✒️ 프로젝트 개요
이번에는 영화 추천 시스템을 만드는 프로젝트를 진행하게 되었다. 자동화기법을 접목하여 MLFlow, AirFlow를 사용해보는 것을 목표로 진행하는 프로젝트이다!
어떤 작품이 어떤 플랫폼에서 방영이 되는지 알려주는 시스템도 함께 제공함으로써 기존 시스템과의 차별성을 갖추기로 하였다!
프로젝트를 진행하면서 이것저것 실험(?)을 해보며 기록을 해보고자 한다.
✒️ 협업 필터링 추천시스템에 대하여
추천 시스템의 종류를 나눠보면 크게 내용기반 추천시스템, 협업 필터링 추천시스템, 그리고 이 둘을 접목한 하이브리드 추천시스템이 있다.
나는 이번 프로젝트에서 협업 필터링을 중심으로 영화 추천시스템을 만들고, 문제점을 해결하는 과정에서 내용기반 추천시스템을 활용하여 하이브리드 방식을 구축할 생각이다.
- 협업 필터링 : 특정 아이템에 대해 선호도가 유사한 고객들은 다른 아이템에 대해서도 비슷한 선호도를 보일 것이라는 기본 가정을 바탕으로 사용자 혹은 아이템간 유사도를 기반으로 선호도를 예측하는 방법
📌 메모리 기반 협업 필터링
기억 기반 협업 필터링 기법은 사용자 기반 협업 필터링과 아이템 기반 협업 필터링으로 구분할 수 있다.
📍 사용자 기반 협업 필터링
- 사용자가 입력한 선호도 정보를 이용하여 고객과 유사한 성향을 갖는 이웃 사용자 선별
- 선별된 이웃들이 공통적으로 선호하는 아이템을 고객에게 추천해주는 방식
👉 사용자 간의 유사도 비교
# 사용자-영화 평점 데이터를 데이터프레임으로 변환
rating_df = pd.DataFrame(rating_dt)
movie_df = pd.DataFrame(movie_dt)
user_movie_matrix = rating_dt.pivot_table(index='userId', columns='movieId', values='rating')
# 사용자 간 유사도 계산 (코사인 유사도)
user_similarity = cosine_similarity(user_movie_matrix.fillna(0))
user_similarity_df = pd.DataFrame(user_similarity, index=user_movie_matrix.index, columns=user_movie_matrix.index)
# 사용자 간 유사도 출력
print("User Similarity Matrix:\n", user_similarity_df)
# 특정 사용자에게 영화 추천
def user_based_recommend(user_id, num_recommendations=5):
# 현재 사용자와 다른 사용자 간의 유사도 가져오기
similar_users = user_similarity_df[user_id].sort_values(ascending=False)
# 가장 유사한 사용자의 평점 데이터를 가져옴
similar_users_ratings = user_movie_matrix.loc[similar_users.index]
# 사용자가 이미 본 영화 제외
user_ratings = user_movie_matrix.loc[user_id]
watched_movies = user_ratings[user_ratings > 0].index
# 다른 유사한 사용자들의 평균 평점 계산 (자신이 본 영화는 제외)
movie_recommendations = similar_users_ratings.apply(lambda x: np.dot(similar_users, x) / similar_users.sum(), axis=0)
movie_recommendations = movie_recommendations.drop(watched_movies)
# 평점이 높은 순으로 영화 추천
top_recommendations = movie_recommendations.sort_values(ascending=False).head(num_recommendations)
# 영화 제목 출력
for movie_id in top_recommendations.index:
movie_title = movie_dt.loc[movie_dt.index == (movie_id - 1), 'title'].values
if len(movie_title) > 0:
print(f"추천 영화: {movie_title[0]}")
# 사용자 기반 협업 필터링 추천
user_id = 334 # 예시 사용자 ID
user_based_recommend(user_id, num_recommendations=5)📍 아이템 기반 협업 필터링
- 특정 아이템이 기준이 되어, 사용자들에 의해 평가된 점수가 유사한 아이템을 이웃 아이템으로 선정
- 이웃 아이템을 평가한 점수를 바탕으로 추천 대상 고객이 특정 아이템에 대해 갖게 될 선호도를 예측
# 사용자-아이템 평점 매트릭스 만들기
user_movie_matrix = rating_dt.pivot(index='userId', columns='movieId', values='rating')
# 결측치는 0으로 대체 (NaN 처리)
user_movie_matrix.fillna(0, inplace=True)
# 영화 간 코사인 유사도 계산
movie_similarity = cosine_similarity(user_movie_matrix.T)
movie_similarity_df = pd.DataFrame(movie_similarity, index=user_movie_matrix.columns, columns=user_movie_matrix.columns)
# 특정 사용자에게 아이템 기반 추천 함수 정의
def item_based_recommend(user_id, num_recommendations=5):
# 사용자의 평점 가져오기
user_ratings = user_movie_matrix.loc[user_id]
# 사용자가 본 영화 중에서 평점이 높은 영화 선택
high_rated_movies = user_ratings[user_ratings > 0].sort_values(ascending=False).index
# 각 영화에 대해 유사한 영화 추천 (아이템 기반 협업 필터링)
movie_scores = pd.Series(dtype=np.float64)
for movie_id in high_rated_movies:
# 해당 영화와 유사한 영화의 유사도 점수 가져오기
similar_movies = movie_similarity_df[movie_id]
similar_movies = similar_movies.drop(high_rated_movies) # 사용자가 이미 본 영화는 제외
# 유사도 점수를 누적
movie_scores = movie_scores.add(similar_movies, fill_value=0)
# 평점이 높은 순으로 영화 추천
top_recommendations = movie_scores.sort_values(ascending=False).head(num_recommendations)
# 영화 제목 출력
for movie_id in top_recommendations.index:
# movie_dt에서 영화 제목 가져오기 (movie_id와 index 매핑)
movie_title = movie_dt.loc[movie_dt.index+1 == movie_id, 'title'].values
if len(movie_title) > 0:
print(f"추천 영화: {movie_title[0]}")
# 아이템 기반 협업 필터링 추천 실행
user_id = 54
item_based_recommend(user_id, num_recommendations=5)협업 필터링은 다음 과정을 거친다.
