
1. Google Cloud 서비스 사용(애플리케이션에 집중하고 싶을 때)
GCP 관리 스토리지 서비스와 자체 관리 컨테이너 스토리지를 사용할 때의 장단점에 대해 알아볼텐데 Google Kubernetes Engine에서 실행되는 애플리케이션을 위한 여러 스토리지 옵션이 있다.
이것들은 서로 다른 절충안을 만들고 우리의 응용 프로그램에 적합한 것을 선택할 수 있다.

Kubernetes는 클러스터의 애플리케이션에 스토리지를 제공하는 데 사용할 수 있는 스토리지 추상화, 볼륨 및 영구 볼륨을 제공하는데 이것을 대체할 수 있는 GCP 관리 스토리지 솔루션에 대해 알아보자.
볼륨 및 영구 볼륨은 애플리케이션에서 직접 액세스할 수 있는 파일 시스템 용량을 제공한다는 점은 알고있고, 이를 내구성 있는 파일 저장소로 사용하거나 데이터베이스의 백업 저장소 또는 직접 배포하고 관리하는 기타 저장소 서비스로 사용할 수 있다.
GKE에서는 일반적으로 Compute Engine Persistent Disk가 이것을 지원하지만, 이러한 Kubernetes 스토리지 추상화를 사용하는 경우 이를 사용하여 구축하는 스토리지 서비스를 관리해야 하는 작업이 있다.
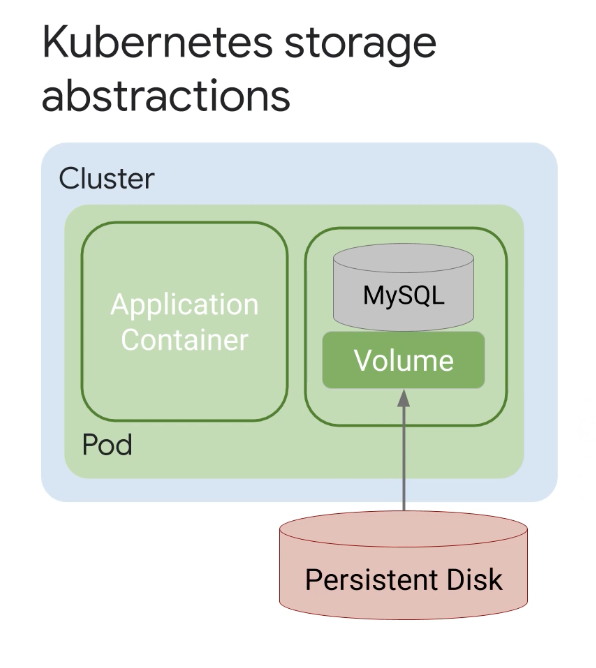
예를 들어 데이터베이스 파일을 저장하기 위해 영구 디스크를 기반으로 하는 Kubernetes 볼륨을 사용하여 직접 MySQL 서버를 컨테이너로 구축하고 배포할 수 있지만, 서버 응용 프로그램 수명 주기를 직접 관리해야 하는 수고스러움이 있다.
레이블이 지정된 서비스에서 복원력을 구축하는 것은 전적으로 나의 책임이다.
애플리케이션에 대한 스토리지 서비스를 유지 관리하는 것보다 애플리케이션에 집중하고 싶을 수 있을텐데 Google Cloud의 완전 관리형 데이터베이스 및 스토리지 서비스는 모든 종류의 데이터를 저장하는 데 드는 작업을 줄여주고 GCP의 관계형 및 비관계형 데이터베이스와 객체 스토리지 서비스는 운영 관리 부담을 줄이는 데 도움이 될 수 있다.
2. API 사용
GKE 관리 Kubernetes 클러스터 내에서 이러한 GCP 관리 스토리지 서비스를 사용하려면 컨테이너화된 애플리케이션이 Google Cloud Platform API를 사용할 수 있어야 한다.
애플리케이션에서 GCP API를 사용하도록 허용하려면 관련 API를 사용 설정하고 애플리케이션에 적절한 사용자 인증 정보를 제공해야 한다.
이러한 자격 증명을 사용하여 응용 프로그램은 서비스에 대해 자신을 인증하고 작업을 수행할 수 있는 권한을 얻는 방식이다.
적절한 자격 증명이 생성되어 GKE의 애플리케이션에서 사용할 수 있게 되면 클라우드 서비스를 최대한 활용할 수 있다.
GCP의 모든 작업은 인증 및 승인을 받아야 하며 애플리케이션은 GCP API가 사용할 수 있도록 API에 직접 사용하는 서비스 계정의 사용자 인증 정보를 보낼 수 있어야 한다.
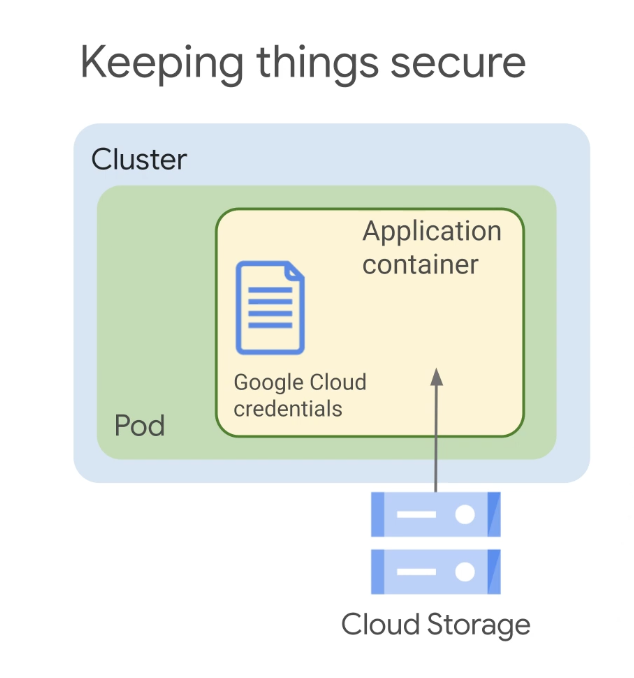
예를 들어 위의 다이어그램에서 컨테이너화된 애플리케이션은 사용자 인증 정보를 제공하여 Google Cloud Storage의 리소스를 사용하고 있다.
애플리케이션은 GCP API, 인증, 승인에 Cloud IAM 서비스 계정을 사용해야 하며 Kubernetes에도 서비스 계정이 있지만 Cloud IAM 서비스 계정은 Kubernetes 내부가 아닌 GCP 수준에서 정의되기 때문이다.
GKE에서는 일반적으로 이전에 배운 Kubernetes 보안 시크릿을 사용하여 Cloud IAM 서비스 계정의 인증 사용자 인증 정보를 애플리케이션에 제공했다.
또한, 이러한 비밀에는 JSON 또는 p12 형식의 자격 증명이 포함되어 있다.

서비스 계정에는 애플리케이션에 필요한 권한이 있는 IAM 역할이 할당되어야 하며 단순히 기존 Compute Engine 기본 서비스 계정의 권한을 업데이트하면 안된다.
대신 GCP 서비스에 요청해야 하는 각 애플리케이션에 대해 새 서비스 계정을 생성하는 것을 권장한다.
서로 다른 애플리케이션에 별도의 서비스 계정을 사용하면 각 계정과 관련된 권한을 최소화할 수 있기 때문이다.
별도의 계정이 있으면 애플리케이션 수준에서 API 요청의 모니터링 및 감사를 보다 쉽게 활성화할 수 있고 또한 공유 서비스 계정에 대한 액세스 권한을 취소하는 대신 해당 애플리케이션과 연결된 서비스 계정을 삭제하여 특정 애플리케이션의 액세스 권한을 취소하는 것이 더 쉽고 간단하다.
기본 서비스 계정의 권한을 업데이트 하면 여러 애플리케이션에 동시에 영향을 미치며 관리 문제가 될 수 있기 때문이다.
보안 침해가 발생한 경우 별도의 계정을 사용하면 노출을 줄일 수 있고 서비스 계정이 많으면 공격자에게 각 계정의 가치가 낮아진다.
