
✒️ 생성형 LLMs 개요
🔻Language Models
- 언어 모델은 자연어에 대한 확률 모델이다.
- vocabulary에서 만들어 낼 수 있는 특정한 단어 시퀀스가 주어졌을 때 이에 대해 확률을 계산할 수 있는 모델!
- 식 :
✔️ 자연어 모델이 사용되는 분야 (Natural Language Processing)
📍 NLU
- 자연어 이해 : 주어진 텍스트를 모델이 읽고 내용을 이해해서 과제를 해결하는 문제
📍 NLG
- 자연어 생성 : 모델로 하여금 말이 되는 자연어를 생성하게끔 하는 태스크
✔️ Timeline of Generative LM Development
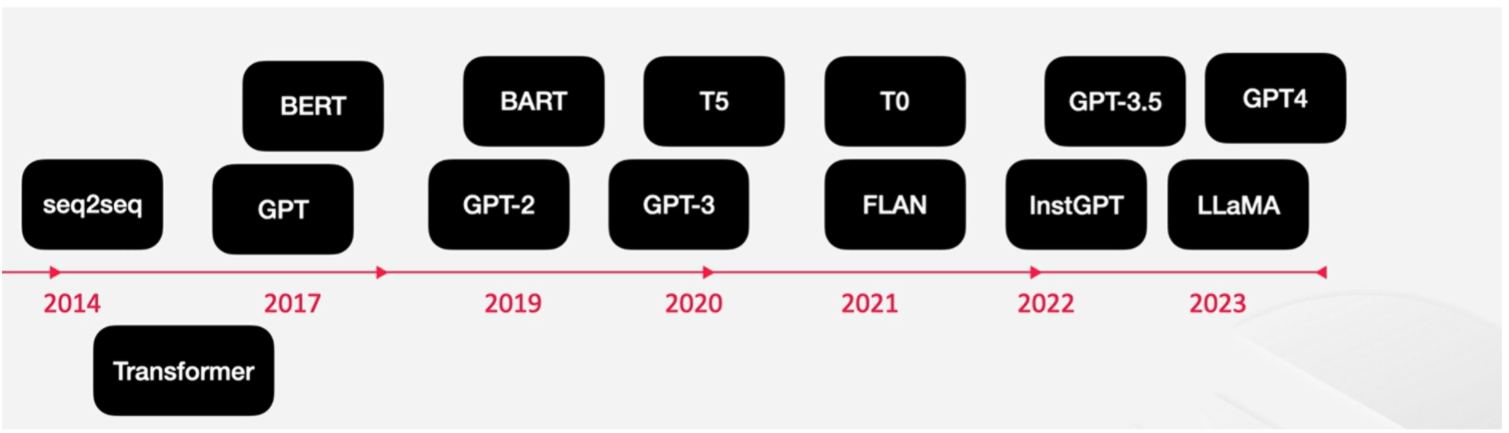
📍Seq2Seq
-
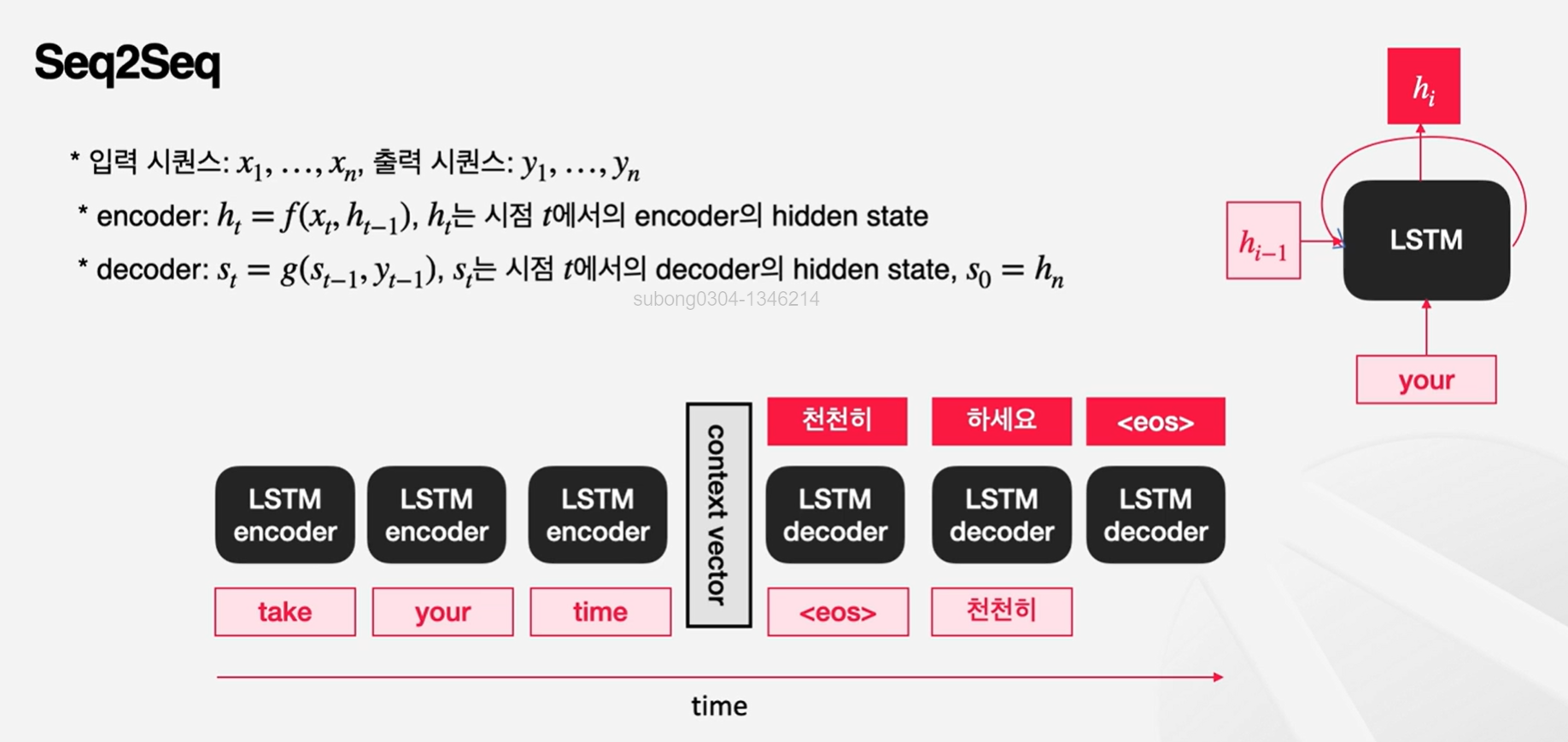
seq2seq : 인코더, 디코더를 가지고 있는 모델로, 순차적인 데이터를 입력받아 순차적인 데이터를 출력하는 모델
-
인코더 : 입력 시퀀스를 이해하는 부분으로, 입력 시퀀스의 문맥을 반영해 context vector를 생성
-