✔️ 유사도 측정
✔️ 선호도 예측
✔️ 상위 N개 아이템 추천
📌 모델 기반 협업 필터링
🔻잠재요인 기반 Latent factor Based
📍 SVD (Singular Vector Decomposition)
본래 고유한 분해(Eigen Value Decomposition)를 이용한 행렬 분해의 경우, 정방행렬(nxn)이어야 하지만, SVD를 이용한다면 m x n 행렬로도 대각행렬을 통한 특이값 분해가 가능하기 때문에 유저, 아이템의 행과 열의 개수가 다른 추천모델에도 적합하다.
SVD는 수학적으로는 다음과 같이 표현한다
- M : 원본 데이터
- U 와 V* 는 시그마로 표시된 대각 행렬 벡터를 기반으로 PCA가 이루어진 데이터다
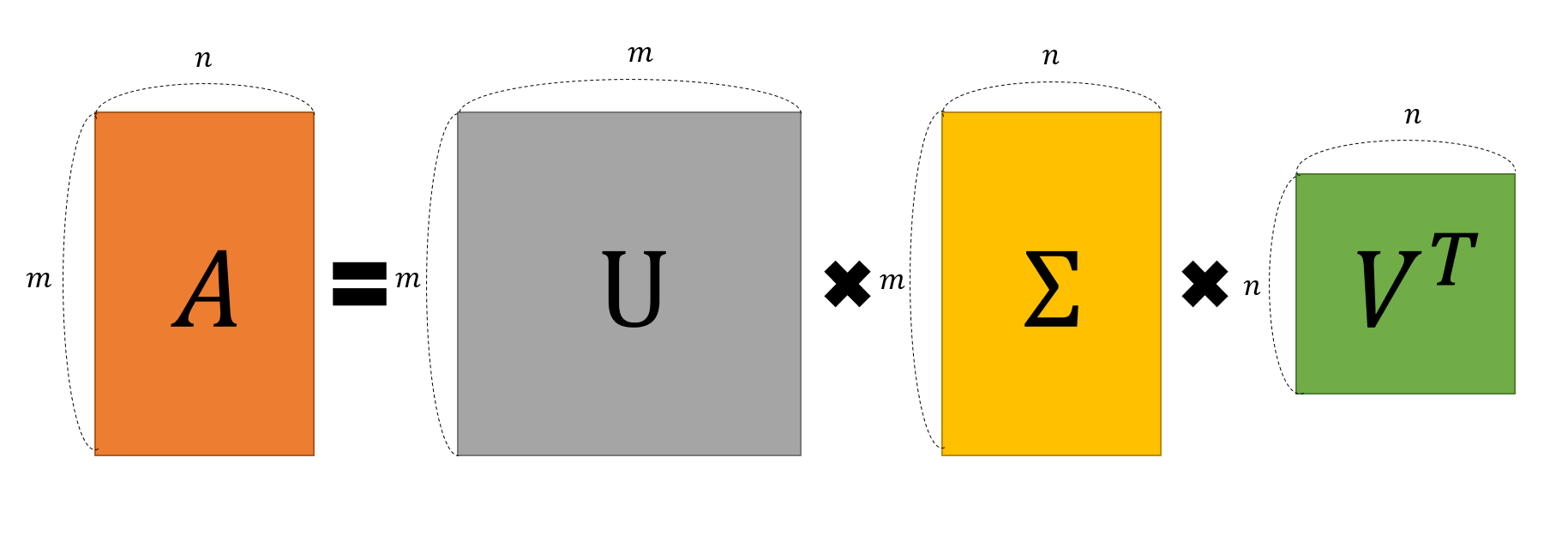
우리의 사용자-영화 데이터는 SVD를 이용하면 다음과 같이 3개의 벡터로 분리된다.
- U에 해당하는 좌측 벡터 : 사용자 정보를 의미미
- V에 해당하는 우측 벡터 : 영화정보를 의미
1번째 로우에 가까워질수록 높은 정보량을 가진다. 여기서 정보량이 높다는 것은 분산이 높다는 것을 의미하며, 기하학적으로 좌표평면에서 넓게 퍼져있다는 것을 의미한다.

모든 정보량을 다 가진 SVD를 Full SVD라고 하며, 대각행렬로 이루어진 벡터를 조정하면 압축된 column 정보를 가진 벡터를 표현할 수 있다. 이를 TruncatedSVD라고 한다.
가운데 대각 행렬 벡터는 압축된 정보를 의미한다. 유저-영화 관계라면 호러영화, SF 영화, 전쟁영화 같은 특징이 되겠으며 좌측, 우측 벡터는 이를 기반으로 압축된 정보를 가진다.
오차를 구할 때는 보통 RSME 혹은 MAE(Mean Absolute Error) 활용한다.
📍 MF(Matrix Factorization)
Matrix Factorization은 행렬분해를 의미한다. MF는 User-Item Matrix를 아래와 같이 User Matrix, Item Matrix 2개의 행렬의 곱셈으로 분해하는 것이다.