-
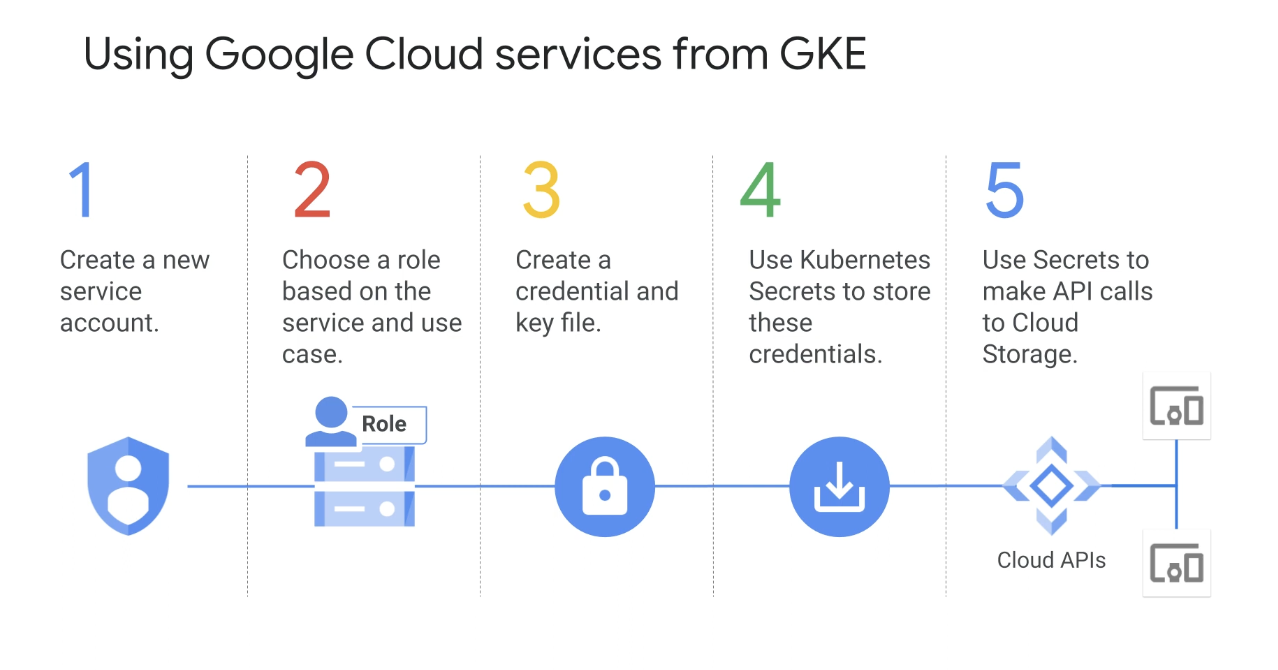
새 클라우드 IAM 서비스 계정을 생성
-
서비스 계정을 생성하는 동안 적절한 클라우드 IAM 역할을 선택
- 역할은 역할을 보유한 계정에 권한을 부여한다.
Cloud Storage를 예로 들어 보자.
애플리케이션이 Cloud Storage 버킷에서 읽어야 하고 서비스 계정인 Storage를 제공해야 한다고 가정해 보면 객체 뷰어 역할은 클라우드 스토리지에서 데이터를 읽을 수 있는 애플리케이션 권한을 부여하지만 변경할 수는 없다.
- 필요한 역할을 선택한 후 JSON 또는 p12 형식을 사용할지 지정한다.
- 자격 증명 파일을 삭제하면 새 키가 생성되어 선택한 형식으로 저장되고 시간이 지남에 따라 이러한 자격 증명의 순환을 관리하는 것은 우리의 책임이다.
- GKE 내에서 서비스 계정을 사용하려면 서비스 계정의 사용자 인증 정보 파일을 저장할 Kubernetes 보안 시크릿 리소스 유형을 만든다.
- Google Cloud Key Management Service(KMS)를 사용하여 Cloud IAM 인증 사용자 인증 정보를 비롯한 보안 비밀을 관리하고 교체할 수 있고 이는 GKE의 보안 비밀 리소스에 대한 추가 보호를 제공한다.
- 그런 다음 시크릿을 파트 또는 디플로이먼트 정의의 파트로 볼륨으로 탑재한다.
-
파트 내의 애플리케이션 컨테이너는 이제 자격 증명을 파일로 액세스하고 이를 사용하여 클라이언트 라이브러리를 통해 API를 호출할 수 있다.
-
이러한 사용자 인증 정보는 애플리케이션을 생성한 서비스 계정으로 인증한다.
결과적으로 , 서비스 계정에 올바른 권한이 있는 역할을 부여한다고 가정하면 애플리케이션은 클라우드 스토리지 서비스 및 애플리케이션에 대해 관리하는 개체를 사용할 수 있어야 한다.
3. Cloud Storage
클라우드 스토리지는 다양한 사용자가 사용하는 개체 스토리지 서비스이며, 객체 스토리지는 단순히 정렬된 바이트 그룹의 스토리지를 의미한다.
스토리지 서비스는 해당 바이트의 구조 및 의미 체계를 알지 못하거나 신경 쓰지 않고 우리의 애플리케이션이 이를 결정한다.
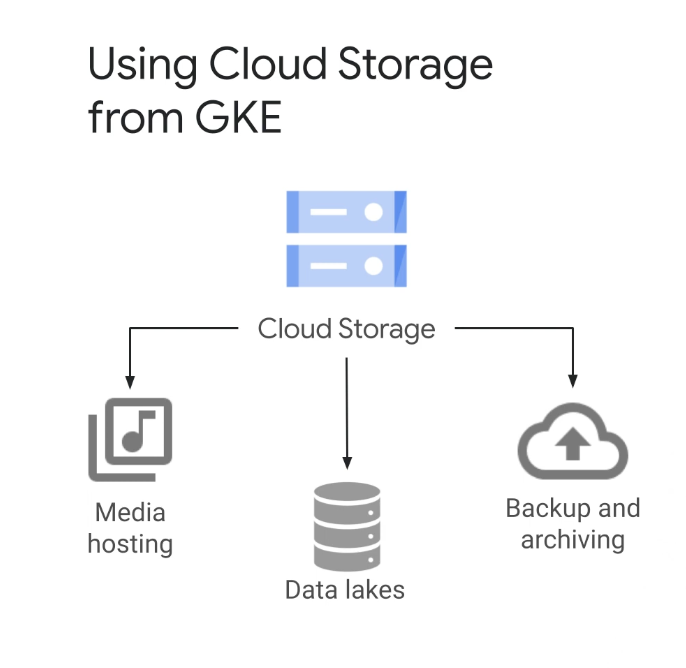
클라우드 스토리지는 일반적으로 웹 사이트용 이미지 제공 또는 음악 및 비디오 스트리밍과 같은 미디어 호스팅에 사용되며, 유전체학 및 데이터 분석과 같은 분석 및 머신 러닝 워크로드를 위한 데이터 레이크로도 사용할 수 있다.
또한 테이프 마이그레이션 또는 재해 복구와 같은 백업 및 아카이브에 클라우드 스토리지를 사용할 수 있다.
객체 스토리지가 필요한 이러한 종류의 애플리케이션 등을 GKE에 배포할 수 있는데 예를 들어 모바일 앱 백엔드가 GKE에 배포될 수 있으며 Cloud Storage 버킷의 이미지에 액세스해야 할 수 있다.
클라우드 스토리지를 요약하면 Blob 스토리지라고도 하는 구조화되지 않은 파일을 위한 개체 스토리지를 제공하는데 구조화된 데이터를 저장하는 데 사용할 수도 있지만 서비스는 쿼리 기능에 최적화되어 있지 않기 때문에 다른 서비스를 고려할 필요가 있고 나중에 소개하겠다.
클라우드 스토리지는 파일 시스템으로 사용하도록 설계되지 않았으므로 영구 볼륨을 대신하지 않다는 점에 주의 하자.
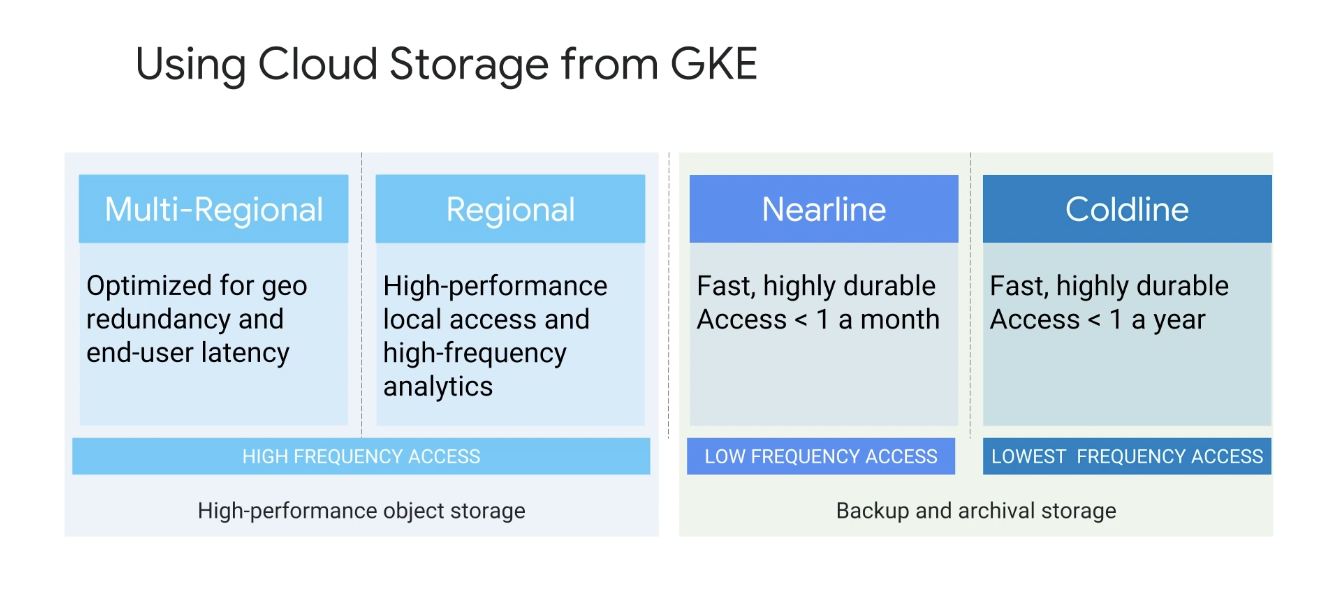
클라우드 스토리지의 스토리지 클래스는 가격과 지리적 중복성에 대해 서로 다른 장단점을 제공하며 네 가지 스토리지 클래스를 제공한다.
