✒️ 딥러닝 기본 개념
📌 딥러닝 발전 단계

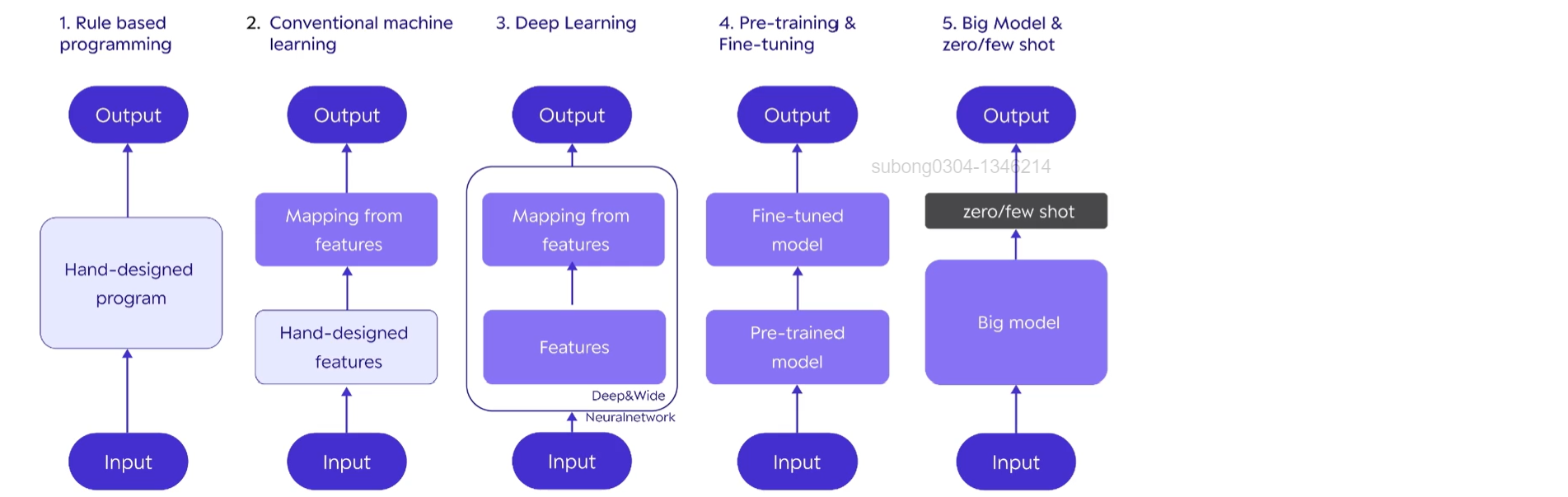
- AI/ML/DL 관점에서 크게 5단계로 개발 방법론이 진화해왔다
- 세 단계로 나눌 때는 SW1.0, SW2.0, SW3.0이라고도 부른다
개와 고양이를 구별하는 task가 있다고 해보자
각 단계에서 어떻게 구별을 해나가는지 살펴보도록 하겠다
📍 첫 번째 단계 : 규칙 기반 프로그래밍 (Rule-based programming) [SW1.0 방식]
- 규칙 기반 프로그래밍은 목표 달성에 필요한 연산 방법을 사람이 전부 고안

어떻게 계산을 해야 결과가 잘 나와?라고 했을 때 필요한 연산을 다 사람이 만들어낸다는 뜻이다.
📍 두 번째 단계 : 전통 머신 러닝 기법 (Conventional Machine Learning) [SW1.5 방식 : SW1.0과 SW2.0의 하이브리드]
- 특징값을 뽑는 방식은 기존처럼 하되, 특징값들로 판별하는 로직은 기계가 스스로 고안
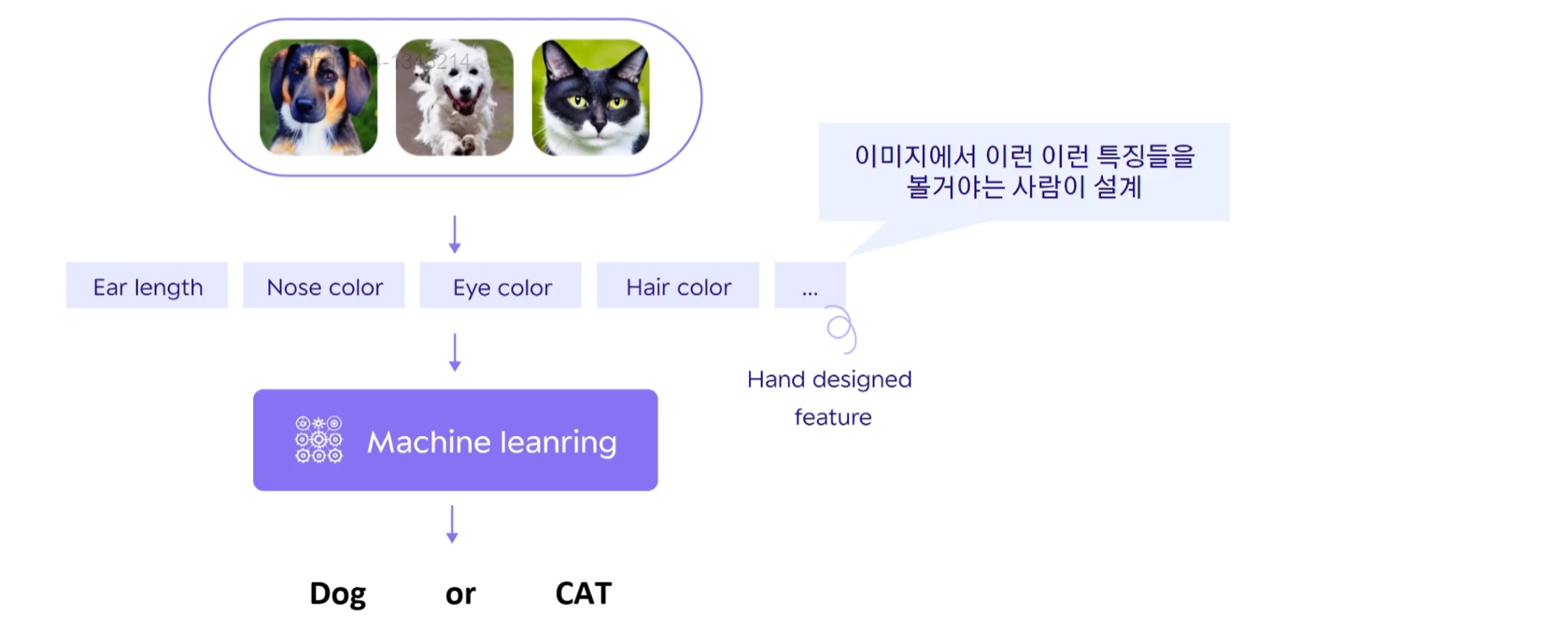
어떤 특징들을 봐야하는지를 사람이 설계하기 때문에 Hand designed feature라고 부른다
이 특징들을 가지고 판별을 하기 위한 판단 로직은 기계가 설계한다
그렇다면 이 판단 로직을 기계가 스스로 설계한다는 것을 무엇일까? 머신러닝이 학습을 시키는 과정을 살펴보자.
✔️ 머신 러닝 동작법 살펴보기
- 학습 데이터 준비
- 이미지 수집 : 판별의 대상이 되는 이미지를 수집
- 특징 정의 : 판별 대상의 특징을 정의한다
- 학습 데이터 생성 : 정의된 특징을 숫자로 변환하는 과정
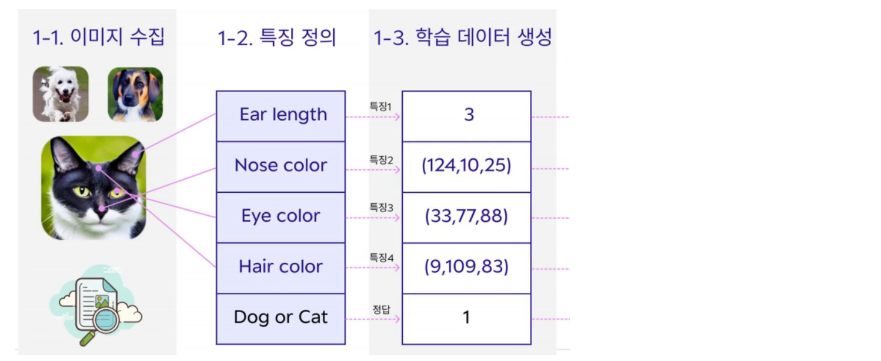
정의된 특징을 숫자로 변환하는 프로그램도 다 사람이 설계를 했었다. 설계된 프로그램을 활용해서 수치를 다 얻기까지의 과정을 학습 준비 과정이라고 한다.
