🪄 Day 3
✒️ Statistical Inference
- 통계적 추론 (Statistical Inference) : 표본의 통계량으로부터 모집단의 모수를 추정하는 것
- 모평균을 추정하기 위해서는 표본평균을 보고, 모분산을 추정하기 위해 표본분산을 활용해야함
- 해당하는 통계량을 어떤 식으로 활용하느냐에 따라 점추정(point estimation)과 구간추정(interval estimation)으로 나뉨
이때, 통계적 추론은 조사자의 관심에 따라 모수의 추정과 모수에 대한 가설검정이라는 두가지 문제로 나눌 수 있다
- 모수의 추정 : 미지수인 모수에 대한 추측 혹은 추측치를 그 수치화된 정확도와 함께 제시하는 것
- 모수에 대한 가설검정 : 모수에 대한 여러가지 가설들이 적합한지 혹은 적합하지 않은 것인지를 추출된 표본으로부터 판단하는 것
들어가기 앞서 간략하게 정리를 해보자면...
🔹 x를 하나의 값으로 추정 → 점추정
🔹 x를 포하할만한 적당한 구간을 정함 → 구간추정
🔹 x 값이 5년 전의 평균값인 y와 다른지 판단 → 가설검정
📌 Point Estimation
- 점추정(point estimation) : 표본의 통계치 하나로 모수를 추정하는 방법
예를 들어 생각해보자
대한민국 남자의 평균 키를 알아내기 위해 어느 작은 읍단위 지역 전체의 남성을 대상으로 키를 평균내어 168.64cm라는 수치를 얻었다고 가정해보자.
이는 표본평균의 값 중 하나일 것!
이 지역의 인구를 정확히 알 수 없지만, 시골임을 가정했을 때 연령대가 고루 분포해있을 가능성이 낮기 때문에 해당 값으로 전체 집단의 모수를 추정하기엔 신뢰도가 많이 부족할 것이다.
그럼 부산 전체의 남성을 대상으로 평균 키를 산출한다면 어떨까?
📌 Interval Estimation
- 구간추정 (interval estimation) : 점추정한 값을 기준으로 interval을 부여하여 추정하는 것
- 즉, 추정량의 분포를 이용하여 표본으로부터 모수 값을 포함하리라고 예상되는 구간을 제시하는 것
- 이때 제시되는 구간을 신뢰구간(confidence interval)이라 부름
신뢰구간은 대개 (L,U)의 형태로 이뤄지며, L과 U는 표본으로부터 계산된다. 즉, 매 표본마다 계산되는 신뢰구간이 서로 다를 수 있다.
만약 어떤 모평균에 대한 신뢰구간으로 (-∞.∞)가 주어진다면, 어떤 표본에 대해서도 모평균의 값은 항상 포함될 것이다. 그러나, 이 신뢰구간으로부터 모평균이 실수라는 것 외에 어떠한 정보도 얻을 수가 없다.
따라서 신뢰구간을 가능한 줄일 필요가 있는데, 그러이 귀애서는 신뢰구간이 어떤 표본에 대해서도 모수를 포함해야 한다는 조건을 어느 정도는 완화시킬 필요가 있다.
즉, 신뢰구간이 모수를 포함할 확률을 1보다는 작은 일정한 수준에서 유지시키면서 구간의 길이를 줄이는 것이 좋은 신뢰구간을 만드는 기초라 할 수 있다.
이때, 모수를 포함할 확률을 보편적으로 90%, 95%, 99% 등을 사용하는데, 이 확률을 신뢰수준(level of confidence) 또는 신뢰도라고 한다
- 신뢰수준 (α)
- 예를 들어, 신뢰수준을 90%라 하자.
