
1. Google Cloud 운영 제품군
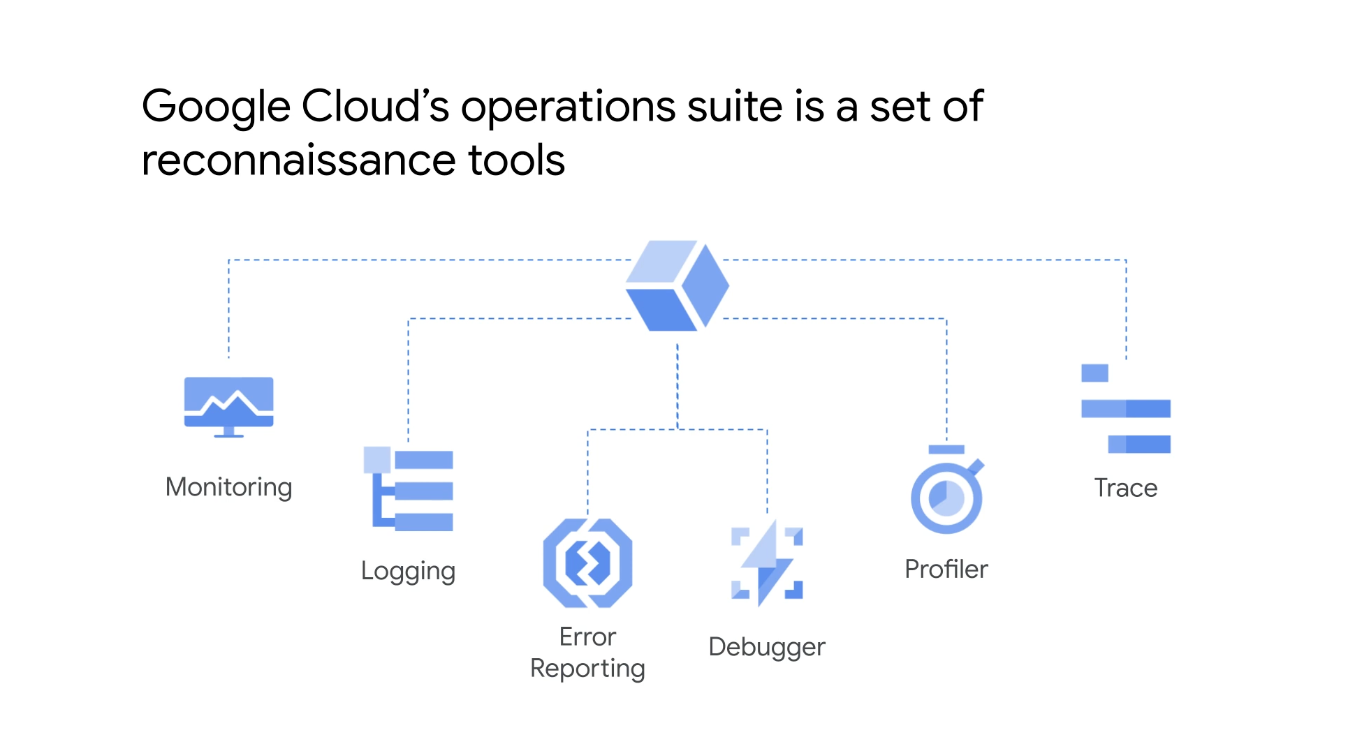
Google Kubernetes 엔진, 클러스터 및 애플리케이션을 모니터링하고 문제를 해결하는 방법을 설명할 것인데 Google Cloud의 운영 제품군은 애플리케이션 및 인프라에 대한 모니터링, 로깅, 디버깅을 포함하는 정찰 도구 모음이며 인프라의 모든 상태를 보고 경고를 관리할 수 있는 단일 창을 제공한다.
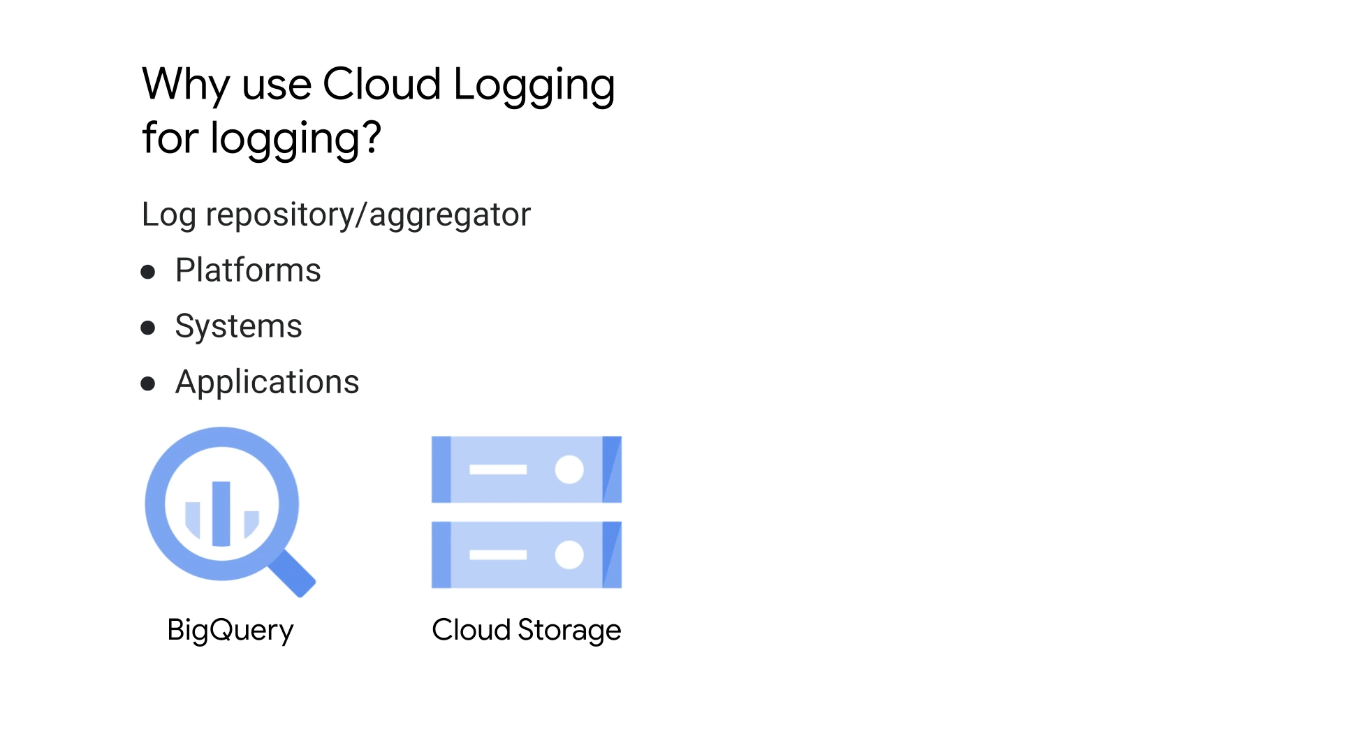
클라우드 로깅은 플랫폼, 시스템 및 애플리케이션에 대한 로그 저장소 및 수집기 역할을 한다.
로그는 가장 복잡한 검색의 일부를 공감하는 빅 쿼리의 힘으로 검색할 수 있으며 장기 보관 및 참조를 위해 로그 데이터를 클라우드 로깅에서 Google Cloud 스토리지 서비스, 즉 클라우드 스토리지 또는 BigQuery로 이동할 수 있다.
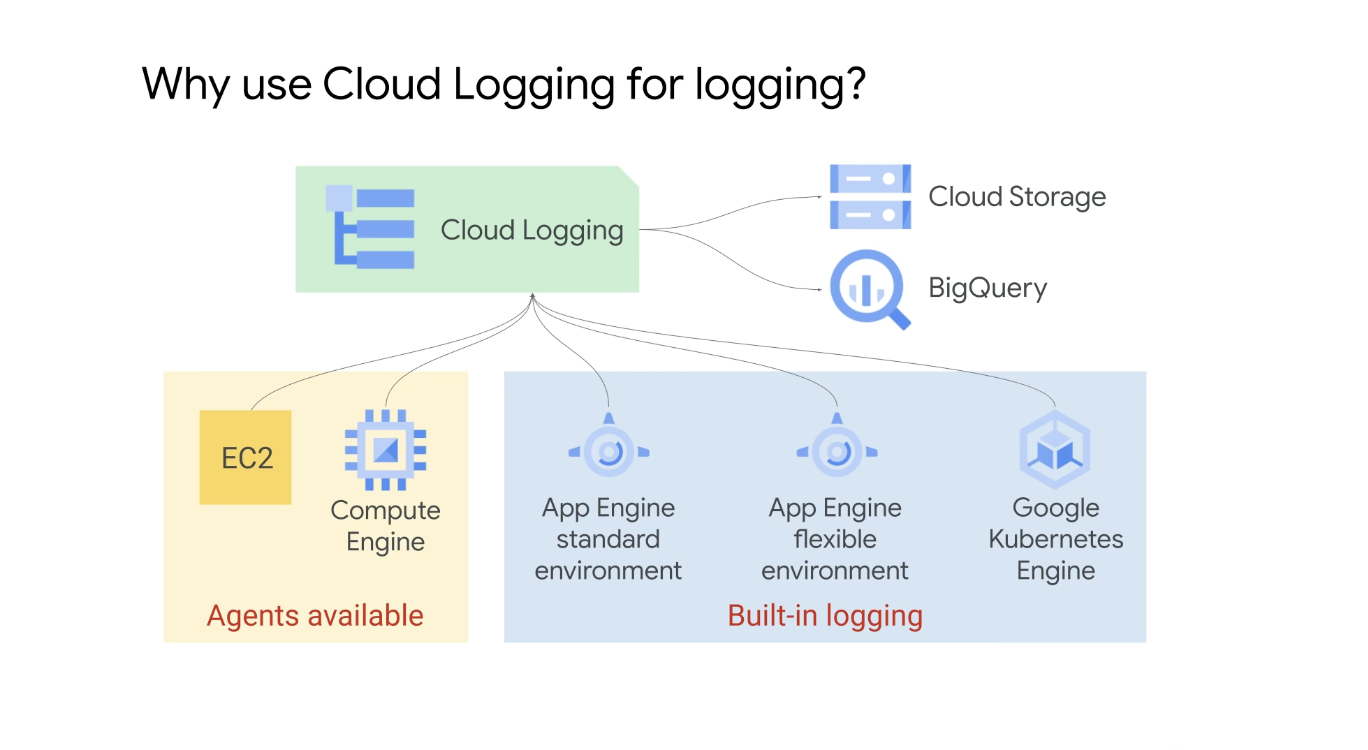
Cloud Logging은 많은 Google Cloud 제품 및 서비스의 기본 로깅 솔루션이며 컴퓨팅 엔진 인스턴스 및 Amazon EC2 인스턴스용 에이전트 기반 설치 소프트웨어를 제공한다.

클라우드 모니터링 엔진을 사용하면 애플리케이션의 상태를 나타내는 메트릭이 포함된 사용자 정의 대시보드 및 경고를 생성할 수 있다.
또한, 메트릭을 사용자 정의하여 애플리케이션의 상태, 로드 또는 동작에 대한 추가 정보를 얻을 수도 있다.
클라우드 모니터링의 대시보드와 그래프는 시스템이 제대로 작동하는지 한 눈에 확인할 수 있는 방법을 제공한다는 장점이 있는데 가장 중요한 점은 그래프가 성능 병목 현상 또는 서비스 종속성과 같은 이벤트에 대한 시각적 상관 관계 대기열을 제공한다는 점이고 또한, 클라우드 모니터링을 많은 타사 제품 즉, 써드파티 제품들과 통합할 수 있다.

하지만, 이벤트는 밀접하게 관련되어 있지만 메트릭과 다르다.
메트릭은 CPU 또는 디스크 사용량과 같이 모니터링할 수 있는 값이고 게이지 값이라고 하는 시간이 지남에 따라 위 또는 아래로 변경되는 값 또는 카운터라고 하는 시간이 지남에 따라 증가하는 값일 수 있다.
이벤트는 클러스터, 포드 또는 컨테이너에서 발생하는 일이며 이벤트의 몇 가지 예를 살펴보자.
포드, 메모 또는 서비스의 재시작, 클러스터의 배포 수 확장 또는 축소 또는 요청에 응답하는 애플리케이션에 Event는 일반적으로 성공, 경고 또는 실패를 보고하고 Metric은 숫자 값을 보고한다.
- 메트릭은 리소스에 따라 다르고 병목 현상을 식별하는 데 도움이 될 수 있음
- 이벤트는 클러스터 확장 또는 축소 시도에 나타나는 오류 또는 경고를 포함할 수 있음
Google Cloud의 운영 제품군은 단순한 모니터링 및 로깅을 넘어 애플리케이션 개발을 지연시키거나 방해할 수 있는 오류 및 성능 문제에 대한 더 깊은 통찰력을 제공하는데 추가 도구를 사용하면 디버깅 및 코드 문제 해결에 쉽게 액세스할 수 있다.
-
Cloud Trace
- 애플리케이션의 구성 요소에서 생성한 각 요청의 실제 지연 시간을 정량화
-
Error Reporting
- 응용 프로그램 내에서 오류가 발생하면 이를 알리고 정보 및 호출 스택을 캡처한 다음 디버깅을 위해 해당 정보를 제공
- 클라우드 로깅만으로 캡처되는 문제 해결에 대한 자세한 정보를 제공
-
Cloudy Debugger
-
코드를 살펴보고 감시 지점을 설정하여 코드 실행 중에 주요 변수의 값을 결정할 수 있는 실시간 분석 도구
-
여러 면에서 중단점을 삽입할 수 있는 통합 개발 환경과 같음
-
코드에서 다음 코드 블록으로 이동하기 전에 현재 상태를 검사하며 디버거의 경우 이러한 중단점을 감시점이라고 하며 애플리케이션이 실행되는 동안 실제로 생성됨
-
애플리케이션 실행 중에 디버거는 코드를 읽고 살펴보며 현재 사용 중인 변수를 나열하는데 이를 통해 애플리케이션에 입력되는 사용 값에 대한 실시간 통찰력을 얻을 수 있으며 실행 중인 애플리케이션의 문제 해결을 훨씬 쉽게 만들 수 있음
-
디버거의 주요 이점은 워크로드의 성능에 상당한 영향을 미치지 않으면서 이러한 기능을 제공하며 저조한 성능의 코드로 애플리케이션 및 웹 서비스의 대기 시간과 비용을 매일 증가시키는 일을 줄일 수 있음
-
-
Profiler
- 애플리케이션 전체에서 실행되는 CPU 또는 메모리 집약적인 기능의 성능을 지속적으로 분석
- Profiler는 모든 프로덕션 애플리케이션 인스턴스에서 실행되는 통계적 기술과 매우 낮은 영향을 미치는 계측을 사용하여 애플리케이션 속도를 저하시키지 않으면서 애플리케이션 성능에 대한 완전한 그림을 제공
- Java, Go, 노드를 지원하여 Google Cloud, 기타 클라우드 플랫폼 또는 온프레미스를 포함하여 어디에서나 실행되는 애플리케이션을 분석할 수 있음
2. Logging
로깅은 프로그램, 프로세스 또는 서비스가 수행한 작업에 대한 포렌식 기록을 제공한다.
서비스나 제품이 잘 작동하는지 또는 오류가 발생하는지에 관계없이 로깅은 발생한 작업 및 이벤트에 대한 가시성을 제공한다.
로깅은 종종 수동적인 형태의 시스템 모니터링이며 서비스 상태를 능동적으로 쿼리하는 모니터링 서비스 대신 로깅 서비스가 이벤트 로그를 수동적으로 수집하고 이러한 로그를 사용하여 패턴을 식별하거나 운영자가 시스템 오류의 근본 원인을 추적하는 데 도움을 줄 수도 있다.
로깅은 모니터링과 함께 사용해야 한다는 점!
모니터링이 최종 사용자가 직면한 지표, 즉 서비스 수준 지표를 확인하는 경우 로깅은 훨씬 덜 어려운 방식으로 내부 시스템에서 데이터를 수집할 수 있다.
로그를 보는 방법은 두 가지가 있는데 kubectl 명령어를 사용하거나 Stackdriver 웹 기반 GCP 콘솔 인터페이스(유료 서비스)에서 컨테이너 로그를 볼 수 있다.
kubelet 및 kube 프록시와 같은 Kubernetes 시스템 구성 요소의 로그는 각 노드의 파일 시스템의 /var/log 디렉터리에 저장되며 각 컨테이너가 표준 출력 및 표준 오류에 작성한 메시지도 동일한 디렉터리에 기록된다.
실제 응용 프로그램에 이러한 메시지가 유용할까?
버퍼링이나 필터링 없이 단순히 표준 출력에 로그 메시지를 쓰는 것은 응용 프로그램에서 점차 보편화되고 있는데 이유는 kubectl 명령을 사용하여 이러한 로그 메시지를 캡처하고 중앙에서 관리할 수 있기 때문이다.
-
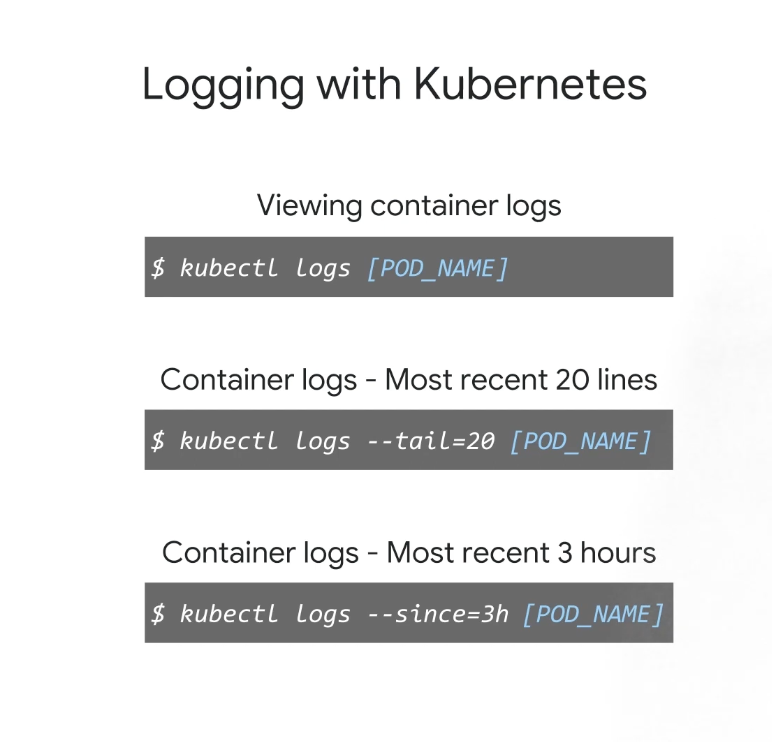
특정 포드의 로그를 보려면 kubectl logs 다음에 포드 이름을 사용
-
최근 문제를 해결할 때 소수의 로그만 검색하는 것이 훨씬 더 편리
-
kubectl logs 명령에
--tail옵션을 포함하면 기록되는 로그 수를 제한할 수 있으며 표시된 예에서는 출력을 가장 최근 20줄로 제한할 수 있다. -
검색할 로그 메시지 수는 있지만 지난 몇 시간 동안 문제가 발생했음을 알고 있다면
--since옵션 뒤에 기간을 추가하여 기준으로 시간을 사용하여 출력을 제한할 수도 있다.- 이 예에서 kubectl은 지난 3시간 동안 이 부분에 대한 로그를 반환합니다.
-
--previous옵션을 사용하여 컨테이너가 충돌하고 다시 시작되기 전에 컨테이너의 이전 인스턴스화를 볼 수도 있다.
Kubernetes에서 컨테이너 엔진은 표준 출력 및 표준 오류 스트림을 컨테이너에서 로깅 드라이버로 보낸다.