- 모델 학습
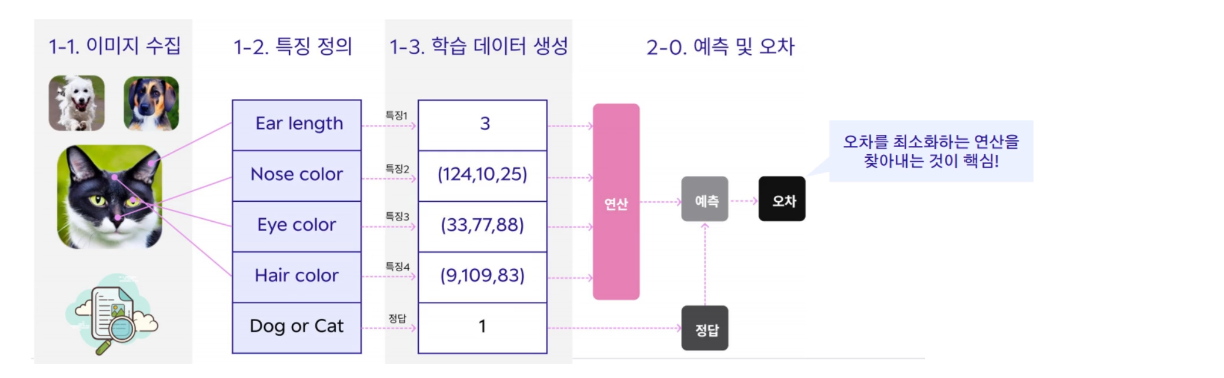
이제 학습 데이터를 가지고 계산을 통해 예측을 하고 오차를 계산한다. 여기서는 고양이를 판별하는 것이므로 고양이일 경우 1이라고 값을 사람이 부여를 해야한다. 이것을 라벨링 작업, annotation 작업이라고 한다.
특징값들을 가지고 머신러닝으로 연산을 했을 때 정답이 나오기를 기대하는데, 오차가 생기게 될 것이다. 이 오차를 최소화하는 연산을 찾는 과정을 학습 과정이라고 한다.
이 연산들은 어떻게 찾을까?
바로 Try & Error 방식으로 최적의 연산 집합을 찾아낸다.
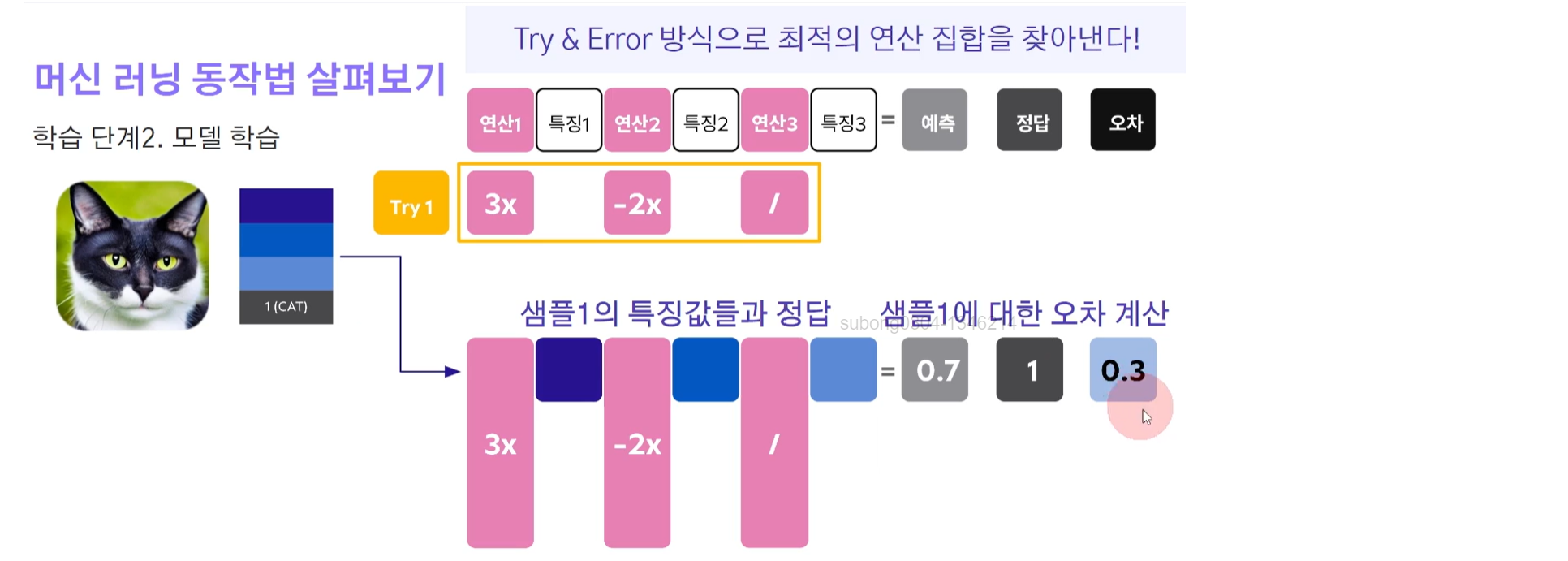
연산들을 Random하게 만들어내고 Try를 해보는 것이다. 이 랜덤하게 만들어낸 연산들이 얼마나 좋은지는 오차를 보고 판단을 하는 것!
학습 데이터셋이 3개가 있다고 하면 각각 같은 과정으로 해당 연산값으로 계산을 해보고 오차를 계산한다.
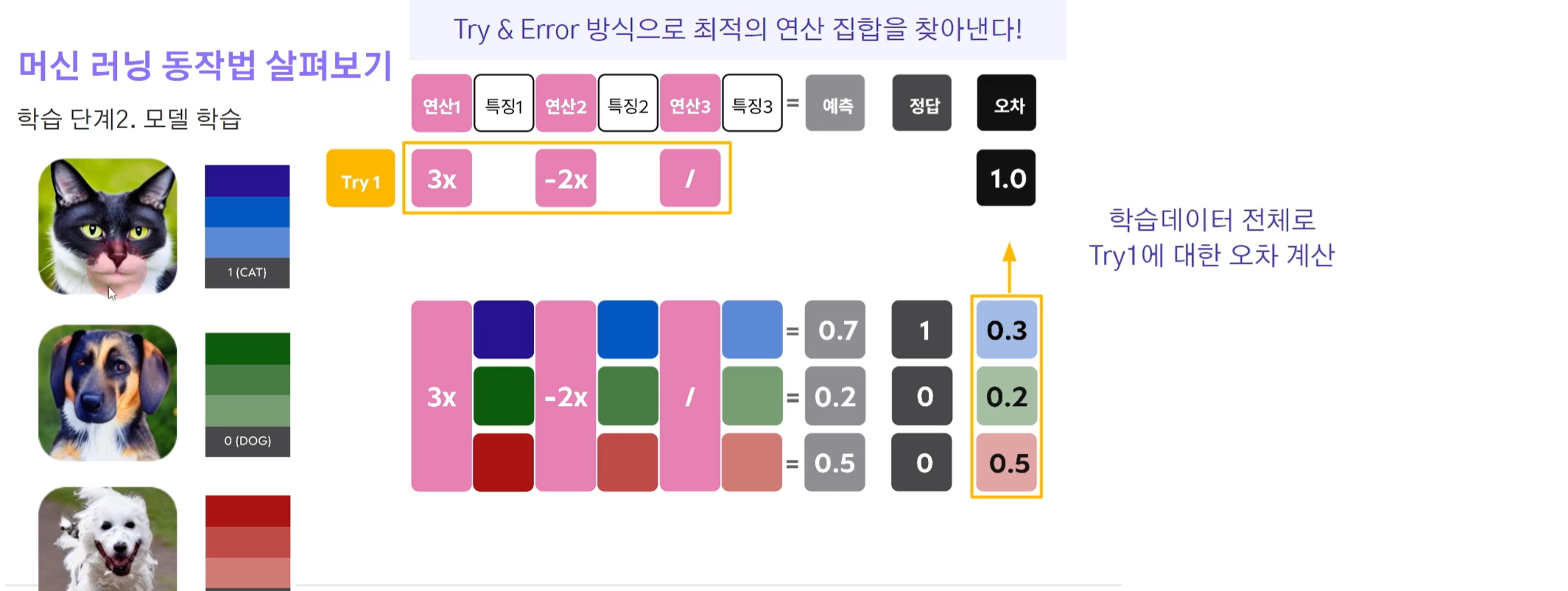
그리고 이 오차 값들을 합치거나 평균화하여 전체 오차 값을 도출해낸다.
Try 2, 3, 4... 과정을 통해 계속해서 랜덤하게 연산을 만들어내고 학습 데이터 전체로 Try n에 대한 오차값을 계산한다.