- 이는 100개의 표본을 뽑아 각각 모평균에 대한 신뢰구간을 제시했을 때, 그 구간 안에 모평균이 속하는 표본이 90개라 해석할 수 있다
- 한 표본에 대한 신뢰구간에 모평균이 포함될 확률이 90%가 아님을 주의해야 한다
🔻 모분산을 아는 상황에서의 모평균 구간추정
모평균(μ)의 신뢰구간을 구하기 위해 μ의 추정량 분포가 필요하다
-
표본평균
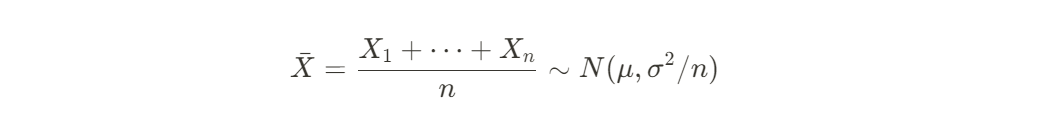
-
표준화 후 표준정규분포 상태
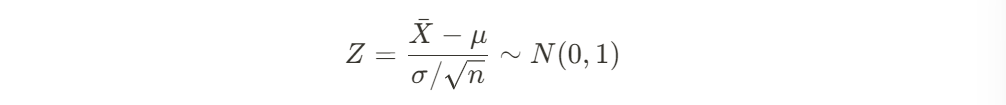
일 때
- α ∈ [0,1]에 대하여 신뢰수준이 1-α인 신뢰구간은 다음을 만족시키는 구간이다
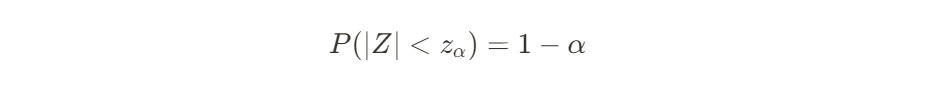
를 전개해보면...

이고 이때의 구간인
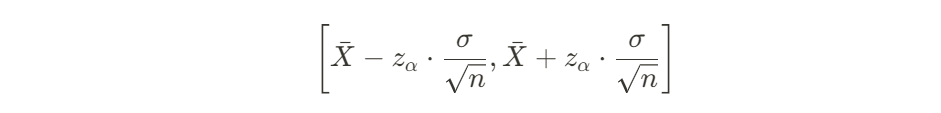
를 의미하는 것이다!
- 는 z-score라고 하고, 자주 쓰는 값으로 = 1.96, =2.58 가 있으니 알아두면 좋다~!
오해하지 말아야 할 것!
위에서 언급한 바와 같이, 한 표본에 대한 신뢰구간에 모평균이 포함될 확률이 α가 아님을 주의해야 한다
해당 신뢰구간은 확률변수에 의해 나온 구간이기에, 구간의 선택 자체가 하나가 아님을 명심해야 한다! 만약 95% 신뢰구간이라고 한다면, 100개의 표본으로부터 나온 100개의 구간이 있을텐데, 이 중 95개의 구간이 모평균을 포함하고 있을 것이란 뜻으로 해석해야 한다는 것이다!
예시를 통해 살펴보자!
아래 코드는 모집단의 분포가 인 상황에서 n=30으로 하고 20번 sampling하여 95% 신뢰구간을 표현한 것이다.
초록선이 μ(모평균)=100이며, 각 신뢰구간이 μ를 갖고 있는 경우도, 아닌 경우도 있지만 대부분 갖고 있는 것으로 나오는 것에 주목하면 된다. 95%의 확률로 포함되기 때문이다!