이 드라이버는 이러한 컨테이너 로그를 JSON 형식으로 작성하고 노드 수준의 /var/log 디렉터리에 저장하도록 구성되는데 이러한 로그 파일이 커지면 노드 디스크가 쉽게 포화 상태가 될 수 있다.
이를 방지하기 위해 GKE는 기본적으로 이러한 로그를 Stackdriver로 스트리밍한 다음 정기적으로 Linux logrotate 유틸리티를 실행하여 이러한 파일을 정리한다.
1일보다 오래되었거나 100MB로 커진 모든 로그 파일은 압축되어 아카이브 파일로 복사되고 가장 최근에 보관된 로그 파일 5개만 노드에 보관되며 너무 많은 디스크 공간을 사용하는 로그를 방지하기 위해 이전 버전은 제거된다.
그러나 모든 로그 이벤트는 Stackdriver로 스트리밍되며 Stackdriver는 기본적으로 모든 로그 이벤트 데이터를 30일 동안 보관하는데 조직에서 로그 데이터를 30일 이상 보관해야 하는 경우 데이터를 BigQuery 또는 Cloud Storage와 같은 장기 저장소로 내보내도록 Stackdriver를 구성하면 된다.
어떤 이유로든 Pod가 제거되거나 다시 시작되면 해당 Pod와 연결된 로그 및 아카이브가 손실되며 결과적으로 컨테이너, Pod 또는 노드 외부에 로그를 저장해야 하는 솔루션을 세울 수 밖에 없다.
이를 클러스터 수준 로깅이라고 한다.
앞서 언급했듯이 Kubernetes 자체는 로그 스토리지 솔루션을 제공하지 않지만 다양한 구현을 지원하는데 GKE에서는 Cloud Logging과의 통합을 통해 이를 처리한다.
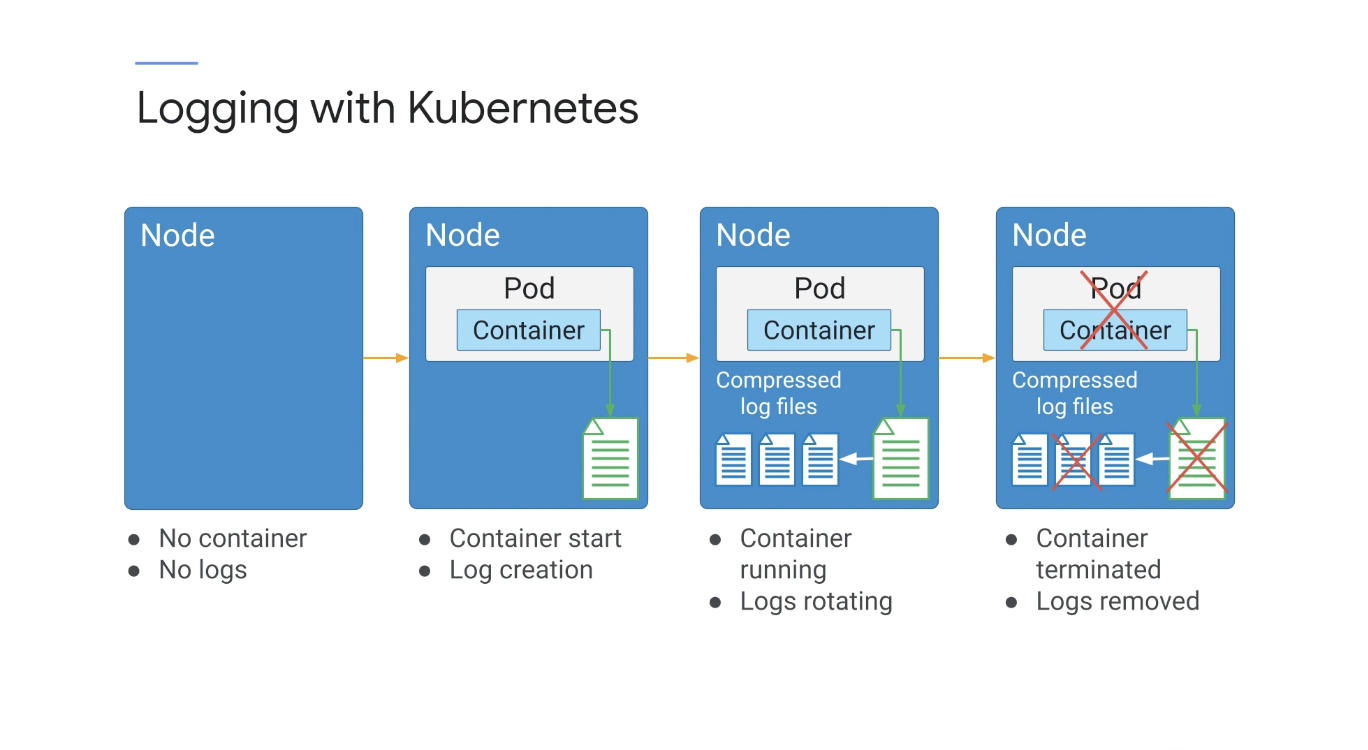
컨테이너가 노드에서 시작되면 로그 파일이 생성되는데 노드 수준 로깅은 순환 메커니즘을 사용하여 로그 아카이브를 구현한다.
컨테이너가 실행되면 이벤트가 발생하고 로그 파일이 커지는데 하루에 한 번 또는 로그 파일이 100MB에 도달하면(둘 중 먼저 도래하는 시점) 회전 유틸리티는 새 로그를 생성하고 이전 로그 파일을 압축하여 아카이브에 저장한다.
그런 다음 가장 최근에 압축된 로그 아카이브 5개를 제외하고 모두 삭제한다.
이렇게 하면 로그가 노드에서 사용 가능한 모든 스토리지를 소비하지 않는 장점이 있다.
컨테이너가 다시 시작되면 kubelet의 기본 동작은 종료된 컨테이너 하나를 로그와 함께 유지하고 컨테이너가 노드에서 삭제되면 컨테이너가 노드에서 삭제될 때 모든 로그가 삭제된다.
포드가 노드에서 삭제되면 해당하는 모든 컨테이너도 해당 로그와 함께 삭제된다.
결국은 Cloud Logging과 같은 중앙 로그 관리 유틸리티를 사용하지 않는 한 로그가 남지 않는다는 점이다.
그러면 Cloud Logging에 대해 알아보면 앞에서 본 것처럼 Logging은 이러한 애플리케이션 및 시스템 로그를 관리하는 완전 관리형 서비스이다.
로깅은 초당 테라바이트의 로그 데이터를 자동으로 확장하고 수집하도록 설계되었으며 GKE에서 Logging은 기본적으로 사용 설정되어 있지만 필요한 경우 클러스터에서 사용 중지할 수도 있습니다.
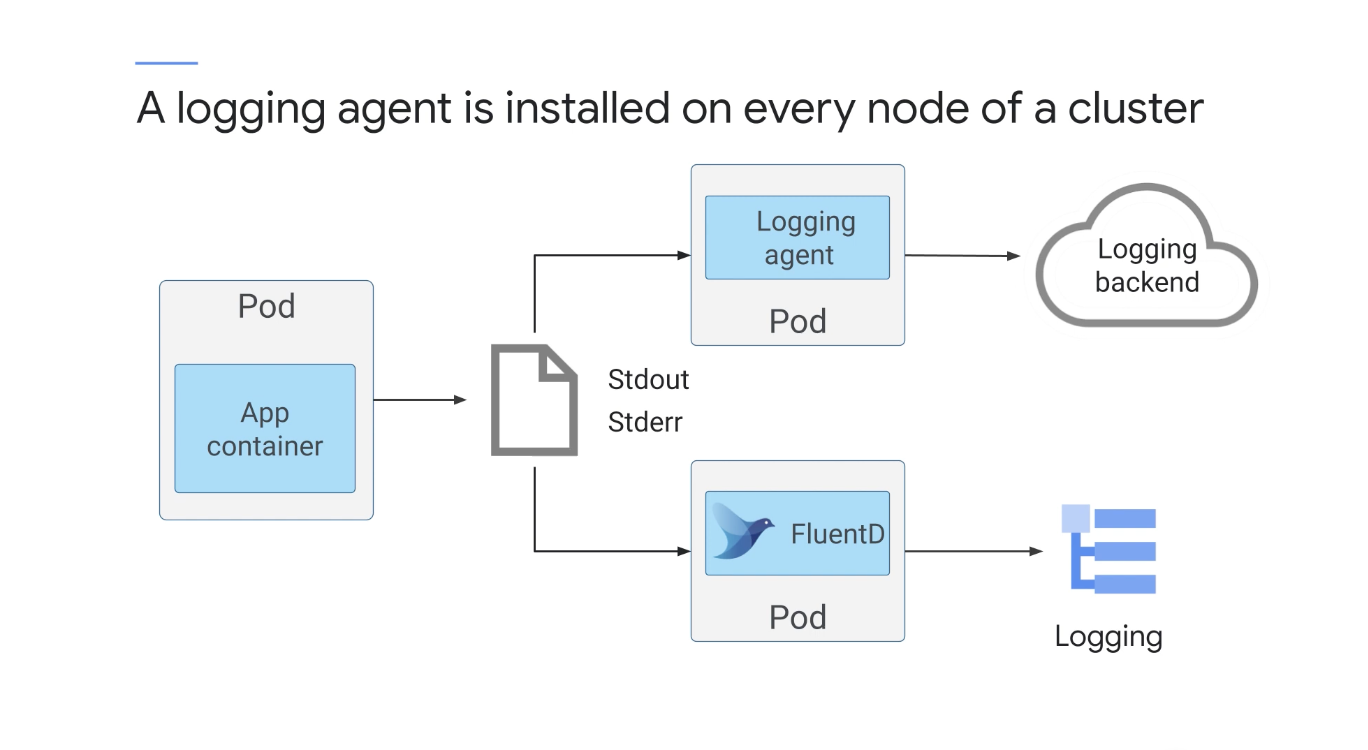
Logging 에이전트는 노드에 사전 설치되고 로그 데이터를 Logging으로 푸시하도록 사전 구성되며 또한, 공개 API를 사용하여 커스텀 로그를 작성하고 Logging에 푸시할 수도 있다.
또한 로그 뷰어 콘솔에서 또는 Cloud Logging API를 통해 직접 Logging 필터 언어를 사용하여 표시되는 로그를 필터링할 수 있다.
GKE는 클러스터의 모든 노드에 로깅 에이전트를 설치하고 이 에이전트는 컨테이너의 로그와 시스템 구성요소 로그를 수집하여 Cloud Logging 백엔드로 푸시한다.
Cloud Logging은 FluentD를 노드 로깅 에이전트로 사용하는데 FluentD는 이전에 언급한 모든 로그를 읽고 유용한 메타데이터를 추가한 다음 해당 로그를 Cloud Logging에 지속적으로 푸시하는 로그 애그리게이터이다
FluentD는 클러스터의 모든 노드가 특정 Pod의 복사본을 실행하도록 DaemonSets를 사용할 수 있기 때문에 DaemonSet를 사용하여 설정된다.
FluentD 에이전트의 구성은 ConfigMaps를 통해 관리되고 이는 구성 요소(ConfigMap)에서 애플리케이션(FluentD DaemonSet)을 분리하여 구현의 확장성을 높일 수 있는 장점이 있다.
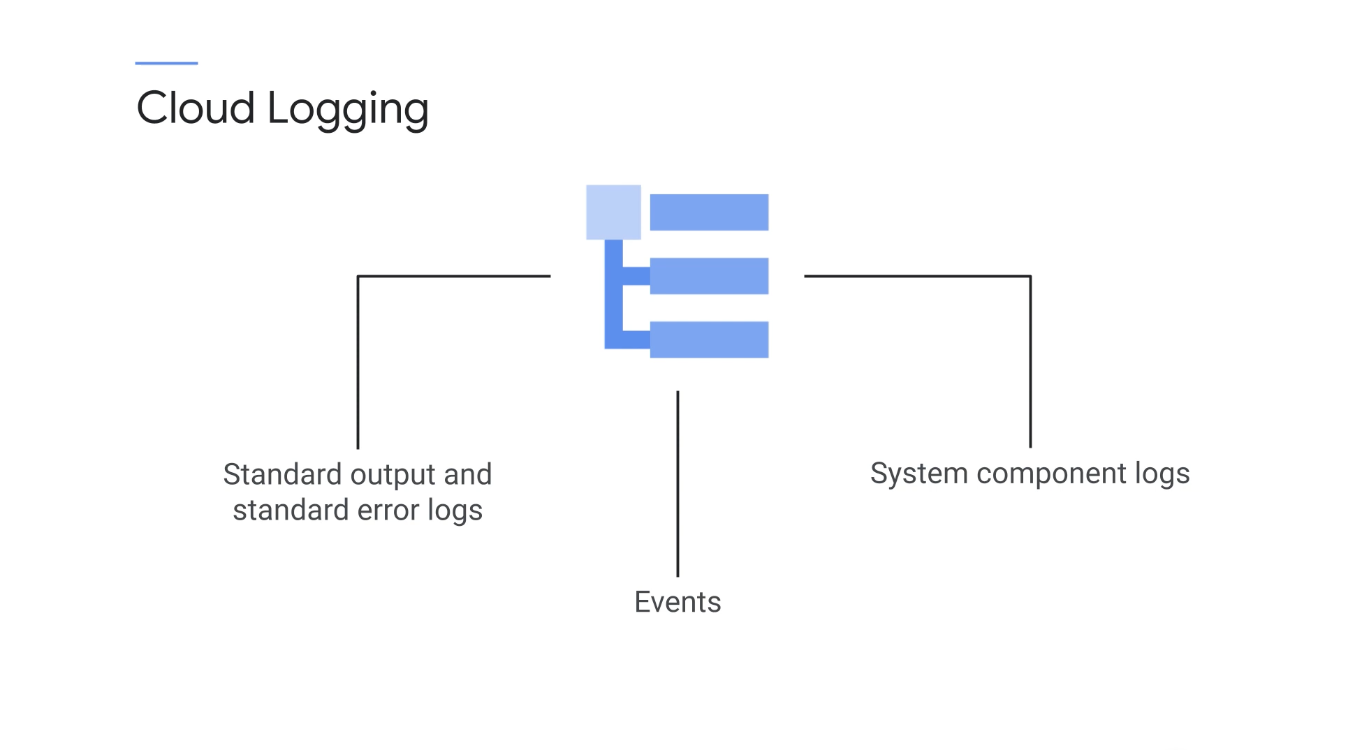
이벤트는 클러스터에서 발생하는 모든 작업인데 몇 가지 예에는 포드 삭제, 확장 및 배포, 컨테이너 생성이 포함된다.
이러한 이벤트는 클러스터 제어 영역에 API 개체로 저장되며 이러한 이벤트는 Kubernetes에 일시적으로만 저장되기 때문에 GKE는 클러스터 제어 영역에 이벤트 내보내기 도구를 배포하여 이러한 이벤트를 캡처하고 Cloud Logging으로 푸시한다.
3. Monitoring
모니터링을 통해 다양한 관점에서 서비스 경험을 시각화할 수 있거나 환경 외부에서 모니터링하여 사용자 관점에서 서비스를 볼 수 있고 또는 환경 내에서 모니터링하여 주요 내부 메트릭에 대한 통찰력을 얻을 수 있다.
사이트 안정성 엔지니어링 SRE는 DevOps에 대한 Google의 접근 방식이다.
이는 Google이 서비스를 안정적이고 대규모로 실행하는 방법의 근본적인 부분이며 SRE의 중요한 부분 중 하나는 바로 서비스 안정성 계층 구조입니다.
위의 다이어그램은 무엇이 무엇에 의존하는지, 주어진 수준의 활동은 그 아래에 무엇이 있는지를 보여준다 다이어그램에서 볼 수 있듯이 모니터링은 서비스 안정성 계층 구조의 가장 기본적인 계층이며 다른 모든 것은 서비스 또는 제품 자체에 이르기까지 모니터링에 달려 있으며 모니터링을 통해 감정이 아닌 데이터를 기반으로 애플리케이션에 대한 결정을 내릴 수 있다.
-
모니터링은 종종 로깅과 결합되어 시스템 상태 및 과거 추세에 대한 완전한 그림을 제공한다.
-
또한 시간 경과에 따라 시스템의 크기를 조정하고 확장하는 데 도움이 되는 경향과 패턴을 나타낼 수 있다.
-
Kubernetes 모니터링은 실제로 클러스터와 메모를 관찰하는 것이 아니라 애플리케이션의 현재 상태와 이를 방해할 수 있는 모든 것을 모니터링하는 것이다.
-
견고한 모니터링 솔루션을 설정하면 마이크로서비스 기반 애플리케이션의 문제를 해결할 때 많은 도움이 될 수 있다.
- 이러한 서비스는 설계상 느슨하게 결합되어 있기 때문에 서로 다른 시스템 간에 데이터를 전송할 때 복잡한 문제 해결 상황이 발생할 수 있다.
-
서비스의 처리량 및 대기 시간을 포함하여 이러한 서비스의 상태를 정확하게 모니터링할 수 있는 경우 성능 병목 현상을 보다 쉽게 추적할 수 있다.
- Stackdriver의 집계 로깅 및 디버깅을 통해 애플리케이션 코드 문제를 진단할 수 있다.
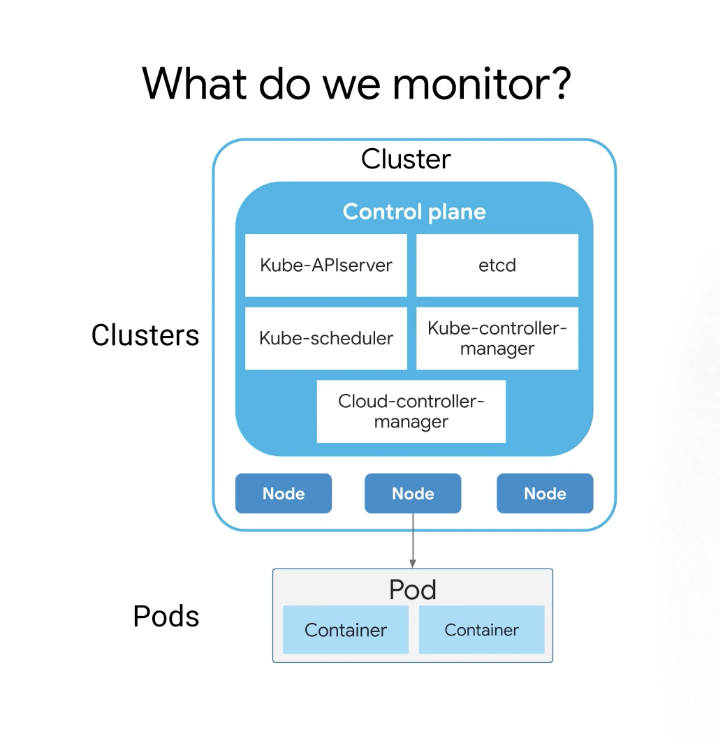
Kubernetes에서 모니터링은 두 개의 도메인으로 나눌 수 있는데 하나의 도메인은 클러스터 수준 구성 요소 모니터링과 관련된 클러스터이다.
- 개별 노드, kube-APIserver, etcd, kube-controller-manager 등
다른 모니터링 도메인은 내부에서 실행되는 컨테이너 및 애플리케이션을 포함하는 포드이다.

클러스터 모니터링은 클러스터 서비스, 노드 및 기타 인프라 요소를 나타내며 이는 GCP 콘솔의 모니터링을 사용하거나 상태 확인 및 대시보드를 사용하는 Stackdriver를 통해 수행할 수 있다.
