Objective: To web crawl the name of the drink and its image.
Importing selenium to the python file.
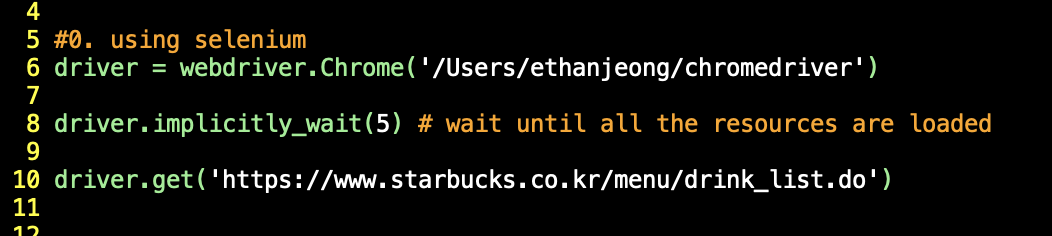
Locating the common directory from the top:
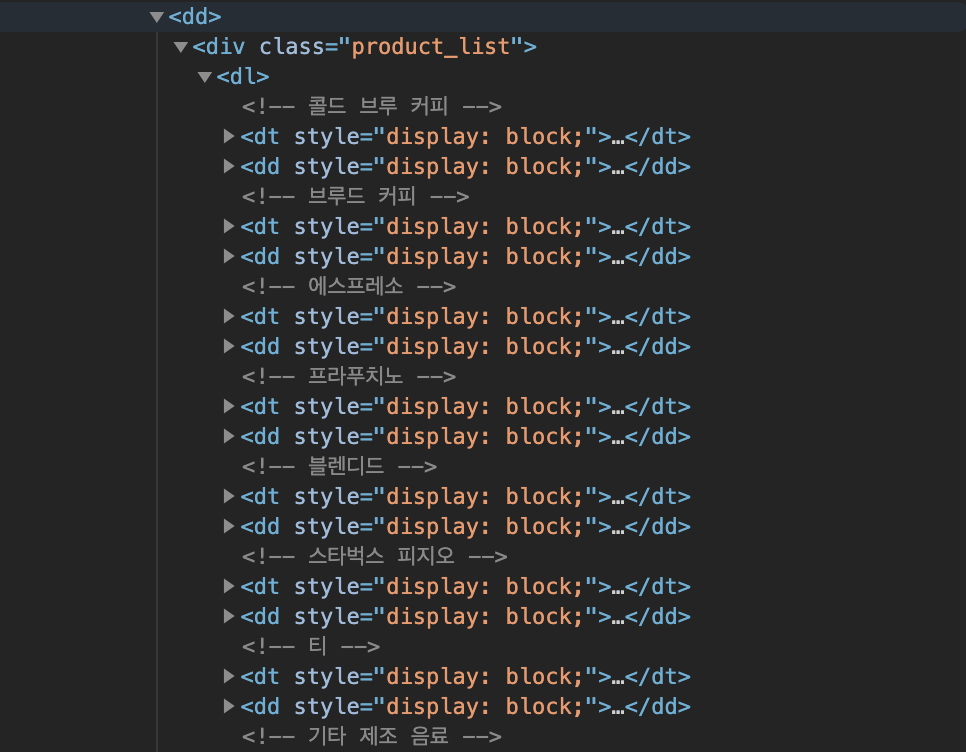
- As you can see there is a product list on the top, and inside dd tags, you can access the name and the image url of the drink.
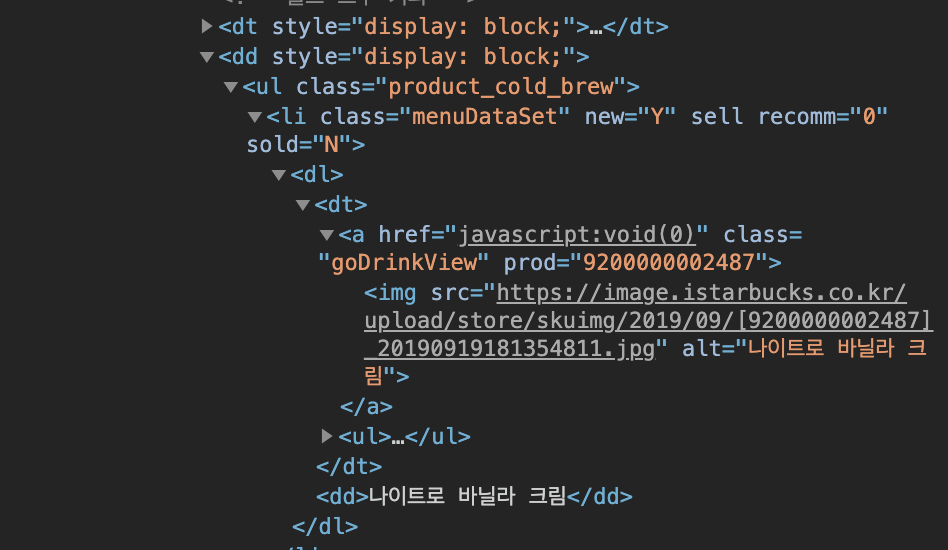
menu_list = driver.find_elements_by_css_selector('.product_list dd .menuDataSet- You can omit all the common tags (like ul and li), and you don't need '>' when the directories are not directly related. JUST SPACES.
