이번 4기에서 진행되는 첫 프로젝트로, 협업 과정을 해보는 것에 초점을 둔다고 한다.
우리 팀은 RAG을 구축하여 QA Engine을 만들어 보는 것을 목표로 한다.
첫 프로젝트라서 나름 긴장도 되었었는데... 프로젝트 시작 직전 주말에 이석증에 걸렸다 (이석증이 뭔지 이번에 처음 알았다)
그래서 초반 이틀간 참여를 제대로 못했는데 그래도 맡은 바를 빠르게 마무리 하였고, 자료조사나 ppt 제작에 최대한 기여를 하려고 노력했다..ㅎㅎ
이제 RAG가 무엇인지, Langchain을 활용한 RAG 구축을 통해 어떻게 QA Engine을 만들 수 있는지 살펴보도록 하자!
📌 요구사항
필수 기능
-
API를 통해 답변이 제대로 생성되었는지 확인
-
LLM의 답변을 의도대로 생성하기 위해 System Prompt를 테스트하는 기능 - system prompt는 선택
-
RAG를 하기 위해 데이터를 VectorDB에 저장하는 기능
-
Langchain를 통해 사용자 입력과 적절한 Knowledge를 추출하는 기능
-
main.py를 통해서 나머지 모듈들을 불러와서 한 번에 실행하는 기능
-
SQLite나 pymysql등을 사용하여 RDBMS에 구축된 데이터로부터 RAG를 수행하는 기능 (선택)
- 여기서 사용하는 DB는 각자 프로젝트 기획에 맞는 table 데이터를 수집하여 사용
- schema를 반드시 README.md에 기술
- text-to-sql은 변환이 완벽하지 않으니, 이부분을 해결하는 prompt를 디자인
📌 구조
AILAB_AItheory
- 목표 : AI 이론과 정보를 RAG 알고리즘을 통해 간단하게 정리하여 제공하는 시스템 구축
- 선정 주제/기능 :
- 사용자가 입력한 질문에 대해 AI 이론과 관련된 정보를 검색하고 요약된 답변을 제공
- Wikipedia와 arxiv에서 AI 관련 이론을 포함한 데이터를 수집하여 인덱싱
- LLM을 사용해 검색된 정보를 기반으로 간단한 요약관 답변 생성
프로젝트 디렉토리 구조
RAG_Project/
├── data/ # 데이터 관련 파일 저장
│ ├── raw/ # 원본 데이터 파일 (예: PDF, 텍스트 파일 등)
│ └── processed/ # 전처리된 데이터 파일
├── src/ # 소스 코드 디렉토리
│ ├── init.py # Python 패키지로 인식하기 위한 파일
│ ├── llm.py # LLM API 호출 및 응답 처리
│ ├── vector_store.py # RAG 구축 및 벡터 저장 관련 모듈
│ ├── retriever.py # 벡터 DB에서 정보 검색 관련 모듈
│ ├── crawler.py # 데이터 수집(크롤링) 관련 모듈
│ ├── chat_history.py # 대화 기록 관리 모듈
│ ├── sql.py # 데이터베이스 연동 및 SQL 처리 모듈
│ └── logger.py # 로깅(Logging) 관련 모듈
├── tests/ # 테스트 코드 디렉토리
├── requirements.txt # 프로젝트 의존성 목록 (설치할 패키지들)
├── README.md # 프로젝트 개요 및 사용법 설명
├── main.py # 메인 실행 파일, 전체 애플리케이션의 흐름 제어
└── .gitignore # Git에서 무시할 파일/디렉토리 목록
✒️ RAG (Retrieval-Augmented Generation)
- RAG(Retrieval-Argumented Generation) : 검색 기반의 생성을 말하며, 사용자 질의와 유사한 내/외부의 지식 정보를 찾아 이를 문맥(context)으로 설정하여 질의에 응답하는 일련의 시스템을 말함
RAG 구축의 핵심 포인트는 LLM이 답변을 할때 참조하길 바라는 데이터를 외부DB에 저장을 해놓고, 임베딩 과정을 통해 빠르게 유사도를 계산하여 답변을 생성한다는 점이다!