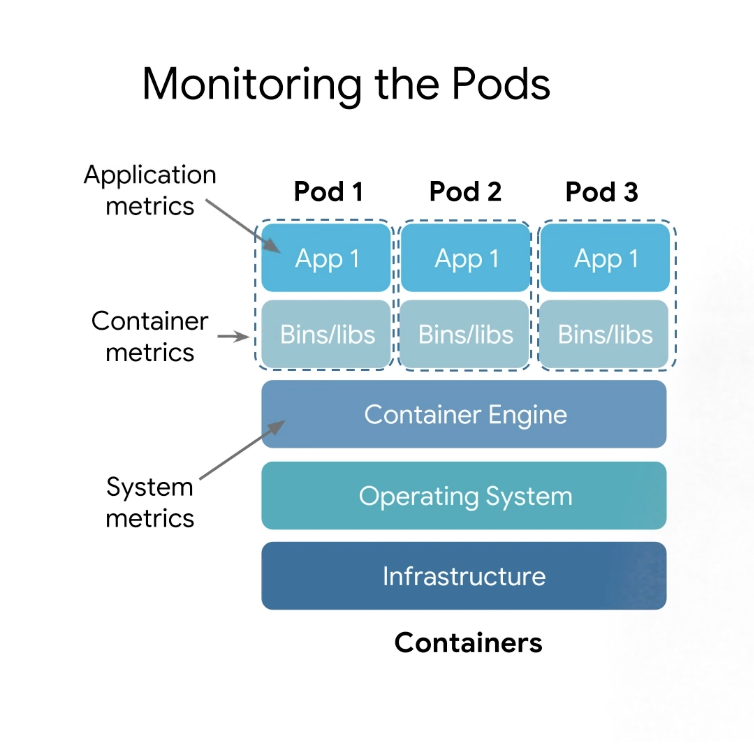
Pod 모니터링은 컨테이너 배포, 인스턴스, 상태 확인 및 상태와 관련된 여러 하위 범주 시스템 메트릭으로 나눌 수 있다.
컨테이너 메트릭은 애플리케이션 개발자가 설계하고 모니터링 솔루션에 노출되는 리소스 소비 및 애플리케이션별 메트릭과 같은 컨테이너별 메트릭인데 모니터링할 호스트 이름을 지정할 수 있는 기존 서버 모니터링과 달리 Kubernetes의 추상화 계층은 일반적으로 컨테이너이다.
따라서 특정 호스트 이름이나 iP 주소를 모니터링하는 대신 접근 방식을 변경하도록 해야하는데 Kubernetes의 모든 리소스에는 논리적 구조를 생성하기 위해 정의하는 레이블이 있으며 이러한 레이블은 리소스 구성에 대한 논리적 접근 방식을 제공한다.
또한 서로 다른 레이블 조합을 선택하여 특정 시스템이나 하위 시스템을 더 쉽게 모니터링할 수 있다.
Stackdriver 및 기타 도구를 사용하면 로그를 필터링하고 지정된 라벨과 일치하는 구성요소에 대한 모니터링에 집중할 수도 있다.
4. GKE 네이티브 모니터링 및 로깅 구성 실습
이 실습에서는 GKE 클러스터를 빌드한 다음 Kubernetes Engine Monitoring과 함께 사용할 포드를 배포한다.
차트와 사용자 지정 대시보드를 만들고, 사용자 지정 메트릭으로 작업하고, 경고를 만들고 응답해볼 것이다.
우리의 목표는 Kubernetes Engine Monitoring을 사용하여 클러스터 및 워크로드 측정항목을 볼 것이고 Cloud Monitoring 알림을 사용하여 클러스터 상태에 대한 알림 수신을 구현해볼 것이다.
4-1. Kubernetes Engine Monitoring 사용
이제 Google Kubernetes Engine에 Monitoring에 대한 관리형 지원이 포함되는데 GKE 클러스터를 만들 때 두 가지 Monitoring 지원 옵션 중 하나를 선택할 수 있다.
레거시 Cloud Monitoring➡️ GKE Version 1.13 이하시스템 및 워크로드 로깅 및 모니터링➡️ GKE Version 1.14 이상
이 작업에서는 Kubernetes Engine Monitoring을 지원하는 새 클러스터를 만든 다음 Kubernetes Engine 모니터링 및 로깅 인터페이스를 사용하여 일반적인 모니터링 작업을 수행한다.
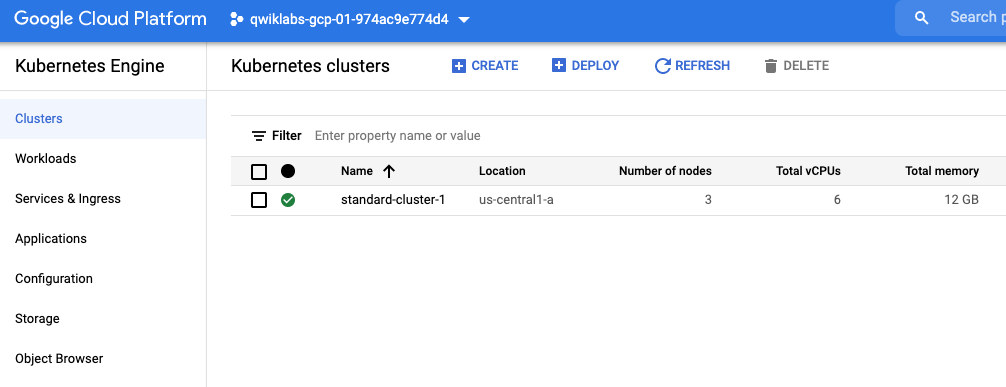
Kubernetes Engine Monitoring으로 GKE 클러스터 구성
export my_zone=us-central1-a
export my_cluster=standard-cluster-1
source <(kubectl completion bash)네이티브 Kubernetes 모니터링이 활성화된 VPC 네이티브 Kubernetes 클러스터 생성
gcloud container clusters create $my_cluster \
--num-nodes 3 --enable-ip-alias --zone $my_zone \
--logging=SYSTEM \
--monitoring=SYSTEM
gcloud container clusters get-credentials $my_cluster --zone $my_zoneGoogle Cloud Console을 사용하여 모니터링 구성 확인
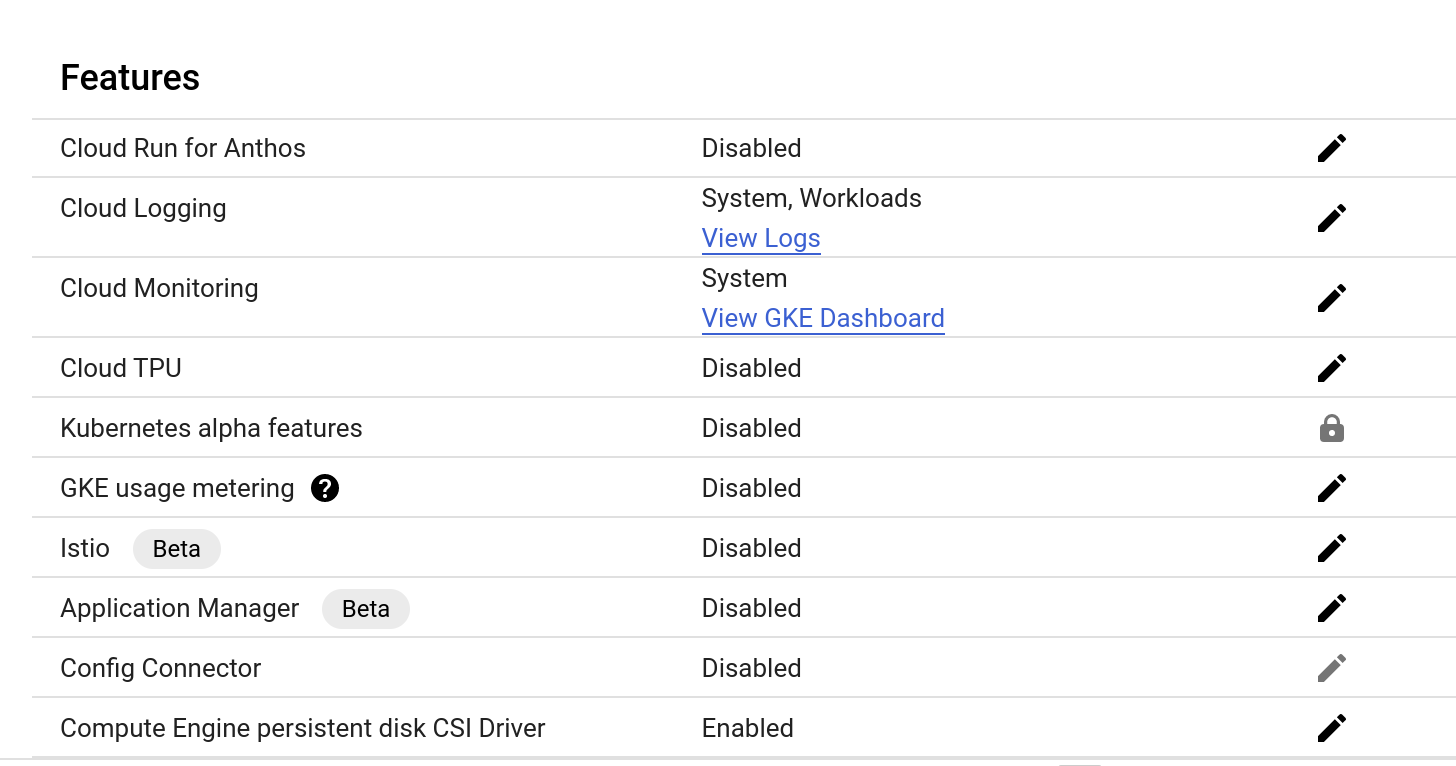
기능 제목 아래에서 로깅 유형을 시스템, 워크로드 및 시스템 으로 설정하는 Cloud Logging 및 Cloud Monitoring 설정을 볼 수 있다.
GKE 클러스터에 샘플 워크로드 배포
이 워크로드는 간단한 Hello World 데모 애플리케이션을 실행하는 3개의 팟(Pod) 배치로 구성되며 뒷부분에서 Monitoring에서 이 워크로드의 상태를 모니터링할 수 있을 것이다.
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
ln -s ~/training-data-analyst/courses/ak8s/v1.1 ~/ak8s
cd ~/ak8s/Monitoring/
kubectl create -f hello-v2.yaml
kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
hello-v2 3/3 3 3 6sGCP-GKE-Monitor-Test 애플리케이션 배포
# 현재 프로젝트 ID를 환경 변수에 저장
export PROJECT_ID="$(gcloud config get-value project -q)"
cd gcp-gke-monitor-test부하 테스트 애플리케이션용 Docker 이미지를 빌드하고 랩 프로젝트용 Google gcr.io 레지스트리에 이미지를 푸시
gcloud builds submit --tag=gcr.io/$PROJECT_ID/gcp-gke-monitor-test .
$ cat Dockerfile
FROM node:10-alpine
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm ci --only=production
COPY . .
EXPOSE 8080
CMD [ "node", "server.js" ]
$ cat package.json
{
"name": "gcp-gke-monitoring",
"version": "1.2.0",
"description": "A monitoring test utility for GKE and Stackdriver",
"main": "server.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node server.js"
},
"repository": {
"type": "git",
"url": "git+https://github.com/brianeiler/gcp-gke-monitoring.git"
},
"keywords": [
"GKE"
],
"author": "Brian Eiler",
"license": "ISC",
"bugs": {
"url": "https://github.com/brianeiler/gcp-gke-monitoring/issues"
},
"homepage": "https://github.com/brianeiler/gcp-gke-monitoring#readme",
"dependencies": {
"@google-cloud/monitoring": "^1.2.2",
"body-parser": "^1.19.0",
"express": "^4.17.1",
"googleapis": "^40.0.1",
"nanotimer": "^0.3.15"
}
}
cd ..
# gcp-gke-monitor-test.yaml 파일의 자리 표시자 값을 방금 gcr.io 에 푸시한 Docker 이미지로 바꾸기
sed -i "s/\[DOCKER-IMAGE\]/gcr\.io\/${PROJECT_ID}\/gcp-gke-monitor-test\:latest/" gcp-gke-monitor-test.yamlKubernetes Engine Monitoring을 테스트하는 데 사용할 배포 및 서비스 생성
$ cat gcp-gke-monitor-test.yaml apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: gcp-gke-monitor-test
name: gcp-gke-monitor-test
namespace: default
spec:
replicas: 1
selector:
matchLabels:
name: gcp-gke-monitor-test
template:
metadata:
labels:
name: gcp-gke-monitor-test
spec:
containers:
- image: gcr.io/qwiklabs-gcp-04-9ab754beb8f7/gcp-gke-monitor-test:latest
name: gcp-gke-monitor-test
ports:
- containerPort: 8080
protocol: TCP
env:
- name: POD_ID
valueFrom:
fieldRef:
fieldPath: metadata.uid
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: NAMESPACE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.namespace
---
apiVersion: v1
kind: Service
metadata:
labels:
name: gcp-gke-monitor-test
name: gcp-gke-monitor-test-service
namespace: default
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
name: gcp-gke-monitor-test
type: LoadBalancer
kubectl create -f gcp-gke-monitor-test.yaml
kubectl get deployments
NAME READY UP-TO-DATE AVAIL AGE
gcp-gke-monitor-test 1/1 1 0 1s
hello-v2 3/3 3 3 38s
kubectl get service
4-2. GCP-GKE-Monitor-Test 애플리케이션 사용
GCP-GKE-Monitor-Test 애플리케이션을 사용하여 Kubernetes Engine Monitoring의 다양한 측면을 살펴볼 것인데, 이 도구는 다음 네 부분으로 구성된다
- Generate CPU Load(CPU 부하 생성)
- Custom Metrics
- Log Test
- Crash the Pod
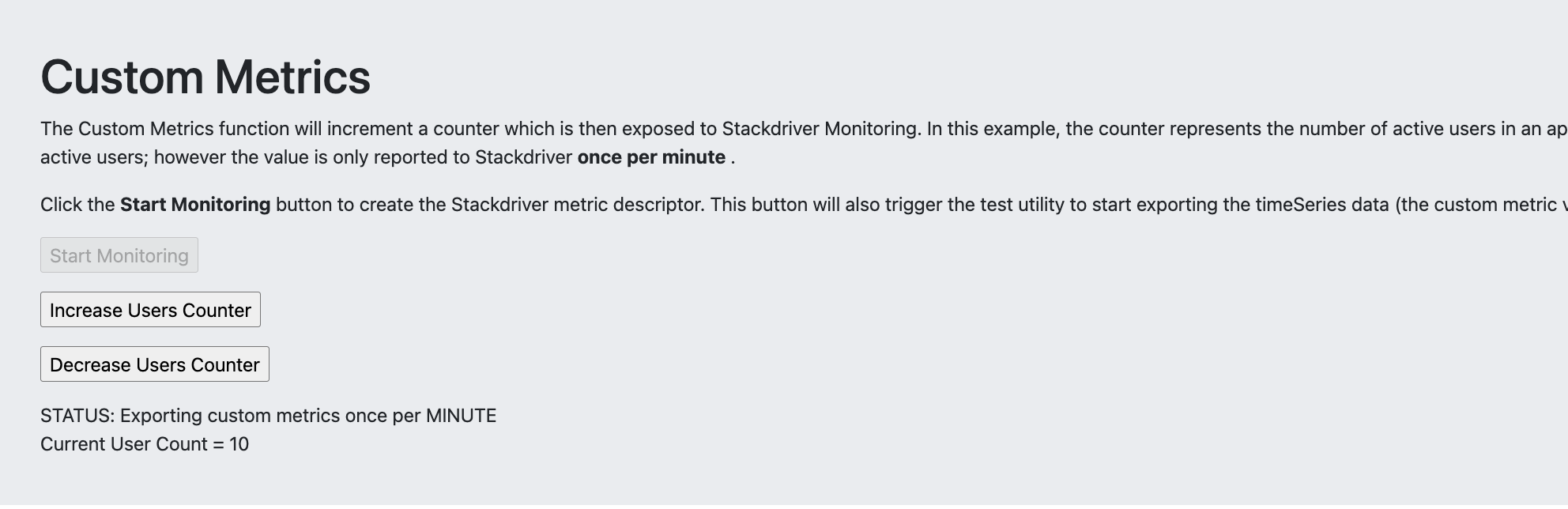
두 번째 섹션인 Custom Metrics 에서는 Cloud Monitoring 내에서 커스텀 측정항목 모니터링을 탐색할 수 있다.
모니터링 시작을 클릭하면 도구에서 먼저 필요한 사용자 정의 커스텀 메트릭 생성자를 생성한 다음 커스텀 메트릭값을 60초마다 Monitoring에 전송하는 루프를 시작한다.
이 도구에 코딩된 사용자 정의 메트릭은 연결된 활성 사용자 수를 추적할 수 있는 애플리케이션을 시뮬레이트한 다음 해당 수치를 외부 서비스에 보고하도록 설계되어있다.
이러한 사용자 지정 메트릭을 활용하려면 애플리케이션 코드 내에서 몇 가지 추가 계측이 필요할 수 있는데 이 실습에서는 사용자 증가 및 감소 버튼을 클릭하여 연결 및 연결 해제하는 사용자를 시뮬레이션할 수 있다.
또한 웹 도구를 사용하면 실시간으로 사용자 수를 변경할 수 있지만(사용자가 실생활에서 연결 및 연결 해제할 수 있는 것처럼) Cloud Monitoring API를 사용하면 도구에서 분당 한 번만 현재 값을 전송할 수 있다.
즉, Cloud Monitoring 차트는 분당 업데이트 사이에 발생하는 변경사항을 반영하지 않는다는 점이다.
로그 테스트는 컨테이너의 표준 출력(콘솔)에 다양한 텍스트 문자열을 보내고 Cloud Monitoring에서 주기적으로 수집하고 pod 및 컨테이너와 연결된 로그 메시지로 저장할 수 있다.
선택적으로 디버그 수준 로깅을 활성화하여 로그에서 더 많은 항목을 볼 수 있는데 이렇게 하면 Custom Metrics 섹션에서 사용자 수를 늘리거나 CPU Load Generator를 활성화 또는 비활성화할 때 로그에서 메시지를 볼 수 있다.
이러한 로그는 JSON 형식 메시지를 지원하지 않는 레거시 애플리케이션을 시뮬레이트하기 위해 일반 텍스트 형식으로 전송된다.
Logging에서 로그를 보면 포드의 JSON 기반 Kubernetes 이벤트 로그에 구조화되지 않은 로그에 사용할 수 있는 것보다 훨씬 강력한 필터링 및 쿼리 옵션이 있음을 알 수 있다.
Crash the Pod에서는 버튼 클릭으로 Pod를 충돌시킬 수 있다.
이 도구는 처리되지 않은 오류가 있는 코드 섹션을 실행하여 포드를 충돌시키고 배포를 트리거하여 해당 위치에서 새 포드를 다시 시작한다.
이 도구를 사용하여 Kubernetes Engine이 오류로부터 얼마나 빨리 복구할 수 있는지 확인할 수 있고, 또한 각 Pod가 중앙 위치에 저장하는 대신 자체 세션을 유지하기 때문에 세션 상태 손실이 실제로 발생하는 것을 볼 수 있는 기회이기도 하다.
포드가 다시 시작되면 모든 토글 버튼과 설정이 기본값으로 돌아간다.
CPU 부하 생성기 시작
kubectl get service명령어를 실행하여 EXTERNAL-IP 주소를 받고 GCP-GKE-Monitor-Test 도구에 연결하고 CPU 부하 생성기를 시작하자.