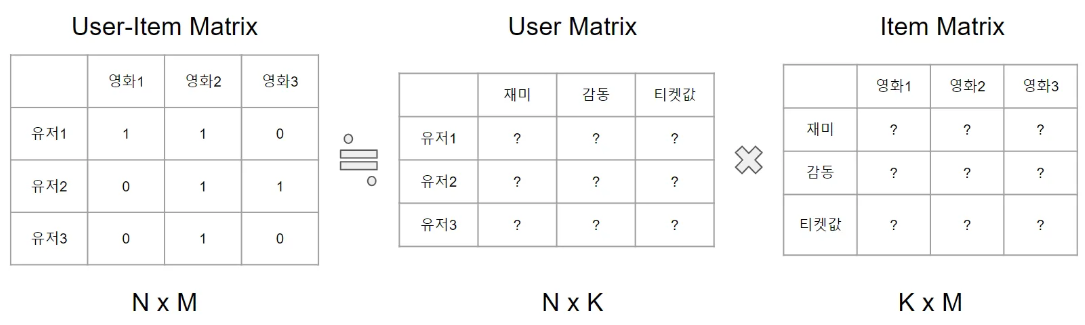
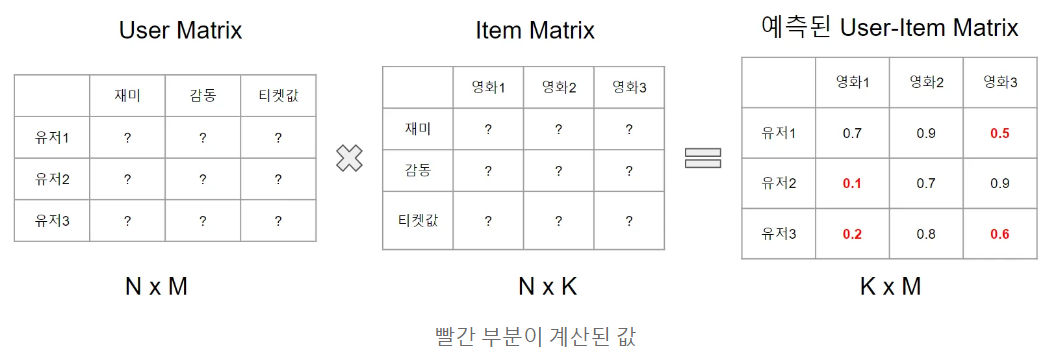
이때 k는 임의의 값이다. 원본 행렬 M은 두 개의 행렬의 곱으로 나타내지며, User Matrix와 Item Matrix는 각각 k개의 feature를 갖게 된다. 예를 들어 위 사진에서는 재미, 감동, 티켓값이라는 3개의 feature를 만들었다. 유저 행렬에는 각 유저가 재미, 감동, 티켓값 중 어떤 feature를 더 중요하게 여기는지를 수치화하고, 아이템 행렬에서도 영화가 재미, 감동, 티켓값 중 어떤 feature에 적합한지를 수치화한 뒤 유저 행렬과 아이템 행렬을 내적해서 원본 행렬을 복원하게 된다.
유저의 feature와 영화의 feature가 비슷하다면 영화와 유저가 잘 맞는다는 의미이고, 내적은 1이 될 것이고 비슷하지 않으면 0이 될 것이다. 각 feature는 User-Item Matrix를 복원하기 위해 자동으로 계싼되는 값이기 때문에 실제로 무슨 값인지는 알 수 없다. 이 feature들을 latent feature라고 한다.
위 예시에서는 k값이 클수록 원본 행렬을 잘 복원하지만 계산량은 늘어나고, k의 값이 작을수록 원본 행렬과의 오차는 커지지만 계산량은 줄어들 것이다.
📍 AutoEncoder(Latent Feature)
PCA는 성능이 그다지 뛰어나지 않다는 단점을 가지고 있고, SVD는 데이터가 linear한 상황에서만 잘 동작한다는 단점을 가진다. 또한 hiwte space가 아주 많은 행렬에서는 거의 최악에 가까운 성능을 보여주고, k파라미터가 증가할수록 오차도 같이 증가하는 기이한 현상을 보여주기도 한다. 이를 보정하기 위한 PMF(probabilistic-matrix-factorization) 알고리즘 역시 가우시안 모형을 가설로 하기 때문에 현실세계의 profile 데이터에서는 좋지 않은 성능을 보인다. SVD로 축소하느냐 AE로 축소하느냐보다는, matrix의 profile 피처를 얼마나 잘 다듬어내느냐가 더 중요하다고 한다.
그래서 다른 방법으로 눈을 돌린 것이 바로 DL 기반의 차원 축소 기법이다. 그 중 가장 basic한 방법이 바로 Autoencoder이다.
Autoencoder는 아주 간단한 뉴럴 네트워크 레이어의 재구성이라고 할 수 있다.
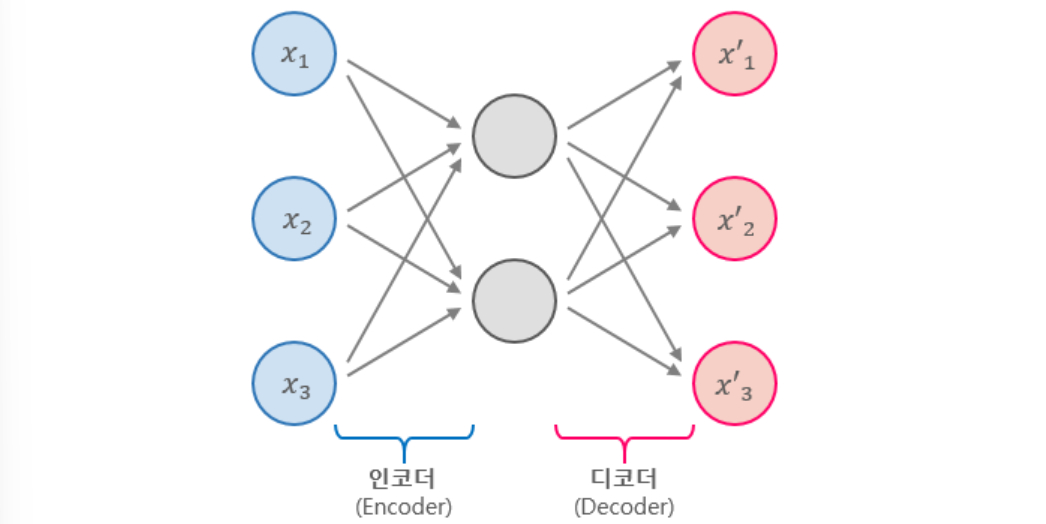
단, input data와 output data가 같은 것으로 하여 네트워크를 학습시킨다. SVD가 rmse를 목표로, latent vector를 중간에 두고 원래의 행렬을 복원해내는 것과 동일한 아이디어라고 볼 수 있다. 다만, 이 네트워크는 훨씬 더 복잡하게 응용이 가능하고 non-linear problem solving에서도 아주 좋은 성능을 보여준다. 간단한 예로, 히든 레이어 몇개를 더 추가하는 것만으로도 더욱 복잡한 autoencoder를 구성할 수 있다.
