✒️ 머신러닝이란
📍 인공지능 Artificial Intelligence
- 인간의 학습능력, 추론능력, 지각능력을 인공적으로 구현하려는 컴퓨터 과학의 세부분야 중 하나
- 정보공학 분야에 있어 하나의 인프라 기술이기도 함
- 지능을 갖고 있는 기능을 갖춘 컴퓨터 시스템이며, 인간의 지능을 기계 등에 인공적으로 시연(구현)한 것
🔻기술적 특이점 (Technological Singularity)
인공지능이 발전해, 인간의 도움 없이도 스스로 발전을 계속할 수 있게 되고, 결국 인류 전체를 합친 것보다 뛰어난 지능을 가지게 되는 가상의 시점을 이르는 말
❓ 특이점이 왔다면, 우리는 그걸 어떻게 알 수 있을까?
-
튜링 테스트(Turing Test) : 기계가 인간과 동등한 지적 능력을 가졌는지 확인하기 위해 고안된 테스트로, 대화를 해보며 인간인지 기계인지 판별해보는 과정을 포함
- 하지만 명확한 기준 없이 질문자의 주관적인 판단에 의전하는 시험으로 크게 의미가 없음!
-
그렇다면 똑똑한 사람이 하는 무언가를 인공지능으로 구현해보자!
- 체스 : 간단한 경우의 수 탐색일뿐 지능을 가졌다고 보기 힘듦
- 바둑 : 이기고 지는 전략의 패턴을 암기했을 뿐, 아직 지능을 가졌다고 보기 힘듦
- 스타크래프트, DOTA 등 복잡한 게임 : 게임처럼 변수가 적은 격리된 환경이라 가능한 것! 현실에서는...
🔻종류
- 약인공지능
- Weak AI 또는 ANI(Artificial Narrow Intelligence) : 정해져있는 과제들을 잘 수행하는 인공지능
- 머신러닝이 여기에 해당
- 강인공지능
- Strong AI / AGI(Artificial General Intelligence): 사람처럼 복합적인 사고를 통해 어떤 일이든 수행하는 AI
📍머신러닝 Machine Learning
🔻 머신러닝의 구조
- 함수(소프트웨어) : 하나의 특별한 목적의 작업을 수행하기 위해 독립적으로 설계된 코드의 집합
- 함수(수학) : 어떤 집합의 각 원소를 다른 어떤 집합의 유일한 원소에 대응시키는 이항 관계
일련의 과정을 통해 인풋으로 들어오는 무언가를 특정한 아웃풋으로 변환해주는 것
복잡한 고수준의 함수를 만들어내는 과정은 까다로울 수 있는데, 머신러닝이 이 과정을 도와주게 되는 것!
- 파라미터를 활용해 함수들의 공간을 정의
- 데이터를 사용해 얼마나 틀렸는가를 측정
- 틀린 정도를 최소화하는 파라미터 찾아내기
📍딥러닝 Deep Learning
딥러닝은 심층신경망 구조의 모델을 사용하는 머신러닝의 일종!