디코더 : 이렇게 이해한 내용을 가지고 출력 시퀀스를 생성하는 부분으로, context vector를 seed로 사용해 순차적으로 출력을 생성
-
각각의 단어(token)은 LSTM(long short term memory) encoder가 처리
- LSTM : 시퀀스를 순서대로 처리할 수 있음. 각 타임스탭마다 이전 시점의 hidden state와 현재 시점의 input을 가지고 이번 시점에서의 hidden state를 만듦. 이 hidden state는 또 다음 스탭에서 활용이 됨으로써 이전 사항을 기억을 할 수 있고, 새로운 인풋의 내용도 기억할 수 있음! 디코더에서는 인코더에서 마지막으로 생성된 hidden state를 context vecotr 삼아 가지고 옴.
-
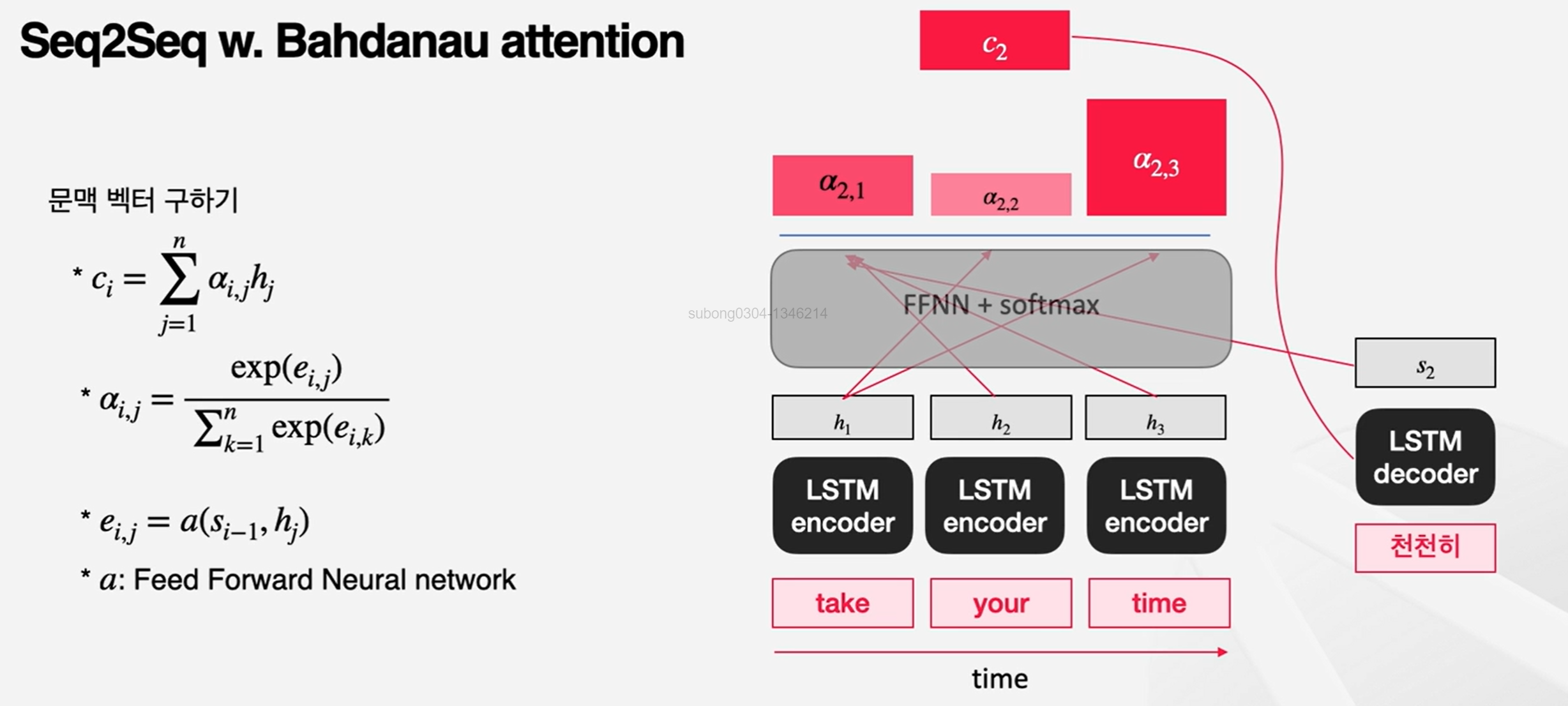
Seq2Seq w. Bahdanau attention: 기존의 attention 방식에서는 output을 뱉을 때마다 input의 어떤 부분을 참고해야 할지가 변하지 않았음! (ex. 환경에 따라 자기소개할 때 강조해야하는 부분이 달라져야 함!)