📍 SVM (Support Vector Machine)
SVM은 클래스(범주)를 가장 효율적으로 분류할 수 있는 초평면(Hyperplane) 또는 결정 경계(Decision Boundary)를 찾는 모형이다.
예를 들어, 아래 그림과 같이 두 클래스를 분류하는 3가지 선형 결정 경계를 만든다고 가정해보자. 1번의 경우 클래스를 제대로 분류하지 못했고, 3번의 경우 두 클래스를 제대로 분류했지만, 결정 경계선과 관측 데이터가 매우 가깝기 때문에 추후 새로운 데이터를 분류하려 할 경우 잘못 분류될 가능성이 크다. 한편, 2번 결정 경계는 두 클래스를 제대로 분류했을 뿐만 아니라, 결정 경계선과 두 클래스의 최근점 관측치 사이의 거리가 큰 폭으로 떨어져 있기 때문에 추후 새로운 데이터에 대한 분류에 대해서도 비교적 안정적인 성능을 발휘할 수 있을 것이다.
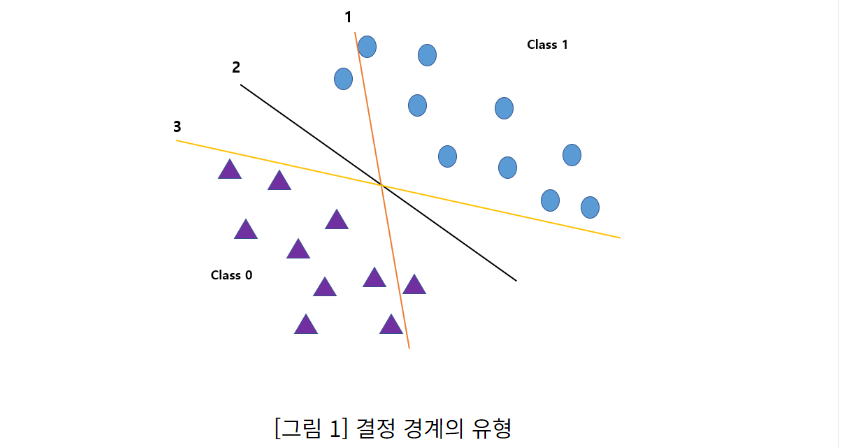
2번과 같은 최적 결정 경계를 초평면 (Hyperplane)이라고 하며, SVM은 결국 범주를 효과적으로 분류할 수 있는 초평면을 찾는 모형이다.

-
선형 SVM
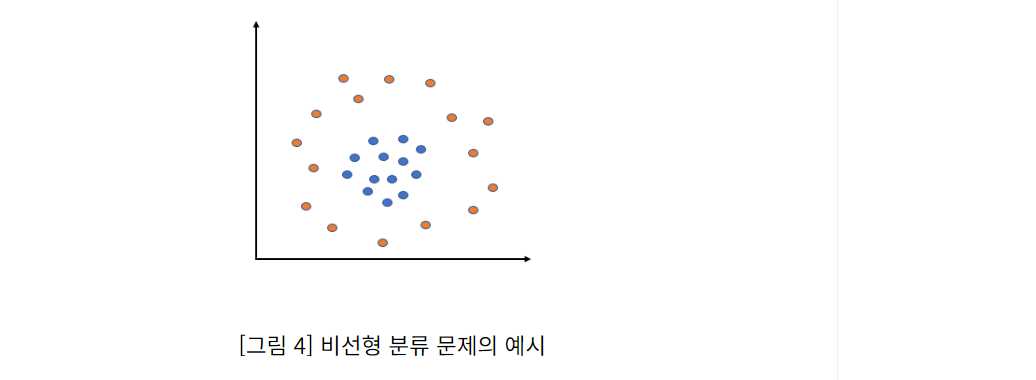
-
비선형 SVM
-
커널 기법 : 주어진 데이터를 고차원 공간으로 변환하여 선형 분류 혹은 수치 예측을 가능하게 해주는 방법이다. 즉, 커널 기법을 적용한다는 것은 벡터 간의 내적을 커널 함수로 대체한다는 것
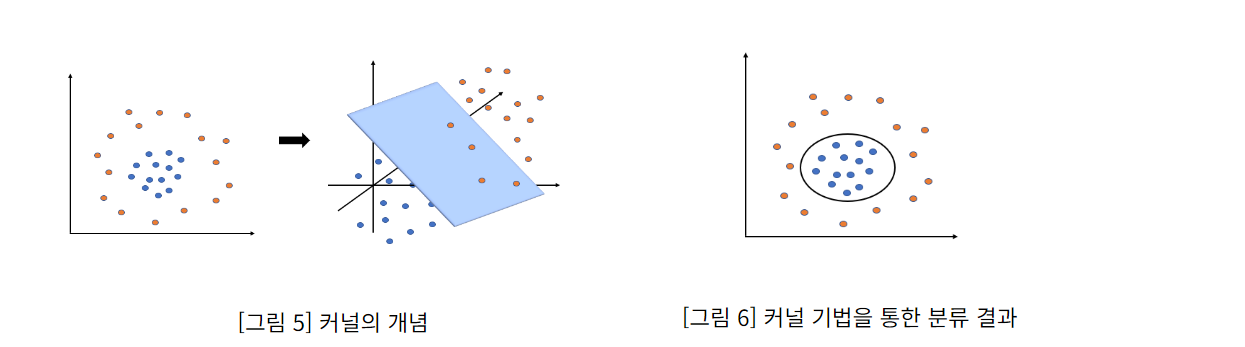
🔻딥러닝 기반 Deep Learning Based
📍 NCF (Neural Collaborative Filtering)
NCF(Neural Collaborative Filtering)는 사용자와 아이템 간의 상호작용을 신경망을 통해 모델링하는 추천 시스템 모델이다. 전통적인 행렬 분해 방식(예: SVD)과 달리, NCF는 여러 숨겨진 레이어를 통해 비선형적인 패턴을 학습하여 사용자와 아이템 간의 복잡한 상호작용을 더 잘 포착할 수 있다.