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
population_mean = 100 # 모집단의 평균
population_std = 15 # 모집단의 표준편차
sample_size = 30 # n
num_samples = 20 # 샘플링 횟수
confidence_level = 0.95
alpha = 1 - confidence_level
z_score = stats.norm.ppf(1 - alpha / 2)
sample_means = []
confidence_intervals = []
for _ in range(num_samples):
sample = np.random.normal(loc=population_mean, scale=population_std, size=sample_size)
sample_mean = np.mean(sample) # 표본평균의 평균값
margin_of_error = z_score * population_std / np.sqrt(sample_size)
confidence_interval = (sample_mean - margin_of_error, sample_mean + margin_of_error)
sample_means.append(sample_mean)
confidence_intervals.append(confidence_interval)
plt.figure(figsize=(12, 8))
for i in range(num_samples):
plt.plot([i, i], confidence_intervals[i], color='red', linewidth=2)
plt.plot(i, sample_means[i], 'bo', label='Sample Mean' if i == 0 else "")
plt.axhline(y=population_mean, color='green', linestyle='-', label='Population Mean')
plt.title('Confidence Intervals for Population Mean (95% Confidence Level)')
plt.xlabel('Sample Index')
plt.ylabel('Values')
plt.xticks(range(num_samples))
plt.ylim(80, 120)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()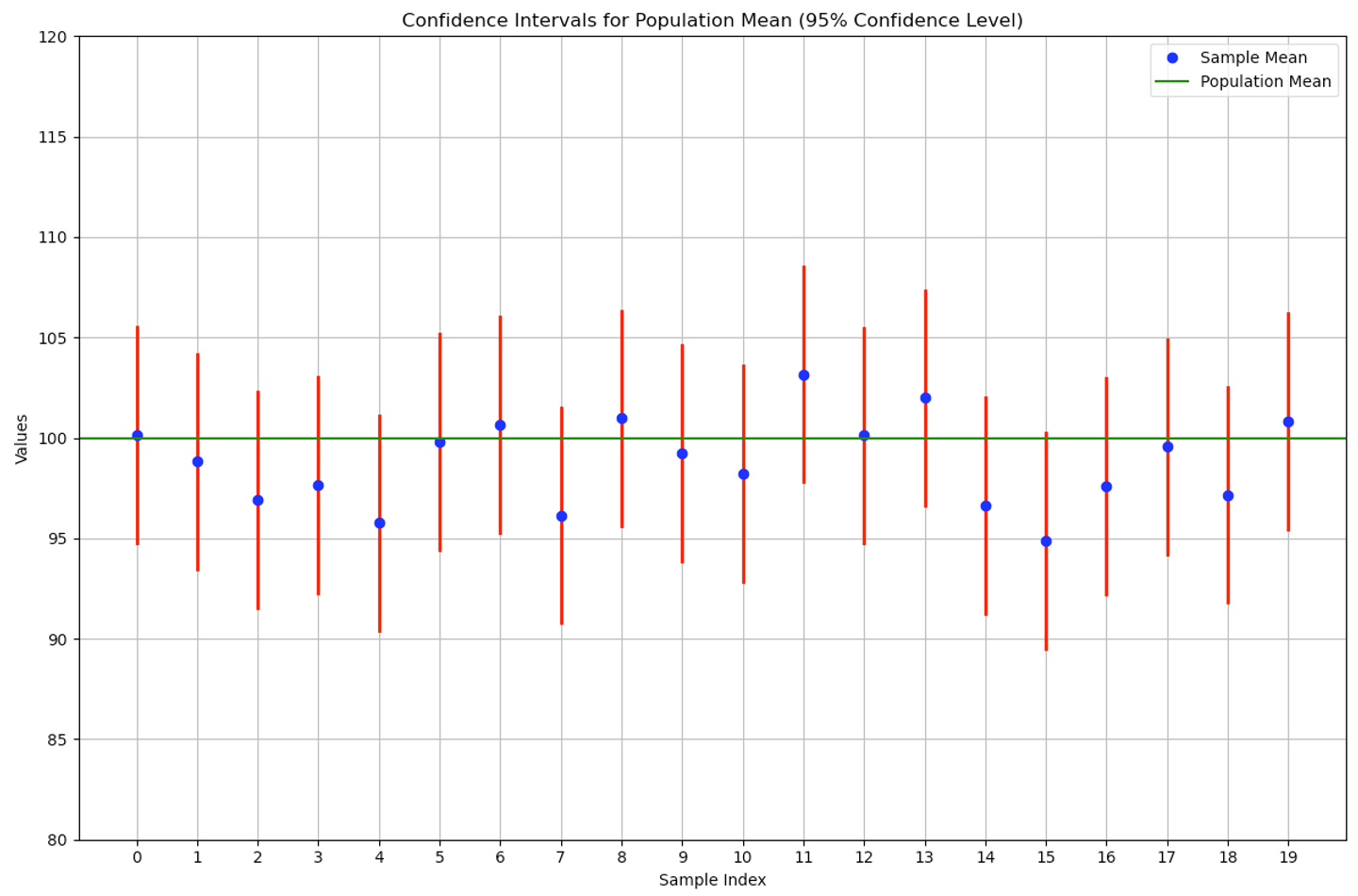