-
다중 지역 저장소- 웹 사이트 콘텐츠, 대화형 워크로드 또는 모바일 및 게임 애플리케이션을 지원하는 데이터와 같이 자주 액세스하는 데이터를 저장하는 데 적합
-
지역 저장소- 컴퓨팅 엔진 인스턴스 또는 Google과 동일한 지역 위치에 데이터를 저장하는 데 적합
- 다중 지역 위치에 데이터를 저장하는 것과는 대조적으로 데이터 집약적인 계산을 위해 더 나은 성능을 제공하는 Kubernetes Engine 클러스터에 적합
- 사용하는 양에 따라 지역 및 다중 지역 스토리지 비용을 지불한다.
-
니어라인 저장소- 평균적으로 한 달에 한 번 미만으로 읽거나 수정되는 데이터에 이상적
- 예를 들어 클라우드 스토리지에 파일을 지속적으로 추가하고 분석을 위해 해당 파일에 분기별로 액세스할 계획인 경우
- 데이터 백업, 재해 복구 및 아카이브 스토리지에도 적합
-
Coldline Storage- 데이터 보관, 온라인 백업 및 재해 복구를 위한 매우 저렴하고 내구성이 뛰어난 스토리지 서비스
- 다른 클라우드 스토리지 서비스와 달리 몇 시간 또는 며칠이 아닌 밀리초 이내에 데이터를 사용할 수 있음
- 콜드라인 스토리지의 가격 구조는 1년에 한 번 미만으로 검색되는 데이터에 이상적
03:28
니어라인과 콜드라인은 트레이드 오프를 제공하며 다중 지역 및 지역 스토리지보다 저장된 기가바이트당 비용이 저렴하지만 검색에 대한 추가 비용을 고려해야한다.
데이터 액세스 빈도가 적을수록 니어라인 및 콜드라인에 대한 후보가 더 좋은건 직관적이고 짐작하겠지만 coldline은 저장 비용이 가장 낮고 검색 비용은 nearline보다 높다.
모든 스토리지 클래스는 짧은 대기 시간과 높은 내구성을 제공하고 모든 스토리지 클래스에 대해 단일 API만 필요하기 때문에 애플리케이션은 다양한 종류의 데이터에 대해 여러 스토리지 클래스를 사용할 수 있다.
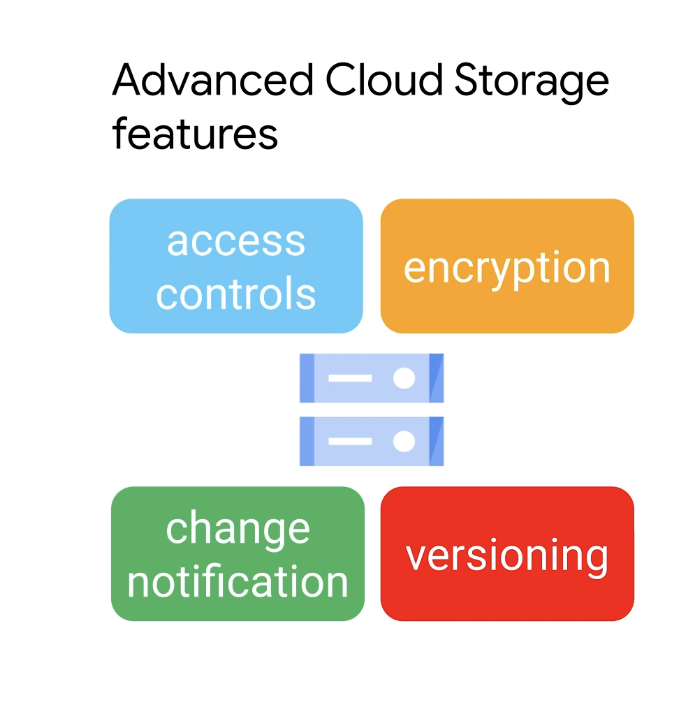
클라우드 스토리지는 포괄적인 세분화된 액세스 제어 기능을 지원한다.
이러한 기능을 사용하여 클라우드 스토리지에 저장된 모든 개체가 적절하게 보호되도록 할 수 있다.
클라우드 스토리지는 데이터가 디스크에 기록되기 전에 항상 서버 측에서 데이터를 암호화하는데 고객 제공 또는 고객 관리 암호화 키를 사용하는 서버 측 암호화도 지원한다.
이 암호화는 클라우드 스토리지가 데이터를 수신한 후 데이터가 디스크에 기록되고 저장되기 전에 발생한다.
기본 암호화로는 충분하지 않다는 규제 요구 사항에 직면한 경우 이러한 옵션을 고려해볼 수 있다.
클라우드 스토리지 서비스는 개체 변경 알림을 제공하므로 클라우드 스토리지 버킷이 변경될 때마다 URL 호출을 통해 애플리케이션에 알림이 전송된다.
또한 GCP의 완전 관리형 실시간 메시징 서비스인 Cloud pubsub와 함께 Cloud Storage를 사용하여 보다 확장 가능하고 관리하기 쉬운 방식으로 동일한 효과를 얻을 수 있는데 AWS 의 S3 와 AWS SNS 같은 서비스와 비슷한 개념인 것 같다.
클라우드 저장소는 버전 관리를 지원하지만 사용하려면 먼저 활성화해야 하고 버전 관리를 활성화한 후 클라우드 스토리지는 개체의 라이브 버전을 덮어쓰거나 삭제할 때마다 개체의 보관된 버전을 생성한다.
보관된 버전은 객체의 이름을 유지하지만 세대 번호로 고유하게 식별될 수 있다.
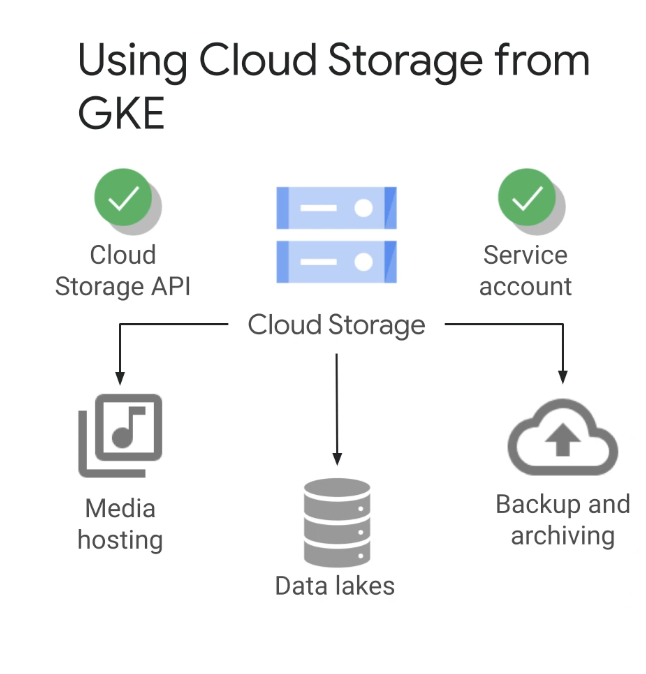
GKE 클러스터 내의 애플리케이션은 Cloud Storage API를 사용하여 Cloud Storage에 액세스할 수 있는데 다른 Google Cloud API와 마찬가지로 Cloud Storage API를 사용 설정해야 애플리케이션에서 사용할 수 있다.
또한 관련 API를 활성화한 후에는 애플리케이션이 사용하려는 서비스에 액세스하기 위해 서비스 계정을 사용해야 한다는 점을 잊지 말자.
4. Google 클라우드 데이터베이스 사용
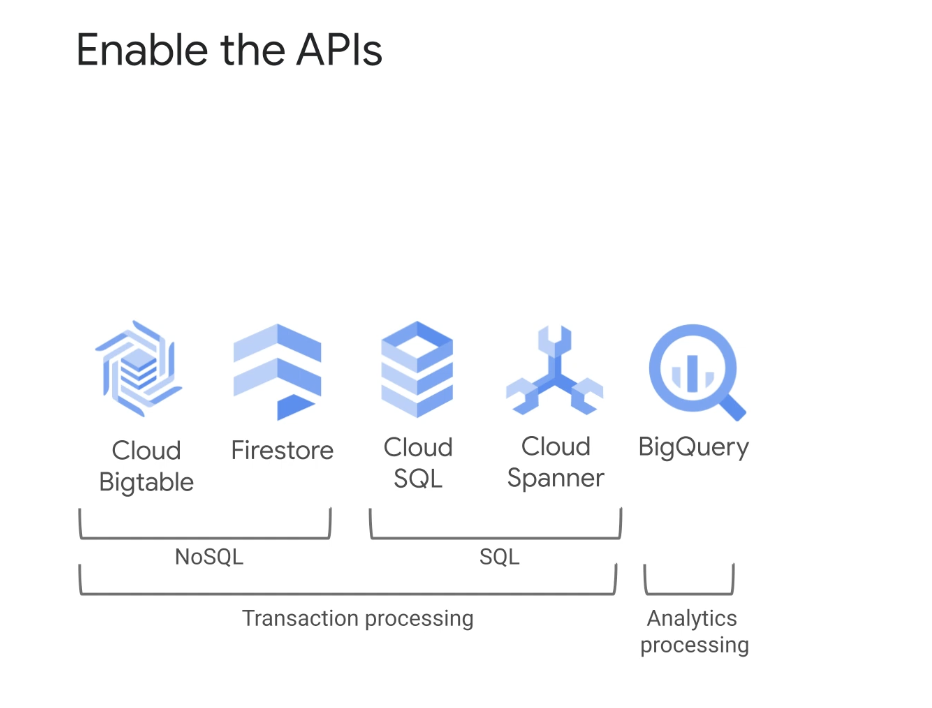
제 GCP에서 제공하는 관리형 데이터베이스 서비스의 유형을 살펴볼텐데 Cloud Big Table, BigQuery, Cloud Firestore, Clouds SQL, Cloud Spanner의 주요 기능에 대해 알아볼 것이다.