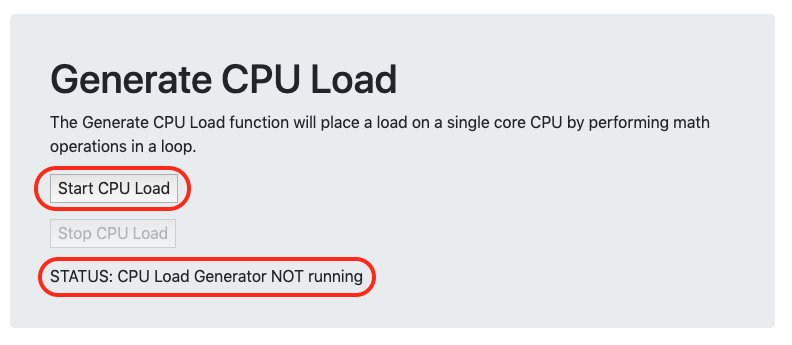
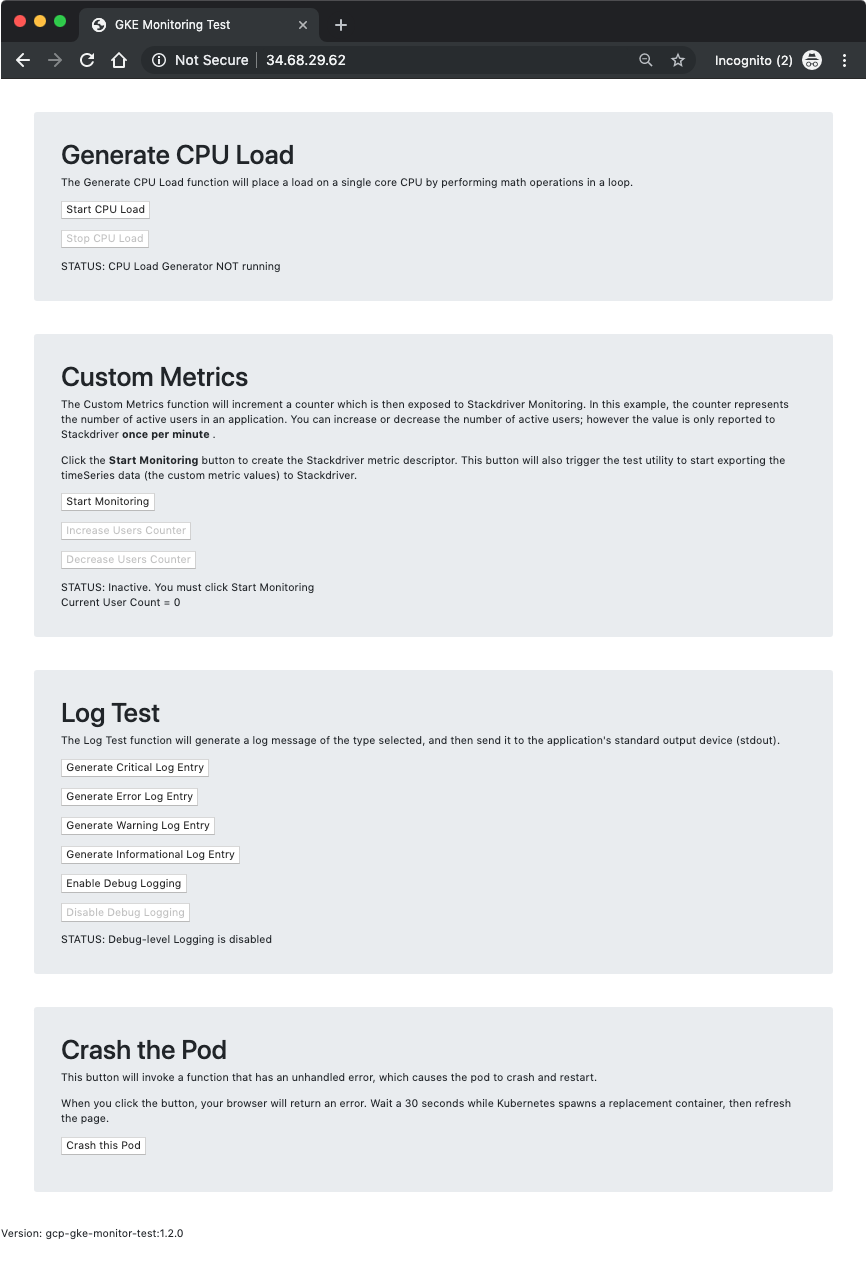
CPU 부하 생성 섹션 에서 CPU 부하 시작 버튼을 클릭하면 부하 생성기가 실행되기 시작하면서 STATUS 텍스트가 변경된다.
커스텀 메트릭 수집 시작
이제 Cloud Monitoring 내에서 커스텀 메트릭 설명자를 생성하는 GCP-GKE-Monitor-Test 도구 내에서 프로세스를 시작한다.
나중에 도구가 커스컴 메트릭 데이터 전송을 시작하면 Monitoring에서 데이터를 이 커스텀 메트릭 설명자와 연결한다.
커스텀 메트릭 데이터를 보낼 때 Monitoring에서 자동으로 커스텀 메트릭 설명자를 생성하는 경우가 많지만 수동으로 설명자를 생성하면 메트릭 탐색기로 Monitoring 인터페이스에 표시되는 텍스트를 더 잘 제어할 수 있으므로 데이터를 더 쉽게 찾을 수 있다.
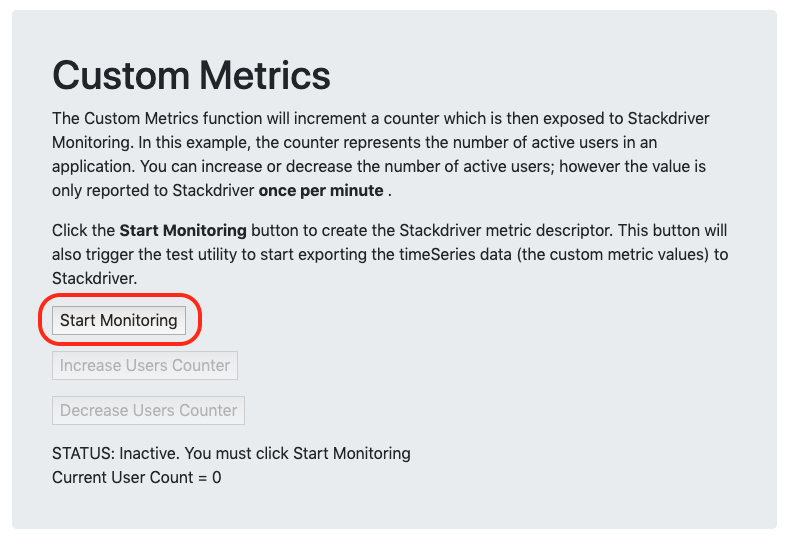
모니터링 시작 버튼을 클릭 ➡️ 사용자 수 증가를 클릭 하고 현재 사용자 수가 10명으로 설정될 때까지 반복

테스트 로그 메시지 생성
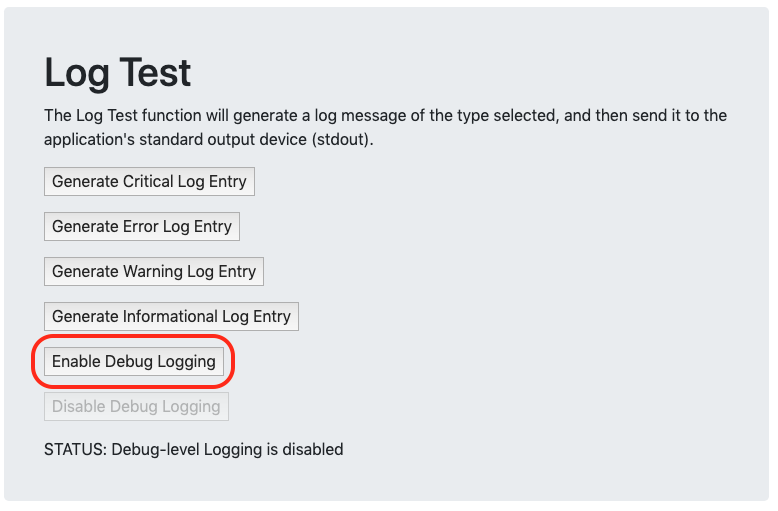
로그 테스트 섹션 에서 디버그 로깅 활성화 버튼을 클릭하여 도구가 생성하는 로그 수를 늘리자.
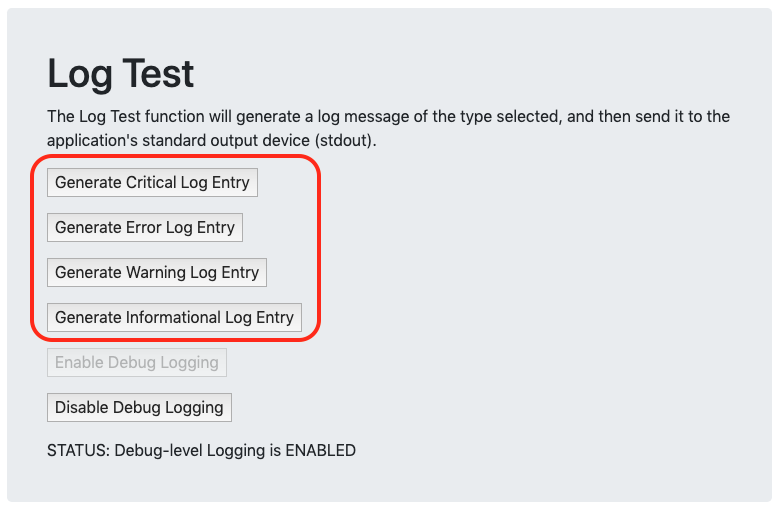
다른 4개의 로그 항목 버튼을 클릭하여 일부 추가 샘플 로그 메시지를 생성하는데 다양한 메시지 유형이 Monitoring에 표시되는 방식을 확인할 수 있도록 다양한 심각도 수준을 선택하는 것이 중요하다.
4-3. Kubernetes Engine Monitoring 사용
Kubernetes Engine Monitoring을 사용하여 GKE 클러스터와 클러스터에서 실행 중인 두 워크로드의 현재 상태를 확인해보자.
Console ➡️ 모니터링을 클릭
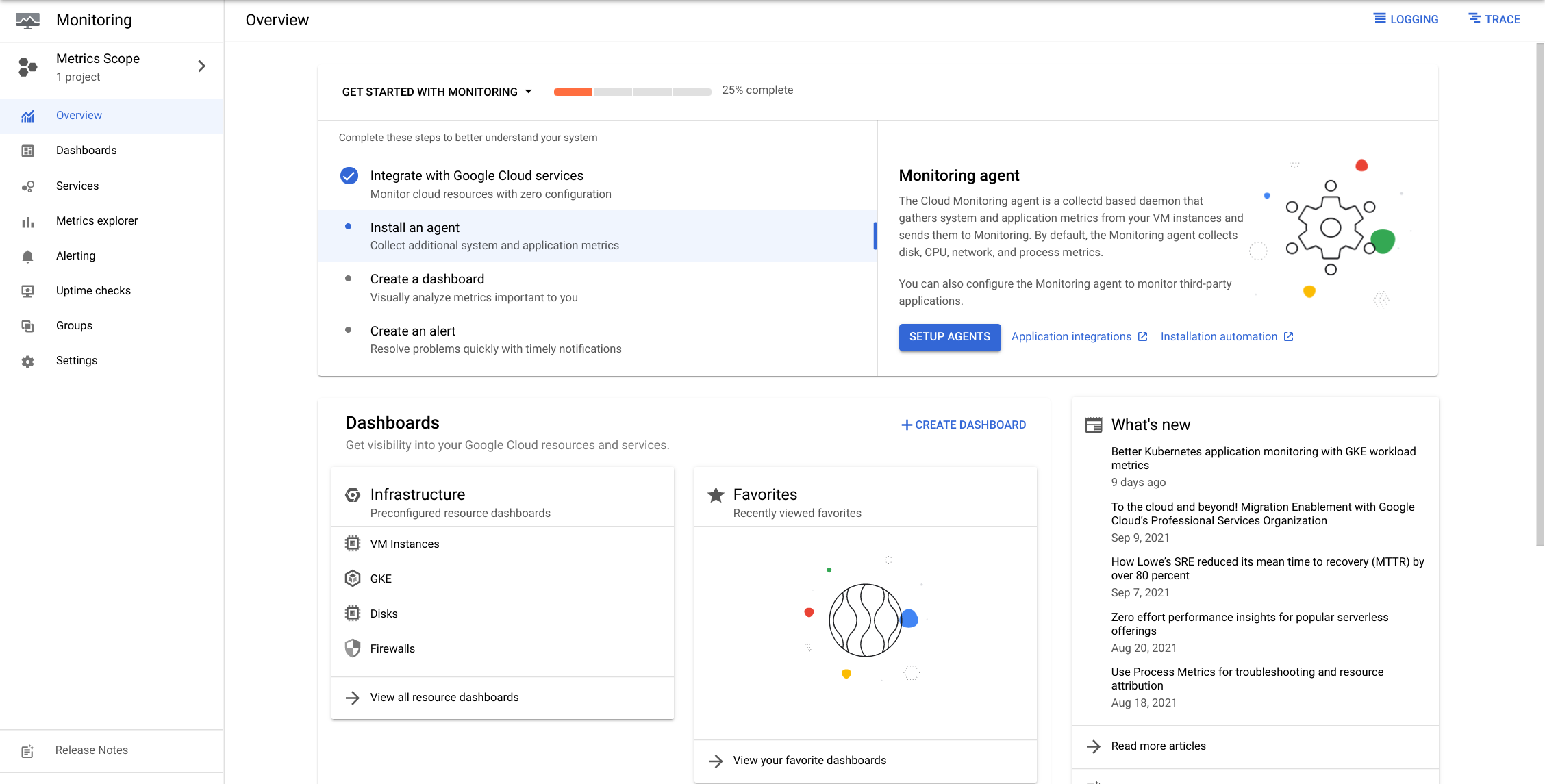
Kubernetes Engine 모니터링 인터페이스 검토
Kubernetes Engine Monitoring 인터페이스의 인프라, 워크로드 및 서비스을 열고 탐색해볼 것이다.
-
대시보드 섹션 의 GKE를 클릭하여 새 모니터링 인터페이스 보기
-
모니터링 인터페이스를 검토
- GKE 클러스터와 해당 워크로드의 상태를 보여주는 대시보드
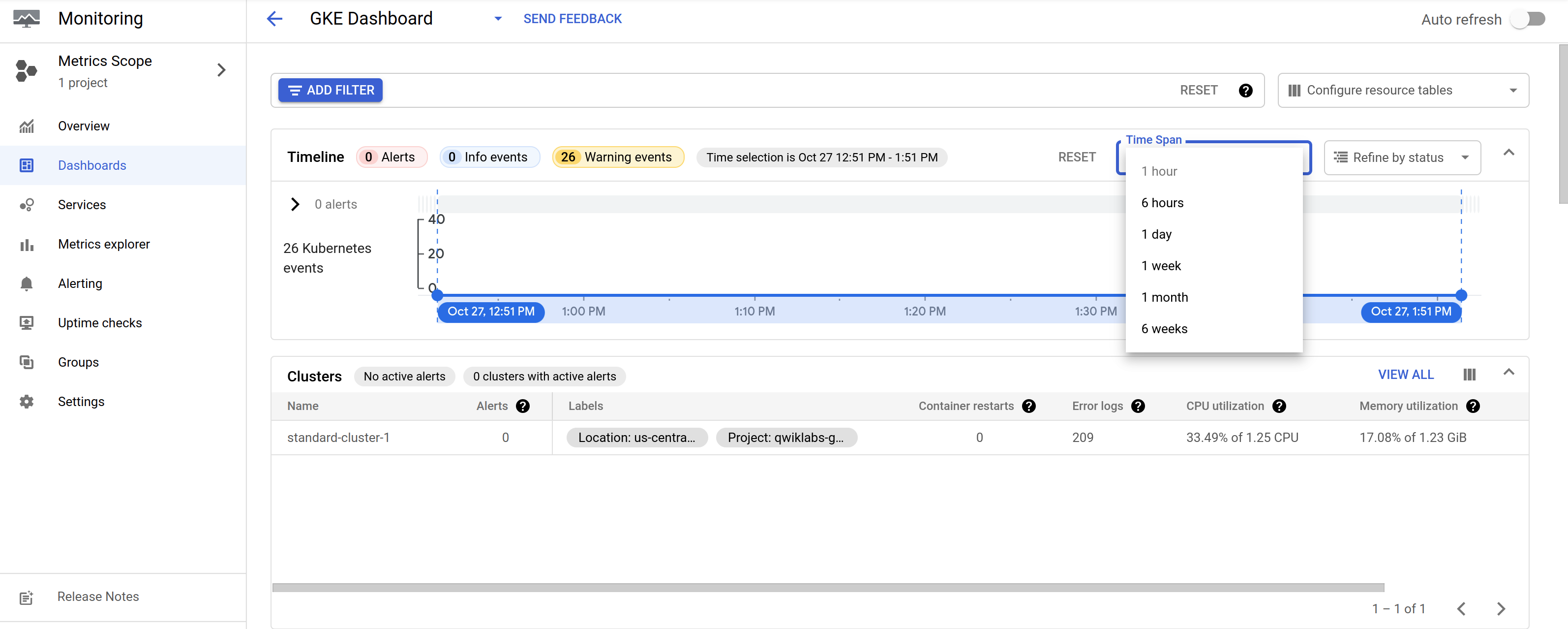
-
동적 타임라인은 인터페이스의 상단 부분에 표시되고 필요한 경우 드롭다운 아이콘을 클릭하여 확장할 수 있다.- 화면 상단에서 시간 범위를 조정할 수 있음 (1h, 6h, 1d, 1w, 1m, 6w 또는 사용자 지정 시간)
- 이 타임라인에는 알림(인시던트라고도 함) 발생을 나타내는 마커가 포함된다.
-
자동 새로 고침 버튼(화면 왼쪽의 토글 버튼): 자동 새로 고침 버튼을 클릭 하면 새 이벤트가 수신될 때 화면이 업데이트 된다. -
이 대시보드의 아래쪽 부분에는 클러스터 및 해당 워크로드의 여러 섹션 보기가 포함되어 있다.
- 인터페이스는 클러스터, 네임스페이스, 노드, 워크로드, Kubernetes 서비스, 포드 및 컨테이너의 여러 섹션으로 나뉜다.