특정 n에서 멈췄다고 해보자. 학습이 멈춘 것이다.
이때 최적의 연산 집합은 모든 Try 중에 오차가 제일 작은 것이다.
= 최적의 모델
= 학습 완료된 모델
= 추론 시 사용되는 모델 (서비스 사용 시)
💭 이렇게 연산 과정을 머신러닝 방법으로 찾아냈을 때 결과가 좋다보니, 특징 값을 수치화하는 프로그램도 머신러닝으로 찾아내면 더 좋지 않을까? 라는 생각을 하게 되었다. 그것이 바로 세 번째 딥러닝 방식이다.
📍 세 번째 단계 : Deep Learning [SW2.0 방식]
- 딥러닝부터 출력을 계산하기 위해 모든 연산들을 기계가 고안
- 엄청나게 많은 연산들의 집합
- 자유도가 너무 높아 연산들의 구조를 잡고 사용
- 구조 예) CNN, RNN etc
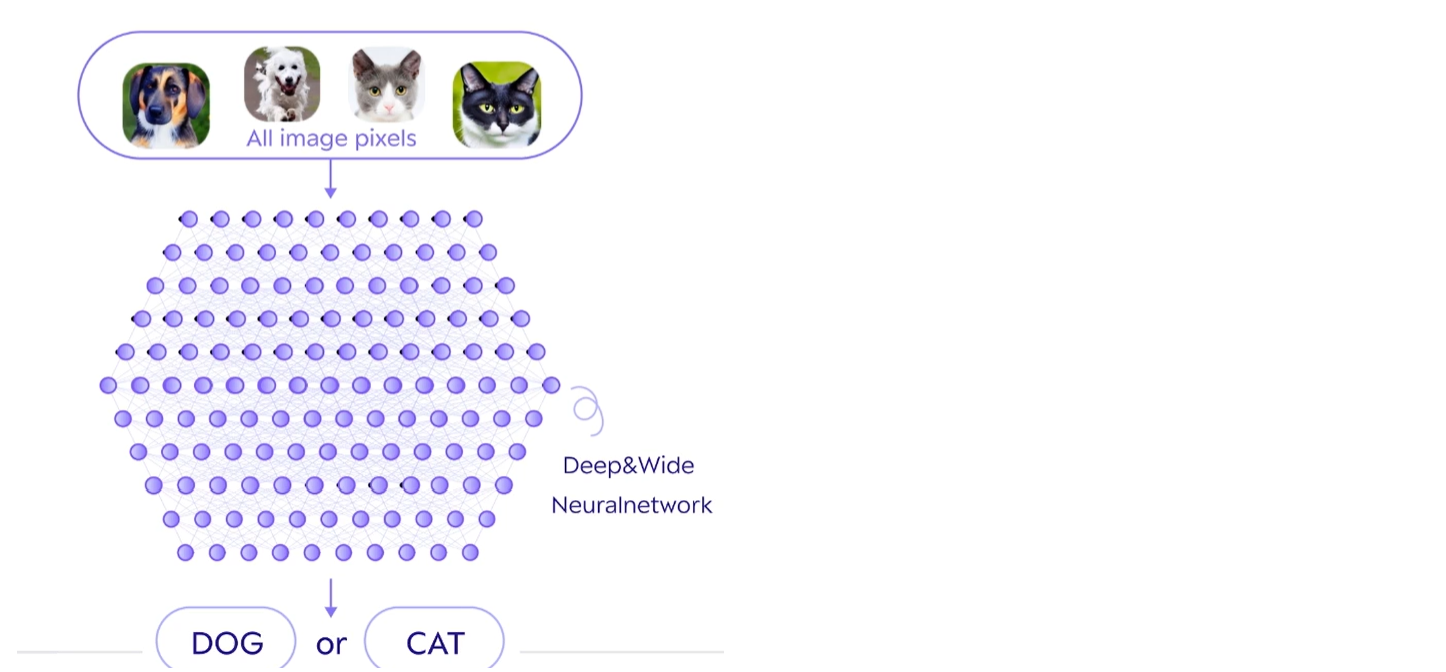
이처럼 딥러닝은 스스로 알아낼 게 더 많으니 더 많은 데이터가 필요한 것이다!
기존 전통적인 ML 방식에서와 달리 특징을 정의하지 않아도 되기 때문에 학습 데이터를 준비할 때 훨씬 편리하게 되었다.
기존에는 특징 정의가 뽑히도록 프로그램을 다 만들어줘야 했고, 그 이미지에 대한 분류 정답은 사람이 보고 직접 부여를 해야했다.
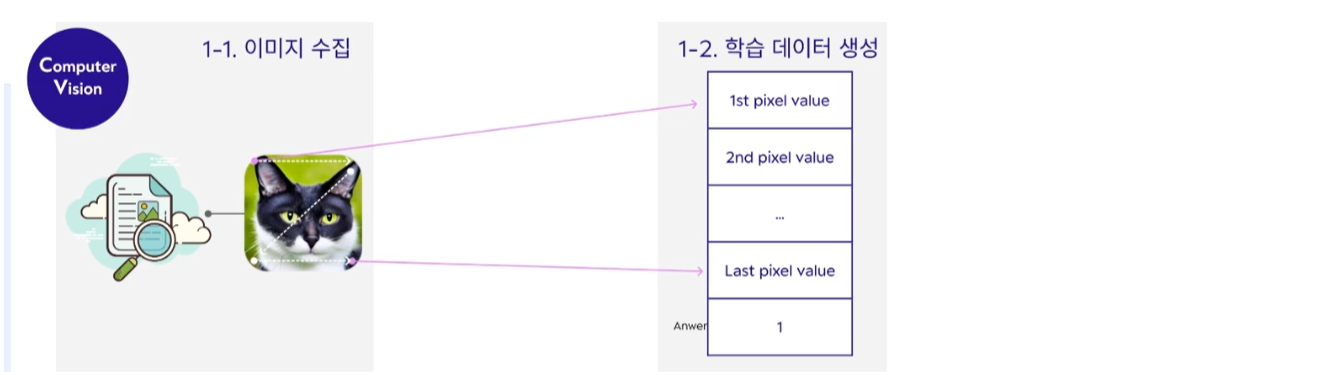
하지만 딥러닝 방식에서는 이미지 분류 정답을 사람이 부여하는 과정이 여전히 필요하지만, 특징값을 넣어주는 단계가 필요없고 이미지에 대한 값을 그대로 넣는다. 이미지는 픽셀 화소로 구성되어 있기 때문에 각각의 픽셀값을 그대로 특징값으로 넣어준다. 이미지에 있는 값을 고스란히 넣어주기 때문에 데이터 준비 과정이 훨씬 간편해진 것이다.
🔻 그렇다면 텍스트는 어떻게 다룰까?
텍스트 값을 학습 데이터 생성과정에 그대로 넣어주긴 하되, 한 번 중간 과정을 거치게 된다. 바로 토큰화 과정이다.
의미 파악이 용이하도록 잘게 쪼개는 과정이 들어가는 것이다. 이 잘게 쪼개지는 단위를 토큰이라고 부른다. 이 단위는 단어든, 글자든 방식에 따라 다르다.
"과연 잘 나올지 두근두근" 이라는 텍스트를 토큰화 했을 때 의미 파악이 용이하도록 쪼개지기 때문에 "과연, 잘, 나, 아, 오, ㄹ지, 두근두근"과 같이 사람이 생각했을 때와 다르게 토큰화 될 수 있다.
이 토큰별로 특징값이 하나씩 들어가게 된다.
텍스트 감정 분석을 할 경우에는 이 문장이 긍정인지, 부정인지에 대한 정답값(1 or 0)은 필요하고 여전히 사람이 넣어주어야 하지만, 특징값을 뽑아내고 넣는 과정은 필요없게 된 것이다.
📍 네 번째 단계 : 사전 학습과 미세 조정 Pre-training & Fine-tuning [SW2.0]
- 기존의 문제점 : 분류 대상이/ 태스크가 바뀔 때마다 다른 모델이 필요
딥러닝 기법이 워낙 강력하다 보니 더 많이 사용을 하고 싶어졌는데, 태스크나 분류 대상이 달라지면 모델을 처음부터 새롭게 만들어야 한다는 비효율성이 있었다.
- 이러한 단점을 극복하기 위해서 사전 학습과 미세 조정 과정이 들어오게 된 것이다.