사용자와 아이템을 임베딩 벡터로 변환해 고차원 데이터를 저차원으로 표현함으로써 유사도를 효율적으로 계산할 수 있다. 이로 인해 대규모 데이터에서도 빠르고 정확한 추천이 가능하다.
뿐만 아니라 확장성이 뛰어나고, 추천 성능이 더 우수하다!
NCF 구현 단계:
- 임베딩 (Embeddings):
사용자와 아이템을 저차원 공간에 밀집 표현으로 임베딩합니다. 이 임베딩 벡터는 각 사용자와 아이템을 수치적으로 표현하여, 각 객체를 보다 압축된 형태로 나타내줍니다.
- 결합 (Concatenation):
사용자와 아이템의 임베딩 벡터를 결합하여 해당 사용자-아이템 쌍에 대한 결합된 표현을 만듭니다. 이렇게 결합된 벡터는 사용자가 아이템에 대해 어떤 관계를 가질지 나타낼 수 있는 특징을 포함하게 됩니다.
- 신경망 (Neural Network):
결합된 임베딩 벡터를 여러 개의 완전 연결(fully connected) 레이어를 통해 통과시킵니다. 각 레이어는 비선형 활성화 함수(ReLU와 같은)를 사용하여 사용자와 아이템 간의 복잡한 상호작용을 학습합니다.
- 예측 (Prediction):
마지막 레이어는 예측 점수를 출력하며, 이는 주어진 사용자-아이템 쌍에 대한 평점을 나타냅니다. 훈련 과정에서는 이 예측 점수를 실제 평점과 비교하여 모델을 학습시키게 됩니다.
📍 DeepFM (Deep Factorization Machine)
📌 고려해야할 사항
📍 데이터 희소성 (Sparsity)
-
사용자의 아이템에 대한 만족도를 점수로 나타낸 사용자-아이템 행렬을 사용해 추천 대상 고객의 선호도를 예측
-
데이터의 부족으로 인해 발생하는 문제를 총칭해 데이터 희소성이라고 함
-
Cold Start : 상품의 인기도에 따라 데이터가 편중되거나 아직 평가 값을 입력하지 않은 새로운 사용자가 존재하는 경우, 유사도를 측정할 만한 충분한 데이터가 존재하지 않기 때문에 선호도를 예측하는 것이 불가능
-
First rater : 아직 구매가 이뤄지지 않아 점수가 존재하지 않을 경우, 누군가가 점수를 주기 전까지는 추천이 이뤄질 수 없는 경우
-
[해결방법 예시] 키워드 추출, 사회연결망 기법 활용, 주용 사용자와 일반 사용자로 분류하는 방법, 특이값 분해(SVD)
📍 확장성 (Scalability)
-
최근 사용자-아이템 데이터 셋의 크기가 점점 커지고 있으며, 이에 따라 추천 알고리즘 구현 시 컴퓨터 계산량이 급증하게 되어 많은 시간과 비용이 소모되는 문제점이 발생하고 있음
-
보통 사용자의 구매행동이 발생하는 즉시 사용자-아이템 행렬이 갱신되며, 대부분의 시스템에서는 이와 같이 실시간으로 갱신되는 정보를 통해 신속하게 새로운 예측 값을 계산하여 고객에게 추천을 진행함
-
모든 데이터를 사용하여 선호도를 예측하는 방식은 계산량이 많을 뿐만 아니라 예측력의 정확도를 저하시킬 수 있음
-
[해결방법 예시] 유사도가 큰 순서대로 N개의 사용자 혹은 아이템만을 선정하여 선호도를 예측하는 방법은 높은 추천 만족도를 지니면서 모든 데이터를 활용한 것보다 빠른 계산 속도를 보임
📍 Grey Sheep
-
협업 필터링 접근 방식은 사람들 취향에 경향과 패턴이 존재하는 가정을 하고 있음. 그렇기에 일관성 없는 의견을 가진 사용자들의 데이터는 경향과 패턴을 파악함에 있어 방해가 되며 예측 정확도를 떨어뜨림
-
[해결방법 예시] 콘텐츠 기반 접근방식과 협업 필터링을 모두 사용하여 가중 평균값을 예측 값으로 활용하는 방법
📍 Shilling Attack
-
의도적으로 특정 아이템에 긍정적인 평가점수를 입력해 추천 리스트에 포함되게 하거나 부정적인 평가점수를 입력하여 추천되지 않도록 할 수 있음
-
이처럼 악의적으로 평가점수를 입력하여 추천시스템의 정상적인 작동을 방해하는 행위를 shilling attack이라고 함
-
[해결방법 예시] 조작된 평가점수가 추천 결과에 미치는 영향을 최소화하기 위한 추천시스템 모델 구축 방법 제안, 허위 사용자 탐지 기법에 대한 연구 진행, 기계학습 알고리즘을 통해 비정상적인 행위를 미리 학습한 뒤 공격을 탐지하는 기법
✒️ 내용 기반 추천시스템에 대하여
- 내용 기반 필터링(Content-Based Filtering)은 사용자가 과거에 좋아했던 아이템의 속성을 분석해 유사한 속성을 가진 아이템을 추천하는 방식
- 협업 필터링(Collaborative Filtering)과 달리, 다른 사용자의 행동(평점, 조회수 등)에 기반하지 않고 아이템 자체의 특성을 이용해 추천함 → 개인의 취향을 분석하는 것!