또한 Cloud Sequence 프록시를 사용하여 GK 애플리케이션을 Cloud Sequence 인스턴스에 연결하는 프로세스를 단순화하는 방법도 알아보자.
다른 액세스를 위해 클라우드 스토리지에 액세스하는 데 사용하는(Cloud Bigtable, BigQuery, Cloud Firestore, Clouds SQL, Cloud Spanner GPS 데이터베이스 서비스와 같은 GCP 서비스) 것과 동일한 접근 방식을 사용할 수 있다.
따라서 전반적인 목적에 따라 데이터 저장 및 검색과 같은 온라인 데이터 사용을 지원하고 응용 프로그램에 사용하기에 적합하다.
반면에 GCP는 데이터 마이닝과 패턴 및 추세 발견에 최적화된 분석 데이터베이스 서비스도 제공하는데 차례로 온라인 응용 프로그램을 백업하는 데이터베이스 서비스는 SQL 및 NoSQL 범주에 속한다.
SQL 데이터베이스 서비스는 관계형 데이터용이며 데이터베이스의 의미 체계를 적용하는 데 도움이 되는 데이터베이스 엔진을 원할 때 선택하고 NoSQL 데이터베이스 서비스는 유연하게 구조화된 데이터를 위한 것이며 데이터 무결성을 유지하는 것은 애플리케이션에 달려 있다.
5. Cloud Bigtable Use case
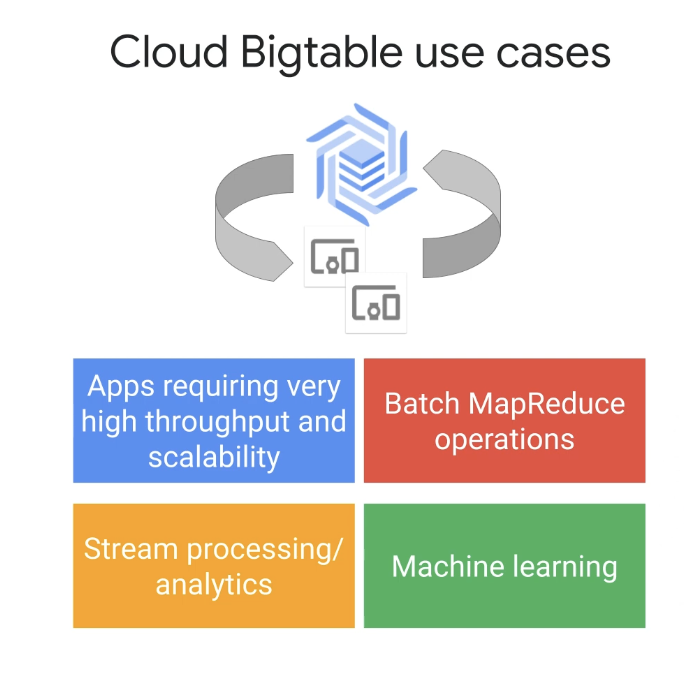
먼저 클라우드 빅테이블이란 확장을 위해 설계된 Google의 NoSQL 데이터베이스이다.
Bigtable은 대규모로 확장 가능한 테이블에 데이터를 저장하며 각 테이블은 단일 키에서 넓은 열로의 매핑이라고 생각하면 된다.
키당 하나의 행에 맞는 플랫 데이터가 있고 밀리초 범위의 데이터에 대한 액세스 대기 시간이 필요한 경우 Bigtable을 선택하자.
또한 더 많은 노드를 추가함에 따라 선형적으로 확장되는 데이터베이스가 필요한 경우 Bigtable을 선택하자.
Cloud Bigtable은 데이터를 페타바이트까지 확장하고 10밀리초 미만의 지연 시간으로 초당 수백만 건의 작업을 원활하게 처리할 수 있다.
따라서 구조화되지 않은 키-값 데이터에 대해 매우 높은 처리량과 확장성이 필요한 애플리케이션에 적합하다.
데이터베이스 액세스에 Apache HBase와 동일한 API를 사용하기 때문에 MapReduce 작업을 위한 탁월한 스토리지 솔루션이다.
또한 일반적으로 스트림 처리 및 분석과 기계 학습 애플리케이션에 사용되며 시계열 데이터, 마케팅 데이터, 재무 데이터, IoT 데이터 등을 저장하고 쿼리하는 애플리케이션에 Cloud Bigtable을 사용할 수 있다.
6. FireStore Use case
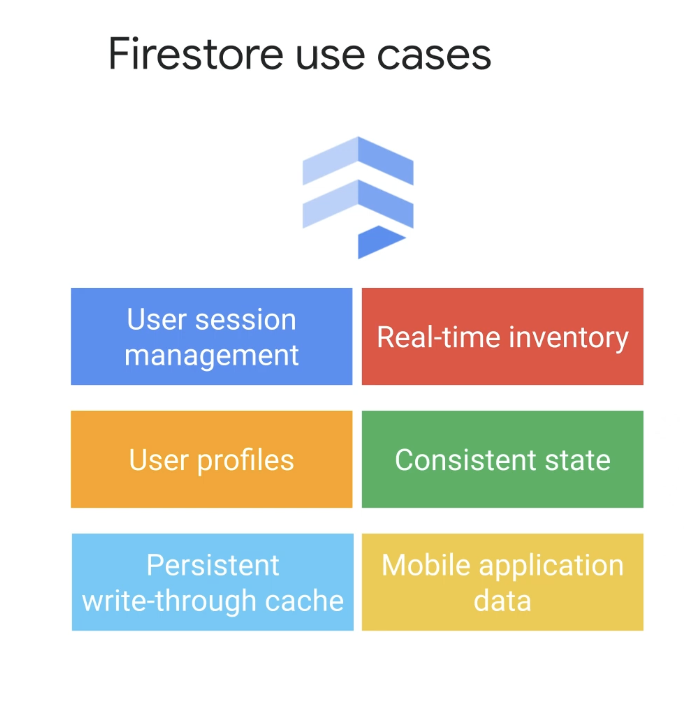
Cloud Firestore는 데이터를 자동으로 확장하고 복제하여 고가용성과 내구성을 유지한다.
데이터를 지역적으로 또는 다중 지역적으로 복제할지 여부를 선택할 수 있으며 트랜잭션에 대한 강력한 일관성 보장을 제공한다.
모든 필드가 자동으로 인덱싱되기 때문에 빠른 쿼리를 수행할 수 있다.
Cloud Firestore를 사용하여 장바구니 및 예약 이벤트에 대한 실시간 세션을 설정할 수 있으므로 이러한 애플리케이션에 필요한 트랜잭션 규정 준수를 제공할 수 있다.
Cloud Firestore의 데이터 모델은 Documents store인데 이 컨텍스트에서 '문서'라는 단어의 의미를 이해하려면 필드와 값을 포함하는 JSON 데이터의 스니펫을 생각해 보면 이러한 필드는 중첩될 수 있다.
이러한 필드는 데이터베이스에 저장하는 모든 항목에 대해 항상 동일할 필요는 없으며 엄격한 스키마로 자신을 제한할 필요 없이 Cloud Firestore를 사용하여 비균질 데이터를 저장할 수 있다.
예를 들어 다양한 재고 데이터를 저장하는 경우 이상적인데 애플리케이션이 각 사용자의 프로필을 유지한다고 가정하자.
응용 프로그램을 시작한 지 6개월 후에 사용자를 위해 새 필드를 저장해야 한다는 사실을 깨달았다면 어떻게 할까?
Cloud Firestore의 유연한 스키마를 사용하면 새로운 기능을 추가할 때 애플리케이션에서 사용자 프로필의 모든 구조를 가질 수 있습니다.
Cloud Firestore는 'ACID 트랜잭션'이라는 것을 제공하는데 본질적으로 ACID 준수는 트랜잭션이 전체적으로 실행되거나 전혀 실행되지 않기 때문에 데이터베이스의 데이터가 내부적으로 일관성을 유지함을 의미한다.
Cloud Firestore의 ACID 준수로 인해 애플리케이션은 대규모 구현에서도 일관된 상태를 유지할 수 있고 예를 들어 대규모 온라인 게임 애플리케이션이 있다고 가정하면 Cloud Firestore는 수많은 동시 플레이어 세션에 대해 일관된 글로벌 게임 상태를 유지하는 데 이상적이다.
Cloud Firestore를 영구 쓰기 캐시로 사용하여 데이터 손실을 방지하고 애플리케이션이 실패할 경우 영구 상태를 제공하는 간단한 키-값 저장소를 제공할 수 있다.
마지막으로 Cloud Firestore는 다양한 모바일 프로그래밍 언어로 된 통합 클라이언트 라이브러리가 포함된 Google의 모바일 앱 플랫폼인 Firebase의 일부이기도 하다.