✒️ Hypothesis Test
- 가설검정 (Hypothesis Test) : 파악하고자 하는 모집단의 특성에 대한 가설을 설정하고, 이후 표본관찰을 통해 해당 가설을 채택(accept)할지, 기각(reject)할지 결정하는 통계적 방법론
🔻귀무가설 (null hypothesis) : 통념에 해당하여 우리가 통상적으로 생각하고 있는 바에 해당
🔻대립가설 (alternativie hypothesis) : 통념에 거스리지만 통계적으로 충분히 유의미하다면 받아들일 가설로, 검정하고자 하는 대상이 됨
예를 들어보자
동전을 던져서 데이터를 수집하는 상황인데, 공정한 동전이라고 생각하고 던졌음에도 불구하고 앞면이 지나치게 많이 나오는 상황이라고 가정해보자.
시행횟수가 적을 때에는 노이즈와 같이 인식했을지도 모르겠으나, 시행횟수가 충분히 올랐음에도 불구하고 앞면이 유의미하게 많이 나오고 있다면, 이 동전이 공정한 동전이 아닐수도 있다는 가설을 세우고 정말로 그런지 파악해야봐야 할 것이다!
가설검정을 진행할 때에는 두 가지의 가설, 귀무가설과 대립가설을 두고 진행한다. 위 예시에서 통념적으로 우리는 1/2의 확률로 동전의 앞면이 나올 것이라고 생각하기 때문에
- 귀무가설() : 이고
- 대립가설(): 이 된다
🔻검정통계량 (Test Statistic) : 가설을 채택하기 위해 쓰이는 판단의 기준이 되는 통계량
특정 기준하에 귀무가설을 기각하거나 채택하는 결정을 내릴 때, 표본에 의한 결정을 내리는 것이기도 하고, 특정 기준이라는 것이 어떤 기준점을 갖느냐에 따라 판단의 오류가 발생할 수 있다.

위 표와 같이 총 네가지의 경우의 수가 나온다.
<올바른 선택>
- 귀무가설이 사실인 경우에 귀무가설을 채택한 경우
- 대립가설이 사실인 경우에 귀무가설을 기각한 것
<오류 선택>
- [제1종 오류(type1 error)] 귀무가설이 사실임에도 불구하고 기각을 하는 경우
- [제2종 오류(type2 error)] 대립가설이 사실임에도 불구하고 귀무가설을 채택하는 경우
위와 같은 error는 당연히 가능한 한 작은 것이 좋을 것이다. 그 중에서도 제1종 오류에 주목할 필요가 있는데, 가설검정이라는 과정 자체가 대립가설을 검증하고 채택하고자 하는 경향을 가지고 있기 때문에, 귀무가설을 기각하는 과정에서 발생할 수 있는 오류인 제1종 오류를 최소화하고자 하는 것이다.
그렇다면 error가 얼마나 작아야 작다고 할 수 있을까? 이 역시 기준이 필요한데, 오류를 범할 수 있는 최대 허용한계치를 유의수준 *significance level)이라고 부른다.