Bahdanau attention에서는 기존처럼 context vector가 마지막 hidden state 값으로 되는 것이 아니라, 시점에 따라 다르게 계산됨.
계산 방식 :
-
각 시점에서 context vector를 생성하기 위해 encoder의 각 스탭에서의 hidden state와 직전 스탭에서의 decoder의 hidden state를 사용
-
이 hidden state를 neural network에 넣어 계산해 각 시점의 가중치를 구함
-
이 가중치를 통해 encoder hidden states를 가중합함
👉 이전 스탭까지의 내용과 encoder에서 받아들인 각 입력값의 내용을 참고해서 지금 시점에서 어떤 입력값이 더 중요한지를 판단하겠다는 것!
-
📌 기존의 seq2seq 모델의 한계
인코더-디코더 구조로 구성되어 있는 seq2seq 모델에서는, 인코더에서 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어냈는데 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있었고, 이를 보정하기 위해 어텐션이 사용되었다. 그런데 어텐션을 RNN의 보정을 위한 용도로서 사용하는 것이 아니라 어텐션만으로 인코더와 디코더를 만들어본다면 어떨까?
📍Transformer
- Transformer: "Attention is all you need"의 논문에서 나온 모델로, 기존의 seq2seq의 구조인 인코더-디코더를 Attention만으로 구현한 모델
- 여러 개의 인코더, 디코더 레이어가 쌓여있는 형태
- 각 인코더 레이어는 이전의 출력값을 받아서 새로운 출력값을 생성
- 각 디코더 레이어는 이전 디코더 레이어의 출력값을 받아서 새로운 출력값을 계산, 마지막 인코더 블록의 출력값도 디코더 레이어에서 받아 참고
📌 더 자세히 살펴보기
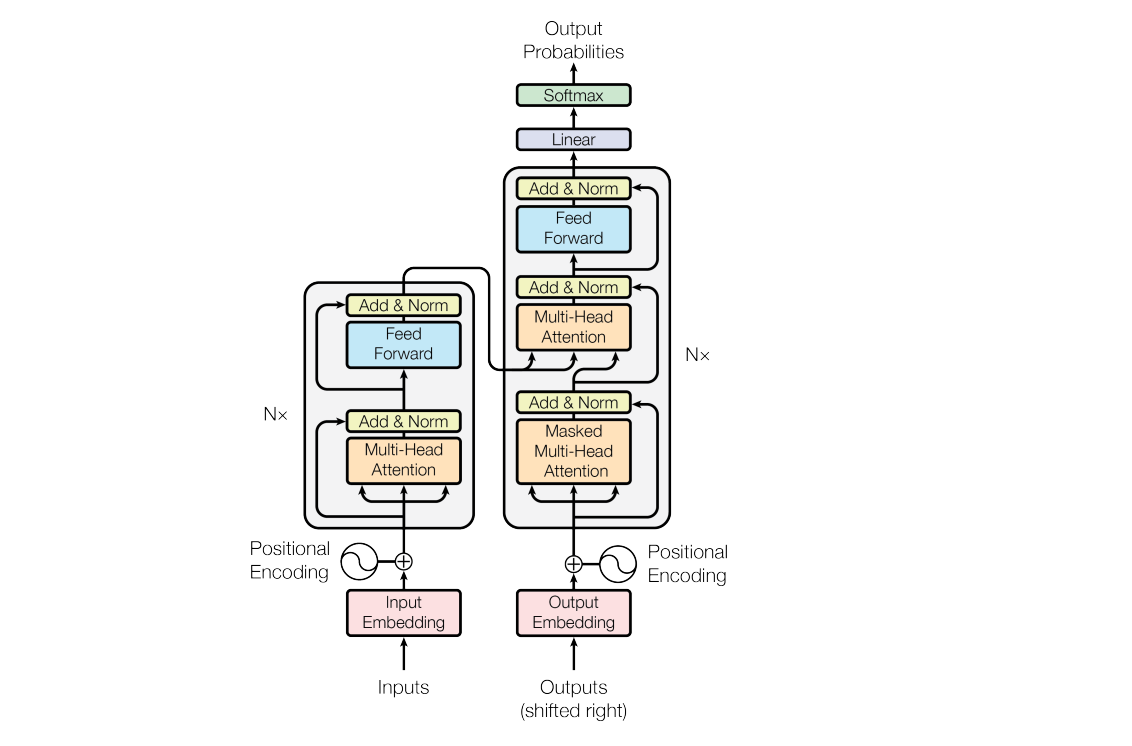
🔻 encoder
-
자연어로 된 input값은 인코더에 들어가기 전에 한 번 전처리를 거친다. : tokenization, embedding 생성 과정
-
positional encoding : embedding 직후 과정으로, 입력값을 순차적이 아닌 한 번에 받는데 자연어 처리는 토큰의 배열이 중요하기 때문에(토큰의 순서에 따라 문맥이 달라질 수 있기 때문!) 필요한 과정이다.