대규모 언어 모델(LLM)은 매우 독창적인 결과를 생성할 수 있지만, 이를 특정 사용자 요구에 맞게 커스텀 하려면 모델을 다시 훈련시켜야 한다. 이 재훈련 과정은 많은 비용이 드는데, RAG는 LLM의 기능을 특정 도메인이나 조직의 내부 지식 기반으로 확장하여 모델을 다시 훈련할 필요가 없다.
RAG는 LLM이 응답을 생성하기 전에 신뢰할 수 있는 외부 지식 베이스를 참조하도록 하여, 최신 정보를 반영하고 답변의 부정확성이나 환각(hallucination)을 줄일 수 있다.
📌 RAG 사용 효과
위에서 이야기 했듯이, RAG를 사용하면 언어모델 답변의 정확성을 높일 수 있다. 이는 언어모델의 입력에 문맥을 제공하여 해당 문맥 내에서 적절한 답변을 찾는 기계 독해(Machine Reading Comprehension) 문제로 추론 파이프라인을 변환하였기 때문이다.

📌 RAG 서비스 구조
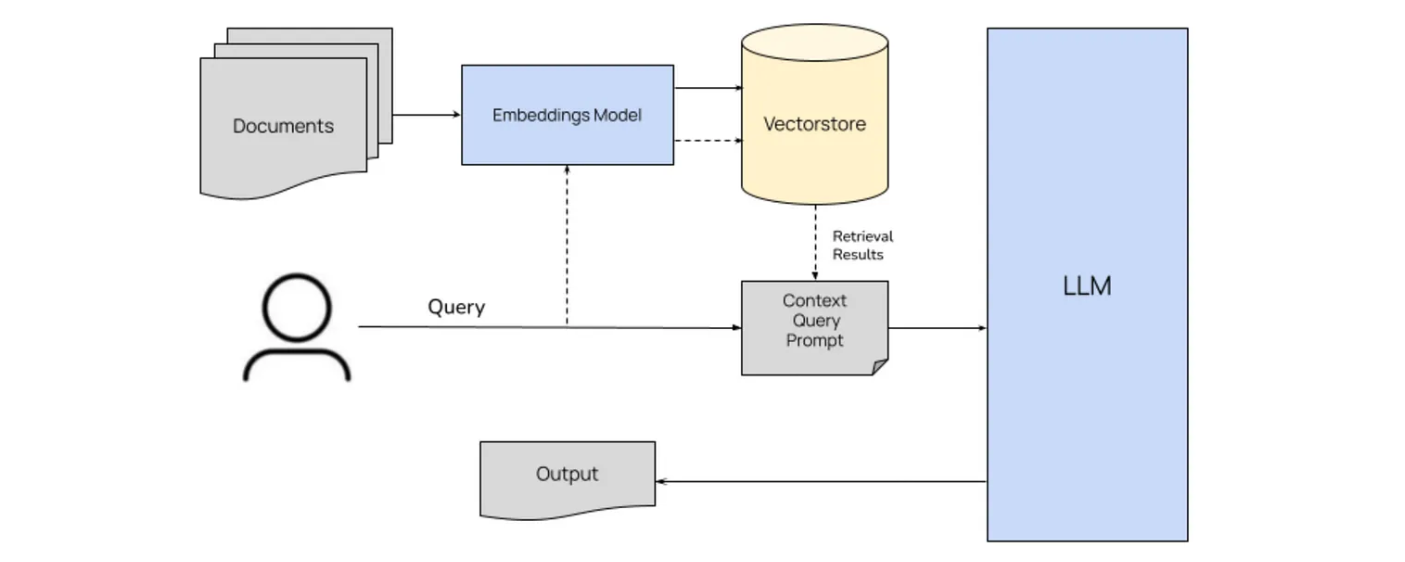
위 그림을 좀 더 구체화 해보면..