쉽게 말하면 True인 상황에도 reject할 확률로, 채택하지 않을 이유가 없다는 뉘앙스를 가지는데 '빼박이다. 이건 채택해야만한다"라는 뉘앙스를 내포한다고 한다 (ㅎㅎ 귀여운 수학자들)
한편, 검정통계량이 귀무가설을 기각하는 영역을 기각역(ciritical region) 이라고 하는데, 예시를 통해 두 용어를 더 살펴보자.
- 예시
어느 제과 회사에서 나오는 쿠키의 무게가 해당 회사에서 공시한대로 50g인지 확인하는 작업을 한다고 가정해보자. 그렇다면 해당 쿠키의 평균 무게를 μ라고 쓸 때, 귀무가설과 대립가설은 아래와 같이 설정될 것이다.
- (귀무가설) : μ 50
- (대립가설) : μ 50
이때 조사팀이 30개의 제품을 sampling하여 평균 무게가 52g이고, 표준편차가 4g이란 결과를 얻었다고 해보자. 이는 하나의 경우이니 각각 표본평균 및 표본표준편차로써 다음과 같이 쓸 수 있다.
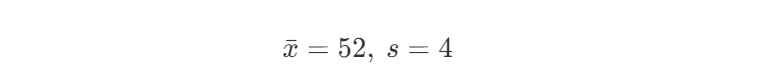
여기서 유의수준 α=0.05로 설정하고, 귀무가설이 참인 상황에서 z-score를 구해보면
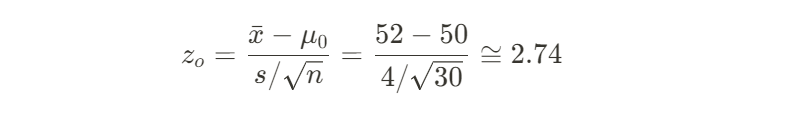
가 나오게 된다.
이때의 기각역은
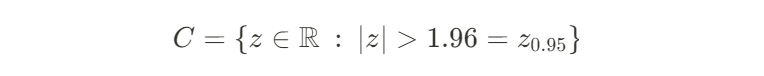
이고
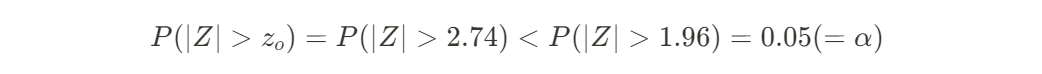
으로부터 ∈ 이므로 귀무가설을 기각하고 대립가설을 채택하지 않을 이유가 없음을 보였다.
방금까지 해서 크게 두 가지의 예를 살펴보았는데, 처음 동전 예시와 같이 대립가설을 한 쪽에 대해서만 시행하는 경우를 one-sided test, 두번째 예시의 인 것처럼 양방향에 대한 대립가설을 설정할 경우를 two-sided test라고 부른다.
🔻p_value: 귀무가설이 참일 때, 현재의 데이터를 관찰할 확률을 의미
위 예시의 경우 x=52, s=4인 경우였는데, 이때의 p_value는
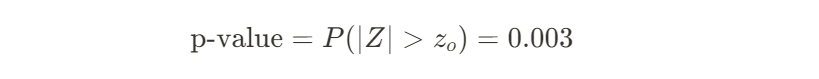
가 나온다. 이말인 즉슨, 제품의 평균 무게가 50g이었다면, 30개의 샘플에서 평균 무게가 52g 나올 확률이 0.003, 즉 0.3%란 말이다. 극단적으로 작다! 결국 제품의 평균 무게가 50g일리는 없다는 강력한 반증이 되는 것이다.
이처럼 작은 p-value는 우리가 찾은 데이터가 귀무가설의 분포로부터 오지 않았을 가능성이 높음을 말해준다. 물론 조심할 점이 있을 것이다. 애초에 운이 좋게 샘플을 택해서 이렇게 나올 수 있는 것이다. 표본의 크기가 너무 작았던 것은 아닌지, 정말로 다시 재현이 되는 것인지 등 교차검증이 필요할 것이다..!