모바일 앱 개발자는 Firestore를 사용하여 글로벌 규모로 앱 데이터를 저장하고 동기화할 수 있다.
7. Cloud SQL
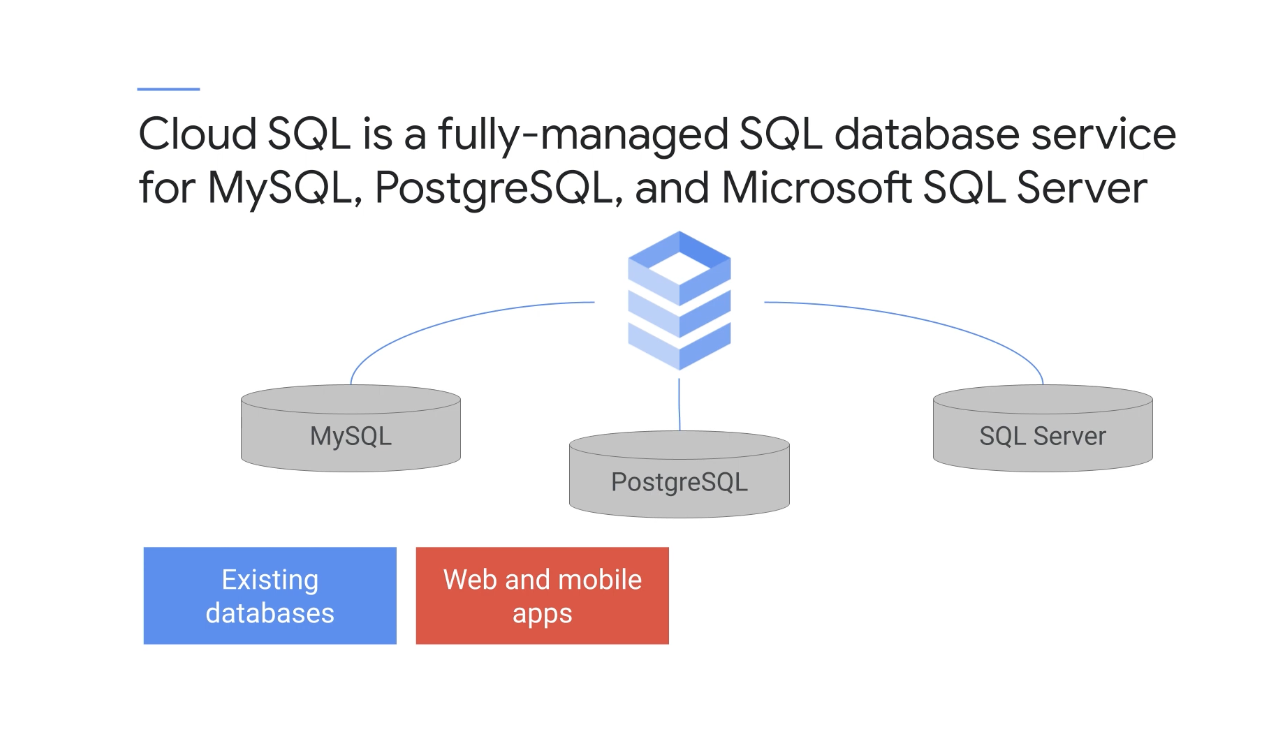
이제 NoSQL 데이터베이스 서비스에서 SQL 데이터베이스 서비스로 전환할텐데, 이러한 서비스의 경우 데이터베이스 엔진에서 데이터베이스에 대한 스키마를 정의하면 데이터베이스를 유지 관리하는 데 도움이 된다.
Cloud SQL은 MySQL, PostgreSQL, Microsoft SQL Server용 완전 관리형 SQL 데이터베이스 서비스이다.
Compute Engine 또는 Kubernetes Engine에서 이러한 데이터베이스 서비스를 직접 실행할 수 있지만 Cloud SQL은 작업을 절약하기 위한 것이며 Google Cloud는 데이터베이스 소프트웨어를 유지관리, 패치, 업데이트하기 때문에 작업을 절약할 수 있다.
데이터 복제를 관리하고 백업을 수행하며 고가용성을 위해 자동 장애 조치도 지원한다.
Cloud SQL 인스턴스를 만든 후 기존 서버에서 데이터베이스 덤프를 가져오고 Cloud SQL 인스턴스를 가리키도록 애플리케이션을 재구성하기만 하면 되므로 간단하다.
또한 웹 및 모바일 애플리케이션, 전자상거래 애플리케이션, 모바일 또는 온라인 게임과 같이 관계형 데이터베이스 요구사항이 있는 모든 애플리케이션에서 Cloud SQL을 사용할 수 있다.
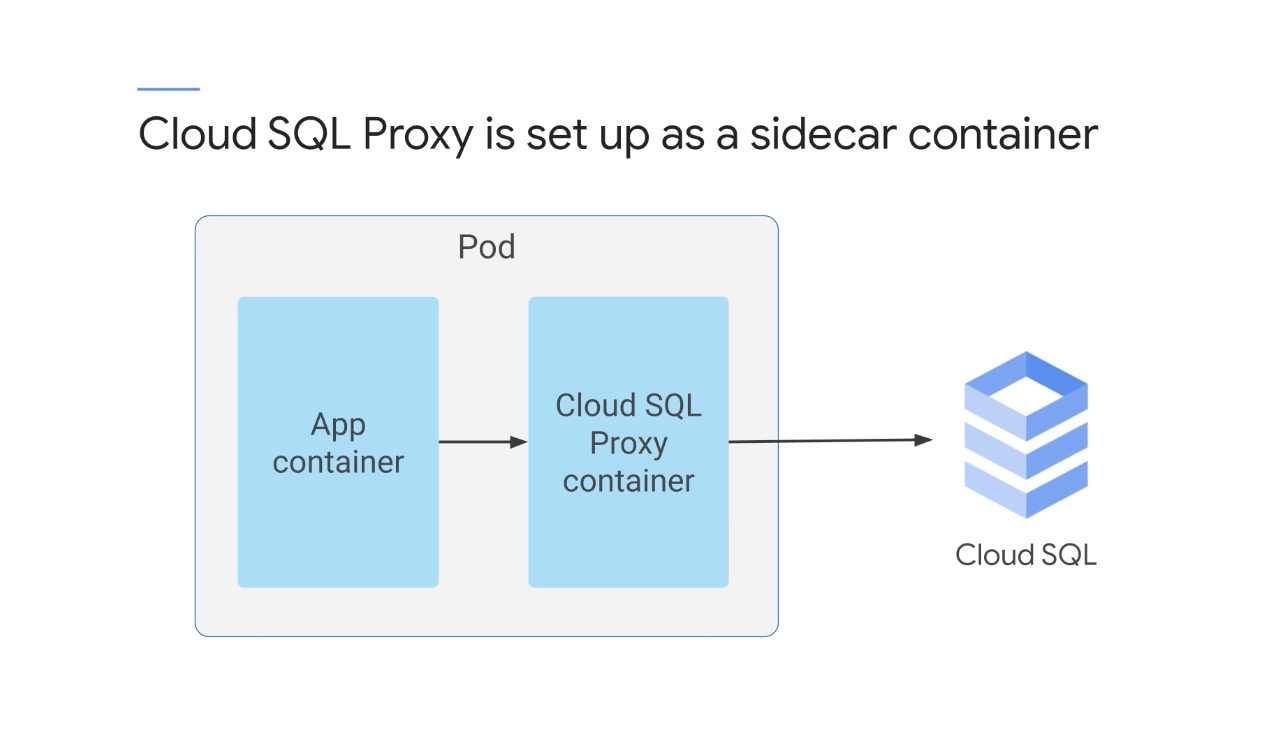
GKE에서 실행 중인 애플리케이션은 Cloud SQL 프록시를 사용하여 Cloud SQL에 액세스하는데 이것은 보안 액세스를 제공하기 위해 애플리케이션에 추가하는 소프트웨어이다.
SSL을 구성하거나 목록 IP 주소를 허용할 필요 없이 Cloud SQL 데이터베이스 인스턴스에 연결할 수 있다.
Cloud SQL 프록시는 전송 중인 트래픽을 자동으로 암호화하고 SQL로 인증을 처리하기 때문에 애플리케이션을 구성하는 Pod가 동적일 수 있지만 여전히 안정적으로 데이터베이스에 액세스할 수 있다.
GKE에서 Cloud SQL 프록시는 애플리케이션이 포함된 동일한 Pod에서 '사이드카' 컨테이너로 설정되고 애플리케이션은 localhost 네트워크 주소를 사용하여 SQL 프록시 컨테이너와 통신한다.
Cloud SQL 프록시가 있으면 다른 외부 애플리케이션과 마찬가지로 애플리케이션을 Cloud SQL에 연결할 수 있다.
8. Cloud Spanner Use case
클라우드 스패너는 여러 면에서 Cloud SQL과 유사하지만 몇 가지 중요한 차이점도 있다.
Cloud SQL과 마찬가지로 Cloud Spanner는 트랜잭션에 대한 ACID 일관성 보장을 제공하는 관계형 데이터베이스 서비스이지만, Cloud SQL과 달리 Cloud Spanner는 전 세계에 분산되어 있다는 특징이 있다.
여러 GCP 지역에서 Cloud Spanner 데이터베이스를 호스팅하도록 선택하더라도 트랜잭션에 대한 강력한 일관성 보장을 제공한다.