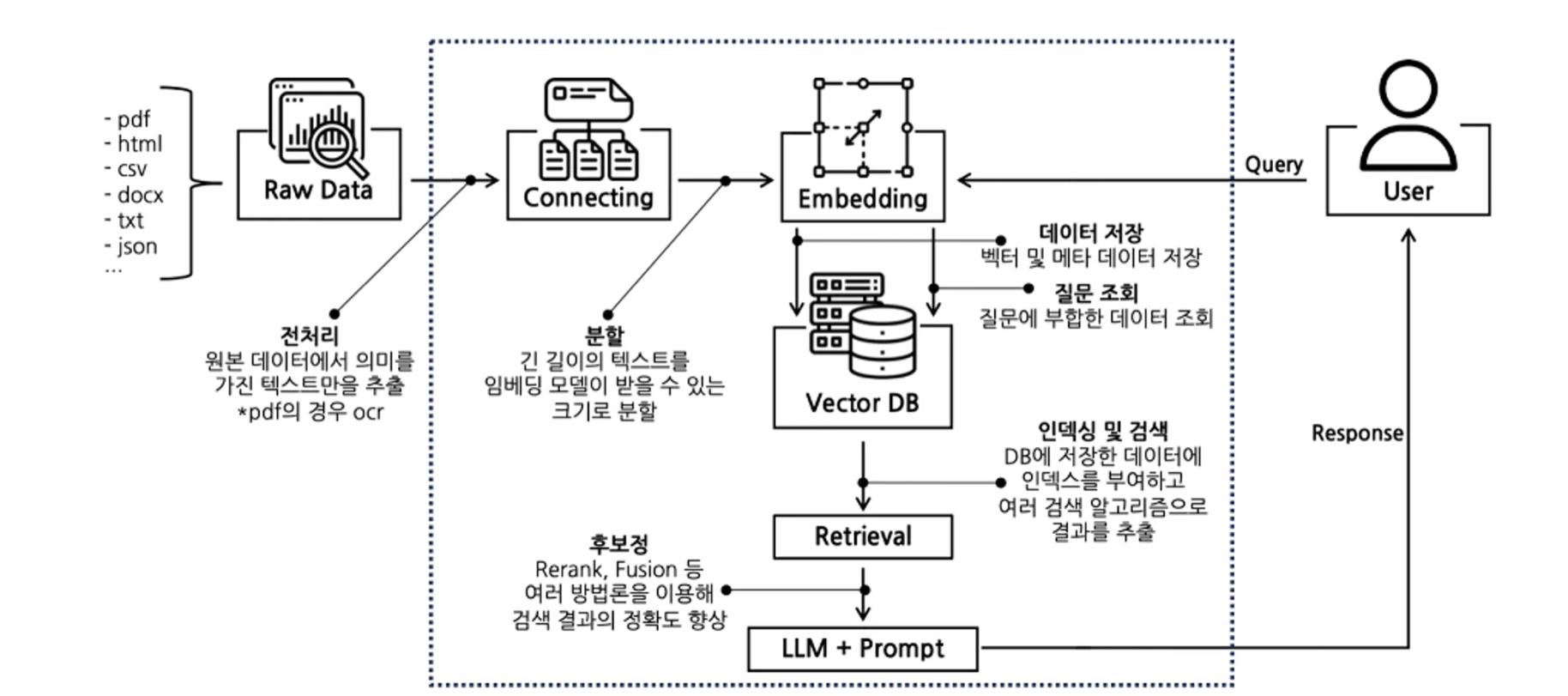
📌 Langchain에서의 RAG 구현 workflow
원본 데이터 → 적재 (Load) → 분할 (Split) → 임베딩 (Embedding) → 벡터 공간 저장 (Store) → Retrieve → output
📍 main.py
사실 이정도의 코드는 한 파일에서 모두 작성해도 되지만, 본 프로젝트는 협업 과정을 중시했기에 main.py를 만들고 호출하는 형식으로 진행이 되었다!