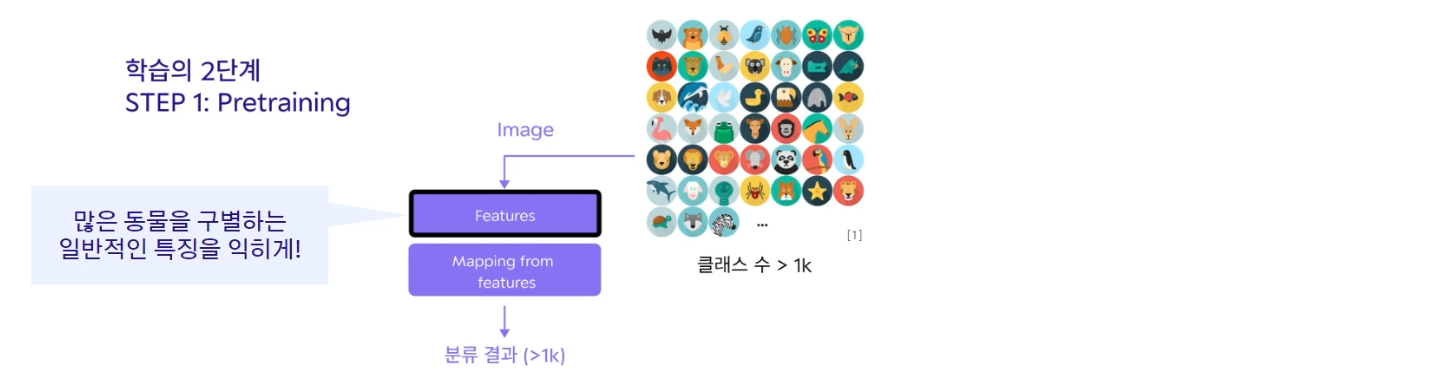
🔻 STEP 1 : Pretraining
만약 동물을 구별짓는 모델을 만든다고 한다면, 우선 많은 동물 데이터를 확보한다. 그래서 많은 동물을 구별하는 모델을 학습시킨다. 모델이 학습이 되었다는 의미는 동물이 들어왔을 때, 이런 특징들을 봐야 구별을 잘해라고 할 수 있는 연산 부분이 학습이 될 것이고, 그 특징값이 ~값일 때 특정 동물이라고 분류하는 연산도 함께 학습이 될 것이다.
🔻 STEP 2 : Fine-tuning
실제로 모델을 사용할 때 Fine-tuning 과정으로 넘어간다.
예를 들어, 판다와 토끼를 구별하고 싶다고 한다면 이 두 데이터를 넣어 학습을 시키는데 모델 전체를 학습시키는 것이 아니라 특징을 구별하는 부분은 이미 잘 학습되어 있다고 가정하여 특징 추출 부분의 연산들은 고정을 한다.
위에서 랜덤하게 연산들을 정해 오차를 계산한다고 했는데 이 최적의 연산은 고정을 하는 것이다. 판다인지 토끼인지 판단하는 부분에서만 연산들을 바꿔가면서 학습을 시킨다.
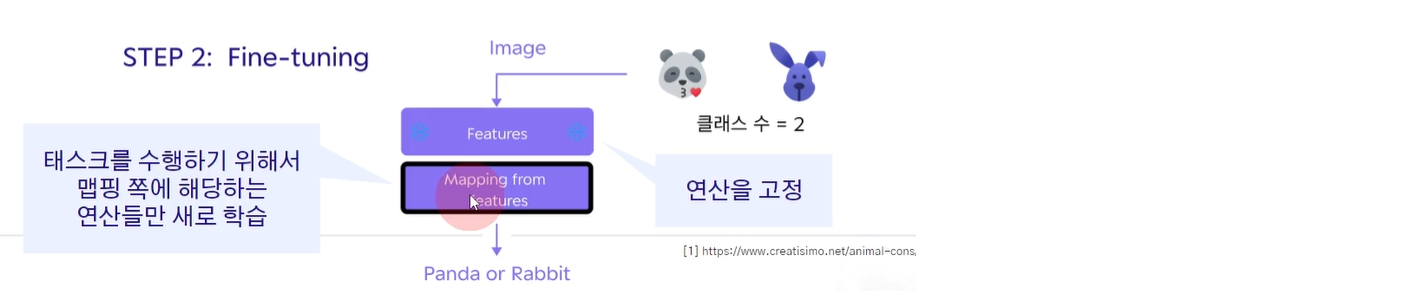
실제로 매핑하는 부분만 Fine-tuning을 하기 때문에 훨씬 더 적은 데이터를 가지고 효율적으로 모델을 만들 수 있게 되었다.
🔹 자 이제 텍스트 데이터 관점에서 살펴보자
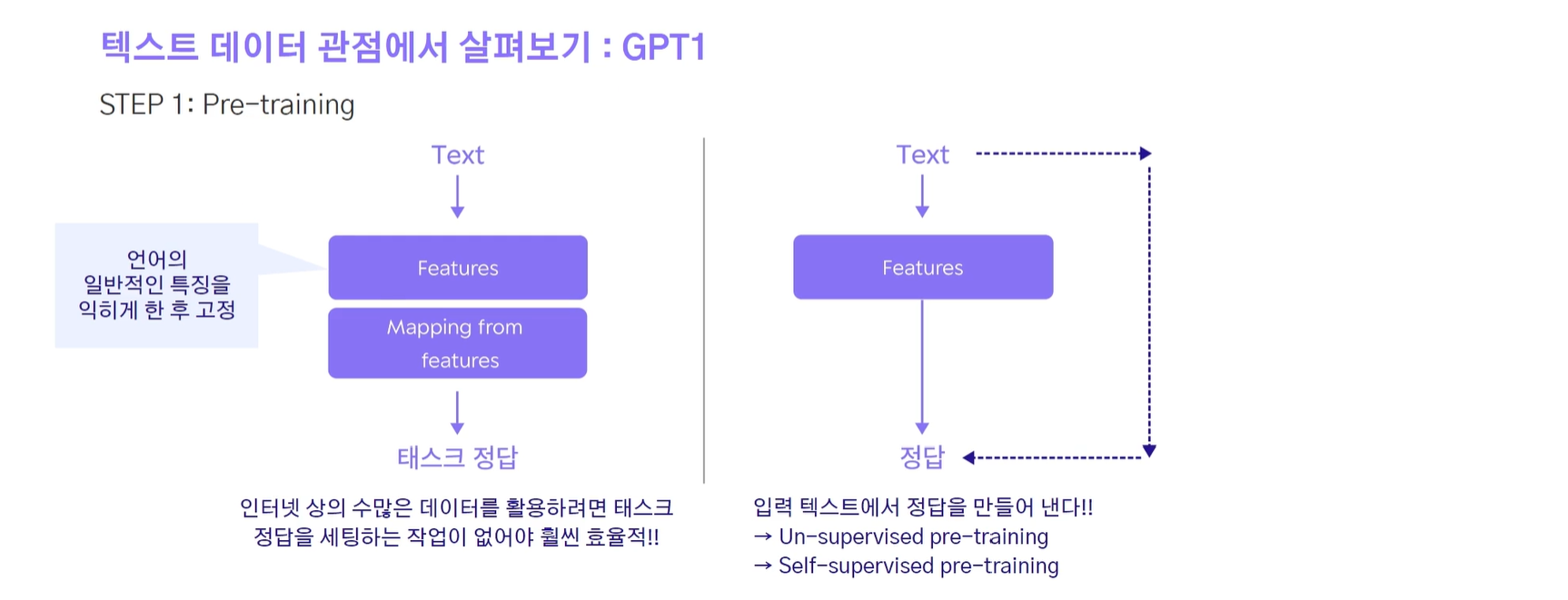
이미지의 경우 라벨링 과정이 필요했는데, pre-traning 과정에서 라벨링이 없어도 학습이 되는 어떤 태스크를 생각해냈다. 그게 바로 GPT1이다! 그래서 인터넷 상의 수많은 데이터를 활용할 수 있게 된 것이다.
텍스트의 경우 라벨링 작업 없이 어떤 Text가 입력되었을 때 정답이 자동으로 나올 수 있게 하였다. 사람의 개입이 없기 때문에 Un-supervised pre-training, self-supervised pre-training이라고 한다.
그렇다면 태스크를 무엇으로 잡았기에 자동으로 정답이 생성될 수 있었을까?
생각보다 간단하다.
입력된 데이터가 있을 때 그 다음으로 나올 단어가 무엇인지 예측하는 것을 태스크로 잡아서 모델을 학습을 시킨 것이다.
예를 들어 살펴보자.

텍스트가 들어갔을 때 다음 글자/단어를 예측하는 것이 태스크이기 때문에 전체 텍스트로부터 학습 데이터를 #1~3과 같이 생성할 수 있다.
이렇게 Pre-training을 거치면 언어의 일반적인 특징을 익혔다라고 간주를 한다. Fine-tuning을 할 때에는 만약 텍스트가 긍정적인지 부정적인지를 분류하고 싶다고 했을 때, Pre-training된 모델을 그대로 가져오고 텍스트 분류 시 매핑 부분(판단하는 부분)의 연산들만 Fine-tuning을 하게 된다.