📌 작동방식
- 아이템 특징 표현 : 각 영화는 장르, 배우, 감독 등으로 특징이 표현됨. 이러한 특징들은 해당 아이템의 프로필을 구성하게 됨
- 사용자 프로필 생성 : 사용자가 좋아하거나 높은 평점을 준 아이템들의 특징을 분석하여 사용자 프로필을 만듦. 이 프로필은 사용자의 선호도를 반영하는 것!
- 유사도 계산 : 사용자의 프로필과 다른 아이템들의 프로필 간 유사도를 계산함. 유사도는 주로 코사인 유사도 같은 수학적 거리 계산 방법을 사용
- 추천 : 사용자 프로필과 유사도가 높은 아이템을 사용자에게 추천함
✒️ 구현 과정
먼저 활용하는 데이터는 movie와 관한 데이터와, user_rating에 관한 데이터, 두 데이터셋을 활용하였다.
movie_dt의 결측치를 확인해보니
movie_dt.isnull().sum()
adult 0
belongs_to_collection 40972
budget 0
genres 0
homepage 37684
id 0
imdb_id 17
original_language 11
original_title 0
overview 954
popularity 5
poster_path 386
production_companies 3
production_countries 3
release_date 87
revenue 6
runtime 263
spoken_languages 6
status 87
tagline 25054
title 6
video 6
vote_average 6
vote_count 6
dtype: int64그리고 튜플에 담긴 값들을 각각 확인해보기 위해 상단 5개 튜플을 뽑아 살펴보았다.
movie_dt.head(5)
여기서 의미있는 컬럼이 무엇일지 생각해보았다.
- Genres
- Popularity
- Release Date : sorting할 때 활용
- Production Companies : ex. 마블, 픽사
- Vote Average : 역시 sorting 할 때?
- Budget : 저예산 영화일 경우
- Original Language : 언어도 중요하다고 생각
- Actors / Directors : 사용자가 높은 rating을 준, 혹은 최근 시청한 영화에 등장한 배우와 감독이 같은 작품을 추천해줄 때 활용 가능
📍 Content-Based
우선 내용기반 필터링에 활용하기 위해 credit.csv파일에서 배우와 감독명을 추출해보았다.
#배우 추출
def extract_actor_names(cast_str):
cast_list = ast.literal_eval(cast_str)
actor_names = [cast_member['name'] for cast_member in cast_list]
return ', '.join(actor_names)
credit_dt['actor_names'] = credit_dt['cast'].apply(extract_actor_names)
print(credit_dt[['actor_names']].head())
#감독 추출
def extract_director_names(crew_str):
crew_list = ast.literal_eval(crew_str)
director_names = [crew_member['name'] for crew_member in crew_list if crew_member['job'] == 'Director']
return ', '.join(director_names)
credit_dt['director_names'] = credit_dt['crew'].apply(extract_director_names)
print(credit_dt[['director_names']].head())추출을 했으니 actor_names와 director_names를 movie_dt에 결합해주었다
movie_dt = pd.merge(movie_dt, credit_dt[['id', 'actor_names', 'director_names']], on='id', how='left')내용기반 필터링은 사용자 개인의 취향을 파악하고 아이템을 추천해주는 기법이기 때문에, 사용자의 취향을 파악하기 위해 프로필을 생성하고 그 프로필과 영화 간의 유사도를 계산해야한다.
다음은 사용자 프로필을 생성하는 과정이다
# 사용자 프로필 생성
def build_user_profile(user_id, rating_dt, movie_dt):
# 사용자가 평점을 준 영화 정보 가져오기
user_ratings = rating_dt[rating_dt['userId'] == user_id]
# 'tmdbId'와 'id'를 매핑하여 사용자의 영화 정보를 가져오기
user_movies = movie_dt[movie_dt['id'].isin(user_ratings['tmdbId'].values)].copy()
user_movies.reset_index(drop=True, inplace=True) # 인덱스 재설정
# 영화 장르, 배우, 감독 데이터 하나의 텍스트로 합치기
user_movies['combined_features'] = (
user_movies['genres'].fillna('') + ' ' +
user_movies['actor_names'].fillna('') + ' ' +
user_movies['director_names'].fillna('')
)
# TF-IDF -> 영화 특징 벡터화
tfidf = TfidfVectorizer(token_pattern=r'[^| ]+') # '|' 또는 공백으로 구분된 특징들
tfidf_matrix = tfidf.fit_transform(user_movies['combined_features'])
# 평점 가중치 반영
weighted_tfidf = np.zeros(tfidf_matrix.shape)
for idx, row in user_ratings.iterrows():
# 'id'와 'tmdbId'가 일치하는 인덱스 찾기
movie_index = user_movies.index[user_movies['id'] == row['tmdbId']].tolist()
# 디버깅용 출력
#print(f"Matching tmdbId {row['tmdbId']} with movie_index: {movie_index}, tfidf_matrix shape: {tfidf_matrix.shape}")
# movie_index가 존재하고, tfidf_matrix의 범위 내인지 확인
if movie_index and movie_index[0] < tfidf_matrix.shape[0]:
# tfidf_matrix와 weighted_tfidf 인덱스 확인
#print(f"Applying weight for movie_index: {movie_index[0]}")
weighted_tfidf[movie_index[0], :] = tfidf_matrix[movie_index[0], :].toarray() * row['rating']
else:
print(f"Movie with tmdbId {row['tmdbId']} not found or index out of range.")