import warnings
from scrapy.utils.log import configure_logging
import logging
from src.wikipedia_crawling import WikipediaCrawler
from src.arxiv_crawling.arxiv_crawling.spiders.arxiv import ArxivSpider
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
import asyncio
from src.vector_store import vector_store
from src.llm import get_response
from src.retriever import get_embadding, retriever, generator
warnings.filterwarnings("ignore", category=DeprecationWarning) # DeprecationWarning 무시
def setup_logger(logger_name, log_file, level=logging.INFO, formatter=None):
"""설정된 로거를 반환"""
logger = logging.getLogger(logger_name)
if not logger.handlers: # 중복 추가 방지
handler = logging.FileHandler(log_file)
if formatter is None:
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(level)
return logger
# 일반 로그 설정
general_logger = setup_logger('general_logger', 'app.log')
def logger(log_message):
"""일반 로그 기록"""
general_logger.info(log_message)
print(f"로그를 기록 중... (Message: {log_message})")
# 채팅 로그 설정
chat_logger = setup_logger(
'chat_logger',
'chat_history.log',
formatter=logging.Formatter('%(asctime)s - %(message)s', datefmt='%Y-%m-%d %H:%M:%S')
)
def chat_history(user_input, response):
"""채팅 기록 로그 기록"""
log_message = f"\nUser: {user_input}\nResponse: {response}\n{'-'*50}"
chat_logger.info(log_message)
print(f"Chat history 기록 중...\n{log_message}")
def crawler(source) -> list:
configure_logging(install_root_handler=False) # 기본 로그 설정 제거
configure_logging({'LOG_LEVEL': 'ERROR'}) # 로그 레벨 설정 (ERROR로 설정 시, 오류만 출력)
print("============\n")
print(f"데이터를 크롤링 중... (Source: {source})")
documents = ["문서1", "문서2"] # 실제로는 수집된 문서 리스트를 반환
# test 용 쿼리
queries = ["machinelearning", "deeplearning"]
wiki_crawler = WikipediaCrawler(queries)
asyncio.run(wiki_crawler.process_queries())
# Arxiv 크롤러
process = CrawlerProcess(get_project_settings())
process.crawl(ArxivSpider, queries)
process.start()
print("크롤링 & 저장 완료")
print("\n\n==============")
return documents
def main():
# 2. 문서 크롤링 및 데이터 수집
source = "Wikipedia and arXiv"
documents = crawler(source)
logger("Documents crawled and collected.") # 일반 로그 기록
# 3. 수집된 데이터 벡터화 및 저장
vector_storage = vector_store(documents)
logger("Documents vectorized and stored.") # 일반 로그 기록
# 4. 사용자 입력에 따라 관련 정보 검색
question = "What is deep learning?"
relevant_info = retriever(question, vector_storage)
logger(f"Relevant information retrieved for the query: {question}") # 일반 로그 기록
# 5. 검색된 정보를 바탕으로 LLM 호출하여 답변 생성
answer = generator(question, relevant_info)
logger(f"Answer generated using LLM: {answer}") # 일반 로그 기록
# 6. 생성된 답변을 대화 기록에 저장
chat_history(question, answer) # 챗 로그 기록
logger("Conversation history updated.") # 일반 로그 기록
print("작업 완료!")
if __name__ == "__main__":
main()📍 Load
프로젝트 주제에 따라 아카이브 문서와 위키피디아 자료를 crawling하였다. 팀원이 작성한 코드를 모두 올려보고 싶으나, 파일이 매우 많고 각자 데이터를 확보하는 과정은 상이할 것으로 판단하여 생략하겠다.
📍 vector_store.py
Vector DB를 구축하는 과정을 내가 맡았다!