Cloud Spanner는 의미상 단일 머신 데이터베이스와 구별할 수 없는 속성 덕분에 지리적 범위가 넓은 애플리케이션에 이상적이다.
Cloud SQL과 달리 Cloud Spanner는 수평 확장이 가능하고 스토리지 또는 초당 트랜잭션 용량이 더 필요한 경우 기존 인스턴스에 Cloud Spanner 노드를 추가하기만 하면 된다.
글로벌 금융 거래 애플리케이션에서 기존 데이터베이스 솔루션은 매우 복잡한 인프라에 의존하여 거래의 트랜잭션 무결성이 글로벌 규모로 유지되도록 하지만 Cloud Spanner의 전 세계적으로 일관된 데이터는 이러한 솔루션에 필요한 이러한 복잡성을 상당 부분 제거한다는 장점이 있다.
마찬가지로 글로벌 규모로 애플리케이션이나 웹 서비스를 운영하는 보험, 콜센터, 공급망 관리, 통신, 물류, 전자상거래 비즈니스는 Cloud Spanner와 잘 어울리고 Cloud Spanner를 사용하면 전 세계적으로 고도의 양방향 온라인 게임 솔루션을 구축할 수 있다.
기존의 데이터베이스 솔루션은 게임이 단일 서버 또는 제한된 지리적 영역을 넘어 확장되지 않도록 플레이어의 일관된 상태를 보장하기 위해 상당한 절충안이 필요한 경우가 많은데 클라우드 스패너는 이러한 절충안에 적합하다.
9. Big Query Use case
지금까지 온라인 애플리케이션 지원에 적합한 GCP의 데이터베이스 서비스에 대해 배웠는데 이제 GCP의 데이터 웨어하우징 서비스에 대해 배워볼 것이다.
BigQuery는 SQL 쿼리를 지원하지만 열 기반 저장소라는 점에서 Google Cloud의 다른 관계형 데이터베이스 서비스와 다르다.
즉, 행 단위 쿼리 및 변경이 아닌 데이터 세트 분석에 최적화되어 있다.
데이터 웨어하우스를 운영하는 것은 많은 작업이 될 수 있는데 BigQuery는 압축, 암호화, 복제, 성능 조정, 확장을 포함하여 구조화된 데이터 저장의 기술적 측면을 관리한다.
또한 기존 데이터 웨어하우스는 사용하지 않는 경우에도 비용이 많이 들 수 있지만, BigQuery의 주요 이점은 데이터 스토리지가 모든 컴퓨팅 요금과 별도로 청구되며 쿼리를 실행할 때만 컴퓨팅 요금이 부과된다는 이점이 있다.
BigQuery는 최신 비즈니스 인텔리전스 솔루션을 위한 데이터 웨어하우징 백엔드를 제공하고, Google 및 써드파티 도구를 사용하여 데이터 통합, 변환, 분석, 시각화 및 보고가 가능하다.
많은 사람들이 실시간 재고, 물류, 공급망 애플리케이션의 일부로 BigQuery를 사용하는데 들어오는 인벤토리를 로드하고 데이터를 BigQuery로 스트리밍하여 데이터 웨어하우징 기능 및 분석을 제공할 수 있다.
BigQuery는 IoT(또는 사물 인터넷) 애플리케이션이 생성하는 방대한 양의 이벤트 및 센서 데이터를 저장하는 데 적합한데 이러한 유형의 데이터는 BigQuery가 처리하도록 최적화된 '한 번 쓰기, 많은 읽기' 액세스 프로필을 갖는 경향이 있으며 BigQuery는 임시 분석을 수행하거나 고급 분석을 실행하거나 보고 및 분석을 위한 추가 파생 데이터를 생성할 수 있다.
매우 많은 양의 기록 또는 실시간 스트리밍 이벤트 데이터를 소비하고 분석해야 하는 애플리케이션에 BigQuery를 사용할 수 있다.
BigQuery는 대규모 이벤트 데이터 로깅을 지원해야 하는 애플리케이션이 있는 경우에도 적합하며 들어오는 스트리밍 데이터에 대한 기본 할당량은 초당 100,000행이다.
해당 한도가 필요에 따라 충분하지 않은 경우 Google Cloud 지원팀에 할당량을 늘리도록 요청하면 되고 BigQuery를 사용하여 예측 디지털 마케팅 애플리케이션을 위해 사용자 프로필 및 활동 데이터를 대규모로 저장하고 분석할 수 있다.
10. Google Kubernetes Engine에서 Cloud SQL 사용 실습
이 실습에서는 SQL 프록시를 통해 Cloud SQL에 연결된 WordPress의 Kubernetes 배포를 설정한다.
SQL 프록시를 사용하면 로컬에 설치된 것처럼(localhost:3306) Cloud SQL 인스턴스와 상호작용할 수 있으며 로컬에서 보안되지 않은 포트에 있더라도 SQL 프록시는 Cloud SQL 인스턴스에 대한 유선 보안을 보장한다.
먼저 GKE 클러스터를 만든 다음 연결할 Cloud SQL 인스턴스와 포드가 Cloud SQL 인스턴스에 액세스할 수 있는 권한을 제공하는 서비스 계정을 만들고, 마지막으로 Cloud SQL 인스턴스에 연결된 SQL 프록시를 사이드카로 사용하여 GKE 클러스터에 WordPress를 배포한다.
실습 목표
-
Wordpress용 Cloud SQL 인스턴스 및 데이터베이스 생성
-
애플리케이션 인증을 위한 자격 증명 및 Kubernetes 시크릿을 생성
-
SQL 프록시를 사용하도록 Wordpress 이미지로 배포를 구성
-
SQL 프록시를 사이드카 컨테이너로 설치하고 이를 사용하여 GKE 클러스터 외부의 CloudSQL 인스턴스에 대한 SSL 액세스를 제공한다.
10-1. 실습 GKE 클러스터에 연결
export my_zone=us-central1-a
export my_cluster=standard-cluster-1
source <(kubectl completion bash)
gcloud container clusters get-credentials $my_cluster --zone $my_zone
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
ln -s ~/training-data-analyst/courses/ak8s/v1.1 ~/ak8s
cd ~/ak8s/Cloud_SQL/10-2. Cloud SQL API 사용 설정
-
Google Cloud Console의 탐색 메뉴 ( 탐색 메뉴 아이콘) 에서 API 및 서비스를 클릭
-
➕ API 및 서비스 활성화를 클릭
-
API 및 서비스 검색 에 SQL을 입력한 다음 Cloud SQL API 타일을 클릭
-
활성화를 클릭하여 Cloud SQL API를 활성화
API가 이미 활성화된 경우 API 활성화 메시지 와 함께 관리 버튼이 대신 나타나고 조치가 필요하지 않음
- 위의 단계를 반복하여 sqladmin API를 활성화

10-3. Cloud SQL 인스턴스 생성
- 다음 명령을 실행하여 인스턴스를 생성
gcloud sql instances create sql-instance --tier=db-n1-standard-2 --region=us-central1
$ gcloud sql instances create sql-instance --tier=db-n1-standard-2 --region=us-central1
Creating Cloud SQL instance for MYSQL_8_0...done.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/qwiklabs-gcp-00-04526d1bd9d1/instances/sql-instance].