미세 조정을 할 때 필요한 데이터는 따로 또 모아야 하는데, 이 경우에는 긍정인지 부정인지 사람이 라벨링을 한 데이터라고 할 수 있다.
Pre-training 과정에서는 사람의 개입이 필요없기 때문에 연구자들이 여기에 들어가는 데이터를 마음껏 늘려간 것이다. GPT-1에서는 5GB, GPT-2에서는 40GB, GPT-3에서는 45TB로 늘려가면서 모델의 파라미터 수도 늘릴 수 있게 되어 모델의 크기가 계속 커지게 된 것이다. 물론 성능도 계속해서 좋아지게 되었다!
GPT-3의 등장과 함께 사람들이 많이 놀라게 되었는데 그 이유를 다섯 번째 단계에서 살펴보자~!
📍 다섯 번째 단계 : Big Model & zero/few shot
- GPT-3부터 사람들이 in-context learning이 된다는 것을 발견했다
이전 단계의 Pre-training, Fine-tuning 과정에서는 여전히 테스크별로 다른 모델이 필요하지만 다른 모델을 만들 때의 효율이 3단계인 딥러닝보다는 좋다는 것이었다.
하지만 in-context learning은 태스크별로 다른 모델을 만들 필요가 없다는 의미다! (ㄷㅂ) pre-training된 모델로 충분하게 된 것!!
- 태스크 별로 별도 모델 필요 없음
- 태스크에 맞는 데이터 모을 필요 없음
Text를 넣을 때 "너는 이런 태스크를 수행해줘야해"와 같은 태스크에 대한 설명을 포함시켜 넣으면, 그 태스크가 무엇인지 pre-training된 모델이 이해를 해서 그 태스크의 결과값을 뱉어낼 수 있게 되었다
GPT-3부터 모델의 크기가 매우 커지게 되면서 가능해진 것. 특정 모델 크기 이상이 되면 in-context learning이 가능해진다는 이야기가 GPT-3 논문의 핵심이다.
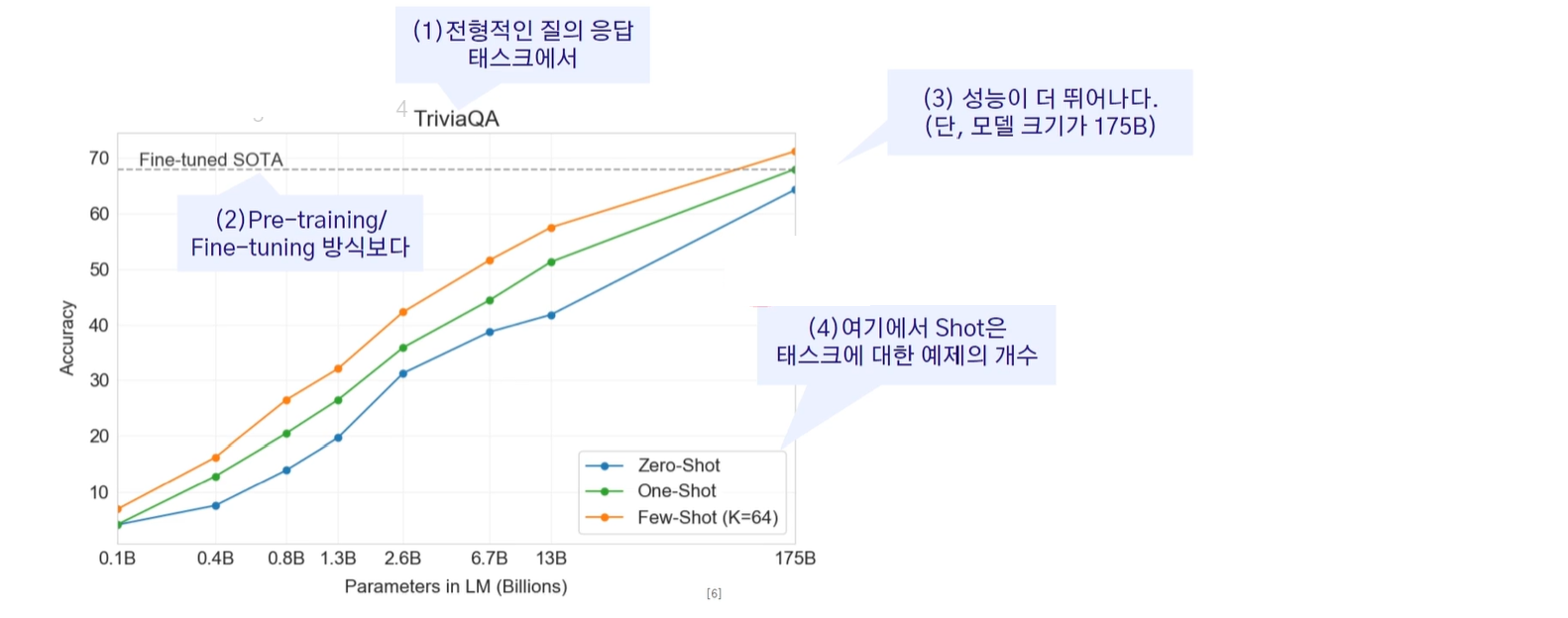
- zero-shot : 태스크 설명을 줄 때 예시를 하나도 안 들어주고 이야기 하는 것
- one-shot: 예시를 하나 들어주는 경우
- Few-shot (K=64) : 예시를 여러 개 들어주는 것인데, K=64는 64개의 시를 들어주는 것을 의미 (Fine-tuning의 효과를 주게 됨)
그래프에서 볼 수 있듯이 모델의 크기가 175B이상이 되었을 때 4단계 방법인 Fine-tuning을 한 모델보다 성능이 더 좋게 나왔다. 이렇기에 전세계가 발칵 뒤집히게 된 것이다!
📌 딥러닝 기술 종류
🔻 Overview
AI 구분법
- 데이터/학습/태스크 관점으로 구분 가능
- ChatGPT의 경우 데이터는 텍스트, 학습은 비교사 학습, 태스크는 생성인 경우에 해당
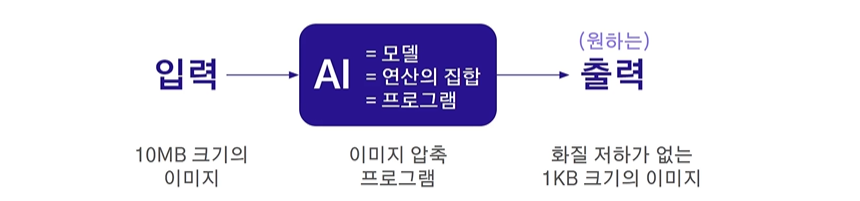
AI = 모델 = 연산의 집합 = 프로그램
- 프로그램은 특정 입력을 특정 출력이 나오도록 하는 연산의 집합