이 모듈은 문서를 벡터화하고, 벡터화된 문서를 Vectore Database에 저장하는 역할을 한다. RAG 모델은 이러한 벡터 데이터를 기반으로 정보를 검색하고, LLM은 이를 바탕으로 답변을 생성하게 되는 것이다!
🔻주요 기능
1. 문서 전처리 및 토큰화 👉 Chunking 과정
- 문서를 수집한 후, 이른 토큰화하고 전처리를 한다. 여기에는 텍스트 정제, 불용어 제거, 문장 분할 등이 포함됨
2. 텍스트 벡터화 👉 임베딩 과정
- 전처리된 텍스트를 벡터화한다. 이 과정에서는 BERT, Sentence-BERT, 또는 다른 임베딩 모델을 사용하여 텍스트를 고차원 벡터로 변환한다
3. 벡터 저장 👉 VectorDB 구축 과정
- 벡터화된 데이터를 Vector Database (예: FAISS, Milvus)에 저장한다. 이렇게 저장된 벡터들은 나중에 검색에 사용된다
🔻고려사항
-
임베딩 모델 선택 : 어떤 모델을 사용할지 결정해야 한다. 일반적으로 AI 이론과 관련된 정보를 다루기 때문에, 도메인에 맞는 임베딩 모델을 선택하는 것이 중요하다
-
Vector DB : 벡터를 저장할 데이터베이스로는 FAISS, Milvus 같은 고성능 벡터 검색 라이브러리를 사용할 수 있다. 데이터가 증가하더라도 빠른 검색 성능을 유지할 수 있는 구조로 설계해야한다
🔻 코드 설명
코드가 두 버전이 있는데, 하나는 OpenAI를 활용하여 임베딩을 구현한 코드이고, 다른 하나는 Solar LLM을 활용하여 임베딩을 구현한 코드이다.
대부분 OpenAI를 활용하지만 인증키를 발급받아 사용하기 위해서는 토큰마다 일정 비용을 지불해야 한다.. 하지만 지원을 받지 못하여 Solar LLM을 활용한 버전도 만들어보았다!
✔️ OpenAI 활용 Langchain RAG
# RAG 구축 및 벡터 저장 관련 모듈 - OpenAI 활용 Langchain
# 인코딩 확인 및 설정
import sys
import io
# 표준 출력 인코딩 설정 (터미널의 인코딩을 UTF-8로 강제 설정)
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import CacheBackedEmbeddings
from openai import OpenAI
from langchain_community.vectorstores import Chroma
from langchain.storage import LocalFileStore
#Solar LLM - OpenAI 연결
client = OpenAI(
api_key="up_LP49URygKq74lrEhGJPQHqBRkEdfV",
base_url="https://api.upstage.ai/v1/solar"
)
# 1. 텍스트 데이터 분할
text = (
"With the growing demand for offline PDF chatbots in automotive industrial production environments, optimizing the "
"deployment of large language models (LLMs) in local, low-performance settings has become increasingly important. "
"This study focuses on enhancing Retrieval-Augmented Generation (RAG) techniques for processing complex automotive "
"industry documents using locally deployed Ollama models. Based on the Langchain framework, we propose a multi-dimensional "
"optimization approach for Ollama's local RAG implementation. Our method addresses key challenges in automotive document "
"processing, including multi-column layouts and technical specifications. We introduce improvements in PDF processing, "
"retrieval mechanisms, and context compression, tailored to the unique characteristics of automotive industry documents. "
"Additionally, we design custom classes supporting embedding pipelines and an agent supporting self-RAG based on LangGraph "
"best practices. To evaluate our approach, we constructed a proprietary dataset comprising typical automotive industry documents, "
"including technical reports and corporate regulations. We compared our optimized RAG model and self-RAG agent against a naive "
"RAG baseline across three datasets: our automotive industry dataset, QReCC, and CoQA. Results demonstrate significant improvements "
"in context precision, context recall, answer relevancy, and faithfulness, with particularly notable performance on the automotive "
"industry dataset. Our optimization scheme provides an effective solution for deploying local RAG systems in the automotive sector, "
"addressing the specific needs of PDF chatbots in industrial production environments. This research has important implications for "
"advancing information processing and intelligent production in the automotive industry."