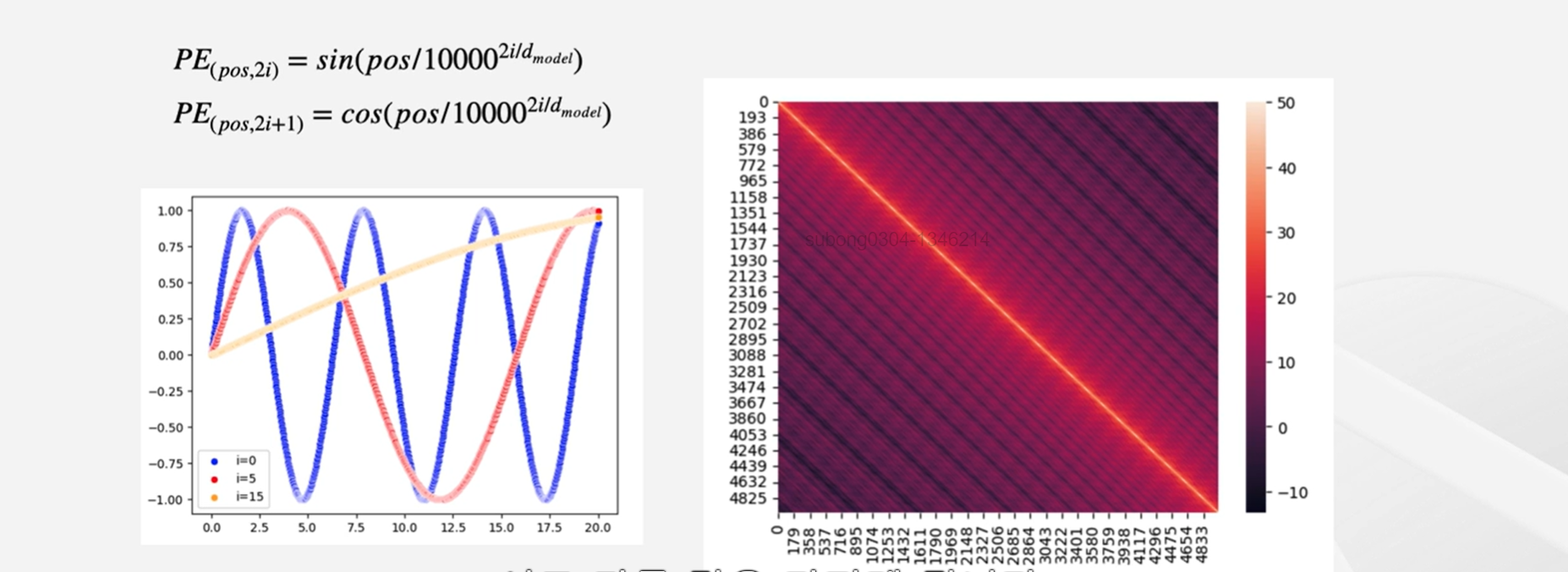
- 각 위치에 대해서 고유한 인코딩을 생성한다.
- 각 인코딩에 포지셔널 인코딩 값을 가지게 되면 같은 토큰이어도 위치에 따라 서로 다른 값을 가지게 된다.
- 이렇게 포지셔널 인코딩 값까지 더해서 input embedding이 완성된다.
🔻 닷-프로덕트 어텐션
- query : 무엇을 찾고 있는지에 대한 질문
- key : 데이터에 대한 정보를 담고 있으면서, query와 대조해볼 수 있는 값
- value : 실제 활용하고자 하는 데이터
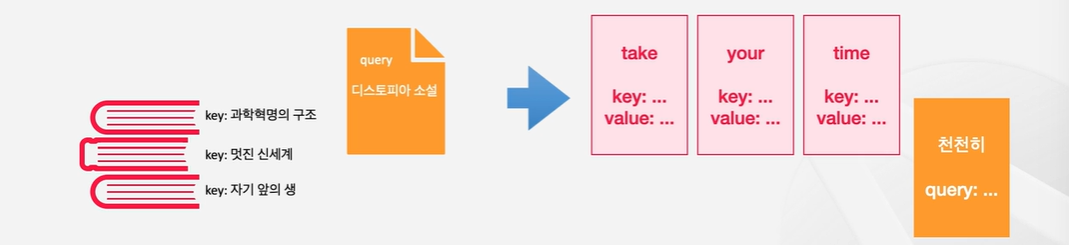
🔹 예제1) 서점에서 책 찾기
만약 서점에서 디스토피아에 대한 책을 찾고 싶다고 해보자. 그렇다면 쿼리는 '디스토피아 소설'이라는 키워드가 될 것이다. 키는 쿼리와 대조할 수 있는 값이므로, 이 경우에는 서점 데이터베이스에 등록되어있는 메타정보(책의 제목, 저자 등)가 있을 것이다. 우리는 query를 key와 대조해서 어떤 value가 내가 필요로 하는 것인지를 찾을 수 있다.