NAME: sql-instance
DATABASE_VERSION: MYSQL_8_0
LOCATION: us-central1-b
TIER: db-n1-standard-2
PRIMARY_ADDRESS: 34.72.153.98
PRIVATE_ADDRESS: -
STATUS: RUNNABLE- 콘솔에서 SQL로 이동
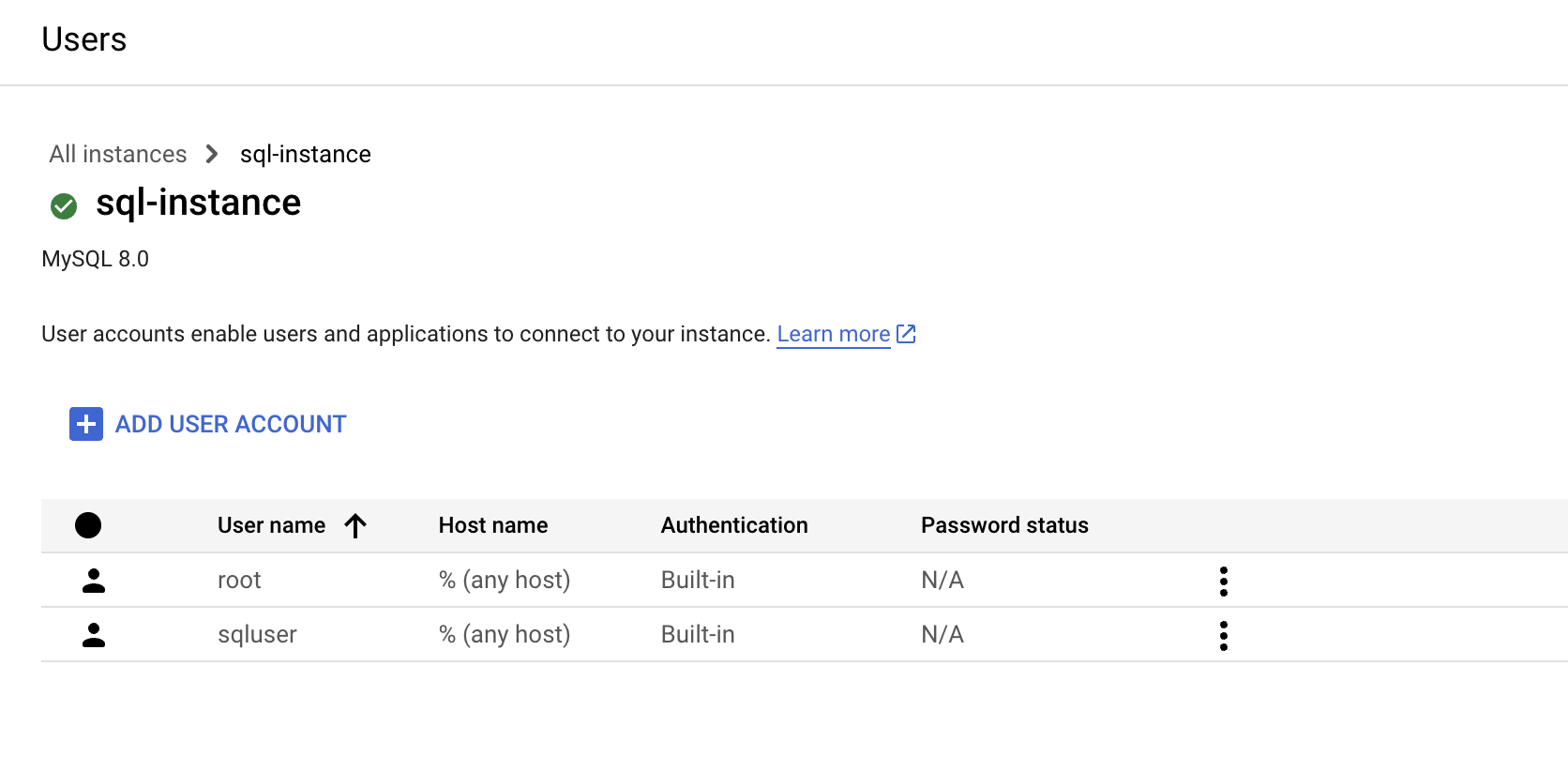
- sql-instance 이름을 클릭한 다음 사용자 메뉴를 클릭
- root 사용자가 나열되면 다음 단계로 이동할 수 있음
- 사용자 계정 추가를 클릭 하고 sqluser 사용자 이름과 sqlpassword 암호를 사용하여 계정을 생성
- 모든 호스트 허용(%) 으로 설정된 호스트 이름 옵션을 그대로 두고, 추가 클릭
- 인스턴스 연결 이름을 복사
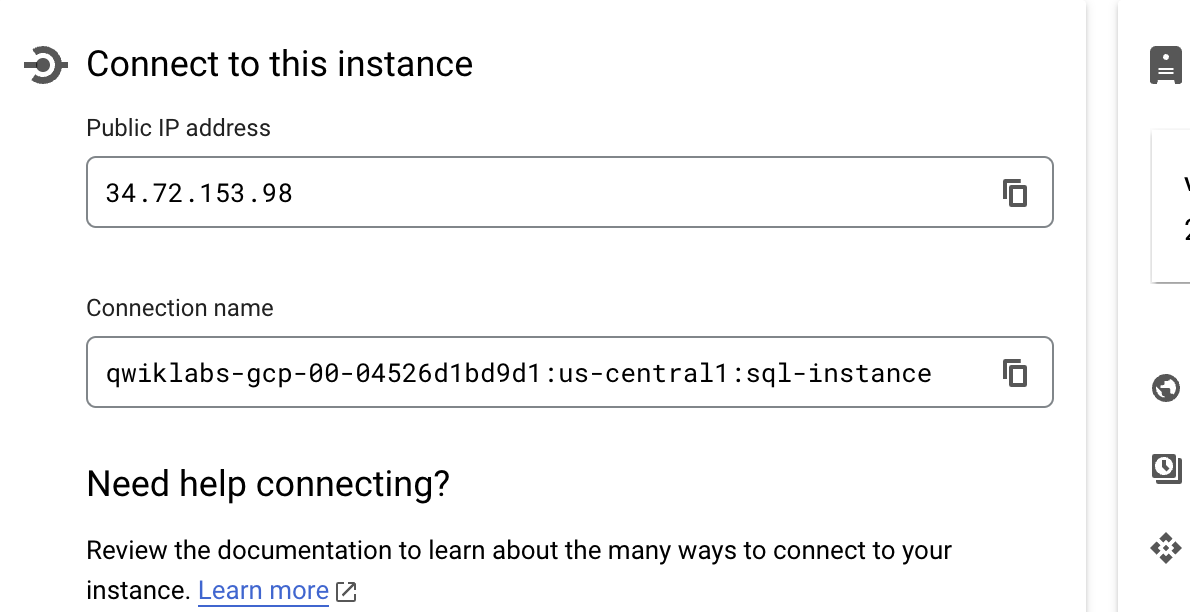
- Cloud SQL 인스턴스 이름을 저장할 환경 변수 생성
export SQL_NAME=[Cloud SQL Instance Name] - Cloud SQL 인스턴스에 연결
gcloud sql connect sql-instance - 루트 암호를 입력하라는 메시지가 표시되면 Enter 키를 입력(루트 SQL 사용자 암호는 기본적으로 비어있음)
mysql>MySQL 클라이언트를 사용하여 Cloud SQL 인스턴스에 연결되었음을 나타내는 프롬프트가 생성
- Wordpress에 필요한 데이터베이스를 생성
create database wordpress;
use wordpress;
show tables;
exit;10-4. Cloud SQL 액세스 권한이 있는 서비스 계정 준비
-
Google Cloud 콘솔에서 IAM 및 관리자 > 서비스 계정 으로 이동
-
➕ 서비스 계정 만들기를 클릭
-
sql-access 라는 서비스 계정 이름을 지정한 다음 만들기 및 계속을 클릭
-
역할 선택 클릭
-
Cloud SQL을 검색 하고 Cloud SQL 클라이언트를 선택한 후 계속을 클릭 하고 완료 버튼 클릭
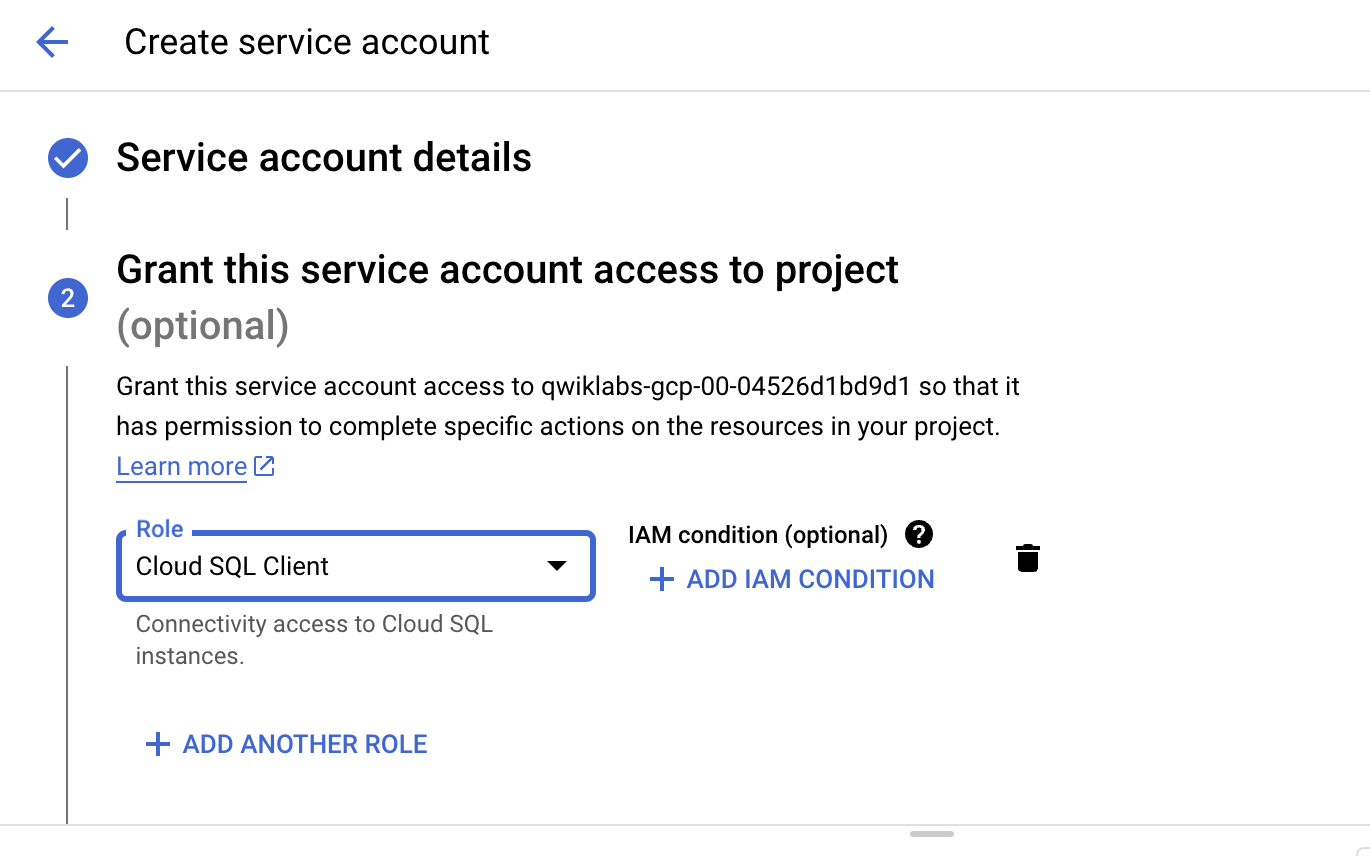
-
서비스 계정 sql-access 을 찾고 작업열 에서 점 세 개 아이콘을 클릭하여 키 관리를 선택
-
ADD KEY를 클릭 ➡️ Create new key를 선택 ➡️ JSON 키 유형이 선택되었는지 확인 하고 만들기를 클릭
- 이렇게 하면 공개/개인 키 쌍이 생성되고 개인 키 파일이 컴퓨터에 자동으로 다운로드된되며 나중에 이 JSON 파일이 필요하다.