# 사용자 프로필 벡터 생성
user_profile = np.mean(weighted_tfidf, axis=0)
return user_profile, tfidf
movie와 rating을 매핑할 컬럼 때문에 굉장히...고생을 했던 기억이.......
이제 사용자 프로필과 영화의 유사도를 계산하고, 사용자가 평점을 준 영화와 개봉연도가 가까운 영화들에 가중치를 더 부여하고 싶어서 가중치를 부여한 코드까지 들어간 추천 시스템 구현 코드다
# 사용자 프로필과 영화 유사도 비교, 개봉연도 가중치 추가
def content_based_recommendation(user_id, movie_dt, rating_dt, num_recommendations, bonus_weight):
# 사용자 프로필 생성
user_profile, tfidf = build_user_profile(user_id, rating_dt, movie_dt)
# 영화 특징 추출 및 TF-IDF 변환
movie_dt['combined_features'] = (
movie_dt['genres'].fillna('') + ' ' +
movie_dt['actor_names'].fillna('') + ' ' +
movie_dt['director_names'].fillna('')
)
tfidf_matrix = tfidf.transform(movie_dt['combined_features'])
# 사용자 프로필과 영화 간 코사인 유사도 계산
cosine_sim = cosine_similarity(user_profile.reshape(1, -1), tfidf_matrix).flatten()
# 사용자가 평가한 영화들의 개봉연도 가져오기
user_rated_movies = rating_dt[rating_dt['userId'] == user_id]['tmdbId'].values
rated_movie_years = movie_dt[movie_dt['id'].isin(user_rated_movies)]['release_year'].values
# 영화 코사인 유사도 계산 + 개봉연도 가중치 부여
movie_scores_with_bonus = []
similarity_scores=[]
for idx, predicted_rating in enumerate(cosine_sim):
if idx < len(movie_dt):
movie_id = movie_dt.iloc[idx]['id']
movie_year = movie_dt.iloc[idx]['release_year']
# 개봉연도 가중치 계산
if len(rated_movie_years) > 0:
date_diff = np.mean([abs(movie_year - rated_year) for rated_year in rated_movie_years])
proximity_bonus = 1 / (1 + date_diff)
else:
proximity_bonus = 0
# 최종 점수 계산
total_score = predicted_rating + bonus_weight * proximity_bonus
movie_scores_with_bonus.append((movie_id, total_score))
# 최종 점수 기준으로 상위 10개의 영화 출력
top_10_movies = sorted(movie_scores_with_bonus, key=lambda x: x[1], reverse=True)[:10] # 상위 10개 점수
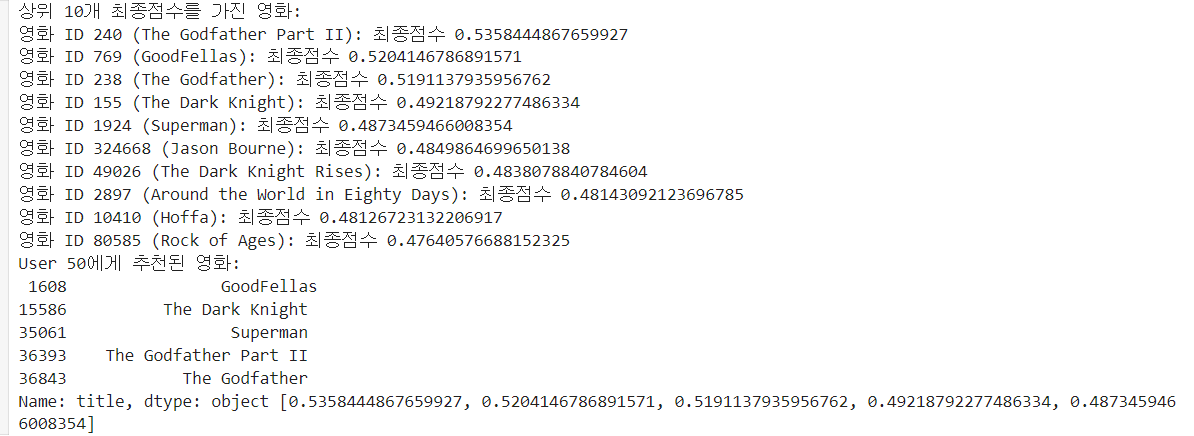
print("상위 10개 최종점수를 가진 영화:")
for movie_id, total_score in top_10_movies:
movie_title = movie_dt[movie_dt['id'] == movie_id]['title'].values[0]
print(f"영화 ID {movie_id} ({movie_title}): 최종점수 {total_score}")
# 영화 추천 결과 정렬 후 상위 추천 영화 선택
top_recommendations = sorted(movie_scores_with_bonus, key=lambda x: x[1], reverse=True)[:num_recommendations]
top_movie_ids = [rec[0] for rec in top_recommendations]
recommended_movies = movie_dt[movie_dt['id'].isin(top_movie_ids)]['title']
recommended_ratings = [rec[1] for rec in top_recommendations]
return recommended_movies, recommended_ratings
디버깅을 해보기 위해 상위 10개 최종점수를 가진 영화를 출력했고, user_id값을 입력했을 때 영화가 잘 추천되는지 확인해보았다~
user_id = 50
num_recommendations = 5
bonus_weight=0.1
recommended_movies, recommended_ratings = content_based_recommendation(user_id, movie_dt, rating_dt, num_recommendations, bonus_weight)
print(f"User {user_id}에게 추천된 영화:\n", recommended_movies, recommended_ratings)결과
<파이썬 코드 설명>
- Reader : 데이터셋의 평점 범위를 지정하고, Surprise 라이브러리가 pandas DataFrame등의 데이터를 올바르게 해석할 수 있도록 도와줌. 이를 통해 데이터를 추천 모델에 맞는 형식으로 변환할 수 있음
- rating_scale : 데이터셋에 있는 평점의 범위를 정의
- 예를 들어, 평점이 1점에서 5점 사이인 경우 (1,5)로 설정하여 데이터의 최소 및 최대 평점 값을 이해할 수 있다!