query인 디스토피아 소설의 책에 대한 설명이나 책의 제목 등과 대조를 해서 책의 내용을 직접 참고하지 않아도 어떤 책이 내가 원하는 책인지 알 수 있다는 것이다!
🔹 예제2) take your time과 천천히
'천천히'라는 토큰의 query와 take, your, time이라는 토큰들의 key를 대조해서 가장 연관 깊은 단어를 찾고, 그 value를 가져오는 것이 목표이다.
이해하기 어려우니, Seq2Seq와 Bahdanau attention과 접목하여 설명을 해보겠다.
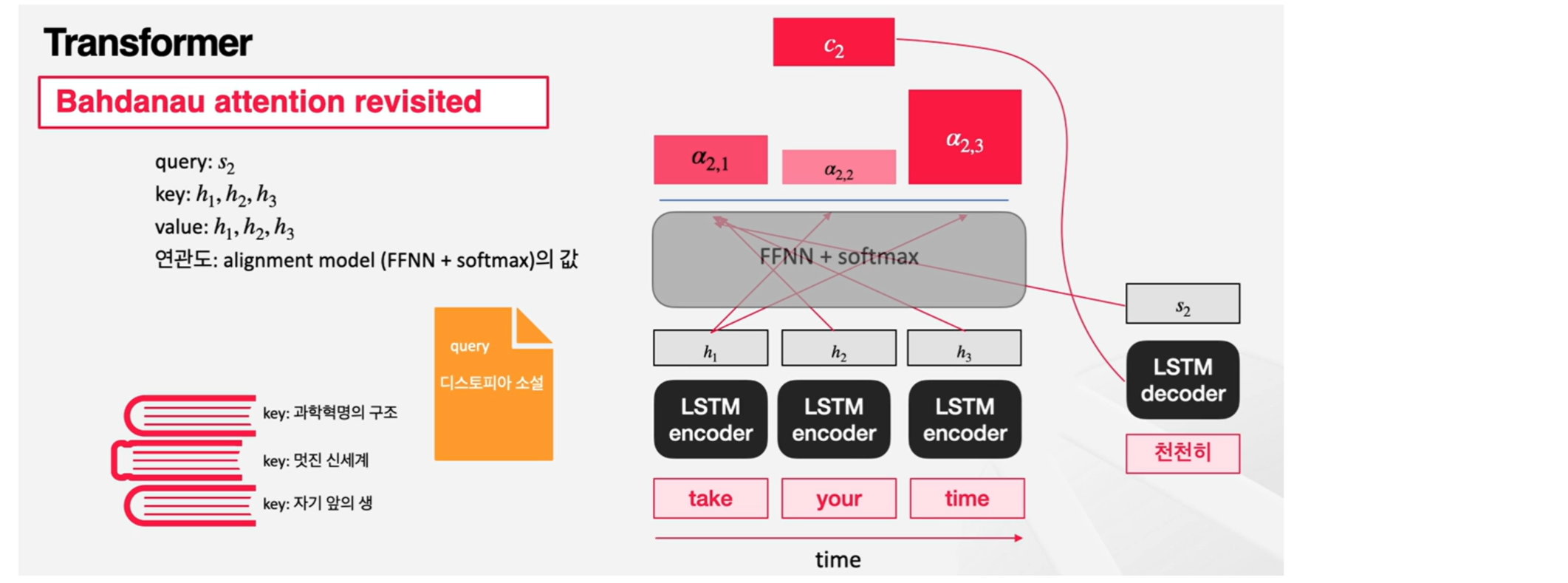
Take, your, time이라는 input이 들어온 상황이고, 디코더단에서 토큰을 생성하는 중에 나올 수 있는 그림이다. '천천히'라는 토큰이 이전에 생성되었을 때 다음 토큰을 생성하기 위해서 세 토큰 중에 어떤 것을 얼마나 참조해야 되는지 알고 싶은 상황인 것이다.
이때 어떤 토큰을 얼마나 참조할지를 결정하기 위해서 Bahdanau attention에서는 decoder가 가지고 있는 이전 스탭에서의 hidden state를 encoder의 각 타임 스탭에서 생성된 hidden state들과 비교해서 결정했다. 즉, 이 상태에서 보면 query는 decoder의 hidden state가 되며, key는 encoder의 각 타임 스탭에서의 hidden state가 된다. 그리고 value는 실제로 사용되는 값이다. encoder의 hidden state를 가중합해서 최종 context vector를 만들게 되기 때문에 value도 encoder의 hidden state가 된다.