Locating the final information
- As you can see above, we are inside .menuDataSet right now, and we want to get to 'img src', and 'dd' for the image and the name.

- In order to do that, we need to use 'find_element_by_css_selector'. Since it's iterating through for loop, we don't need to do 'find_elements_by_css_selector'.
- Here, we need to add '.text' next to 'coffee.find_element_by_css_selector('dd').
- If we don't add '.text, the elements are not in text form, so it prints like this:

- We don't need '.text' for img part because we put '.get_attribute' which makes it the text form.
Code
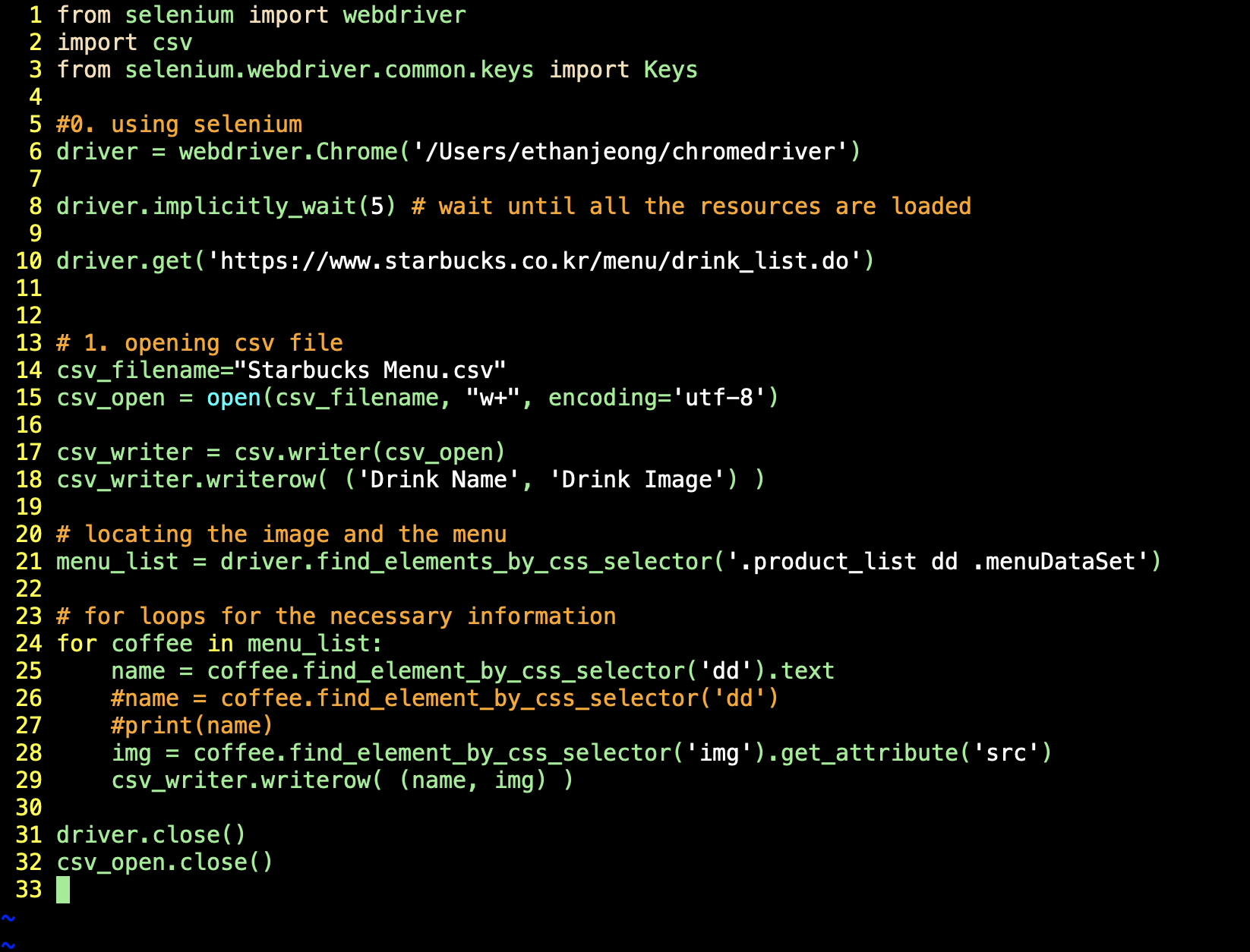
- Don't forget to close the driver and the csv file!!