인터페이스의 각 섹션 검사
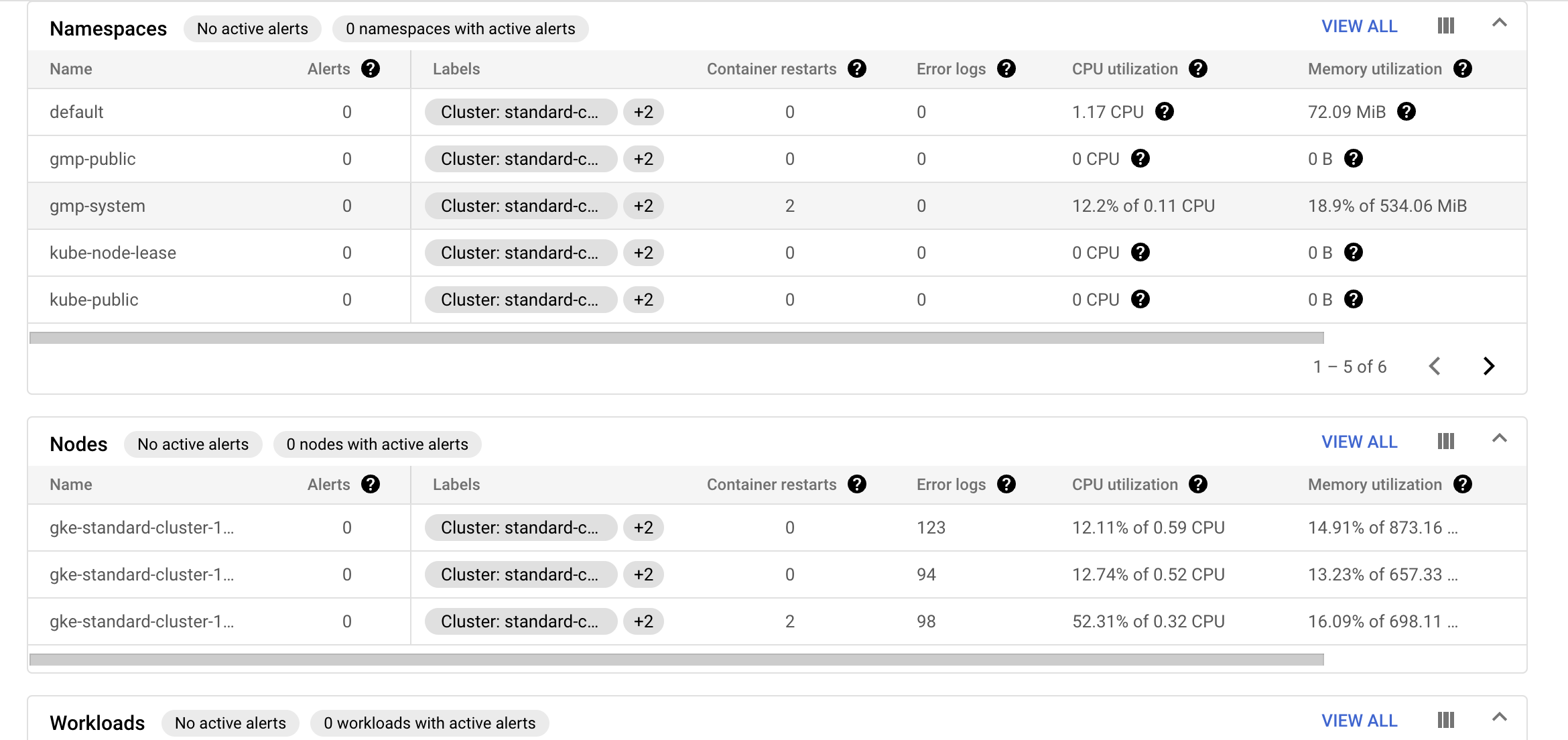
-
Clusters , Nodes 및 Pods 섹션을 사용하면 클러스터에 있는 특정 요소의 상태를 확인할 수 있다.- 이를 사용하여 클러스터의 특정 노드에서 실행 중인 포드를 검사할 수도 있음
-
클러스터의 세부 정보를 보려면
클러스터 요소를 클릭 -
워크 로드 섹션은 특히 노출된 서비스가 없는 워크로드를 찾을 때 매우 유용하다.
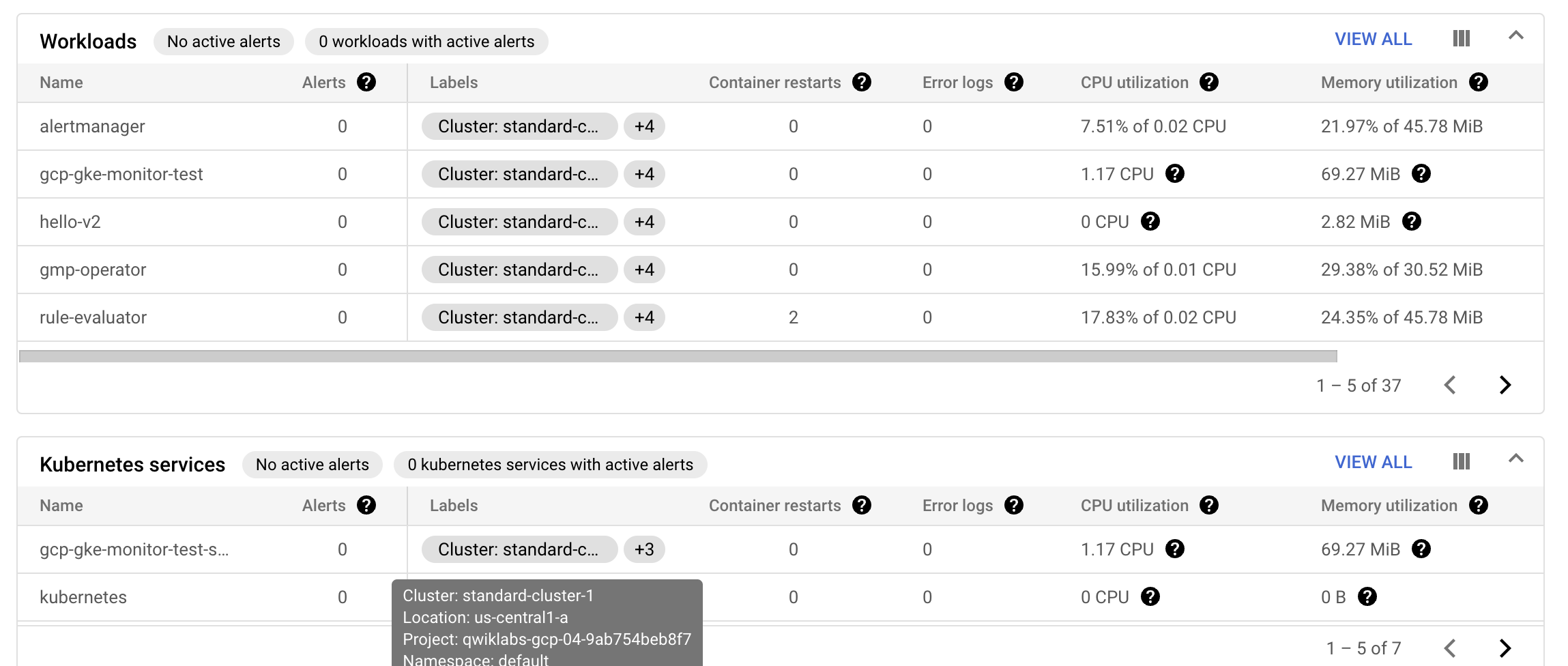
-
Kubernetes
서비스 섹션은 환경에 구성된 서비스를클러스터별로 구성한 다음네임스페이스(클러스터 내의 관리 장벽 또는 파티션)별로 구성하여 해당 네임스페이스 내에서 사용자가 사용할 수 있는 다양한 서비스를 보여준다.- 서비스 이름을 클릭하면 각 서비스에 대한 자세한 내용을 볼 수 있다.
-
네임 스페이스 섹션에는 클러스터 내의 네임스페이스 목록이 표시됨
모니터링 인터페이스는 배포 및 포드에 대한 더 자세한 정보를 제공할 수 있다.
-
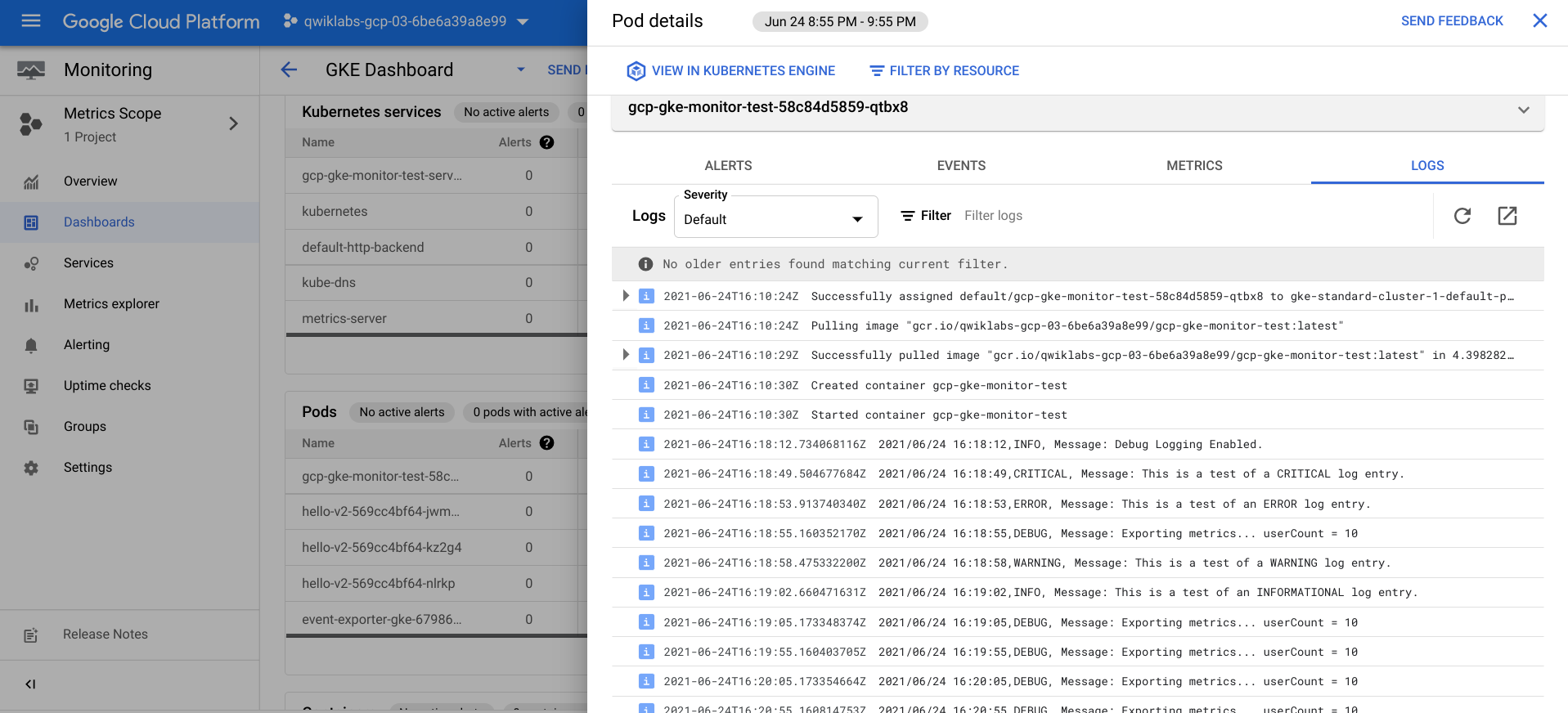
포드 섹션에서 fluentbit-gke-xxxx 로 시작하는 포드를 클릭한 다음 측정 View all 항목 탭을 클릭하여 더 많은 측정 항목을 확인- 팟(Pod)의 CPU 요청 사용률 값을 기록해 두고 이 숫자는 클러스터에서 원래 요청한 것과 관련하여 포드가 소비하는 CPU 리소스의 양을 나타낸다.
-
포드 세부 정보 창의 오른쪽 상단 모서리에 있는 ❎ 를 클릭하여 gcp-gke-monitor-test 로 시작하는 포드를 클릭하여 세부정보를 확인
- 포드 대신 네임스페이스를 선택한 경우 약간 다른 정보가 표시됨
-
Metrics 탭을 클릭하면CPU 요청 사용률및CPU 사용 시간과 같은 추가 메트릭을 볼 수 있음 -
포드 세부 정보 창에서로그 탭을 클릭하여 포드에 대한 로그 활동 탐색 가능- 이것은 포드가 생성한 로그 메시지와 시간 경과에 따른 포드의 로깅 활동을 나타내는 그래프를 보여주며 여기에서 도구에서 생성한 샘플 로그 중 일부를 볼 수 있다.
- 포드 세부 정보 창의 오른쪽 상단 모서리에 있는 ❎를 클릭하여 모니터링 인터페이스로 다시 돌아가자.
팟(Pod)을 모니터링하기 위한 커스텀 모니터링 대시보드 생성
Monitoring에서 커스텀 대시보드를 만들어 CPU 사용률, 컨테이너 다시 시작 등의 중요한 측정항목과 연결된 사용자 수에 대한 커스텀 측정항목을 표시할 수 있다.
- 모니터링 페이지 왼쪽의 탐색 모음에서 측정항목 탐색기를 클릭하여 대시보드 작성을 시작
-
메트릭 선택을 클릭
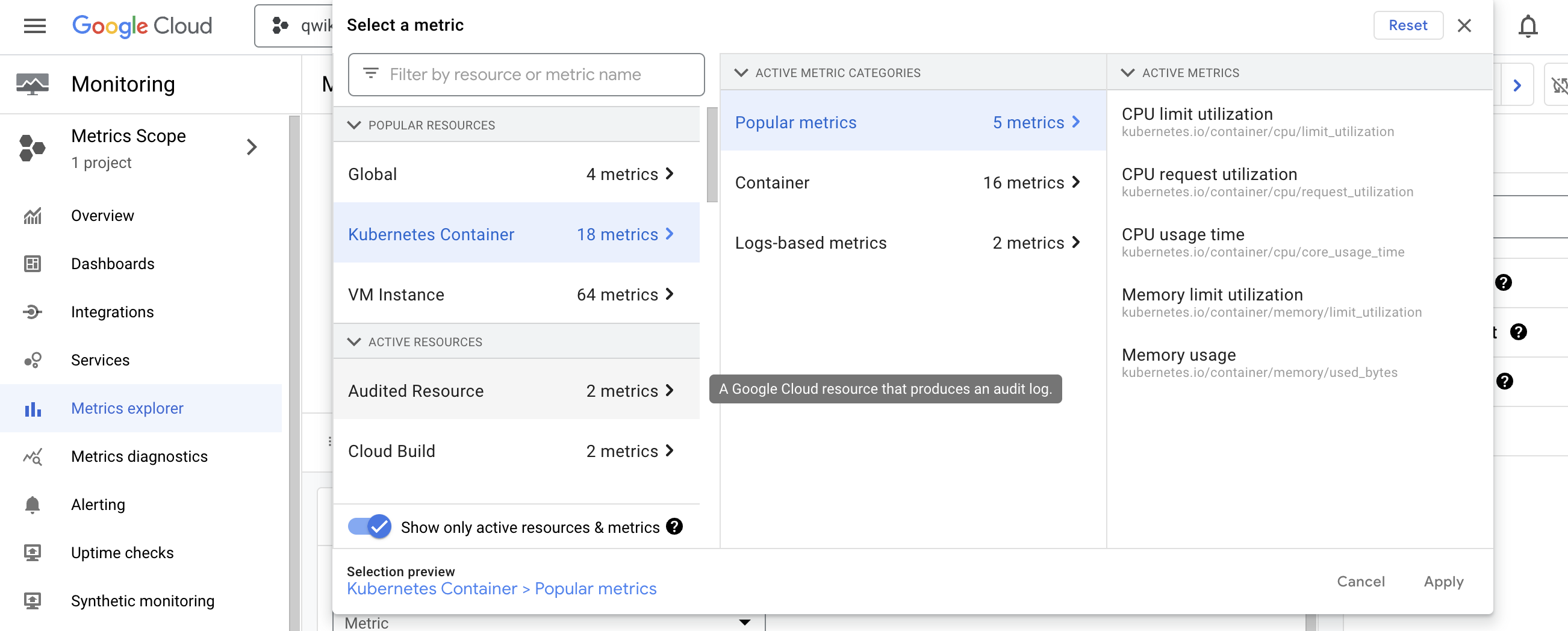
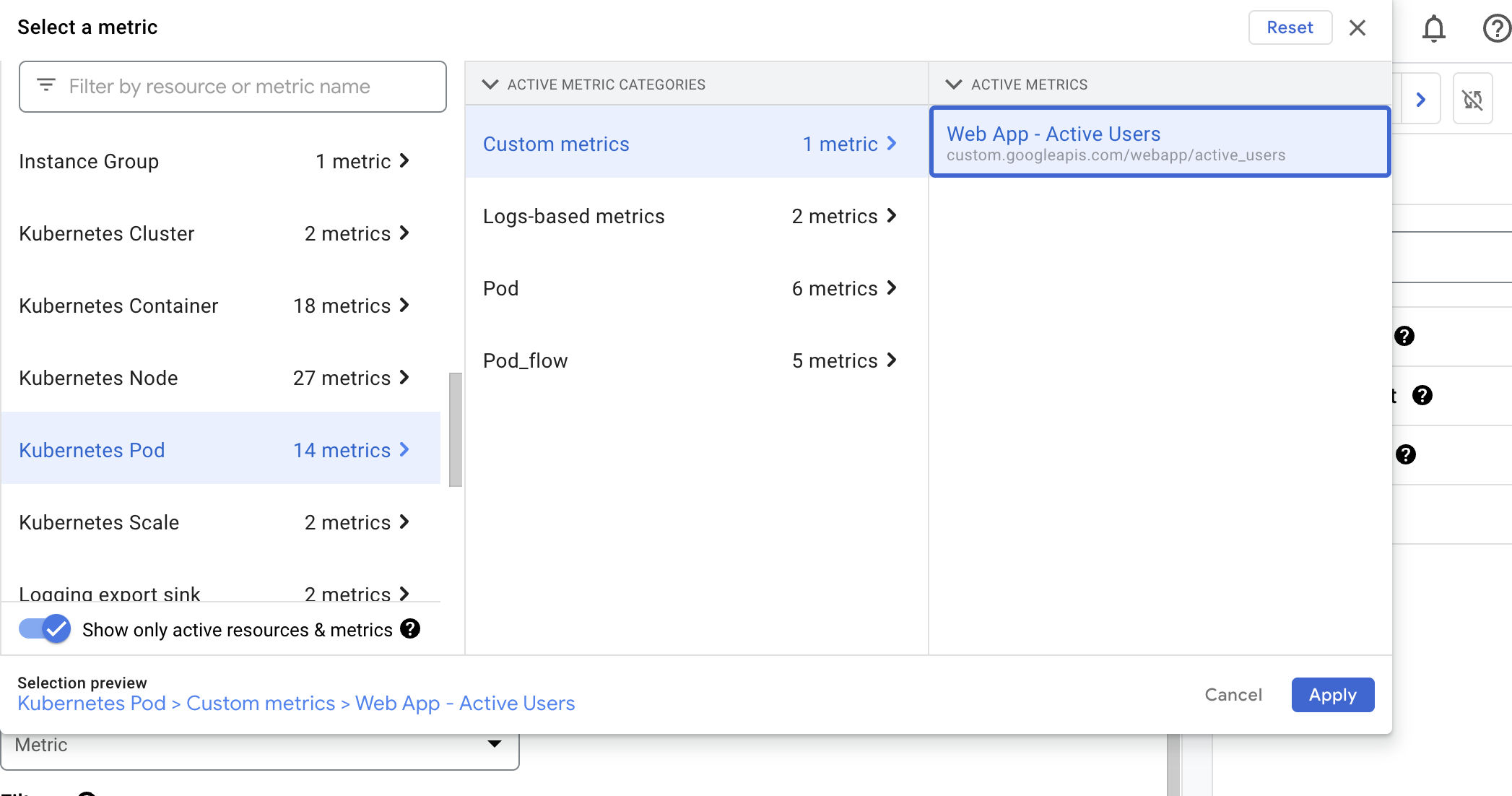
- 이렇게 하면 새로운 Kubernetes Engine Monitoring 도구에서 지원하는 리소스 유형으로 목록이 필터링된다.
-
Kubernetes 컨테이너 ➡️ Popular Metrics ➡️ CPU 요청 사용률을 선택 ➡️ 적용
-
이것은 이전에 fluentbit-gke-xxxx pod를 검사할 때 본 것과 동일한 CPU 요청 사용률 차트 이지만 이제 차트에는 모든 pod에 대한 측정항목이 표시된다.