정리하면 query는 decoder의 hidden state, key와 value는 encoder의 hidden state!!
이제 Transformer에서는 인코더단에서부터 attention을 적용한다!
🔹 예제3) 긴 문장
- 예시 문장 : "오늘 길 가다가 지난 회사 사수님을 만났는데, 그분 혈색이 좋아 보이더라~"
인간은 '그분'이라는 말이 '회사'와 '지난'을 가리키는 것이 아니라 '사수님'을 가리킨다는 것을 알 수 있다.
하지만 앞서와 같은 Seq2Seq 방식이라면 머신에게 이 사실을 어떻게 알려주면 좋을까? 혹은 모델이 이 관계를 파악하고 있는지 아닌지 우리가 어떻게 알 수 있을까?
여기서 Safe Attention의 개념이 사용된다.
이전에는 query는 decoder에서, key는 encoder에서 가지고 와 두 가지를 대조하여 어떤 value의 가중치가 높은지를 생각했다면, 이번에는 encoder의 각 토큰을 다른 토큰들과 비교해보는 과정이 되는 것이다.
'지난', '사수', '회사'라는 key와 '그분'이라는 query를 가지고 비교하는 셈이다. 이렇게 비교하면 '그분'이라는 토큰이 '사수님'과 깊은 관계를 맺고 있다는 사실을 알 수 있을 가능성이 좀 더 커지게 된다.
이런 식으로 주어진 텍스트의 토큰들 안에서 attention을 적용하는 것을 Safe Attention이라고 한다.
Transformer에서 사용되는 key, query, value는 무엇일까?
take, your, time 각각과 상응하는 임베딩이 있다고 생각해보자. 닷-프로덕트 어텐션에서는 key, query, value 각각의 메트릭스를 하나씩 할당한다. 각 단어에 대한 key, query, value는 인코더 레이어에 들어온 인베딩을 이 매트릭스들에 곱해서 구할 수 있다.
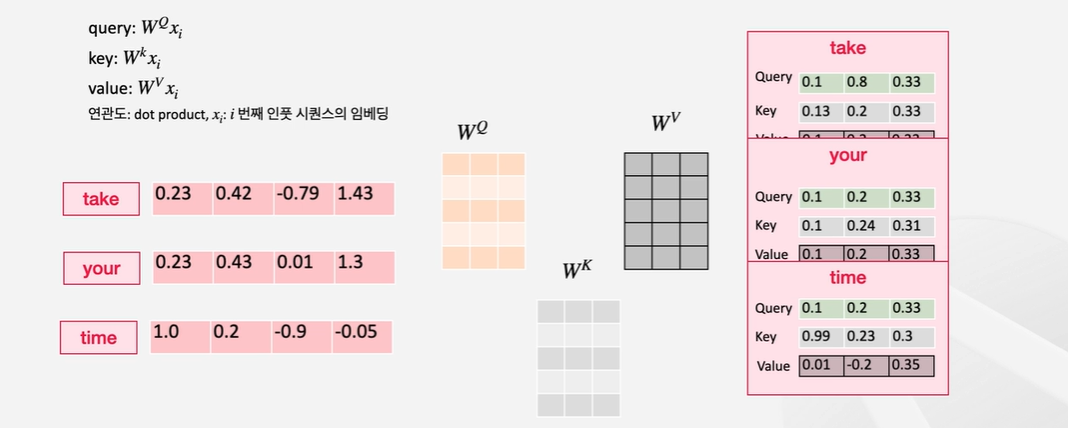
행렬에 곱해진다면 key가, 행렬에 곱해진다면 query가, 행렬에 곱해진다면 value가 되는 것이다.
값이 구해졌다면 닷-프로덕트를 통해서 각 query와 각 아이템들 간의 연관성을 구하고, 그 가중치를 이용해서 value를 가중합할 수 있다.
🔻 MULTI-HEAD
트랜스포머는 한 번의 과정에 여러 개의 Attention을 사용한다.
하나의 Attention을 사용한다면 그 Attention이 잘못된 결과를 내면 다음 Attention은 고스란히 그 잘못된 결과를 따라가게 된다. 하지만, 여러 개의 Attention을 함께 사용한다면 이런 리스크를 줄일 수 있게 되는 것!
각 어텐션 헤드에서 나온 결과물을 concat해서 최종적으로 사용하게 된다.
🔻 디코더에서의 Attention :
- MaskedMultiHeadAttention
- 디코더에서 생성하는 토큰들을 가지고 self-attention을 한 번 취하게 됨
- 하지만 아직 생성하지도 않은 토큰들을 참고하면 안됨! 학습이 제대로 되지 않을 것이다.
⇒ 디코더의 self-attention에서는 현재 시점상 아직 생성되지 않은 시점의 토큰들은 -∞로 마스킹을 해준다 (참조할 수 없게 하는 것)!
🔻 인코더-디코더 MultiHead Attention:
- 아까 인코더 블록에서의 결과물을 사용한다.
- 사용 방식은 Bahdanau Attention의 query, key, value 관점으로 표현했을 때와 비슷하다.
- query는 이전의 Masked Multi Head Attention에서 나온 결과물을, key와 value는 encoder의 output embedding을 출처로 해서 닷-프로덕트 어텐션을 계산하게 된다.