✒️ 모델과 데이터
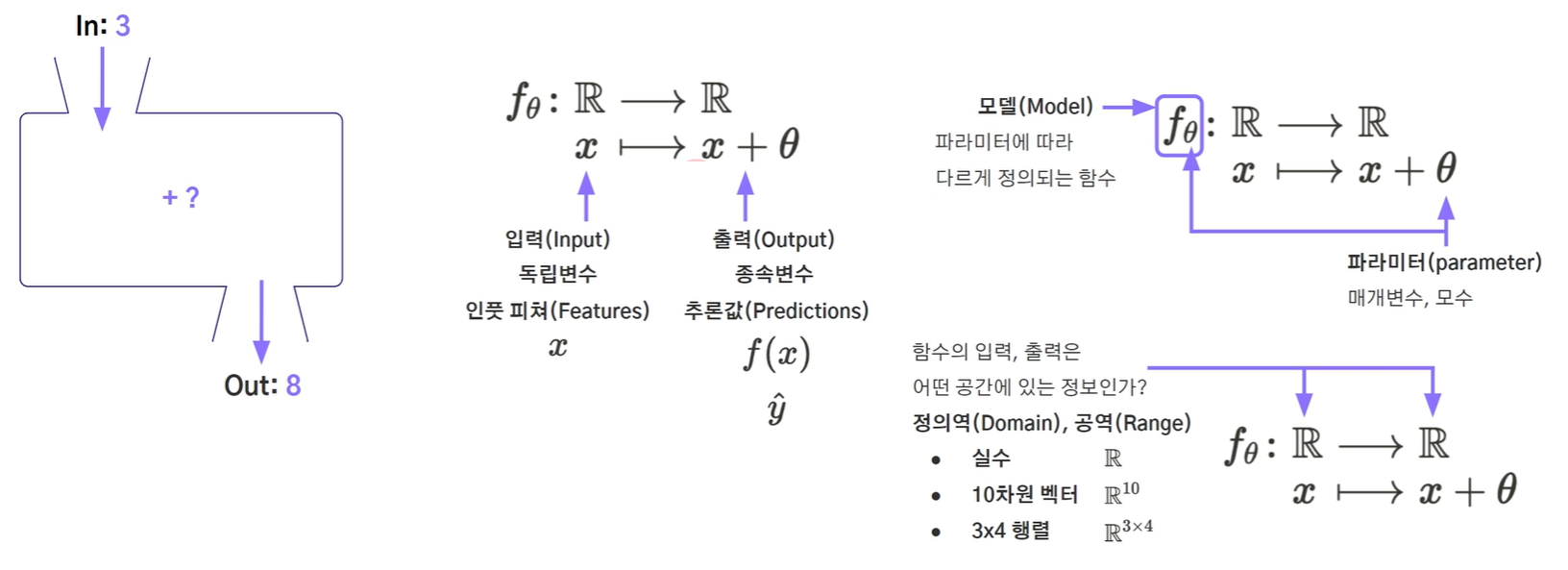
-
여기서 y는 실제 output값 (정답/목표값)이고, y^은 추측값을 의미
-
손실값(loss) : |y-y^|
📌 머신러닝에서의 학습
학습을 한다는 것은
- 정해진 parmetric 함수, 즉 모델에서
- 데이터의 인풋값에 대한 모델 예측값과 라벨의 차이로 계산되는 손실함수를 최소화하는
- 파라미터 θ를 찾아내는 것
다양한 머신러닝 방법론은
- 어떤 구조의, 어떤 파라미터를 가진 모델을 사용하는가?
- 함수의 인풋/아웃풋은 어떤 것인가?
- 어떤 손실함수를 사용하는가?
📌 머신러닝을 위한 문제정의
인풋, 아웃풋을 숫자로 표현하기
머신러닝 모델을 만들기 이해서는 주어진 데이터를 전부, 사람에게 익숙한 형태가 아닌 벡터나 행렬 같은 숫자의 형태로 표현해야 한다.
🔻데이터의 종류
- 정형 데이터 Structured Data
- 데이터를 표현하는 변수들이 의미를 가진 정량적 정보로, 주로 테이블 형태로 구조화 되어있는 데이터셋
- ex. 엑셀 스프레드시트, CSV(Comma-Separated Values)파일
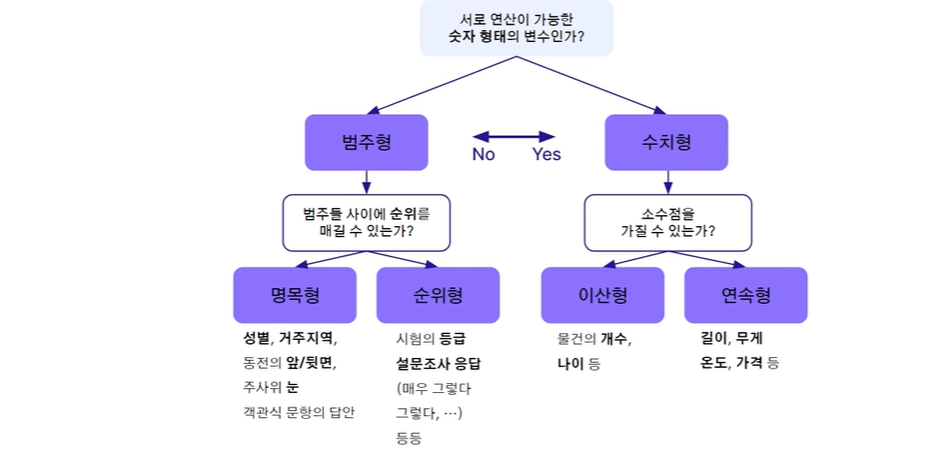
- 수치형 변수 Numerical Variable : 양적 변수라고도 하며, 평균 값 등의 수치적 연산이 가능한 숫자 형태의 변수
- 범주형 변수 Categorical Variable : 질적 변수라고도 하며, 가능한 여러 범주들 중 하나(또는 여러개)를 고르는 형태로 표현되는 변수
- 비정형 데이터 Unstructured Data
- 변수들이 구조화 되어있지 않은, 정성적 정보로 구성된 데이터셋
- ex. 텍스트, 이미지, 동영상, 음악, 녹음파일 등
그렇다면 데이터를 어떻게 숫자로 표현할 수 있을까?
