![]()
Robots.txt
웹사이트에서 크롤링하며 정보를 수집하는 검색엔진 크롤러(또는 검색 로봇)가
액세스하거나 정보수집을 해도 되는 페이지가 무엇인지
해서는 안되는 페이지가 무엇인지 알려주는 역할을 하는 .txt 파일이다.
검색엔진 크롤러가 웹사이트에 접속하여 정보 수집을 하며 보내는 요청으로 인해
사이트가 과부화되는 것을 방자하기 위해 사용된다.
example
다음과 같이 네이버 금융 사이트에서 살펴보고자 한다.
네이버 금융의 주소는 https://finance.naver.com/ 인데
robots.txt 를 추가하여 이동하면 다음과 같은 화면으로 전환된다.
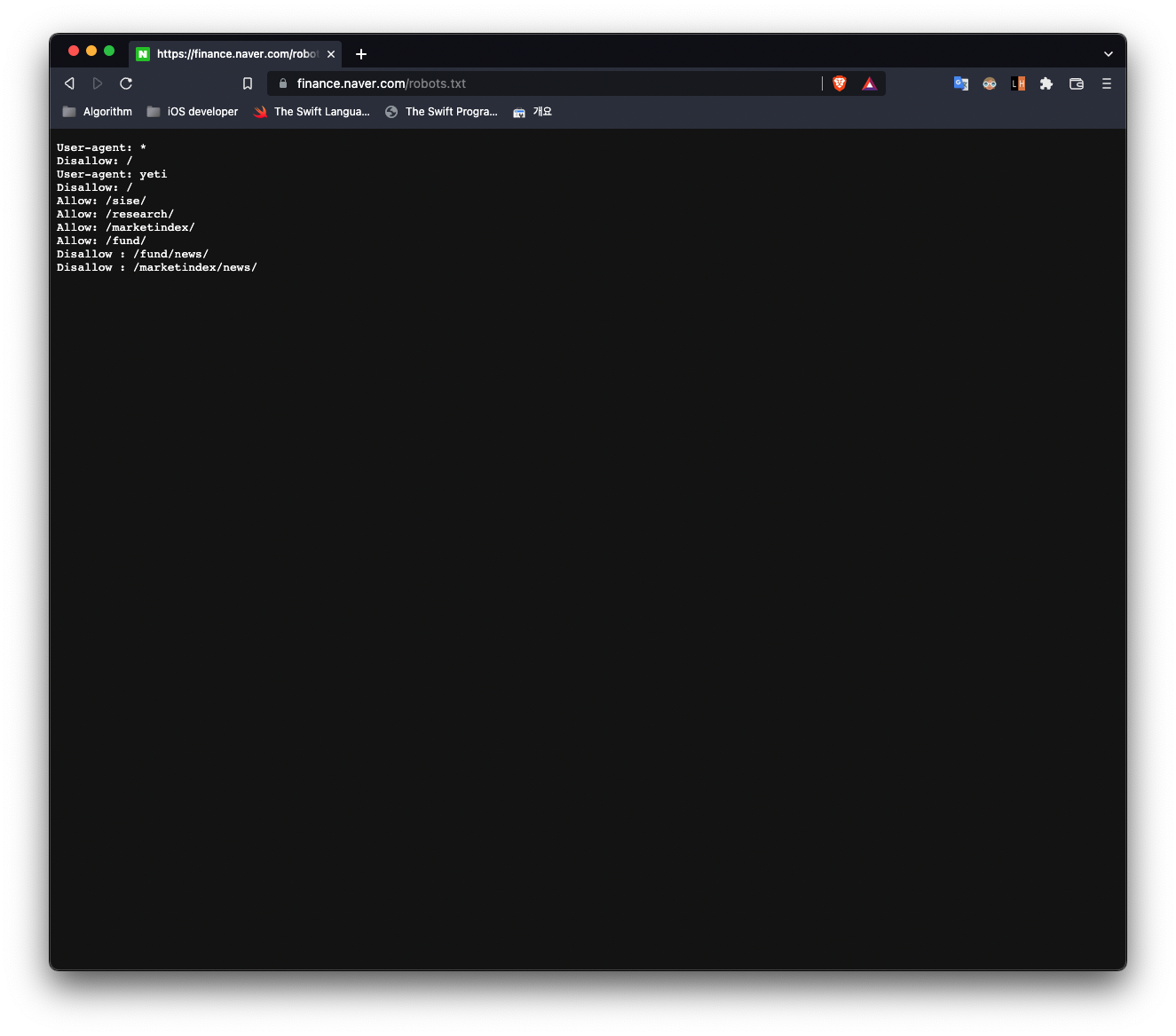
Disallow 라고 명시되어있는 디렉토리 및 파일에 대해서는 크롤링할 수 없다.
반대로 Allow 라고 명시되어있는 디렉토리 및 파일에 대해서는 크롤링이 가능하다.
User-agent: *
Disallow: /
User-agent: yeti
Disallow: /
Allow: /sise/
Allow: /research/
Allow: /marketindex/
Allow: /fund/
Disallow : /fund/news/
Disallow : /marketindex/news/User-agent 는 robots.txt 에서 지정하는
크롤링 규칙이 적용되어야 할 크롤러를 지정한 것이다.
📚 Reference
Robots.txt 소개
robots.txt 10분 안에 끝내는 총정리 가이드
[파이썬, Python] 크롤링(crawling) 가능 여부 확인 - robots.txt

🌱 iOS developer