이로써 생성하고 있었던 시퀀스의 맥락과 인풋 시퀀스의 맥락을 모두 반영하면서 문장을 생성할 수 있는 것이다.
📍BERT
-
BERT: Transformer의 encoder를 활용한 자연어 이해 모델, Attention을 사용하여 기존의 자연어 이해 모델들과는 다르게 입력 시퀀스를 bidirectional하게 이해할 수 있음
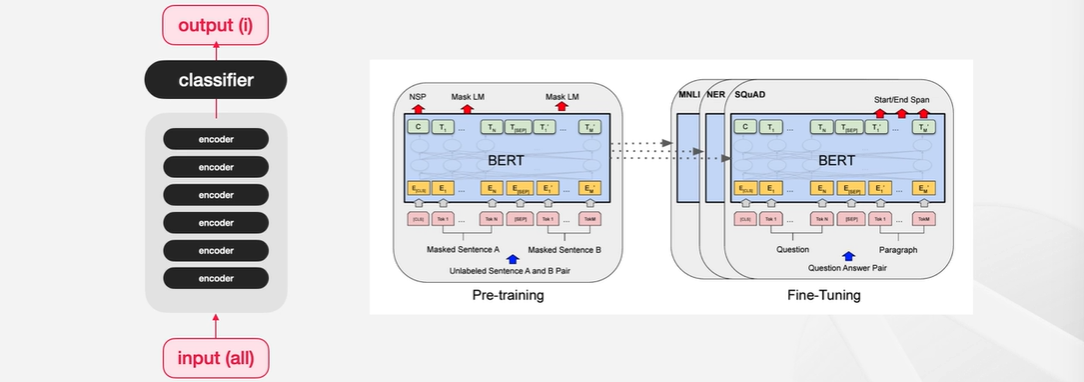
- Transformer encoder layer를 여러 개 쌓아서 인베딩을 만들고 마지막 classifier layer를 붙여서 원하는 결과물을 만들어낸다.
- BERT는 사전학습 모델이다.
- 일반적인 데이터 분포를 학습한 다음, 다운스트림 태스크라고 하는 특정한 태스크에 대해서 다시 학습시켜서 모델을 좀 더 뾰족하게 만드는데 이를 Fine Tuning이라고 한다.
📌 더 자세히 살펴보기
🔹 Pre-training
일반적으로 프리트레이닝은 주어진 큰 데이터셋에서 문제를 자동적으로 생성해서 모델에게 풀게하는 방식을 통해서 진행된다.
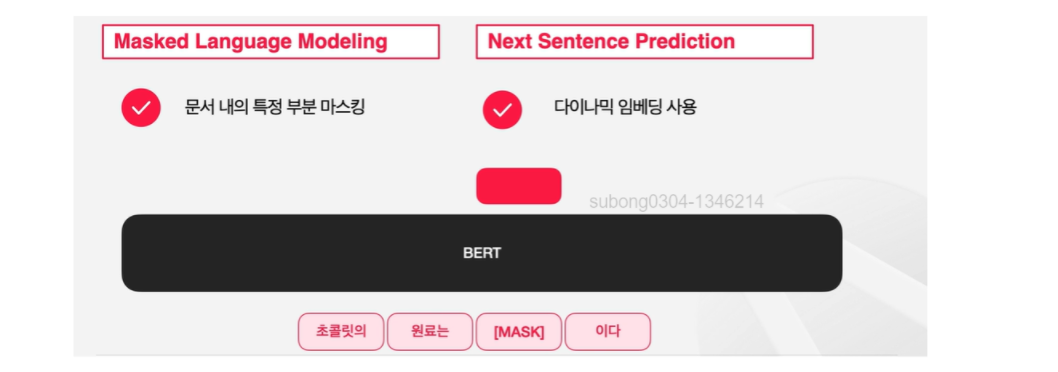
BERT는 빈칸에 해당하는 [MASK] 토큰이 가지는 임베딩을 가지고 해당 Mask 토큰이 원래 무엇인지를 예측하는 방식으로 pre-traning을 한다.

BERT는 Next-Sentence Prediction 전략을 사용하기도 한다. 두 개의 문장이 연속되는 문장인지 아닌지를 판별하는 문제이다.
첫 번째 토큰 자리의 임베딩에 classifer를 씌워서 연속하는 문장일 경우에 1, 연속하는 문장이 아닐시에 0을 출력하도록 한다.
위 그림에서 나온 예시는 연속된 문장일 가능성이 높으므로 2를 출력하게 된다.
이러한 방식은 일반적인 사전 지식을 얻게 해준다.
📍GPT
- GPT: Transformer의 디코더 구조만 활용한 모델로 자연어 생성에 초점을 맞춘 모델
- Transformer의 디코더 레이어와 달리 encoder를 사용하지 않기 때문에 encoder-decoder self attention을 사용할 수 없음
- 따라서 Masked Self-Attention과 Feed-Forward Network의 구조를 가짐
📌 더 자세히 살펴보기

BERT의 사전 학습과 달리 Next Word Prediction 기법 을 사용한다. 이전의 토큰들이 있을 때 다음의 토큰을 예측하는 방식이다. 레이블링 되지 않은 케이스에서도 학습한 문제를 만들어낼 수 있게 된다.