📌 데이터의 수치적 표현방법
📍 범주형 데이터의 인덱싱(Indexing)
각 범주의 순서를 임의로 정해, 0번부터 번호를 부여(indexing)하여 표현하는 방식
ex)
- 성별 : 여성(0), 남성(1)
- 거주지역 : 서울(0), 경기(1), 강원(2), 충청(3), 전라(4), 경상(5), 국외(6)
- 영어 알파벳: a(0), b(1), ... z(25)
📍 텍스트 데이터의 글자별(Character-level), 단어별(Word-level) 인덱싱
텍스트를 구성하는 각 글자, 또는 단어를 인덱싱하면 문장도 숫자로 표현이 가능
📍 자연어처리 (NLP, Natural Language Processing)
📍 비트맵(Bitmap)
이미지를 수치형 데이터로 변환할 때 사용하는 기법으로, 빛의 3원색인 빨강, 초록, 파랑색(RGB)의 강도를 0~255사이 정수로 나타내어 색상을 길이 3의 벡터로 표현하고, 이를 이미지의 해상도(가로길이x세로길이)만큼 쌓아 전체 이미지를 표현하는 방식
동영상의 경우는 이미지 데이터를 여러장 겹친 것으로 이해할 수 있다 (일반적으로 영상 1초마다 24~60장)
📍 컴퓨터 비전 (computer vision)
이미지나 동영상 데이터를 주로 다루는 머신러닝의 연구분야
📍 Raw Wave 표현방법
음성 데이터의 수치형 데이터로의 변환 방법으로, 마이크에서 들어오는 (-1에서 1 사이의) 음성 신호를 일정 주기(sampling rate)로 샘플링하여 저장한 형태의 데이터
보통 샘플링은 1초당 44, 100번(44.1kHz) 또는 48,000번(48kHz)씩 진행
📍 추천시스템 Recommender System
개인의 관심사에 맞는 컨텐츠를 제공하는 방법에 대해 연구하는 머신러닝의 분야로, 다양한 형태의 정형, 비정형 데이터를 함게 다룬다.
- 유저가 남기는 평점, 좋아요/싫어요 등 피드백 정보
- 웹페이지 방문 기록, 구매 기록 등
📌 데이터의 품질과 EDA
좋은 데이터는 어떤 데이터여야 하는 것일까~?