- rating_scale : 데이터셋에 있는 평점의 범위를 정의
- pivot_table : 행(인덱스), 열과 값을 기준으로 데이터를 요약하고, 이를 테이블 형식으로 변환하는 함수. 태르릭스 형태로 만들어줌
- reshape을 해야하는 이유 : 데이터의 형상(차원)을 변경해야 할 때, reshape은 기본적으로 데이터의 메모리 배열 구조를 변경하지 않으면서 데이터의 크기를 유지하고 형상만 변경함. 이는 메모리 효율성을 높이고, 빠른 연산을 가능하게 함!
- sklearn의 일부 모델이나, Keras, PyTorch 등의 라이브러리는 데이터를 (샘플 수, 특성 수)와 같은 2차원 배열로 요구하는 경우가 많음
- 만약 1차원 배열(벡터)로 된 데이터를 사용할 경우, reshape()를 이용하여 2차원 형식으로 변환해야함
- ex. data = np.array([1, 2, 3, 4, 5]) -> reshaped_data = data.reshape(-1, 1) # (5, 1)로 변환
- flatten은 다차원 배열(2,3차원 등)을 1차원 배열로 변환하는 함수!
- ex. arr = np.array([[1, 2, 3], [4, 5, 6]])와 같은 2D 배열이 있을 때 flatten을 사용하면 arr.flatten() -> 결과: [1,2,3,4,5,6] 이 되는 것!
이제 협업 필터링을 구현한 코드를 살펴보자. SVD, NCF 모델을 활용해보았는데 끝내 NCF만 성공했다
(아니 분명 SVD도 되었는데 매핑을 다르게 하기만 했는데 negative dimensions are not allowed 에러가 발생함... 시간 내에 해결하지 못했다...^^)
📍 NCF
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Embedding, Input, Dense, Flatten, Concatenate
from sklearn.model_selection import train_test_split
# 1. 데이터 전처리
# userId와 tmdbId를 categorical 변수로 변환하여 처리
user_ids = rating_dt['userId'].unique().tolist()
movie_ids = rating_dt['tmdbId'].unique().tolist()
# 사용자 및 영화 ID를 재정의
user_to_index = {x: i for i, x in enumerate(user_ids)}
movie_to_index = {x: i for i, x in enumerate(movie_ids)}
# rating_dt에 새로운 인덱스 컬럼 추가
rating_dt['user'] = rating_dt['userId'].map(user_to_index)
rating_dt['movie'] = rating_dt['tmdbId'].map(movie_to_index)
# movie_dt에서 movieId를 인덱스에 맞게 매핑 (tmdbId와 movie_dt의 id를 매핑)
movie_dt = movie_dt[movie_dt['id'].isin(movie_ids)]
tmdb_to_movie_title = {row['id']: row['title'] for idx, row in movie_dt.iterrows()}
# 입력 데이터 정의
X = rating_dt[['user', 'movie']].values
y = rating_dt['rating'].values
# 학습 및 검증 데이터 분리
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. NCF 모델 정의
num_users = len(user_ids)
num_movies = len(movie_ids)
embedding_size = 50 # 임베딩 벡터 크기
# 사용자 임베딩 층
user_input = Input(shape=(1,), name='user_input')
user_embedding = Embedding(input_dim=num_users, output_dim=embedding_size, name='user_embedding')(user_input)
user_vec = Flatten(name='user_flatten')(user_embedding)
# 영화 임베딩 층
movie_input = Input(shape=(1,), name='movie_input')
movie_embedding = Embedding(input_dim=num_movies, output_dim=embedding_size, name='movie_embedding')(movie_input)
movie_vec = Flatten(name='movie_flatten')(movie_embedding)
# 임베딩 합치기
concat = Concatenate()([user_vec, movie_vec])
# MLP 네트워크 정의
dense = Dense(128, activation='relu')(concat)
dense = Dense(64, activation='relu')(dense)
output = Dense(1)(dense)
# 모델 컴파일
model = Model([user_input, movie_input], output)
model.compile(optimizer='adam', loss='mean_squared_error')
# 3. 모델 학습
model.fit([X_train[:, 0], X_train[:, 1]], y_train, epochs=2, batch_size=512, validation_data=([X_val[:, 0], X_val[:, 1]], y_val))

from tensorflow.keras.models import load_model
# 모델 저장
model.save('ncf_movie_recommendation_model.h5')# 4. 영화 추천 함수 정의
loaded_model = load_model('ncf_movie_recommendation_model.h5')
def ncf_recommend_movies(user_id, top_n=5):
if user_id not in user_to_index:
print("Invalid user ID.")
return
# 유저 ID 변환
user_idx = user_to_index[user_id]
# 사용자가 평가하지 않은 영화들에 대해 예측
user_rated_movies = rating_dt[rating_dt['userId'] == user_id]['tmdbId'].tolist()
movie_candidates = [m for m in movie_ids if m not in user_rated_movies]
# 예측할 영화 후보군 준비
user_array = np.array([user_idx] * len(movie_candidates))
movie_array = np.array([movie_to_index[movie] for movie in movie_candidates])
# 예측
predictions = loaded_model.predict([user_array, movie_array])
# 영화별로 예측 점수와 함께 정렬
top_movie_indices = predictions.flatten().argsort()[-top_n:][::-1]
top_movie_ids = [movie_candidates[i] for i in top_movie_indices]
# 영화 제목 반환
recommended_movies = [tmdb_to_movie_title[movie_id] for movie_id in top_movie_ids]
return recommended_movies
# 6. 특정 user_id에 대해 영화 5개 추천
user_id = 5 # 예시 user_id
recommended_titles = ncf_recommend_movies(user_id, top_n=5)
print(f"User {user_id}에게 추천하는 영화 5개:")
for title in recommended_titles:
print(title)
📌 참고