- 컴퓨터는 숫자만 이해하므로, 입력/출력 모두 숫자(들)
🔻 학습 방식에 의한 구분
정답 사용 여부, 피드벡 제공 여부, 보상 신호 제공 여부에 의해 구분
각 학습 방법별로 특징들이 뚜렷해, 그에 맞는 AI 태스크들이 존재
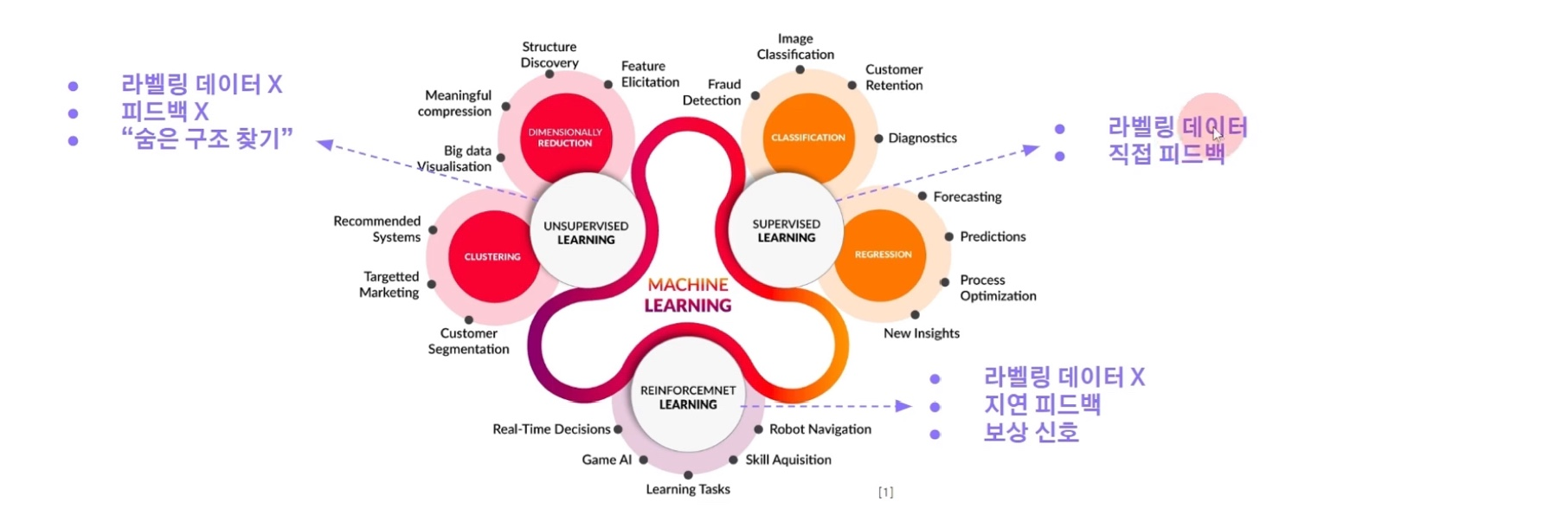
📍 교사 학습
- 라벨링 데이터를 활용 (사람이 직접 주거나, AI가 만듦)
- 직접 피드백을 제공
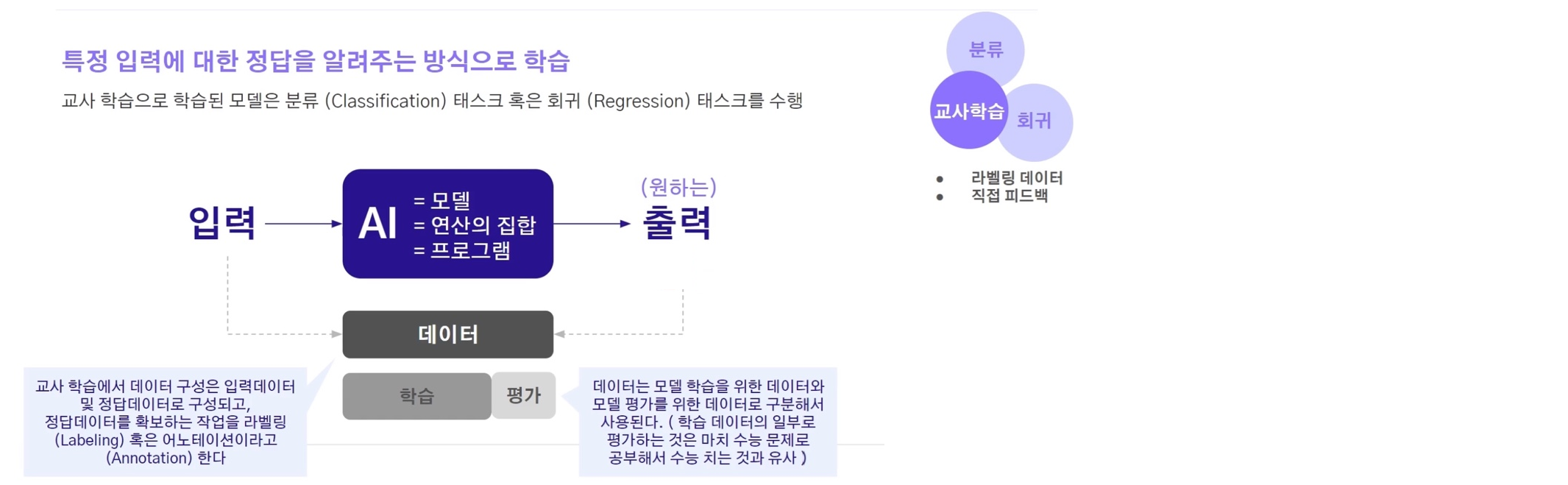
원하는 정답이 무엇인지를 직접적으로 알려주는 방식
데이터는 학습 데이터와 평가 테스트로 나누어서 사용해야 한다
🔹 Classification
- 분류는 기정의된 클래스들 중 입력이 어느 클래스에 해당하는지 맞추는 태스크
- 결과값은 클래스 종류 중 하나이므로, 양수의 정수값으로 보통 표현한다

🔹 Regression
- 회귀는 입력 데이터에 대한 실수 혹은 실수의 집합을 (벡터) 출력으로 맵핑해주는 태스크
- 즉, 숫자값을 예측하는 경우이다

🔹 Object Detection 객체 검출
- 분류와 회귀를 동시에 진행하는 경우
예시로, 음식들 이미지가 input으로 들어온다고 했을 때, 음식의 종류를 맞추는 것은 분류에 해당할 것이다. 그런 다음 음식들의 위치를 계산하도록 한다면, 좌표값이 도출이 될 것이고 이것은 회귀 문제에 해당한다
교사 학습에서 중요한 것은 데이터의 품질이다!
따라서 라벨링 노이즈에 관해 알아보자
🔻 라벨링 노이즈 (Labeling Noise)
라벨링 노이즈에 따라 교사 학습의 성능이 좌지우지 된다
- 라벨링 결과에 대한 노이즈 = 라벨 작업에 대해 일관되지 않음의 정도
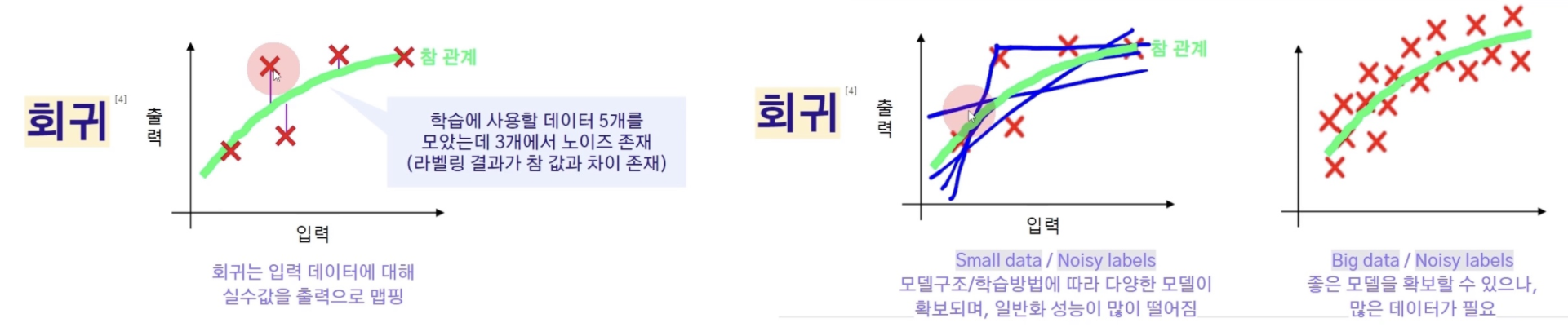
위 그림과 같이 회귀 문제를 생각해보 때, 참인 결과가 있을 것이다.
이때 학습에 사용되는 데이터가 참에 해당하지 않는 경우, 이는 노이즈라고 이야기한다.
우리가 흔히 많은 데이터가 있을수록 좋다고 이야기하는 이유는 두번째 그림과 같이, 적은 데이터인데 노이즈가 있을 경우 많은 모델이 생성되게 되어 일반화 성능이 떨어지게 되기 때문이다. 노이즈가 있더라도 많은 데이터가 있을 경우 좋은 모델이 확보될 수 있지만, 일반화가 가능할 수준의 많은 데이터가 필요하다
그럼 적은 데이터이지만 노이즈가 없는 경우가 항상 좋다고 말할 수 있을까?

노이즈 없이 다 맞아떨어지는 적은 데이터를 가지고 있을 수 있으나, 이는 전체 모델을 반영하지 않는 경우일 수 있다. 아주 적은 부분만 반영하고 있을 수 있다는 이야기다.
따라서 Balanced한 데이터를 가지고 있고, 노이즈가 적으며, 가능한 한 많은 데이터를 가지고 있는 것이 좋다고 볼 수 있다.