- 다양한 인풋에서 학습할 수 있도록 다양성이 크고
- 모델 성능을 떨어뜨리는 노이즈가 적은
데이터셋이 필요하다
📍 데이터셋의 다양성 (Diversity, Coverage)
소득수준에 따른 정신건강지수를 조사해보면 아래 그림처럼 점차 기울기가 감소하는 형태를 보인다
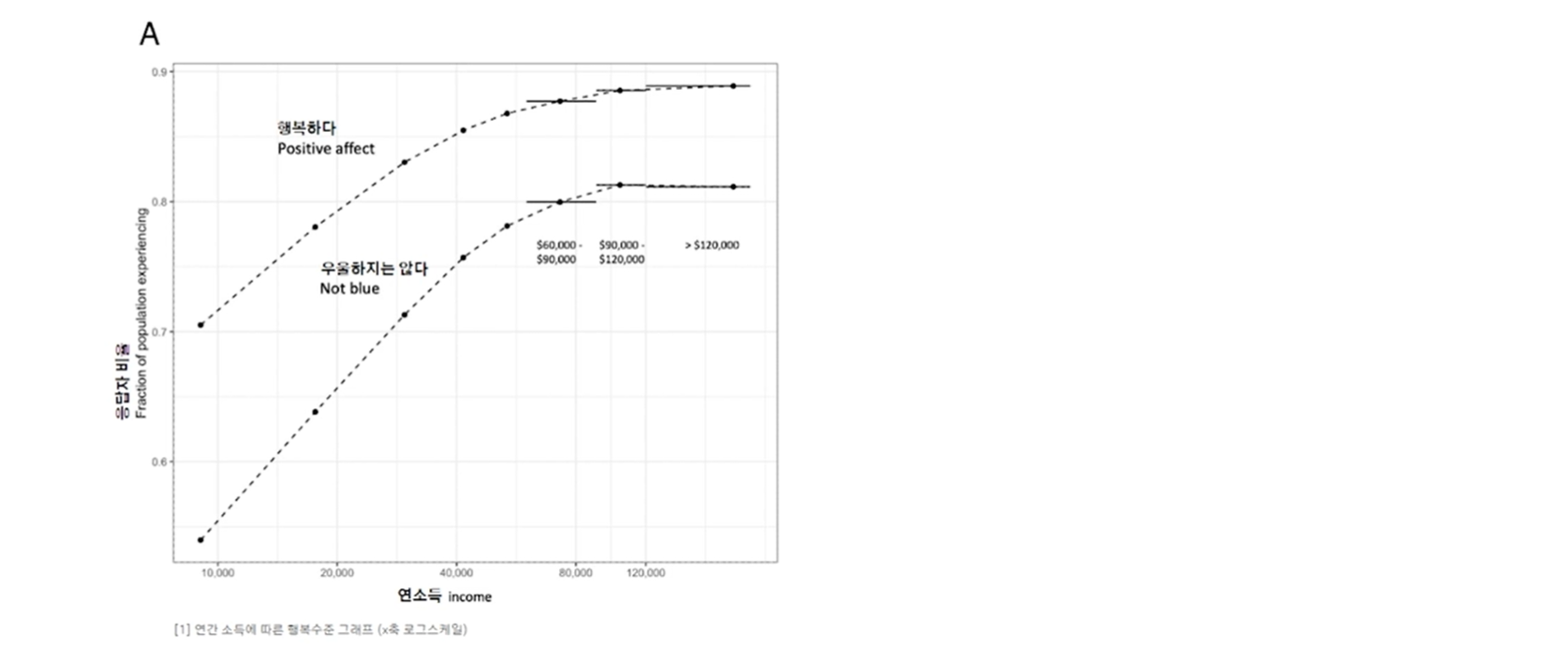
만약 같은 조사를 하면서...
- 연소득 20,000$ 상대적 저소득자에게만 설문을 했다면?
- 또는 연소득 100,000$를 넘는 고소득자의 데이터만 있었다면?
데이터셋이 커버하지 못하는 부분이 있다면 데이터셋 편향(Bias)이 생겨 전체의 경향성을 파악할 수 없다!
📍 데이터 노이즈
머신러닝에서는 만들고자 하는 기능, 함수를 데이터를 통해 정의하는데, 데이터의 노이즈가 있는 경우 함수 정의 자체가 모호해지거나, 불연속 함수가 되어 성능이 떨어진다
대표적인 데이터 노이즈의 예시
- 결측치
- 이상치
- 틀린 라벨
- 중복 샘플
- 도메인 외의 샘플
🔻 결측치
- NaN (Not a Number)
- NA (Not Available)
- null
등으로 다양하게 표현되는, 데이터 내에 아예 비어있는 값으로, 측정 자체가 안되었거나, 저장/변환과정에서 정보가 손상되었거나, 데이터셋을 읽어올 때 테이블 구조를 잘못 파싱하는 등 다양한 원인에 의해 발생할 수 있다
🔻 이상치
이론상 가능한 범위를 벗어나 있거나, 정상 분포에서 크게 벗어난 값
전자의 경우 확실히 노이즈로 판단할 수 있지만, 후자는 추가 분석이 필요하다
🔻 틀린 라벨 incorrectness
- 단순 실수로 라벨링이 잘못된 경우
- 누가봐도 4라고 써있는 이미지에 7이라는 라벨이 붙여있는 경우 등
- 문제 자체가 너무 어려워서 사람이 보아도 정확한 정답이 뭔지 고르기 쉽지 않은 경우
- 번역 모델은 직역을 해야할까 의역을 해야할까?