-
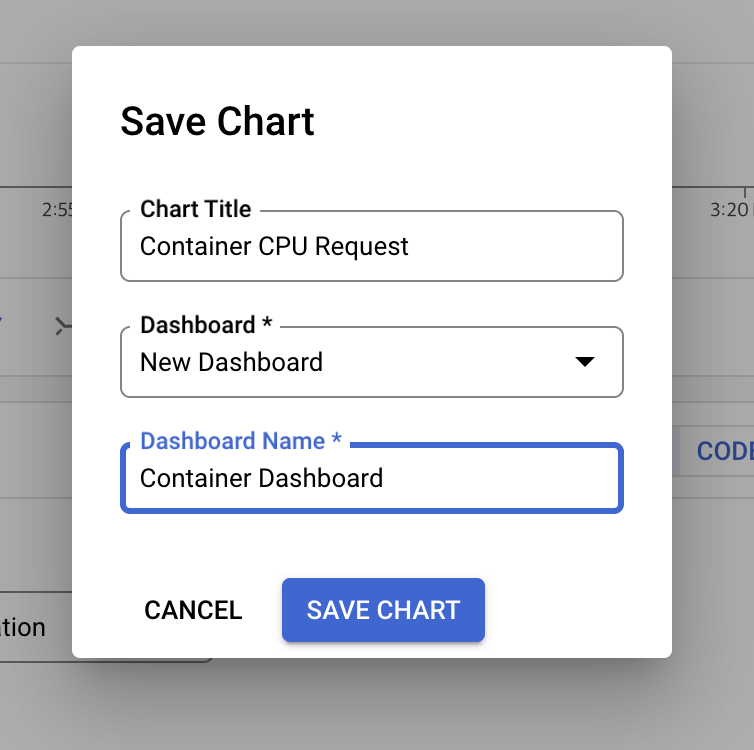
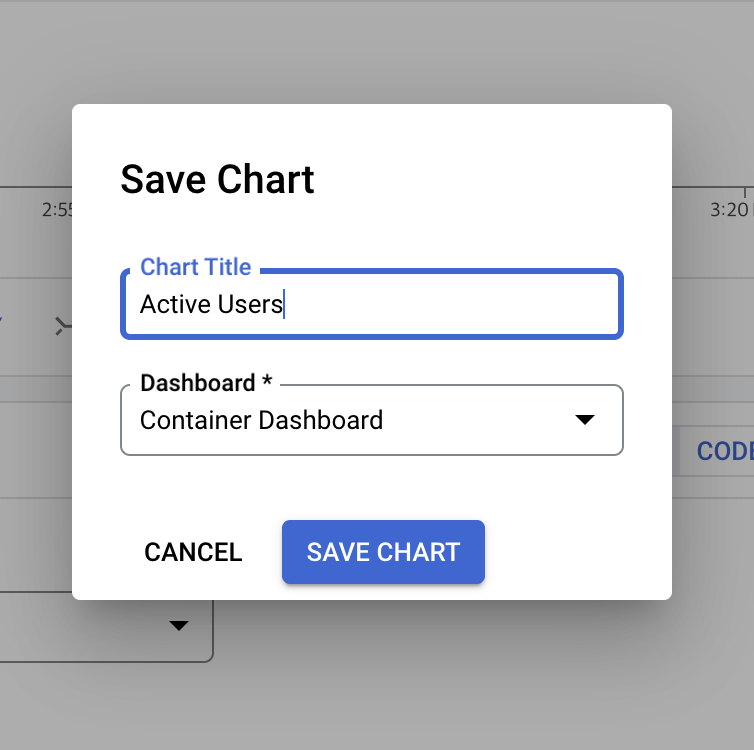
화면 오른쪽 상단에 있는 차트 저장 버튼을 클릭
-
차트에 Container CPU Request 와 같은 이름을 지정한 다음 Dashboard 를 클릭 ➡️ 새 대시보드 를 클릭 ➡️ 대시보드 이름을 Container Dashboard 로 지정 ➡️ 저장
- 이제 탐색 창에서 대시보드를 클릭한 다음 새 대시보드의 이름을 선택하여 대시보드를 시작할 수 있다.
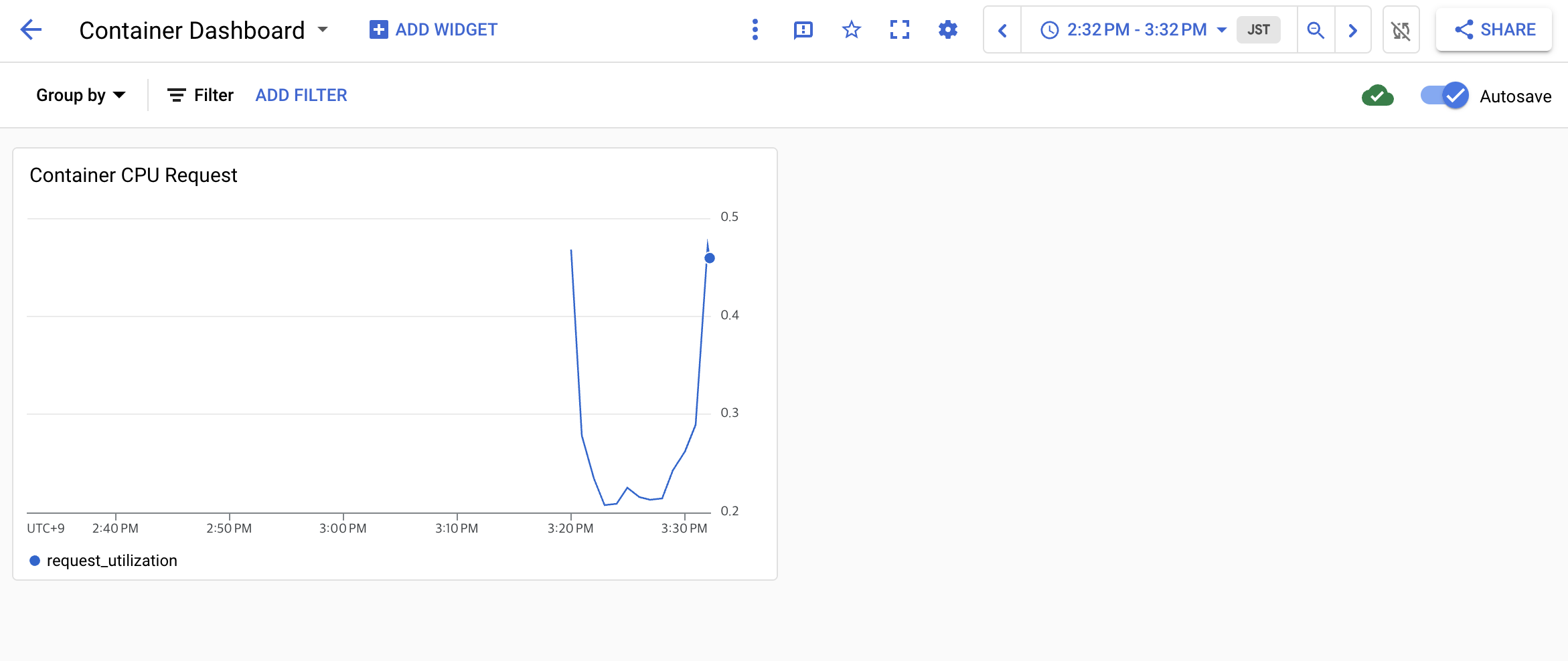
-
이제 표준 Monitoring 측정항목이 포함된 단일 차트를 표시하는 대시보드가 생겼고 다음으로 사용자 정의 모니터링 측정항목에 대한 차트를 만든 다음 이 대시보드에 추가한다.
-
측정항목 탐색기를 클릭 ➡️ 리소스 및 메트릭 상자를 클릭 ➡️ Kubernetes 포드 ➡️ 사용자 정의 ➡️ 웹 앱 - 활성 사용자를 선택 ➡️ 적용 ➡️ 차트 저장 클릭
-
새 차트에 Active Users 와 같은 이름을 지정
-
대시보드 드롭다운에서 컨테이너 대시보드를 선택 ➡️ 저장 클릭
-
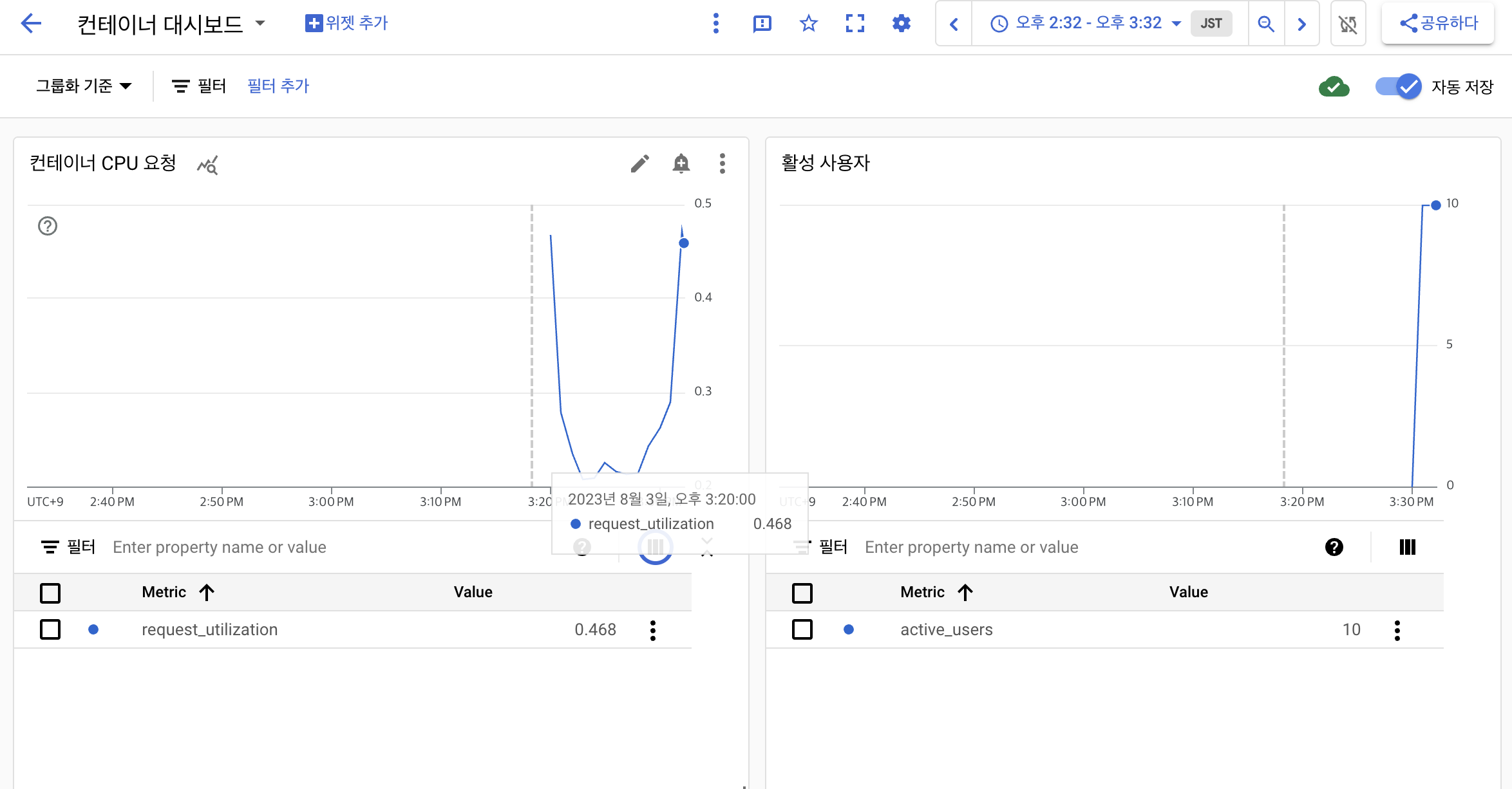
컨테이너 대시 보드로 돌아가 기어 아이콘 ⚙️을 클릭하여 설정 메뉴를 표시 ➡️ 모든 범례 표시를 클릭하여 각 차트 아래에 텍스트를 표시
-
각 차트의 오른쪽에 있는 값이라는 단어 옆에 있는 세 개의 세로 막대를 클릭
- 애플리케이션 서버에서 보낸 timeSeries 데이터에 포함된 다양한 레이블이 포함된 팝업이 표시되며 이 정보를 사용하여 차트의 데이터를 필터링하거나 집계할 수도 있다.
4-4. Kubernetes Engine Monitoring으로 알림 만들기
이제 Kubernetes Engine Monitoring 내에서 알림을 구성한 다음 대시보드를 사용하여 인시던트를 식별하고 대응해보자.
경고 정책 만들기
이제 컨테이너 간의 높은 CPU 사용률을 감지하는 경고 정책을 생성할 것이다.
-
Cloud Console의 탐색 메뉴 ➡️ 모니터링 ➡️ 알림을 선택 ➡️ + 정책 만들기 클릭
-
메트릭 선택 드롭다운을 클릭 ➡️ 활성 리소스 및 측정항목만 표시 비활성화.
-
리소스 및 메트릭 이름으로 필터에 Kubernetes 컨테이너를 입력
-
Kubernetes 컨테이너 ➡️ 컨테이너 클릭 ➡️ CPU 요청 사용률을 선택 ➡️ 적용
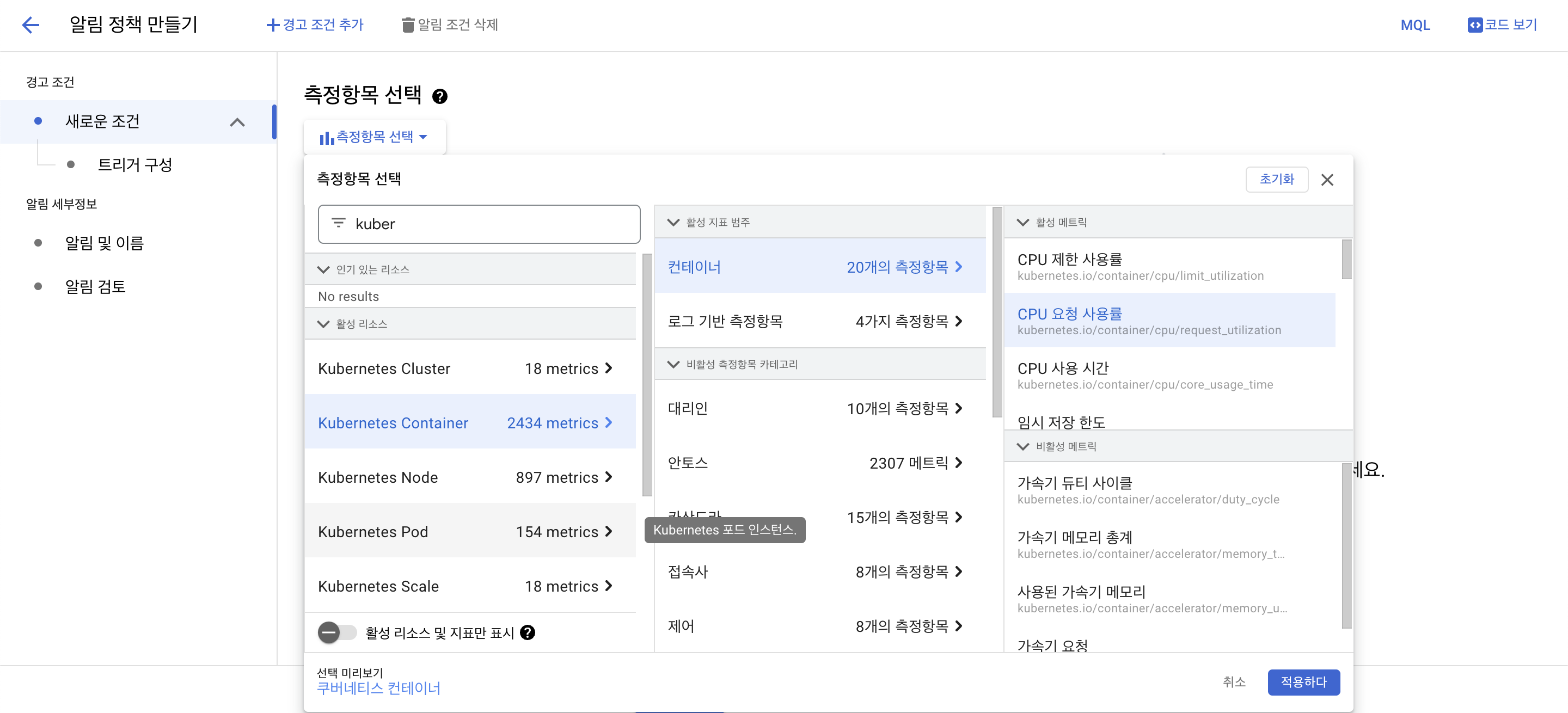
- 롤링 창을 1분으로 설정 ➡️ 다음 ➡️ 임계값 위치를 임계값 위 로 설정 ➡️ 임계값 으로 0.99를 설정 ➡️ 다음 클릭
