | perplexity | open-domain QA | open-domain QA |
📌 Limitations of LLMs
-
Hallucination : 사실이 아닌 정보를 생성하는 것
- 생성형 언어 모델의 본질이 이전의 토큰들을 기반하여 그럴듯한 다음 토큰을 생성하는 것이기 때문에, 자신이 학습하지 않아 '모르는' 내용이더라도 답변을 내놓게 됨
-
Outdated Knowledge : 모델이 띄는 정보가 최신성을 띄기 어려움
- LLM의 knowledge는 주기적으로 업데이트하기가 어려움. LLM을 학습하는 데에는 매우 많은 컴퓨팅 리소스와 시간이 들어가기 때문.
-
Untraceable reasoning process : 모델 자체가 블랙박스! 우리는 모델의 아웃풋을 볼 뿐 모델이 어떠한 이유로 특정 결과를 냈는지 볼 수 없음
-
Bias : LLM은 학습되는 데이터셋에 있는 분포를 그대로 학습하기 때문에 훈련 데이터에 존재하는 편향이 모델의 출력에 그대로 반영될 수 있음
출처
- 패스트캠퍼스 강의
- 고려대학교 산업경영공학부 연구실 논문 정리 발표 영상 : https://www.youtube.com/watch?v=gtf770SDkX4