🔻 문제 정의의 모호성 ambiguity
사람이 봐도 어느 쪽이 정답인지 의견이 갈리는 경우
🔻 중복 샘플 duplicates
데이터셋에 똑같은 입력값을 가진 샘플이 여러번 들어있는 경우로, 서로 다른 라벨이 붙어있다면 더 큰 문제를 일으킴
🔻 문제 정의의 모호성 ambiguity
모델에서 다루려고 하는 대상이 아닌 것들이 인풋으로 들어오는 경우
ex. 사람 얼굴 사진 데이터에 섞여있는 손그림
ex. 한국어 → 일본어 번역 데이터에 끼어있는 영어문장
📍 Silent Failure
모델의 학습을 실행했을 때,
- 코드가 에러없이 잘 돌아가고
- 손실함수 값도 정상적으로 떨어지는 것처럼 보이지만
몇분 또는 며칠 후 학습이 완료되고 평가를 해보면, 전혀 사용할 수 없는 수준의 성능을 보이는 경우가 있는데 이를 Silent Failure(조용한 실패)라고 한다
문제가 있다는 사실조차 긴 시간이 지나야 파악이 가능하기 때문에, 전체 프로젝트의 진행이 크게 지연되어 일반적인 에러보다 훨씬 위험하다.
다양한 원인에 의해 발생하지만 상당수가 데이터 혹은 전처리의 문제로 발생한다!
따라서 좋은 데이터를 만들기 위해서는...
🪄노이즈 처리를 위한 좋은 데이터 만들기
- 수시로 EDA를 통해 데이터를 들여다보며 노이즈를 확인, 정제하거나
- 모델의 성능이 이상하게 나오는 경우, 원인을 분석하여 발생할 수 있는 노이즈의 샘플들을 수집, 분류한다
🪄 데이터셋 라벨링 기준의 설정
수집, 분류한 데이터 노이즈를 기반으로
- 애매한 샘플에 대해서는 명확하고 구체적인 라벨링의 기준 (가이드라인)을 설정하며
- 데이터셋 전체에 일관성 있게 적용하면
데이터셋의 품질을 크게 높일 수 있다.
📌 EDA
- EDA (Exploratory Data Analysis, 탐색적 데이터 분석)
- 데이터를 탐색함으로써 각 변수의 의미와 특성, 분포를 이해하는 과정
- 데이터에 대한 명확한 이해를 통해 정확한 문제 정의와 모델링을 가능하게 하고, 빠르게 다양한 가설을 세워보고, 분석을 통해 검증하면서 문제의 정의와 접근방법을 고민한다
- 데이터를 살펴보면서
- 데이터셋이 어떤 종류의 노이즈를 포함하는지, 어떤 편향이 생길 수 있는지 파악하고 해결방법을 고민한다
- 데이터를 탐색함으로써 각 변수의 의미와 특성, 분포를 이해하는 과정
EDA의 진행과정
📍 1. 데이터의 기본적인 정보 파악
데이터셋을 열어 다음과 같은 기본적인 정보를 파악한다
- 데이터 전체의 샘플 수 , 변수(feature) 수와 종류
- 각 변수가 주어지는 형태와 데이터타입(범주/수치형)
- 수치형 변수라면, 이론상 나올 수 있는 수치의 범위는?
- 범주형 변수라면, 가능한 범주들은 어떤 것인가?
- 비정형으로 주어지는 변수가 있는가?
이 과정에서 확인할 수 있는 형태의 노이즈
- 각 변수가 결측치를 포함하는지 여부
- 이론상 가능한 범위를 벗어나는 값 (가격 정보인데 음수가 존재하는 경우 등)
📍 2. 이상치와 결측치의 파악
데이터 내 결측치나 이상치가 없는지 확인하여 분석 과정에서 생길 문제를 사전에 방지
NULL, NaN 등의 결측치가 왜 생겼는지, 원인을 파악해 처리방식을 고민하고 데이터의 전반적인 특성에서 어긋난 이상치가 있는지를 확인한다
ex. 사람들의 키 데이터에서 어떤 샘플이 17.5로 기록되어있는 경우 결측치일 가능성이 높음!