- 다운로드한 JSON 자격 증명 파일을 찾아 이름을 credentials.json 으로 변경
10-5. 시크릿 생성
두 개의 Kubernetes 비밀을 만드는데 하나는 MySQL 자격 증명을 제공하고 다른 하나는 Google 자격 증명(서비스 계정)을 제공한다.
- MySQL 자격 증명에 대한 암호를 생성
kubectl create secret generic sql-credentials \
--from-literal=username=sqluser\
--from-literal=password=sqlpassword- 이전 작업에서 다운로드한 자격 증명 파일인 credentials.json을 Cloud Shell에 업로드
mv ~/credentials.json .- Google 클라우드 서비스 계정 자격 증명의 보안 비밀 생성
kubectl create secret generic google-credentials\
--from-file=key.json=credentials.json참고: 파일은 `key.json`이라는 이름을 사용하여 Secret에 업로드되고,
이 비밀이 비밀 볼륨으로 연결될 때 컨테이너에 표시되는 파일 이름이다.10-6. SQL 프록시 에이전트를 사이드카 컨테이너로 배포
SQL 프록시 에이전트를 사이드카 컨테이너로 사용하여 데모 Wordpress 애플리케이션 컨테이너를 배포하는 샘플 디플로이먼트 매니페스트 파일을 배포해보자.
Wordpress 컨테이너 환경 설정에서 WORDPRESS_DB_HOST는 localhost IP 주소를 사용하여 지정된다. 사이드카 컨테이너 cloudsql-proxy 는 이전 작업에서 만든 Cloud SQL 인스턴스를 가리키도록 구성된다.
데이터베이스 사용자 이름과 암호는 비밀 키로 Wordpress 컨테이너에 전달되고 JSON 자격 증명 파일은 비밀 볼륨을 사용하여 컨테이너에 전달되며, 인터넷에서 Wordpress 인스턴스에 연결할 수 있도록 서비스도 생성된다.
$ cat sql-proxy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
template:
metadata:
labels:
app: wordpress
spec:
containers:
- name: web
image: gcr.io/cloud-marketplace/google/wordpress:5.9
ports:
- containerPort: 80
env:
- name: WORDPRESS_DB_HOST
value: 127.0.0.1:3306
# These secrets are required to start the pod.
# [START cloudsql_secrets]
- name: WORDPRESS_DB_USER
valueFrom:
secretKeyRef:
name: sql-credentials
key: username
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: sql-credentials
key: password
# [END cloudsql_secrets]
# Change <INSTANCE_CONNECTION_NAME> here to include your Google Cloud
# project, the region of your Cloud SQL instance and the name
# of your Cloud SQL instance. The format is
# $PROJECT:$REGION:$INSTANCE
# [START proxy_container]
- name: cloudsql-proxy
image: gcr.io/cloudsql-docker/gce-proxy:latest
command: ["/cloud_sql_proxy",
"-instances=<INSTANCE_CONNECTION_NAME>=tcp:3306",
"-credential_file=/secrets/cloudsql/key.json"]
# [START cloudsql_security_context]
securityContext:
runAsUser: 2 # non-root user
allowPrivilegeEscalation: false
# [END cloudsql_security_context]
volumeMounts:
- name: cloudsql-instance-credentials
mountPath: /secrets/cloudsql
readOnly: true
# [END proxy_container]
# [START volumes]
volumes:
- name: cloudsql-instance-credentials
secret:
secretName: google-credentials
# [END volumes]
---
apiVersion: "v1"
kind: "Service"
metadata:
name: "wordpress-service"
namespace: "default"
labels:
app: "wordpress"
spec:
ports:
- protocol: "TCP"
port: 80
selector:
app: "wordpress"
type: "LoadBalancer"
loadBalancerIP: ""-
Wordpress env 섹션-
변수(
env) WORDPRESS_DB_HOST는 127.0.0.1:3306로 설정되고, 포트 3306에서 수신 대기하는 동일한 포드의 컨테이너에 연결되며 이것은 SQL-Proxy가 기본적으로 수신 대기하는 포트이다. -
변수 WORDPRESS_DB_USER 과 WORDPRESS_DB_PASSWORD은 마지막 작업에서 생성한 비밀인 sql-credential 에 저장된 값을 사용하여 설정된다.
-
-
cloudsql-proxy 컨테이너 섹션command스위치 구문에서 SQL 커넥션 이름을 정의하고"-instances=<INSTANCE_CONNECTION_NAME>=tcp:3306", ConfigMap 또는 보안 비밀을 사용하여 구성되지 않은 자리 표시자 변수가 포함되어 있으므로 Cloud SQL 인스턴스를 가리키도록 이 예시 매니페스트에서 직접 업데이트해야 한다.JSON credentials파일은/secrets/cloudsql/디렉토리의 시크릿 볼륨에 마운트되고,"-credential_file=/secrets/cloudsql/key.json"이 커맨드 스위치는 google-credentials 시크릿을 만들 때 지정한 해당 디렉터리의 파일 이름을 가리킨다.
-
서비스 섹션- 외부 인터넷 주소에서 애플리케이션에 액세스할 수 있도록 하는 "wordpress-service"라는 외부 LoadBalancer를 생성한다.
SQL 연결 이름의 자리 표시자 변수를 Cloud SQL 인스턴스의 인스턴스 이름으로 업데이트
$ sed -i 's/<INSTANCE_CONNECTION_NAME>/'"${SQL_NAME}"'/g'\
sql-proxy.yaml
$ kubectl apply -f sql-proxy.yaml
$ kubectl get deployment wordpress
NAME READY UP-TO-DATE AVAILABLE AGE
wordpress 1/1 1 1 45s
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.12.0.1 <none> 443/TCP 32m
wordpress-service LoadBalancer 10.12.11.53 34.28.193.59 80:30433/TCP 2m20s
10-7. Wordpress 인스턴스에 연결
- 새 브라우저 탭을 열고 외부 LoadBalancer IP 주소를 사용하여 Wordpress 사이트에 연결하면 초기 Wordpress 설치 마법사가 시작
- 영어(미국)를 선택 하고 계속을 클릭
- 사이트 제목 에 대한 샘플 이름을 입력
- 사이트를 관리하려면 사용자 이름 과 암호를 입력
- 이메일 주소를 입력
- 이러한 값은 특별히 중요하지 않으므로 사용할 필요가 없긴 함!!
- 워드프레스 설치를 클릭
초기화 프로세스는 Cloud SQL 인스턴스의 wordpress 데이터베이스에 새 데이터베이스 테이블과 데이터를 생성했고, 이제 이러한 새 데이터베이스 테이블이 SQL 프록시 컨테이너를 사용하여 생성되었는지 확인하자.
- Cloud Shell로 다시 전환하고 Cloud SQL 인스턴스에 연결
$ gcloud sql connect sql-instance
Allowlisting your IP for incoming connection for 5 minutes...done.
Connecting to database with SQL user [root].Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 212
Server version: 8.0.31-google (Google)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| wordpress |
+--------------------+
5 rows in set (0.18 sec)
mysql> use wordpress
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-----------------------+
| Tables_in_wordpress |
+-----------------------+
| wp_commentmeta |
| wp_comments |
| wp_links |
| wp_options |
| wp_postmeta |
| wp_posts |
| wp_term_relationships |
| wp_term_taxonomy |
| wp_termmeta |
| wp_terms |
| wp_usermeta |
| wp_users |
+-----------------------+
12 rows in set (0.18 sec)
mysql> select * from wp_users;
+----+------------+------------------------------------+---------------+--------------------+---------------------+---------------------+---------------------+-------------+--------------+
| ID | user_login | user_pass | user_nicename | user_email | user_url | user_registered | user_activation_key | user_status | display_name |
+----+------------+------------------------------------+---------------+--------------------+---------------------+---------------------+---------------------+-------------+--------------+
| 1 | dmlwn3232 | $P$ByQbfwDG094SiBZfxn1oM13tbhsy52. | dmlwn3232 | dmlwn3232@adsf.com | http://34.28.193.59 | 2023-08-03 12:51:04 | | 0 | dmlwn3232 |
+----+------------+------------------------------------+---------------+--------------------+---------------------+---------------------+---------------------+-------------+--------------+
1 row in set (0.17 sec)
mysql> exitWordpress를 초기화할 때 선택한 이메일을 보여주는 Wordpress 관리자 계정의 데이터베이스 레코드가 나열되게 아래의 명령을 수행할 수 있음. select * from wp_users;