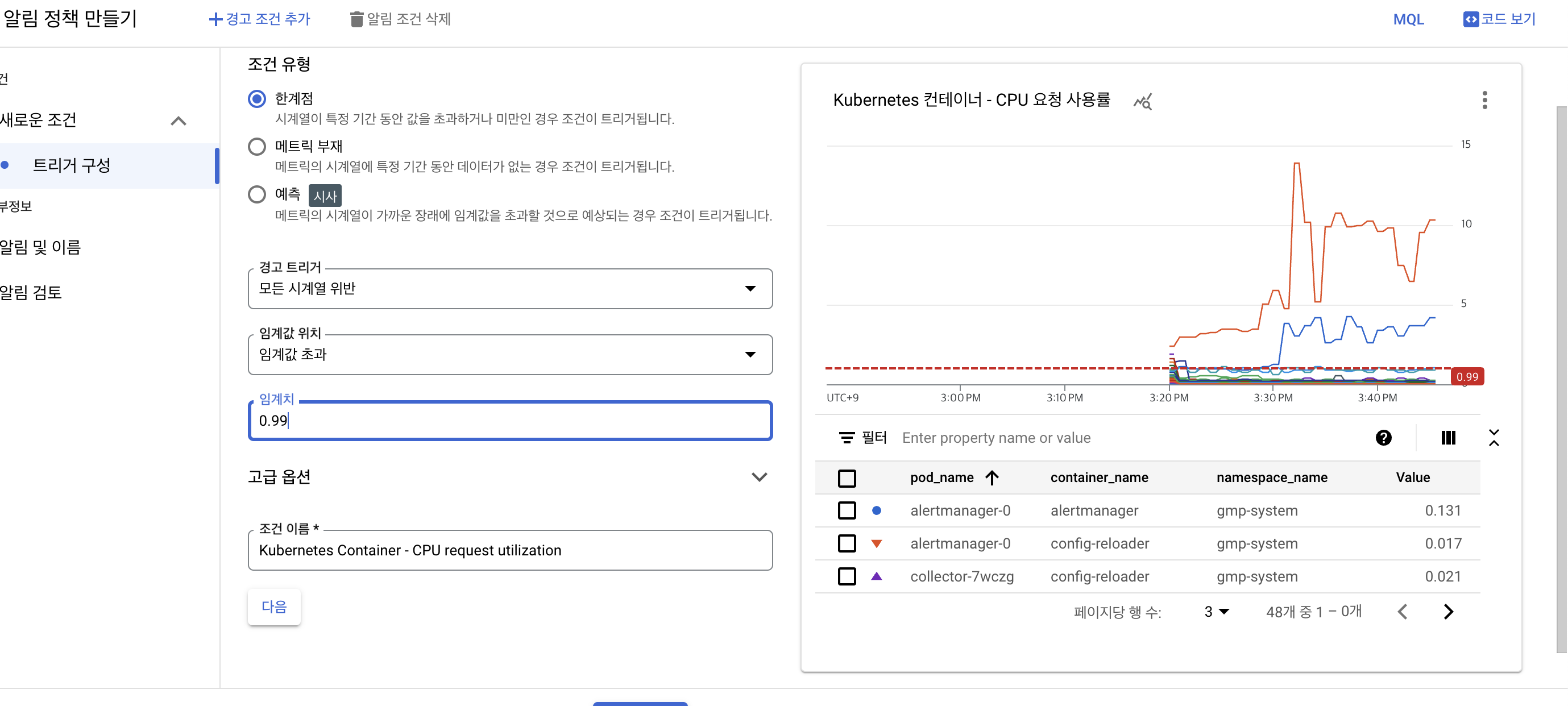
알림 구성 및 알림 정책 완료
- 알림 채널 옆에 있는 드롭다운 화살표를 클릭 ➡️ 알림 채널 관리 를 클릭 ➡️ 알림 채널 페이지가 새 탭에서 열림을 클릭
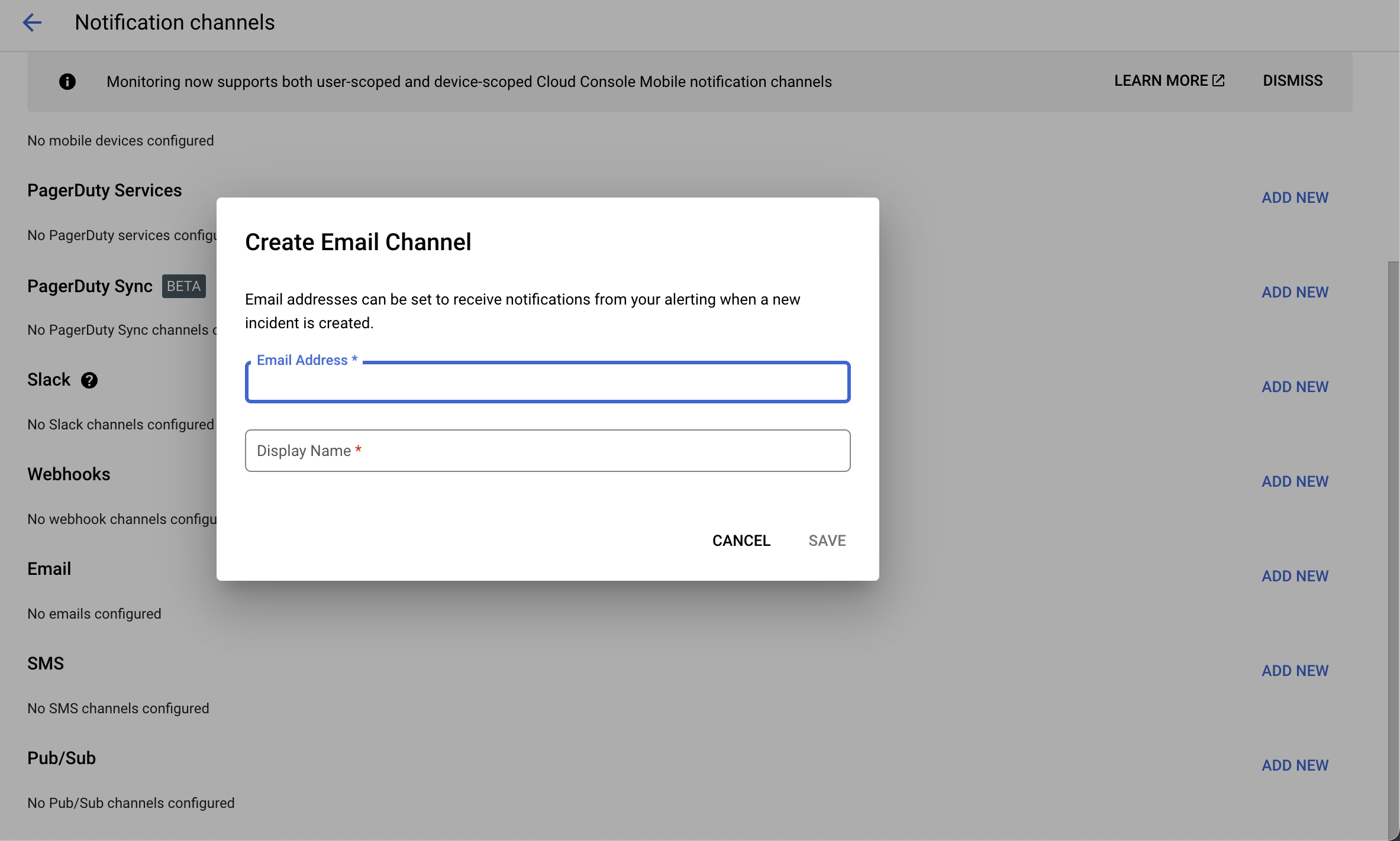
-
페이지를 아래로 스크롤하고 이메일용 새 항목 추가를 클릭 ➡️ 이메일 주소 필드 에 개인 이메일을 입력 하고 표시 이름을 입력 ➡️ 저장
-
이전에 알림 정책 만들기 탭으로 돌아가기
-
알림 채널을 다시 클릭 ➡️ 새로 고침 아이콘을 클릭 ➡️ 이전 단계에서 언급한 표시 이름 가져오기
- 필요한 경우 알림 채널을 다시 클릭
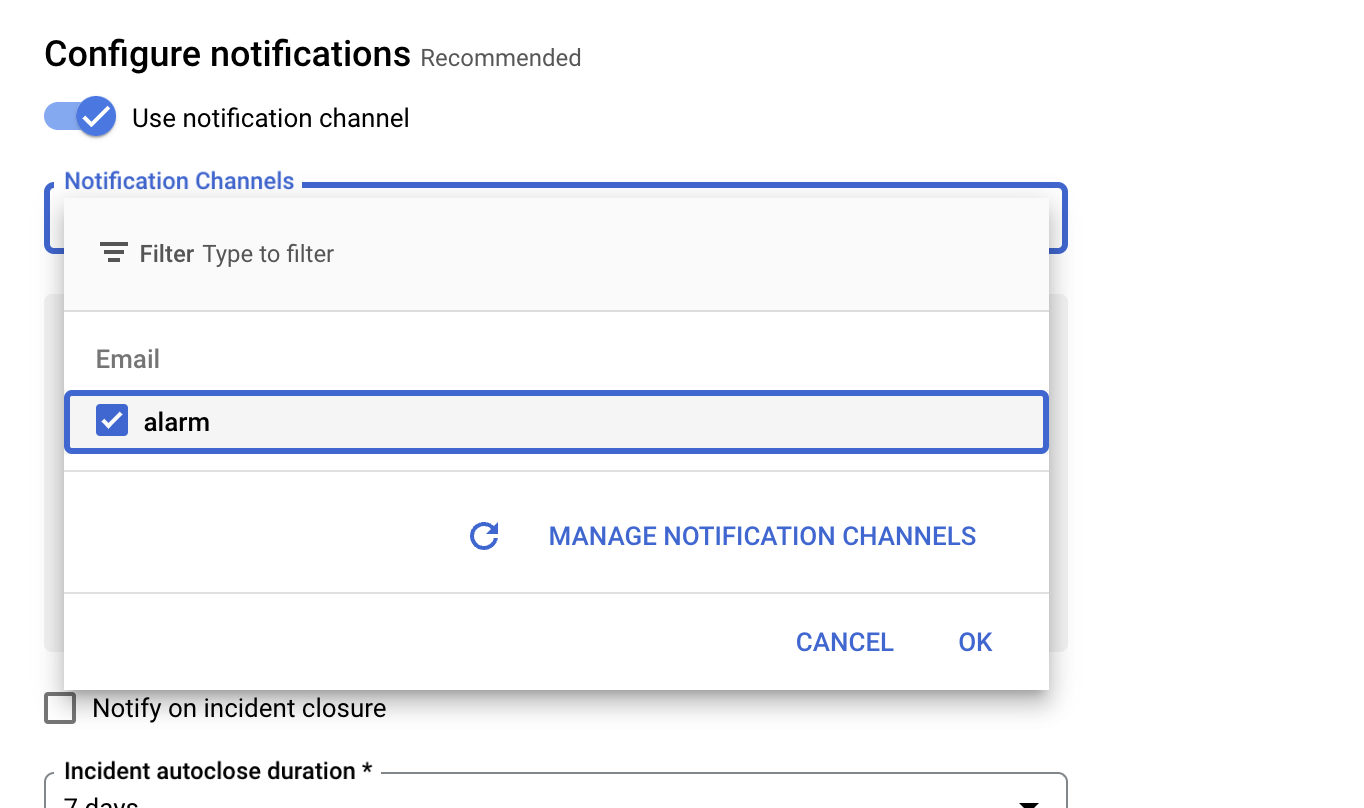
- 이제 표시 이름을 선택 ➡️ 확인 클릭 ➡️ 경고 이름을 지정 'CPU request utilization' ➡️ 다음 ➡️ 알림을 검토하고 정책 만들기를 클릭
인시던트에 대응
이제 컨테이너 중 하나에서 사고가 보고되는 모니터링 대시보드로 돌아가자.

- 모니터링 페이지에서 개요 ➡️ GKE를 선택하여 Kubernetes Engine Monitoring 대시보드에서 컨테이너에 보고된 인시던트를 볼 수 있다.
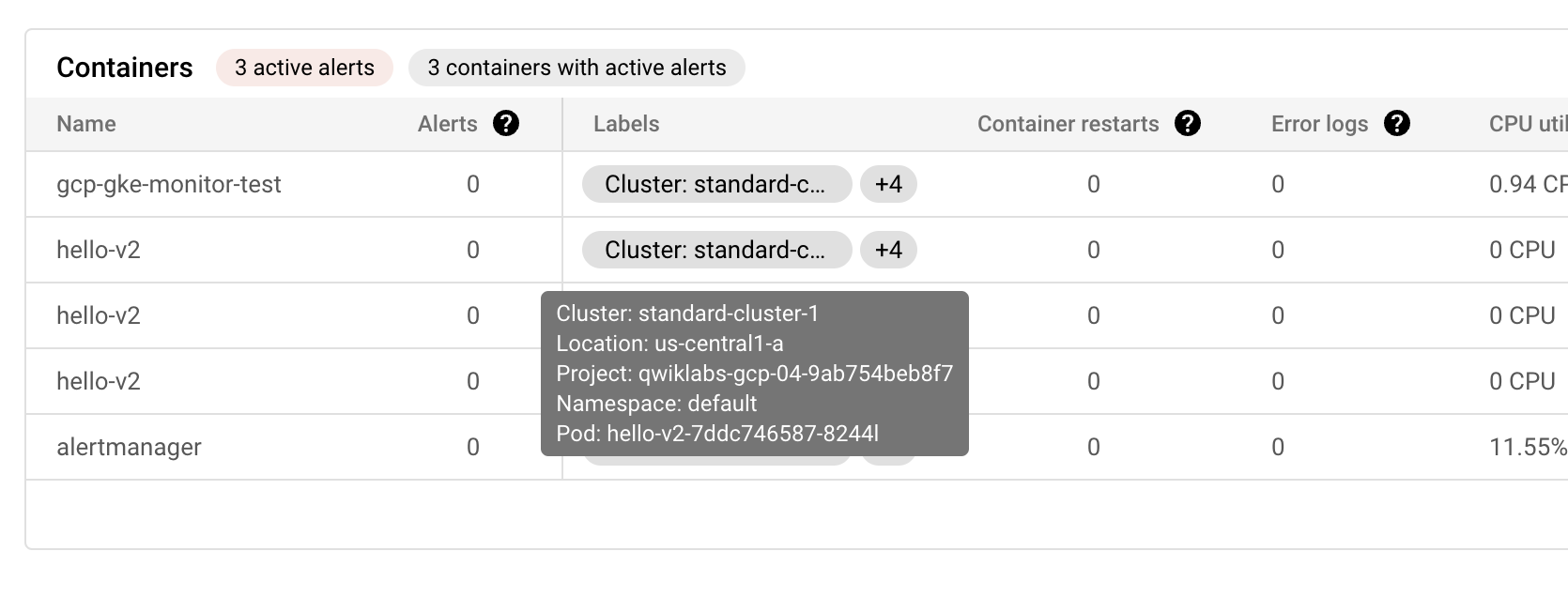
- 컨테이너 탭 에서 경고를 표시하는 컨테이너 이름을 클릭
- 경고를 등록하는 데 1~2분이 소요되며 경고를 보려면 페이지를 새로 고쳐야 할 수 있다.
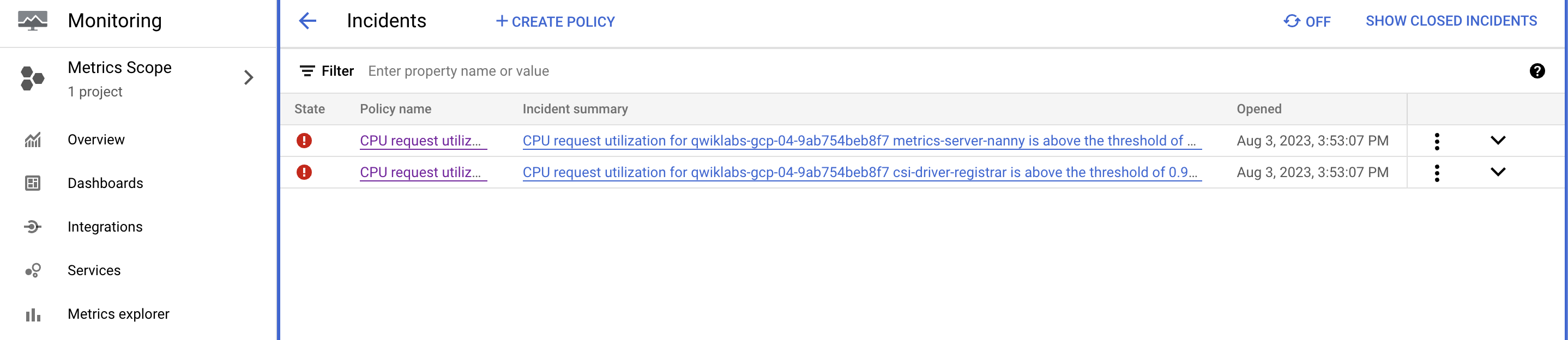
- 알림 페이지 로 이동
- 추가 세부 정보를 보려면 경고 이름 CPU 요청 사용률을 클릭
- 인시던트를 열고 인시던트 요약 항목을 클릭 ➡️ 인시던트 확인을 클릭
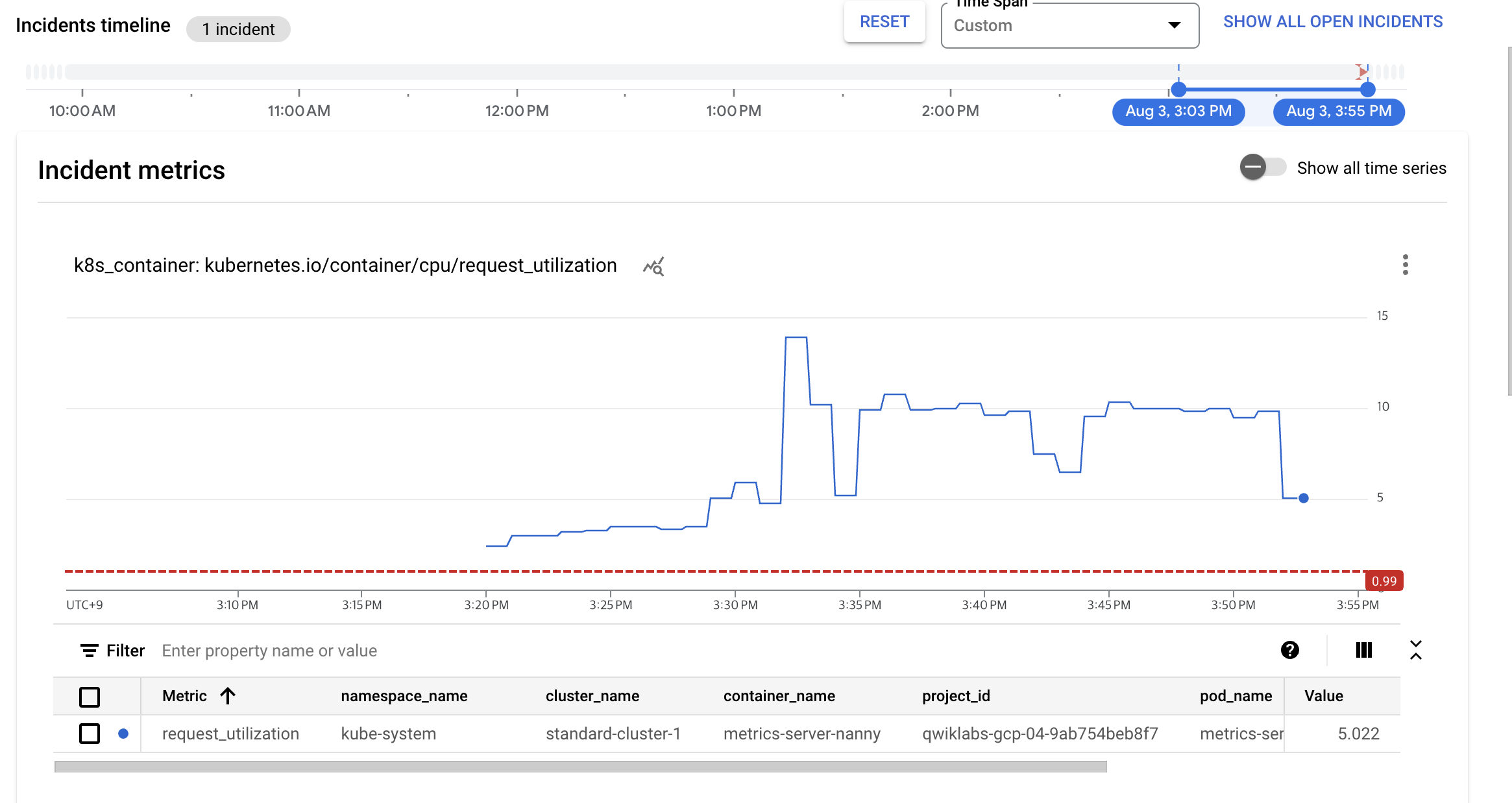
- 이제 인시던트 상태가 Acknowledged로 표시되지만 문제가 해결되지는 않는다.
- 문제의 근본 원인(CPU 부하 생성기 컨테이너)을 수정해야 한다.
- GCP-GKE-Monitor-Test 도구의 웹 인터페이스를 열어 Generate CPU Load 섹션 에서 Stop CPU Load 버튼을 클릭하여 CPU Load Generator를 중지하여 문제를 해결
5. Probes
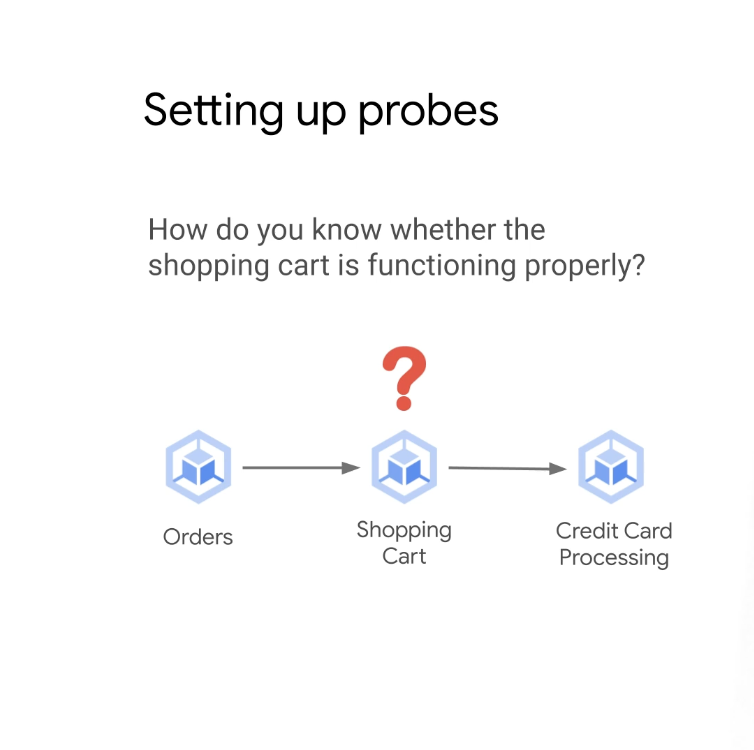
마이크로서비스 환경에서 작업할 때는 서비스 종속성을 고려해야하는데 왜냐하면 서비스가 준비되지 않은 경우 다른 서비스에서 오류가 발생할 수 있기 때문이다.