또한, 숫자에는 한계가 없지만 컴퓨터는 정해진 자릿수의 2진법 표현으로 숫자를 저장하므로 다룰 수 있는 숫자의 범위에 한계가 있을 수 있다.
이 범위를 초과하는 경우 Overflow라는 현상이 일어난다
ex. int32(32비트 정수)타입이 저장할 수 있는 가장 큰 수는 2,147,483,647인데, 유튜브에서는 영상의 조회수를 int32타입으로 저장했었는데 강남스타일 뮤직비디오의 영상 조회수가 이 한계에 도달하자 조회수가 음수인 -2,147,483,648으로 표시되는 현상이 있었음
(유튜브도 강남스타일 같은 경우를 생각 못한게지...케케케.. 우리나라 쵝오..)
📍 3. 박스플롯 boxplot
데이터의 이상치를 파악하기 위한 시각화 방법
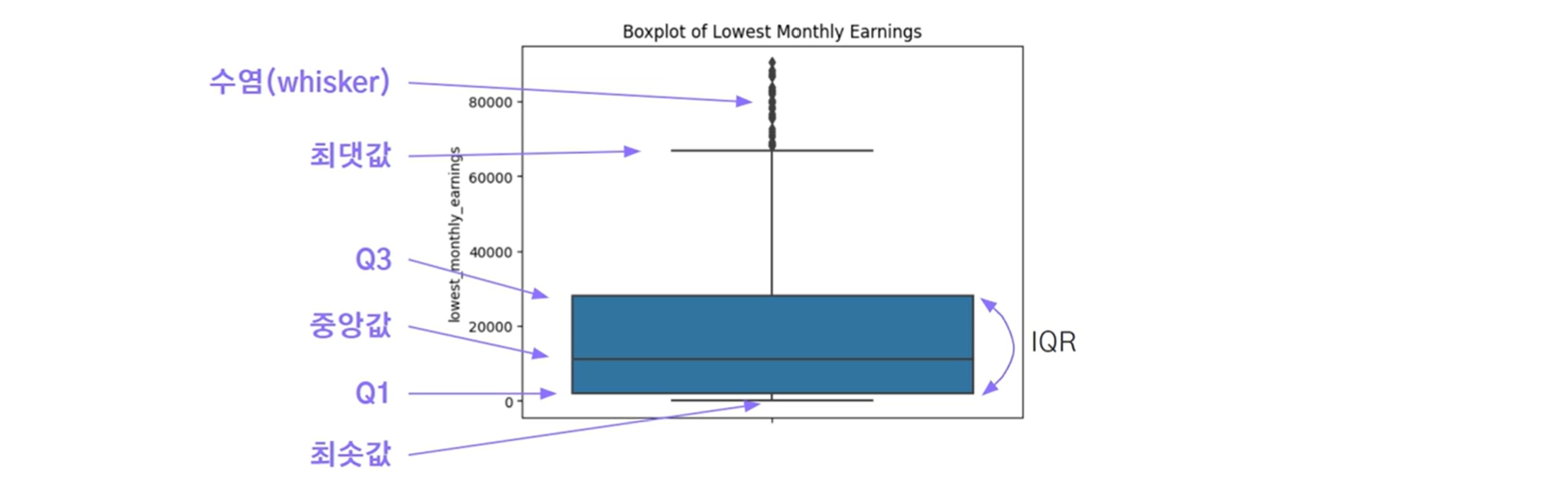
다음 5개의 요약 통계량을 하나의 박스와 선으로 표현
- 최솟값
- 사분위수 (Quantile)값
- Q1: 25%
- 중앙값 : 50%
- Q3 : 65%
- 최댓값
📍 4. 데이터의 기본적인 정보 파악
✒️ 지도학습 방법론
✒️ 비지도학습 방법론
✒️ 다양한형태의 데이터 처리와 ML 기반의 추천 시스템
✒️ 모델 평가와 개선