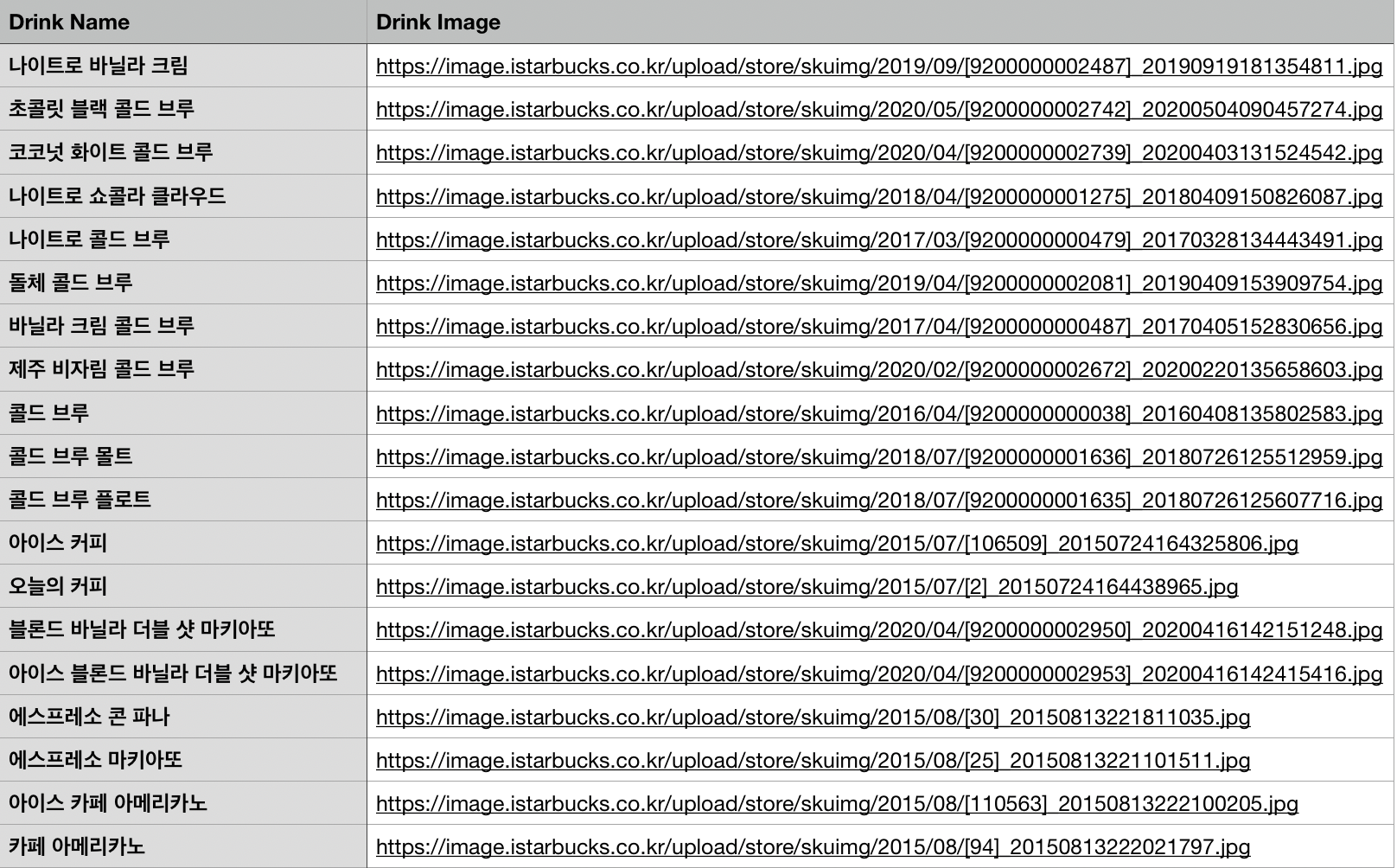
Final CSV file

I'm a Junior studying Economics and Computer Science at Vanderbilt University.