)
# A. 일반 텍스트 분할 방법 - 문맥을 파악하기에 Recursive 방법이 적합
recur_text_splitter = RecursiveCharacterTextSplitter(
# separator="\n\n", #청크 구분 - separator는 CharacterTextSplitter에서 사용
chunk_size=250, # 각 청크의 최대 길이
chunk_overlap=0, # 인접한 청크 간에 겹치는 문자의 수
length_function=len, # 청크의 길이를 계산하는데 사용되는 함수를 결정 - 기본적으로 len 사용
is_separator_regex=False, # separator가 정규 표현식으로 해석될지 여부
)
chunks = recur_text_splitter.split_text(text)
# 분할된 청크를 출력 (테스트)
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1}: {chunk}")
# 2. 임베딩
embeddings = OpenAIEmbeddings(openai_api_key="인증키...")
cache_dir = LocalFileStore("./.cache/practice") #임베딩 과정에서 추가적인 과금을 막기 위함
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(embeddings, cache_dir)
# 3. Vector Store 생성
vector_store = Chroma.from_documents(chunks, cached_embeddings)
위 코드는 chunking 과정을 확인해보기 위해 text를 직접 입력하였고 결과를 확인하였다. 즉, 적재 과정에서 업로드된 document를 불러오는 과정을 포함하고 있지 않다!
✔️ Solar LLM 활용
# 인코딩 확인 및 설정
import sys
import io
# 표준 출력 인코딩 설정 (터미널의 인코딩을 UTF-8로 강제 설정)
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import CacheBackedEmbeddings
from openai import OpenAI
from langchain_upstage import UpstageEmbeddings
from langchain_community.vectorstores import FAISS
# LLM 및 Embeddings 설정
client = OpenAI(
api_key="인증키",
base_url="https://api.upstage.ai/v1/solar"
)
embeddings = UpstageEmbeddings(
api_key="인증키",
model="solar-embedding-1-large"
)
def vector_store(documents):
"""
주어진 문서 리스트를 벡터화하고, 벡터 스토어에 저장합니다.
Parameters:
documents (list): 문서 텍스트의 리스트
Returns:
FAISS: 생성된 벡터 스토어 객체
"""
print("문서를 분할하고 벡터화를 시작합니다...")
# 1. 텍스트 데이터 분할
recur_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=250,
chunk_overlap=0,
length_function=len,
is_separator_regex=False,
)
chunks = []
for document in documents:
chunks.extend(recur_text_splitter.split_text(document))
# 2. 임베딩 생성
doc_embeddings = embeddings.embed_documents(chunks)
# 3. Vector Store 생성
vector_store = FAISS.from_texts(chunks, embedding=embeddings)
print("문서를 벡터화하고 벡터 스토어에 저장을 완료했습니다.")
return vector_store
위 코드에서는 적재한 document을 가져와 chunking을 하고 임베딩을 하여 FAISS를 통해 인덱싱 + 벡터화된 데이터를 저장하도록 하였다.
-
RecursiveCharacterSplitter
- 문단 > 문장 > 단어 순으로 recursive하게 chunking을하여 문맥 보존에 탁월한 방법이라고 함
-
UpstageEmbedding
- Solar LLM에서 제공하는 임베딩으로, 영어, 한국어, 일본어에 대해 벤치마킹한 결과, 3개 언어 모두에서 OpenAI의 Embedding 모델(text-embedding-3-large)보다 우수한 성능을 보인다고 함
-
FAISS
- RAM 용량을 초과할 수 있는 벡터를 포함하여 다양한 크기의 벡터 집합을 검색하는 방법을 제공합니다.