📍 비교사 학습
- 라벨링 데이터 X
- 입력 데이터의 숨어진 구조를 찾는 것
- 피드백 X
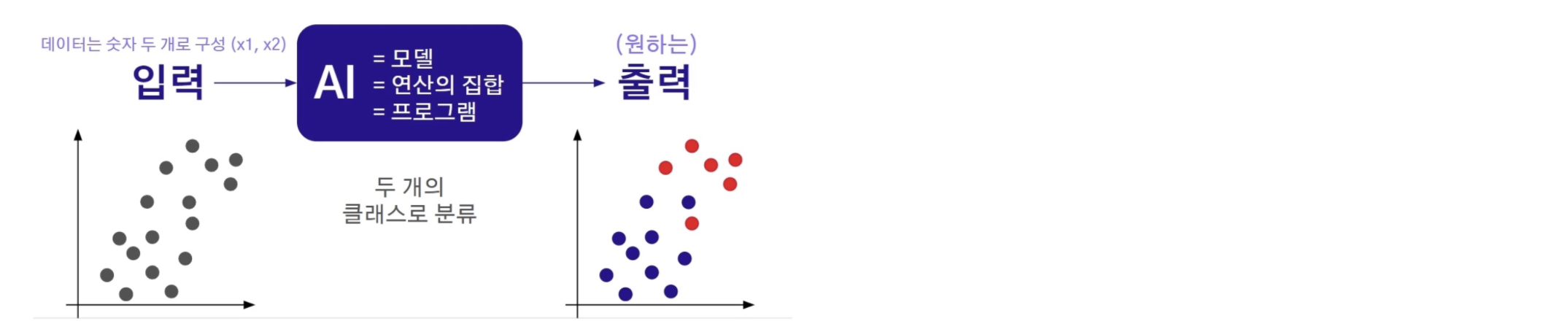
🔹 Dimensionally Reduction
차원 축소는 N차원 입력을 N>n차원 출력으로 변경하는 태스크를 의미한다
입력이 데이터 하나가 숫자 N개로 구성된 N차원 벡터일 경우, 차원 축소를 통해 출력을 데이터 하나가 숫자 n개로 구성된 n차원 벡터로 변환하는 것이다.
예를 들어, N=10만을 n=2개로 줄이는 것!
단, 어떻게 숫자 2개를 만드는게 좋을지 정답을 정하기는 어렵다
더 자세하게 알아보자
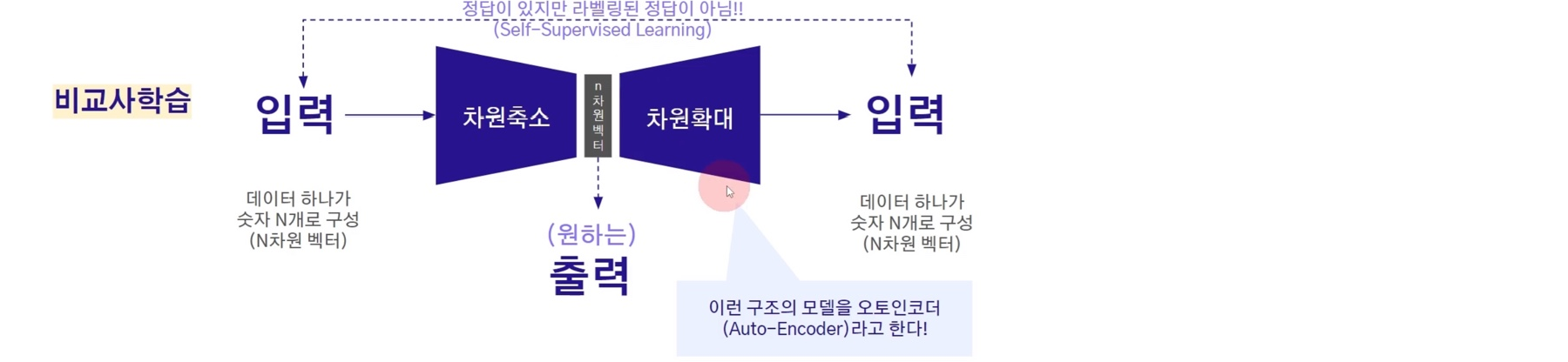
입력 데이터가 있고 차원 축소하고 싶을 때, 차원 축소를 하는 딥러닝 모델을 학습을 시키는 방법이 무엇일까?
바로 축소된 n차원 벡터를 기점으로 반대되는 모델 구조를 또 짜놓는 것!
즉, 차원 확대 모델을 만드는 것이다.
차원축소 전 입력 데이터와, 차원확대 후 (입력) 데이터가 같아지길 바라는 것.
사람이 수기로 만들어놓은 라벨링 데이터는 없지만,
입력 데이터가 곧 정답이 되어 라벨링 역할을 하게 된다. 오토인코더(Auto-Encoder)라고 한다.
이렇게 학습이 끝났으면 차원 축소에 해당하는 모델만 사용한다
차원 축소된 n차원벡터는 적어도 입력 데이터는 복원이 되도록 차원 축소가 되는 것이다!
그렇다면 차원 축소는 왜 하는 것일까?
- 정보 압축 : 이미지/비디오/오디오 압축
- 압축을 통해 용량을 줄여 저장공간을 아끼고, 통신 속도를 올릴 수 있다
- 정보 시각화 : 사람이 눈으로 확인할 수 있는 것은 3차원 (시간이 포함되면 4차원)까지밖에 안되기 때문
- 예를 들어, SNS 관계망을 시각화해서 본다면 누가 누구와 연관지어져 있는지 한 눈에 파악이 가능
- 정보 특징 : 중요한 특징을 추출하여 분석에 사용
- 중복된 특징이 있을 수도 있는데 중요한 특징만 추려서 볼 수 있기 때문에 용이
- 만약 10개 클래스가 잘 구분되는 2차원의 특징 벡터를 찾는다면 훨씬 분류 성능이 뛰어난 모델을 만들 수 있음
- 원본 데이터를 쓸 때보다 성능이 더 좋게 나올 수도 있다~!
🔹 Clustering
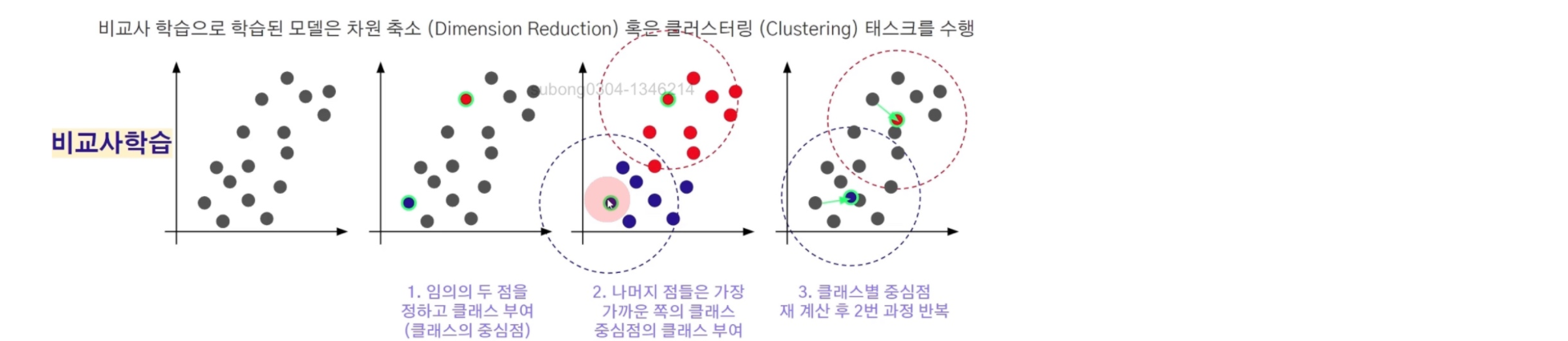
clustering도 분류 작업을 하는 것이지만, 직접 라벨링을 하지 않고 하는 방법이다
clustering 방법 중 가장 대표적인 방법에 대해 소개해보겠다
흩어져 있는 데이터 중 랜덤하게 k개의 점을 고른다.
여기서는 분류해야할 클래스가 두 개이므로 두 개의 점을 고른 것!
선정한 두 개의 centroid와 다른 점들 간의 거리를 각각 계산하여 거리가 가까운 것들을 가지고 클래스를 부여함으로써 clustering을 한다.
형성된 clustering에서 새롭게 centroid를 계산하고, 새롭게 만들어진 중심점을 기반으로 다시 점들 간의 거리를 계산해서 클래스를부여한다.
centroid가 더 이상 바뀌지 않거나 거의 바뀌지 않을 때까지 이 과정을 반복해서 clustering을 만드는 것이다!
이러한 방식을 k-평균 클러스터링이라고 하며, 클러스터링은 데이터의 군집화를 의미한다.