또한, 일부 컨테이너는 컴퓨팅 리소스를 사용하기 때문에 작동하는 것처럼 보일 수 있지만 실제로는 클라이언트 요청을 처리할 수 없다.
이 두 경우 모두에서 다른 마이크로서비스는 우리가 방지할 수 있는 오류를 생성하는데 포드의 상태를 확인하고 응답하지 않는 것으로 확인되면 재배포한다.
위의 예에서 쇼핑 프로세스는 주문, 장바구니 및 신용 카드 처리와 같은 다양한 마이크로 서비스로 분류된다.
주문이 장바구니에 적절하게 저장되는 것이 중요하고 주문이 장바구니에 올바르게 저장되지 않으면 신용 카드가 올바르게 처리되지 않으며 이는 결국 전환 손실과 수익 손실로 이어질 수 있다.
전반적으로 기능적인 쇼핑 장바구니 마이크로서비스가 있어야 하고, 그렇다면 장바구니가 제대로 작동하는지(헬스체크) 어떻게 알 수 있을까??
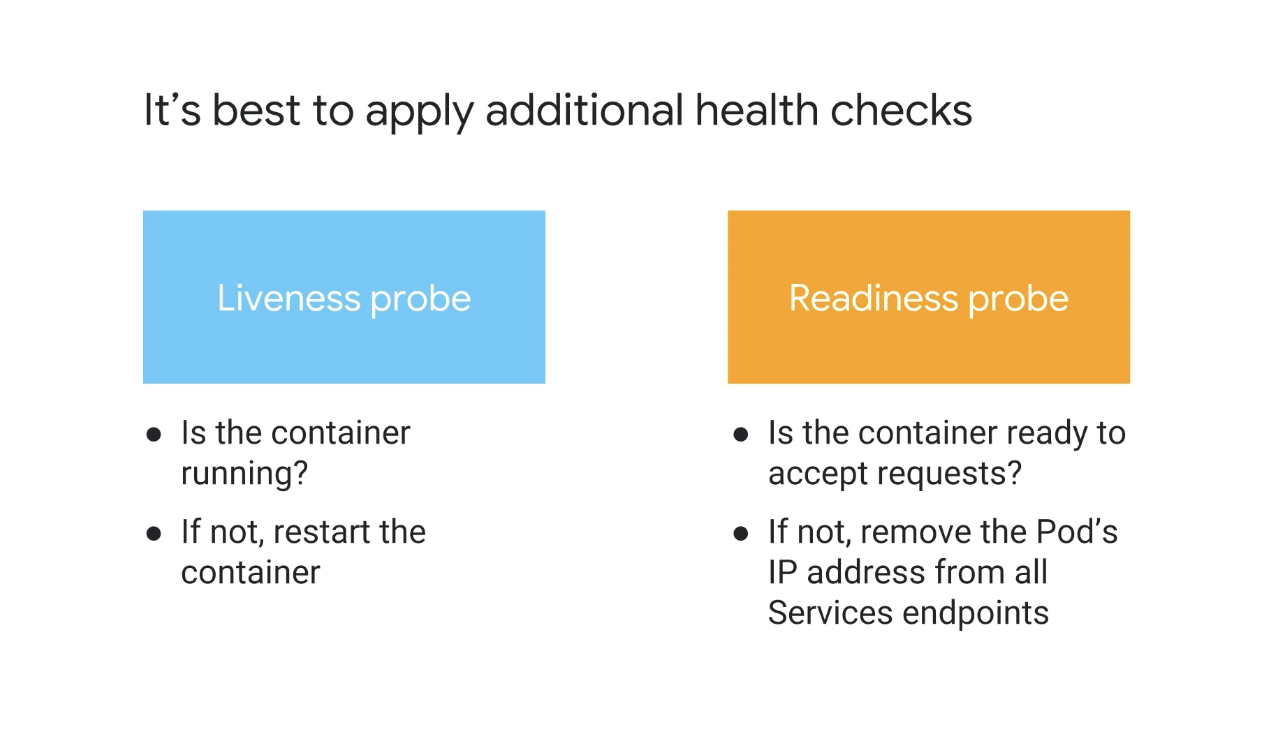
➡️ 활성 및 준비 프로브와 같은 추가 상태 확인을 적용하는 것이 가장 좋다!
활동성 프로브를 사용하여 Kubernetes는 컨테이너가 실행 중인지 확인하고 활동성 프로브가 실패하고 restartPolicy가 Always 또는 OnFailure로 설정된 경우 kubelet은 컨테이너를 다시 시작한다.
Kubernetes는 준비 프로브를 사용하여 컨테이너가 요청을 수락할 준비가 되었는지 확인한다.
준비 프로브가 실패하면 엔드포인트 컨트롤러에 의해 포드의 IP 주소가 모든 서비스 엔드포인트에서 제거된다.
이러한 프로브는 세 가지 유형의 핸들러(명령, HTTP 및 TCP)를 사용하여 정의할 수 있으므로 다양한 유형의 진단 프로브 테스트를 수행할 수 있다.
➡️ 그렇다면, 활동성 또는 준비성 프로브를 사용해야 하는지 여부를 어떻게 결정할까?

컨테이너가 자체적으로 실패할 수 있고 restartPolicy가 Always 또는 OnFailure로 설정된 경우에는 필요하지 않다.
kubelet은 단순히 정의된 restartPolicy에 따라 작동하고 컨테이너를 다시 시작하지만 컨테이너 내의 애플리케이션이 중단된 상태로 멈춰 있고 다시 시작하면 중단된 상태를 감지하고 컨테이너를 다시 시작하도록 활동성 프로브를 설정할 수 있다.
프로브가 도움이 될 수 있는 세 번째 경우는 컨테이너가 실행 중일 수 있지만 애플리케이션이 아직 트래픽을 처리할 준비가 되지 않은 경우이다.
기본적으로 Kubernetes는 컨테이너가 실행 중이기 때문에 트래픽을 컨테이너로 보내는데 활동성 프로브를 설정한 경우에도 활동성 프로브는 단순히 실패하고 컨테이너를 다시 시작하고 이는 응용 프로그램이 트래픽을 수신할 준비가 된 상태에 도달하지 못하는 연속 루프로 끝난다.
이 경우 준비 프로브를 추가하여 트래픽이 전송되기 전에 애플리케이션이 준비되고 실행 중인지 확인할 수 있다.
이러한 프로브를 지정하지 않으면 기본적으로 Kubernetes는 포드가 성공적으로 실행되었다고 가정한다.
1. Command Probe Handler

명령 프로브 핸들러를 사용하여 kubelet은 컨테이너 내에서 명령을 실행하고 명령이 성공하면 즉, 종료 코드가 0이면 컨테이너가 건강한 것으로 간주되고, 그렇지 않으면 kubelet이 컨테이너를 종료한다.
2. HTTP Probe Handler

요청이 200에서 400 사이의 코드 범위로 반환되면 kubelet은 컨테이너가 정상인 것으로 간주하고 이 범위를 벗어나면 컨테이너가 죽는다.
이 프로브를 사용하기 위해 컨테이너에서 경량 HTTP 서버를 쉽게 설정할 수 있다.
3. TCP Probe Handler

kubelet은 TCP 연결을 시도하며 연결이 설정되면 컨테이너가 건강한 것으로 간주된다.
이러한 모든 방법은 정확히 동일한 방식으로 준비 프로브에서 사용할 수 있다.

이러한 프로브를 세분화할 수도 있는데 initialDelaySeconds 필드는 활성 또는 준비 상태 프로브를 시작할 수 있기 전에 대기하는 시간(초)을 설정한다.
애플리케이션이 준비되기 전에 프로브가 시작되지 않도록 하는 것이 중요하며 그렇지 않으면 컨테이너가 연속 루프에서 스래싱된다.
애플리케이션 부팅 시간이 변경되면 이 값을 업데이트해야 하고 periodSeconds 필드는 프로브 테스트 간의 간격을 정의하고 timeoutSeconds 필드는 프로브 시간 제한을 정의하며 성공 및 실패 임계값 필드도 설정할 수 있다.
6. 활성 및 준비 프로브 구성 실습
컨테이너에 대한 Kubernetes 활성 및 준비 상태 프로브를 구성하고 테스트 해볼 것이다.
6-1. 클러스터 연결
export my_zone=us-central1-a
export my_cluster=standard-cluster-1
source <(kubectl completion bash)
gcloud container clusters get-credentials $my_cluster --zone $my_zone
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
ln -s ~/training-data-analyst/courses/ak8s/v1.1 ~/ak8s
cd ~/ak8s/Probes/6-2. 활동성 프로브 구성
이 작업에서는 활성 상태 프로브를 배포하여 실행 중인 상태에서 중단된 상태로 전환된 애플리케이션을 감지한다.
그런데, 경우에 따라 애플리케이션이 일시적으로 트래픽을 처리할 수 없다.
예를 들어 응용 프로그램은 시작하는 동안 대용량 데이터 또는 구성 파일을 로드해야 할 수 있다.
이러한 경우 애플리케이션을 종료하고 싶지는 않지만 애플리케이션에 요청을 보내고 싶지도 않을 것이다.
Kubernetes는 이러한 상황을 감지하고 완화하기 위한 준비 프로브를 제공하는데 컨테이너가 준비되지 않았다고 보고하는 포드는 Kubernetes 서비스를 통해 트래픽을 수신하지 않는다.
준비 프로브는 활성 프로브와 유사하게 구성되며 유일한 차이점은 livenessProbe 필드 대신 readinessProbe 필드를 사용한다는 점에 차이가 있다.
Busybox를 실행하는 간단한 컨테이너 liveness와 컨테이너 내의 파일 /tmp/healthy에 대해 cat 명령을 사용하여 5초마다 활성을 테스트하는 활성 프로브를 정의하는 포드 정의 파일exec-liveness.yaml이 있다.
시작 스크립트는 시작 시 /tmp/healthy 파일을 생성한 다음 30초 후에 삭제하여 Liveness 프로브가 감지할 수 있는 중단을 시뮬레이션한다.
cat exec-liveness.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
kubectl create -f exec-liveness.yaml30초 이내, 35초 이후에 Pod 이벤트를 주시해보자
$ kubectl describe pod liveness-exec
Type: Secret (a volume populated by a Secret)
SecretName: default-token-wq52t
Optional: false
QoS Class: Burstable
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age ... Message
---- ------ ---- ... -------
Normal Scheduled 11s ... Successfully assigned liveness-e ...
Normal Su...ntVolume 10s ... MountVolume.SetUp succeeded for ...
Normal Pulling 10s ... pulling image "k8s.gcr.io/busybox"
Normal Pulled 9s ... Successfully pulled image "k8s.g ...
Normal Created 9s ... Created container
Normal Started 9s ... Started container
## 35 seconds after
$ kubectl describe pod liveness-exec
Type: Secret (a volume populated by a Secret)
SecretName: default-token-wq52t
Optional: false
QoS Class: Burstable
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age ... Message
---- ------ ---- ... -------
Normal Scheduled 2m ... Successfully assigned liveness-e ...
Normal Su...ntVolume 2m ... MountVolume.SetUp succeeded for ...
Normal Pulling 49s ... pulling image "k8s.gcr.io/busybox"
Normal Pulled 49s ... Successfully pulled image "k8s.g ...
Normal Created 49s ... Created container
Normal Started 49s ... Started container
Normal Killing 49s ... Killing container with
id docker://liveness:Container failed liveness probe..
Container will be killed and recreated.
Warning Unhealthy 5s ... Liveness probe failed:
cat: can't open '/tmp/healthy': No such file or directory60초 더 기다린 후 컨테이너가 다시 시작되었는지 확인
- 출력은 활성 프로브에서 감지한 실패에 대한 응답으로 RESTARTS가 증가했음을 보여준다.
$ kubectl describe pod liveness-exec
Name: liveness-exec
Namespace: default
Priority: 0
Service Account: default
Node: gke-standard-cluster-standard-cluster-9bf83ab7-c7wm/10.10.0.5
Start Time: Thu, 03 Aug 2023 08:33:30 +0000
Labels: test=liveness
Annotations: <none>
Status: Running
IP: 10.12.2.3
IPs:
IP: 10.12.2.3
Containers:
liveness:
Container ID: containerd://b3ad87cadbe90f06ab8976bde081ba5c24c17df055401f734f8a405f87660742
Image: k8s.gcr.io/busybox
Image ID: sha256:36a4dca0fe6fb2a5133dc11a6c8907a97aea122613fa3e98be033959a0821a1f
Port: <none>
Host Port: <none>
Args:
/bin/sh
-c
touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
State: Running
Started: Thu, 03 Aug 2023 08:34:46 +0000
Last State: Terminated
Reason: Error
Exit Code: 137
Started: Thu, 03 Aug 2023 08:33:31 +0000
Finished: Thu, 03 Aug 2023 08:34:46 +0000
Ready: True
Restart Count: 1
Liveness: exec [cat /tmp/healthy] delay=5s timeout=1s period=5s #success=1 #failure=3
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-fm8w4 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-fm8w4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 85s default-scheduler Successfully assigned default/liveness-exec to gke-standard-cluster-standard-cluster-9bf83ab7-c7wm
Normal Pulled 84s kubelet Successfully pulled image "k8s.gcr.io/busybox" in 403.83171ms (403.849866ms including waiting)
Warning Unhealthy 40s (x3 over 50s) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 40s kubelet Container liveness failed liveness probe, will be restarted
Normal Pulling 9s (x2 over 84s) kubelet Pulling image "k8s.gcr.io/busybox"
Normal Created 9s (x2 over 84s) kubelet Created container liveness
Normal Started 9s (x2 over 84s) kubelet Started container liveness
Normal Pulled 9s kubelet Successfully pulled image "k8s.gcr.io/busybox" in 183.849945ms (183.868414ms including waiting)
$ kubectl get pod liveness-exec
NAME READY STATUS RESTARTS AGE
liveness -exec 1 / 1 Running 2 4 m6-3. 준비 프로브 구성
팟(Pod)이 성공적으로 시작되고 활동성 프로브에 의해 정상으로 간주될 수 있지만 트래픽을 즉시 수신할 준비가 되지 않았을 수 있다.
이는 로드 밸런서와 같은 서비스에 대한 백엔드 역할을 하는 배포에서 일반적이다.
준비 프로브는 팟 (Pod)과 해당 컨테이너가 트래픽 수신을 시작할 준비가 된 시기를 판별하는 데 사용된다.
준비 프로브는 특정 컨테이너가 준비된 것으로 간주되는지 여부를 제어하며 서비스에서 이를 사용하여 컨테이너가 트래픽을 보낼 수 있는 시기를 결정한다.
이 작업에서는 로드 밸런서와 함께 테스트 웹 서버 역할을 할 단일 포드를 생성하는 포드 정의 파일(readiness-deployment.yaml)이 있다.
컨테이너에는 5초마다 준비 상태를 테스트하기 위해 컨테이너 내의 파일(/tmp/healthz)에 대해 cat명령을 사용하는 정의된 준비 프로브가 있다.
또한, 각 컨테이너에는 컨테이너 내의 동일한 파일에 대해 cat 명령을 사용하여 5초마다 준비 상태를 테스트하는 활성 프로브가 정의되어 있지만 시간이 걸리는 복잡한 시작 프로세스가 있을 수 있는 애플리케이션을 시뮬레이션하기 위해 45초의 시작 지연을 둘 것이다.
컨테이너가 시작된 후 안정화된다.
서비스가 트래픽 처리를 시작하면 이 패턴은 서비스가 트래픽을 처리할 준비가 된 컨테이너에만 트래픽을 전달하도록 한다.
$ cat readiness-deployment.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
demo: readiness-probe
name: readiness-demo-pod
spec:
containers:
- name: readiness-demo-pod
image: nginx
ports:
- containerPort: 80
readinessProbe:
exec:
command:
- cat
- /tmp/healthz
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: readiness-demo-svc
labels:
demo: readiness-probe
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
demo: readiness-probe
$ kubectl create -f readiness-deployment.yaml
# 로드 밸런서 서비스의 상태를 확인
$ kubectl get service readiness-demo-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
readiness-demo-svc LoadBalancer 10.15.255.135 <pending> 80:30878/TCP 13s
# 출력은 준비 프로브가 실패했음을 나타낼 것이다.
$ kubectl describe pod readiness-demo-pod
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m24s default-scheduler Successfully assigned default/readiness-demo-pod to gke-load-test-default-pool-abd43157-rgg0
Normal Pulling 2m23s kubelet Pulling image "nginx"
Normal Pulled 2m23s kubelet Successfully pulled image "nginx"
Normal Created 2m23s kubelet Created container readiness-demo-pod
Normal Started 2m23s kubelet Started container readiness-demo-pod
Warning Unhealthy 35s (x21 over 2m15s) kubelet Readiness probe failed: cat: /tmp/healthz: No such file or directory활동성 프로브와 달리 비정상 준비 프로브는 Pod를 다시 시작하도록 트리거하지않는다.
상태 프로브가 확인하는 파일을 생성
$ kubectl exec readiness-demo-pod -- touch /tmp/healthz
$ kubectl describe pod readiness-demo-pod | grep ^Conditions -A 5
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
로드밸런서에 접속하여 welcome to nginx 메시지를 확인!
활성 및 준비 상태 프로브의 동작 모니터링
이제 디플로이먼트에 있는 포드의 준비 상태가 서비스에 대해 활성으로 활성화된 엔드포인트에 어떻게 해당하는지 확인할 수 있다.
포드가 준비 및 활성 프로브 테스트에 실패하면 준비되지 않은 것으로 표시되고 해당 엔드포인트가 서비스에서 제거되며 활성 프로브가 다시 시작 프로세스를 시작하여 실패한 포드를 복구한다.
다시 시작된 포드는 즉시 준비 상태로 표시되지 않으며 서비스가 엔드포인트를 풀에 다시 추가하기 전에 준비 테스트가 통과할 때까지 기다려야 한다.
kubectl get pods명령어를 통해 Pod 상태를 다시 확인해보자.
이제 개별 포드가 준비됨으로 표시되는 것을 볼 수 있는데 타이밍에 따라 이들 중 하나 이상이 다시 시작될 수 있지만 다시 시작하는 데 2~3분이 소요된다.
준비됨으로 나열된 포드에는 서비스와 연결된 해당 엔드포인트가 있어야 한다.
애플리케이션에 연결할 수 있는지 확인하려면 먼저 로드 밸런서 서비스 세부 정보에서 외부 IP 주소를 쿼리하고 환경 변수에 저장하자
$ export EXTERNAL_IP=$(kubectl get services readiness-demo-svc -o json | jq -r '.status.loadBalancer.ingress[0].ip')
# 응답하는지 확인
$ curl $EXTERNAL_IP몇 분 동안 curl $EXTERNAL_IP명령을 10초 정도마다 반복하여 배포 상태를 확인하고 로드 밸런서에 요청을 보내보자.
$ curl $EXTERNAL_IP
$ kubectl get pods활성 프로브에서 감지한 실패로 인해 개별 컨테이너가 정기적으로 다시 시작되는 경우에도 실패 또는 시간 초과 없이 응답이 계속 표시되어야 한다.
3개의 컨테이너가 모두 거의 동시에 다시 시작되면 여전히 시간 초과가 표시될 수 있지만 거의 발생하지 않는다.
활성 및 준비 프로브의 조합은 서비스가 응답할 수 있는 것으로 알려진 컨테이너에만 트래픽을 전달하는 동안 장애가 발생한 시스템을 안전하게 다시 시작하도록 하는 방법을 제공한다는 결론을 얻을 수 있다.

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.