- Faiss는 평가 코드 및 매개변수 조정 지원도 제공합니다.
- 주요 기능:
- 가장 가까운 이웃뿐만 아니라 두 번째, 세 번째, k번째로 가까운 이웃도 검색합니다. 하나의 벡터에 국한되지 않고 여러 개의 벡터를 동시에 검색할 수 있습니다.
- 최소한의 검색 대신 가장 많은 내부 제품 검색을 활용합니다.
- L1, Linf 등과 같은 다른 거리도 지원하지만 그 정도는 적습니다.
- 쿼리 위치의 지정된 반경 내에 있는 모든 요소를 반환합니다.
- 인덱스를 RAM에 저장하는 대신 디스크에 저장하는 옵션을 제공합니다.
- Faiss는 고밀도 벡터 유사도 검색을 가속화하기 위한 강력한 도구로, 효율적이고 효과적인 검색 작업을 위한 다양한 기능과 최적화를 제공합니다.
- ChromaDB도 OpenAI에서 import해야하는 기능이라 사용이 불가하여 차선책을 찾다가 FAISS를 선택
- ChromaDB : Chroma는 LLM(대규모 언어 모델) 애플리케이션 개발을 간소화하도록 설계된 오픈 소스 임베딩 데이터베이스
- 주요 기능: 쿼리, 필터링, 밀도 추정 등 다양한 기능을 갖추고 있습니다. LangChain(파이썬 및 자바스크립트) 및 라마인덱스 지원. Python 노트북에서 작동하는 것과 동일한 API를 활용하고 프로덕션 클러스터로 효율적으로 확장
- ChromaDB : Chroma는 LLM(대규모 언어 모델) 애플리케이션 개발을 간소화하도록 설계된 오픈 소스 임베딩 데이터베이스
📍 retriever.py
이 모듈은 사용자의 질문(query)에 대해 Vector Database에서 가장 관련성이 높은 벡터를 검색하고, 해당 벡터에 연관된 정보를 반환하는 역할을 한다
주요기능
-
사용자 질문 벡터화
- 사용자의 입력을 임베딩 모델을 사용하여 벡터화한다
-
벡터 검색
- 벡터 DB에서 사용자 질문 벡터와 가장 유사한 벡터를 검색 - top k를 반환
-
관련 정보 반환
- 검색된 벡터와 연결된 원문 정보를 반환
고려사항
-
유사도 측정 : 벡터 간의 유사도를 어떻게 측정할 것인지 ex. 코사인 유사도
-
결과 정렬 : 검색된 결과는 유사도에 따라 정렬되어야하며, 상위 N개의 결과를 반환하도록 설계해야 한다
본 파트는 내가 맡은 부분이 아니었지만, 코드를 따로 작성해보았다.
코드를 입력하세요이처럼 RAG를 구축하면 원하는 데이터를 참조하여 LLM이 답변할 수 있으므로 매우 매력적인 방법이라고 생각된다!
GPT가 같은 창 내에서는 이전에 답변했던 것을 '기억'하므로 그때 데이터를 던져줄 수 있지만, prompt 길이가 매우 길어지기 때문에 효율적이지 못했는데, 이렇게 사용하면 답변의 정확도를 높일 수 있기에 편리하다고 생각된다.
이번 프로젝트에서 더 욕심을 가지고 더 많은 시도를 해보지 못했던 것 같아 아쉬움이 남지만, 이번 프로젝트를 통해 배운 것을 기반으로 하여 졸업 작품에서 RAG를 구축할 때 더 발전된 기능을 구현하도록 노력해봐야겠다고 생각이 들었다 ㅎㅎ
무엇보다 이번 프로젝트를 통해 다양한 사람들을 알게 되어 좋은 기회가 되었다고 생각하고, 다른 팀원 분들의 역량이 매우 좋아 내가 더 노력해야겠다고 다짐하게 되었다....ㅎㅎ 힘내봅세,,