📍 강화 학습 Reinforcement Learning
- 사람이 적은 라벨링 데이터를 주진 않음
- 하지만 보상 신호를 부여 : 잘하고 있는지, 못하고 있는지에 대한 신호
- 이러한 보상 신호는 AI가 답변을 준 후의 피드백으로, 지연 피드백에 해당
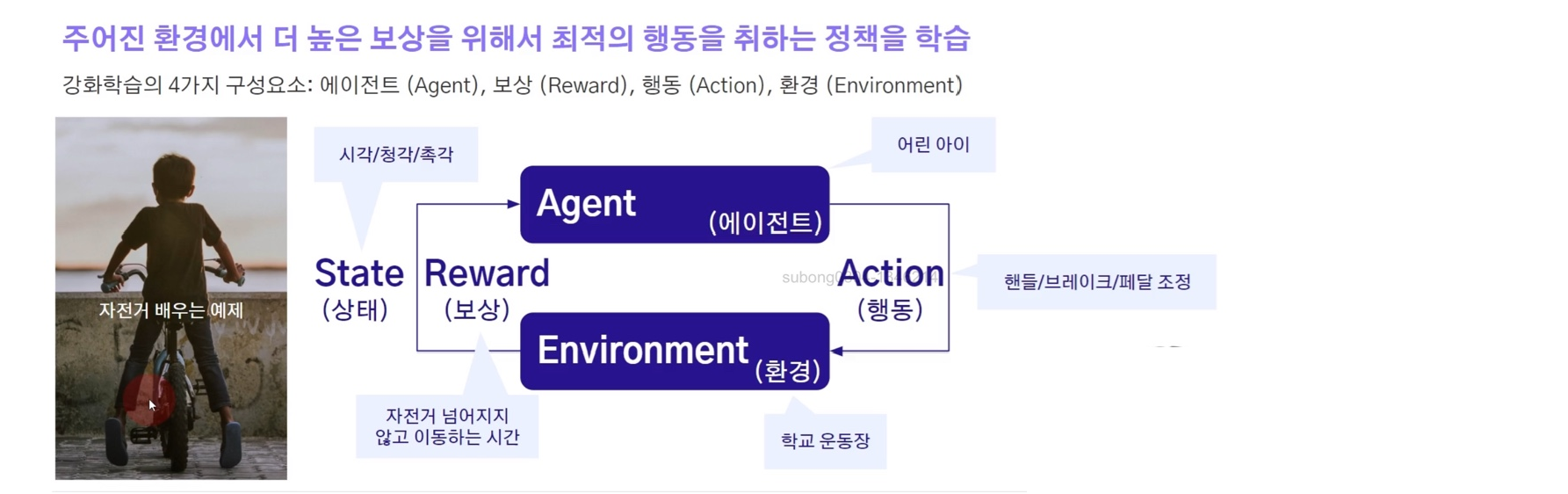
사람이 자전거를 배운다고 해보자
- 에이전트: 자전거를 조절하는 아이일
- 행동 : 핸들/브레이크/페달 조정을 하는 행동을 취할 것
- 리워드 : 자전거를 잘 탔다는 것은 넘어지지 않고 잘 탔다는 것이므로, 리워드를 자전거를 넘어지지 않고 이동하는 시간일 것
에이전트는 리워드가 최대가 되겠끔 학습이 된다
다음 예제로 비디오 게임 예제를 살펴보자
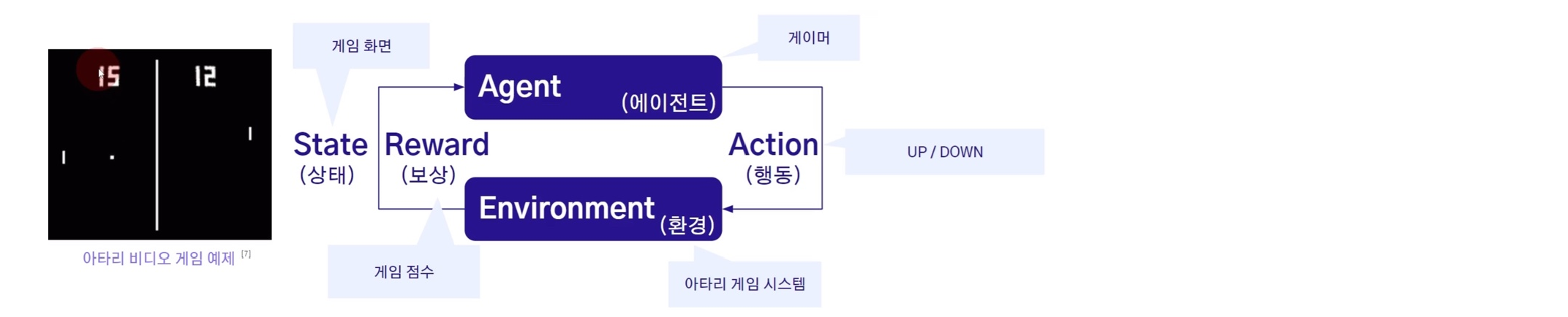
공이 박스 밖으로 튀어나가지 않도록 바를 움직여야 한다고 해볼 때 에이전트인 AI인 막대바를 아래로 내릴지 올릴지 액션을 취할 것이다.
리워드는 다양하게 세팅할 수 있지만 간단하게 게임 점수로 세팅해서 학습을 시킨 경우이다
이때 환경에 대한 상태 정보인데 이것은 화면으로 출력이 되도록 한 것이다
AI 모델 두개로 학습을 시키는 경우가 있다

- 정책을 익히는 모델 : 상태에 대하여 어떤 행동을 취해야 하는지에 대한 정책
- 보상을 예측하는 모델 : 상태와 행동값이 주어졌을 때 보상을 예측하는
🔻 태스크 종류에 의한 구분
📌 데이터 형식에 의한 구분 DATA TYPE
📍 정형 데이터 Tabular Data
- 정형 데이터 : 테이블 데이터, 즉 엑셀 형태로 표현이 가능한 데이터, 아직까지는 딥러닝이 다루기 비효율적
- 비정형 데이터 : 딥러닝이 잘 다루는 데이터로, 이미지/동영상, 텍스트, 음성 등 정형 데이터가 아닌 데이터
구조화된 정보로 저장되어 있는 것이 정형 데이터이며, 정형 데이터 외의 데이터는 다 비정형 데이터이다. 딥러닝을 통해서 비정형 데이터를 구조화된 정보로 바꿀 수 있게 되었다
📍 컴퓨터 비전 Computer Vision
- 입력으로 이미지나 동영상 데이터를 받는 AI
- ChatGPT 이전에는 가장 많이 상품화된 AI 기술이었으며, 딥러닝 기술을 선도함
이미지를 활용하여 수행할 수 있는 태스크를 살펴보면
- 얼굴 인식 → 누구의 얼굴/ 분류
- 얼굴 검출 → 얼굴의 위치 / 회귀
- 성별 인식 → 성별 / 분류
- 나이 인식 → 나이 / 회귀
또 다른 태스크로는 이미지 복원(super resolution)도 있다. 포커스가 안 맞는 이미지를 포커스가 맞게 보정해주는 작업이다
그 외에도...
- 지문 인식
- 명함 인식 (리멤버)
- 배경 제거 (누끼 따기)
- 번호판 인식
- 영수증 인식 (네이버 영수증 리뷰)
- 스타일 변환 (스노우 ai 프로필)
- 자율 주행
- 동영상 요약 (타임랩스) 등등...
📍 자연어 처리 Natural Language Processing
- 입력으로 텍스트 데이터를 받는 AI
입력 받은 텍스트로 수행할 수 있는 태스크 예시는
- 문장 작성 : 주어진 글에 이어서 문장 작성 / 생성
- 혐오글 분류 : 혐오적인 표현 존재 여부 / 분류
- 번역 : 다른 나라 언어로 번역 / 생성
- 감정 분류 : 글에서 느껴지는 감정 / 분류
📍 음성 인식/생성 Speech Recognition/Generation
- 입/출력으로 음성 데이터가 활용되는 AI
예시는...
- 음성 인식 : 음성 속에 담긴 글자 인식 / 인식
- 감정 분류 : 음성 속에 담긴 감정 분류 / 분류
- 나이 인식 : 발화자의 나이 인식 / 회귀
- 화자 분류 : 화자 별로 신호 분류 / 분류
음성 생성은 출력 데이터가 음성인 경우를 말함
📌 태스크 종류에 의한 구분 TASK TYPE
📍 인식 및 생성 Recognition & Generation
비정형 데이터와 정보의 입출력 관계에 따라 인식 혹은 생성으로 구분된다.
생성은 의도된 정보를 입력으로 넣어줄 수 있고, 비정형 데이터를 입력으로 주면서 간접적으로 의도를 줄 수도 있다.
입력 → AI (=모델, 연산의 집합, 프로그램) → 출력
비정형 데이터 → 인식 → 비정형 데이터에서 추출된 정보 (정형화)
비정형데이터/의도된 정보 → 생성 → 의도된 정보가 담긴 비정형 데이터
📍 생성 모델의 역사 History of Generative Models
이미지 인식이 생성보다 더 쉽다고 생각되어, 인식이 먼저 발전이 되었다.
23년도에 StabilityAI의 Stable Diffusion이 상업적으로도 이용가능하면서 오픈소스여서 관련 산업이 급격히 성장
텍스트 생성은, 23년도에 OpenAI에서 내놓은 ChatGPT가 모든 것을 다 변화시킴. 마치 AGI처럼 사람들이 느끼기 시작