📍BART, T5
-
BART, T5: seq2seq와 마찬가지로 encode to decoder 모델
-
BART training : 텍스트에 노이즈를 삽입해 입력하고, 원본 텍스트를 복원하도록 하기 (denoising)
- Token Masking
- Sentence Permutation
- Document Rotation
- Token Deletion
- Text Infilling
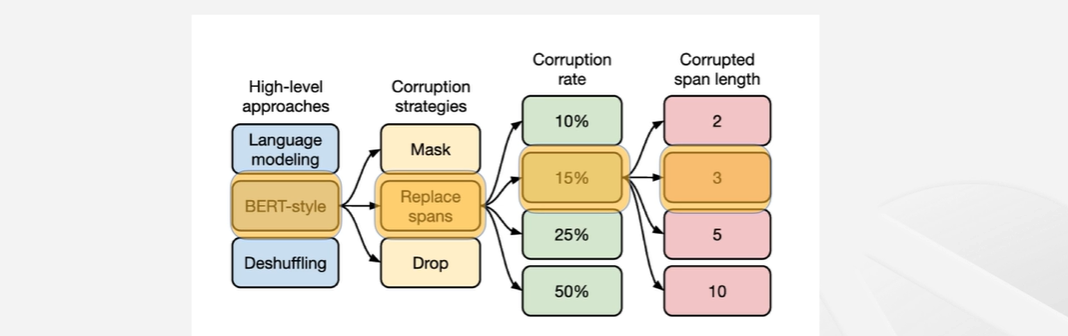
-
T5 training : text-text 기법으로 한가지 모델이 여러 문제를 해결하는데 사용될 수 있음 - 멀티태스킹이 가능함!!
- 문제를 줄때 지시사항을 함께 전달하는 대신 문제의 타입에 대한 힌트를 줌 → training 과정에 없었던 종류의 태스크에 대해서는 잘 풀 수 없게 됨
- Replace Spans : 각각의 마스킹할 토큰들을 서로 다른 스페셜 토큰으로 마스킹하는 방식
- Corrupted span length : BART는 하나의 토큰씩 독립적으로 선택해서 마스킹을 한 반면, 토큰 몇개를 연속적으로 마스킹할지를 위 그림에서 표시된 값을 평균으로 하는 분포에서 길이를 샘플링해서 그 길이만큼의 마스킹을 한다고 생각하면 됨
-
👉 특정한 하나의 태스크에 파인튜닝을 했을 때 잘하는 모델 대신에, 파인튜닝을 하지 않거나 살짝만 해도 많은 다운스트림 태스크에 대해서 잘 작동하는 모델을 만드는 것에 더욱 관심이 높아짐
📍FLAN
- FLAN: Instruction Finetuning이라는 방식을 도입
- 일반적인 Fine Tuning은 특정 문제를 잘 해결할 수 있도록 모델의 가중치를 업데이트하여 하나의 태스크에 특화됨
- 반면 Instructive Fine Tuning은 여러가지 종류의 문제에 대해서 학습을 하여 문제 해결력 자체를 길음으로써, 아예 새로 보는 종류의 태스크에 대응할 수 있도록 함
- Instruction에 내포된 의미를 파악해서 그 지시사항을 따르게 하는 것이 목표!
- 동일한 태스크에서도 여러 변형을 준 Instruction을 배정해서 모델이 Instruction의 패턴을 파악하는 것이 아니라, Instruction의 의미를 배우도록 함!
📍InstGPT
- InstGPT : 이후에 등장한 Instructive GPT에서는 강화 학습을 도입해서 사람의 선호를 모델의 아웃풋에 녹여내게 됨
📌 생성형 LLMs의 한계
- Hallucination : 사실이 아닌 정보를 생성하는 것
- 생성형 언어 모델의 본질이 이전의 토큰들을 기반하여 그럴듯한 다음 토큰을 생성하는 것이기 때문에, 자신이 학습하지 않아 '모르는' 내용이더라도 답변을 내놓게 됨
- 생성형 언어 모델의 본질이 이전의 토큰들을 기반하여 그럴듯한 다음 토큰을 생성하는 것이기 때문에, 자신이 학습하지 않아 '모르는' 내용이더라도 답변을 내놓게 됨
- Outdated Knowledge : 모델이 띄는 정보가 최신성을 띄기 어려움
- LLM의 knowledge는 주기적으로 업데이트하기가 어려움. LLM을 학습하는 데에는 매우 많은 컴퓨팅 리소스와 시간이 들어가기 때문.
- LLM의 knowledge는 주기적으로 업데이트하기가 어려움. LLM을 학습하는 데에는 매우 많은 컴퓨팅 리소스와 시간이 들어가기 때문.
- Untraceable reasoning process : 모델 자체가 블랙박스! 우리는 모델의 아웃풋을 볼 뿐 모델이 어떠한 이유로 특정 결과를 냈는지 볼 수 없음
- Bias : LLM은 학습되는 데이터셋에 있는 분포를 그대로 학습하기 때문에 훈련 데이터에 존재하는 편향이 모델의 출력에 그대로 반영될 수 있음
